segment anything
1.0.0
SAM 2(Segment Anything Model 2) 의 새 릴리스를 확인하세요.
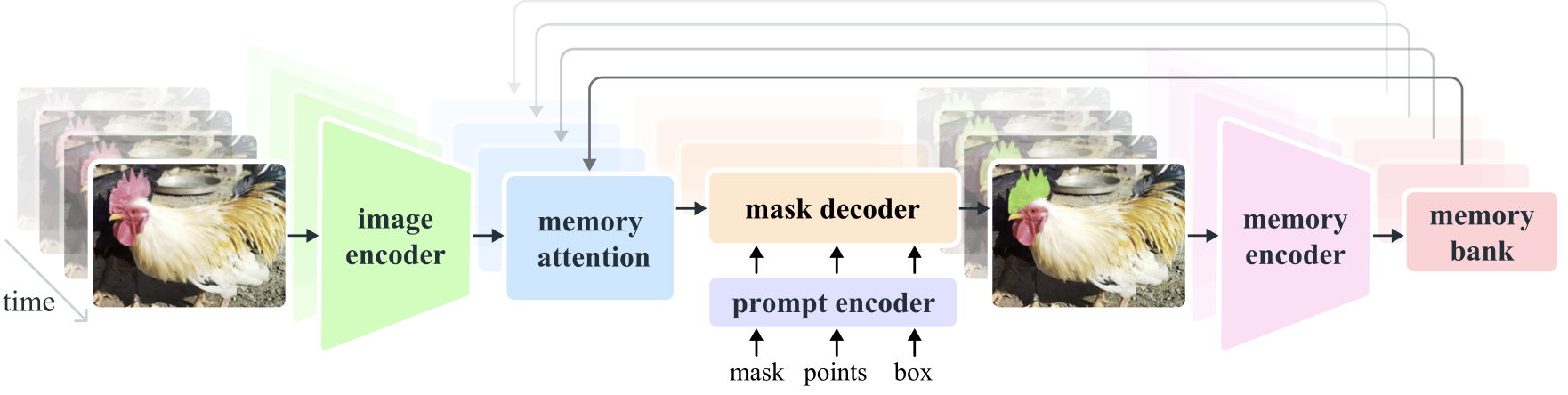
SAM 2(Segment Anything Model 2) 는 이미지와 비디오의 신속한 시각적 분할 문제를 해결하기 위한 기반 모델입니다. 이미지를 단일 프레임의 비디오로 간주하여 SAM을 비디오로 확장합니다. 모델 설계는 실시간 비디오 처리를 위한 스트리밍 메모리를 갖춘 간단한 변환기 아키텍처입니다. 우리는 현재까지 가장 큰 비디오 분할 데이터 세트인 SA-V 데이터 세트를 수집하기 위해 사용자 상호 작용을 통해 모델과 데이터를 개선하는 Model-in-the-Loop 데이터 엔진을 구축합니다. 데이터를 기반으로 훈련된 SAM 2는 광범위한 작업 및 시각적 영역에서 강력한 성능을 제공합니다.
메타 AI 연구, FAIR
알렉산더 키릴로프, 에릭 민툰, 니힐라 라비, 한지 마오, 클로이 롤랜드, 로라 구스타프슨, 테테 샤오, 스펜서 화이트헤드, 알렉스 버그, 완옌 로, 피오트르 달러, 로스 거식
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
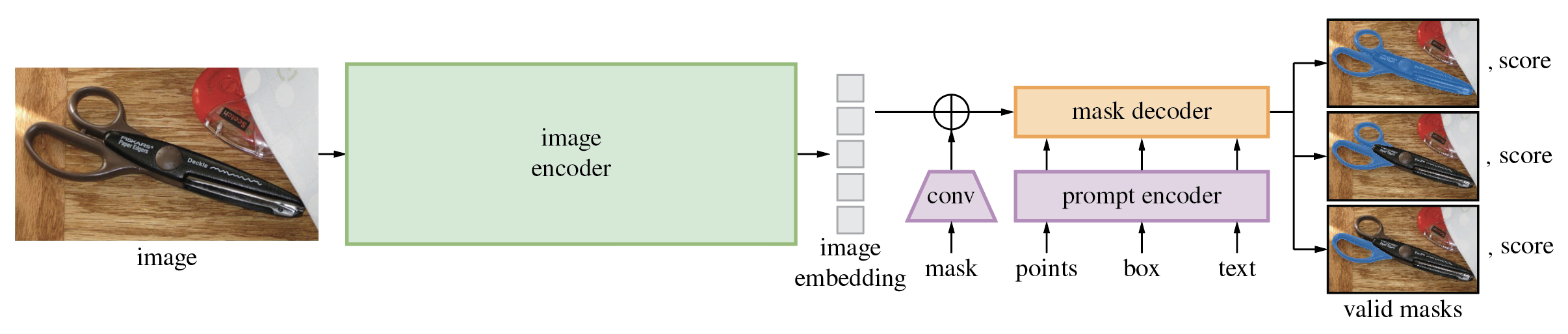
SAM(Segment Anything Model)은 점이나 상자와 같은 입력 프롬프트에서 고품질 개체 마스크를 생성하며 이미지의 모든 개체에 대한 마스크를 생성하는 데 사용할 수 있습니다. 1,100만 개의 이미지와 11억 개의 마스크로 구성된 데이터 세트에 대해 훈련되었으며 다양한 분할 작업에서 강력한 제로샷 성능을 발휘합니다.


코드에는 python>=3.8 , pytorch>=1.7 및 torchvision>=0.8 필요합니다. PyTorch 및 TorchVision 종속성을 모두 설치하려면 여기 지침을 따르십시오. CUDA를 지원하는 PyTorch와 TorchVision을 모두 설치하는 것이 좋습니다.
세그먼트 무엇이든 설치:
pip install git+https://github.com/facebookresearch/segment-anything.git
또는 저장소를 로컬로 복제하고 다음을 사용하여 설치하십시오.
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
마스크 후처리, COCO 형식으로 마스크 저장, 예제 노트북, ONNX 형식으로 모델 내보내기에는 다음과 같은 선택적 종속성이 필요합니다. 예제 노트북을 실행하려면 jupyter 도 필요합니다.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
먼저 모델 체크포인트를 다운로드하세요. 그런 다음 주어진 프롬프트에서 마스크를 가져오기 위해 단 몇 줄의 모델을 사용할 수 있습니다.
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
또는 전체 이미지에 대한 마스크를 생성합니다.
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
또한 명령줄에서 이미지에 대한 마스크를 생성할 수 있습니다.
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
자세한 내용은 프롬프트와 함께 SAM 사용 및 마스크 자동 생성에 대한 예제 노트북을 참조하세요.


SAM의 경량 마스크 디코더는 ONNX 형식으로 내보낼 수 있으므로 데모에 표시된 브라우저 내와 같이 ONNX 런타임을 지원하는 모든 환경에서 실행할 수 있습니다. 다음을 사용하여 모델 내보내기
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
SAM의 백본을 통한 이미지 전처리와 ONNX 모델을 사용한 마스크 예측을 결합하는 방법에 대한 자세한 내용은 예제 노트북을 참조하세요. ONNX 내보내기에는 안정적인 최신 버전의 PyTorch를 사용하는 것이 좋습니다.
demo/ 폴더에는 멀티스레딩을 사용하는 웹 브라우저에서 내보낸 ONNX 모델을 사용하여 마스크 예측을 실행하는 방법을 보여주는 간단한 단일 페이지 React 앱이 있습니다. 자세한 내용은 demo/README.md 참조하세요.
모델의 세 가지 모델 버전은 다양한 백본 크기로 제공됩니다. 이러한 모델은 다음을 실행하여 인스턴스화할 수 있습니다.
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
해당 모델 유형에 대한 체크포인트를 다운로드하려면 아래 링크를 클릭하세요.
default 또는 vit_h : ViT-H SAM 모델.vit_l : ViT-L SAM 모델입니다.vit_b : ViT-B SAM 모델. 데이터 세트의 개요는 여기를 참조하세요. 데이터 세트는 여기에서 다운로드할 수 있습니다. 데이터 세트를 다운로드하면 SA-1B 데이터 세트 연구 라이센스의 조건을 읽고 동의한 것으로 간주됩니다.
이미지당 마스크를 json 파일로 저장합니다. 아래 형식의 Python 사전으로 로드할 수 있습니다.
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}이미지 ID는 위 링크를 사용하여 다운로드할 수 있는 sa_images_ids.txt에서 찾을 수 있습니다.
COCO RLE 형식의 마스크를 바이너리로 디코딩하려면:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
RLE 형식으로 저장된 마스크를 조작하는 방법에 대한 자세한 지침은 여기를 참조하세요.
해당 모델은 Apache 2.0 라이선스에 따라 라이선스가 부여됩니다.
기여 및 행동 강령을 참조하세요.
Segment Anything 프로젝트는 많은 기여자들의 도움으로 가능해졌습니다(알파벳순).
Aaron Adcock, Vaibhav Aggarwal, Morteza Behrooz, Cheng-Yang Fu, Ashley Gabriel, Ahuva Goldstand, Allen Goodman, Sumanth Gurram, Jiabo Hu, Somya Jain, Devansh Kukreja, Robert Kuo, Joshua Lane, Yanghao Li, Lilian Luong, Jitendra Malik, 말리카 말호트라, 윌리엄 응안, 옴카르 파크히, 니킬 레이나, 더크 로우, 닐 세주어, 바네사 스타크, 발라 바라다라잔, 브람 와스티, 재커리 윈스트롬
연구에 SAM 또는 SA-1B를 사용하는 경우 다음 BibTeX 항목을 사용하십시오.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


