obfuscated gradients
v1.0.0
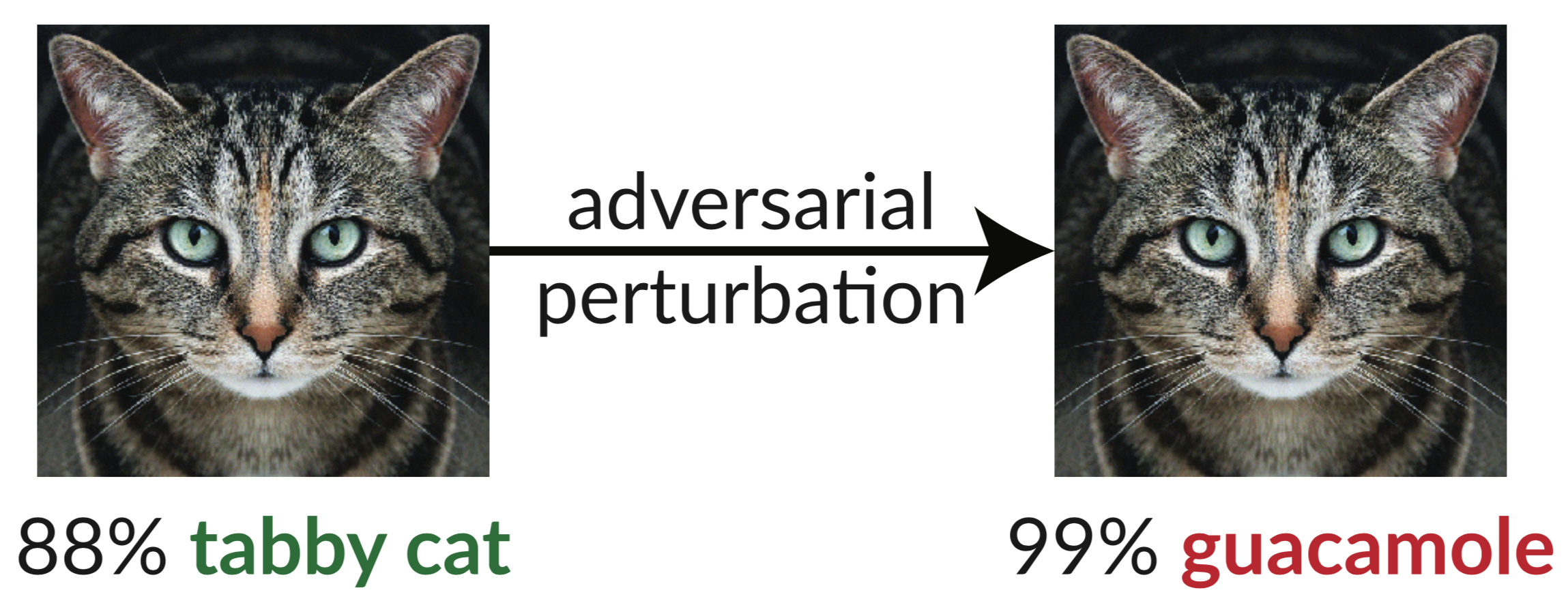
위는 적대적인 예입니다. 고양이의 약간 동요된 이미지는 InceptionV3 분류기를 속여 이를 "과카몰리"로 분류하도록 합니다. 이러한 "속이는 이미지"는 경사하강법을 사용하여 쉽게 합성할 수 있습니다(Szegedy et al. 2013).
최근 논문에서 우리는 적대적 사례에 대한 인증되지 않은 화이트박스 보안 방어로 ICLR 2018에 승인된 9개 논문의 견고성을 평가했습니다. 우리는 9가지 방어 중 7가지가 견고성을 제한적으로 증가시키며 우리가 개발하는 향상된 공격 기술을 통해 깨질 수 있음을 발견했습니다.
아래는 우리 논문의 표 1입니다. 여기서는 우리가 구성할 수 있는 적대적 사례에 대해 허용된 각 방어의 견고성을 보여줍니다.
| 방어 | 데이터세트 | 거리 | 정확성 |
|---|---|---|---|
| Buckmanet al. (2018) | 시파르 | 0.031(린프) | 0%* |
| Maet al. (2018) | 시파르 | 0.031(린프) | 5% |
| Guo et al. (2018) | 이미지넷 | 0.05(l2) | 0%* |
| Dhillonet al. (2018) | 시파르 | 0.031(린프) | 0% |
| Xieet al. (2018) | 이미지넷 | 0.031(린프) | 0%* |
| Songet al. (2018) | 시파르 | 0.031(린프) | 9%* |
| Samangoueiet al. (2018) | MNIST | 0.005(l2) | 55%** |
| Madryet al. (2018) | 시파르 | 0.031(린프) | 47% |
| Naet al. (2018) | 시파르 | 0.015(린프) | 15% |
(*로 표시된 방어는 적대적 훈련 결합을 제안합니다. 여기서는 방어만 보고합니다. 전체 수치는 섹션 5의 논문을 참조하세요. **로 표시된 방어의 기본 원리는 0% 정확도를 갖습니다. 실제로 방어 결함으로 인해 이론적으로 최적의 공격은 실패합니다. 자세한 내용은 섹션 5.4.2를 참조하세요.)
제안된 위협 모델 내에서 적대적 사례에 대한 견고성을 크게 증가시키는 것으로 관찰된 유일한 방어는 "적대적 공격에 저항하는 딥 러닝 모델을 향하여"(Madry et al. 2018)이며, 위협 모델을 벗어나지 않고는 이 방어를 물리칠 수 없었습니다. . 그럼에도 불구하고 이 기술은 ImageNet 규모로 확장하기 어려운 것으로 나타났습니다(Kurakin et al. 2016). 나머지 논문(제한된 견고성을 제공하는 Na et al.의 논문 제외)은 우리가 난독화된 그라디언트 라고 부르는 것에 실수로 또는 의도적으로 의존합니다. 표준 공격은 경사하강법을 적용하여 주어진 이미지에서 네트워크 손실을 최대화하여 신경망에서 적대적인 예를 생성합니다. 이러한 최적화 방법이 성공하려면 유용한 기울기 신호가 필요합니다. 방어가 기울기를 난독화하면 이 기울기 신호가 깨지고 최적화 기반 방법이 실패하게 됩니다.
우리는 방어가 난독화된 경사를 유발하는 세 가지 방식을 식별하고 이러한 각 사례를 우회하는 공격을 구성합니다. 우리의 공격은 일반적으로 의도적 또는 의도하지 않게 미분 불가능한 작업을 포함하거나 그래디언트 신호가 네트워크를 통해 흐르는 것을 방지하는 모든 방어에 적용 가능합니다. 향후 작업에서는 우리의 접근 방식을 사용하여 보다 철저한 보안 평가를 수행할 수 있기를 바랍니다.
추상적인:
우리는 일종의 경사 마스킹인 난독화된 경사를 적대적인 사례에 대한 방어에서 잘못된 보안 감각으로 이어지는 현상으로 식별합니다. 난독화된 그라데이션을 유발하는 방어는 반복적인 최적화 기반 공격을 물리치는 것처럼 보이지만 이 효과에 의존하는 방어는 우회될 수 있습니다. 우리는 효과를 나타내는 방어의 특징적인 동작을 설명하고, 우리가 발견한 세 가지 유형의 난독화된 기울기 각각에 대해 이를 극복하기 위한 공격 기술을 개발합니다. ICLR 2018에서 인증되지 않은 화이트박스 보안 방어를 조사한 사례 연구에서 우리는 난독화된 경사가 흔히 발생하며, 9개 중 7개의 방어가 난독화된 경사에 의존하고 있음을 발견했습니다. 우리의 새로운 공격은 각 문서에서 고려하는 원래 위협 모델에서 6가지를 완전히 우회하고 1가지를 부분적으로 우회했습니다.
자세한 내용은 우리 논문을 읽어보세요.
이 저장소에는 ICLR 2018 방어 중 7가지를 깨뜨린 당사 백서에 설명된 일반 공격 기술의 인스턴스화가 포함되어 있습니다. 일부 방어 수단은 (우리가 이 작업을 수행할 당시) 소스 코드를 공개하지 않았기 때문에 이를 다시 구현해야 했습니다.
@inproceedings{난독화-그라디언트, 저자 = {Anish Athalye 및 Nicholas Carlini 및 David Wagner}, 제목 = {난독화된 그라데이션은 잘못된 보안 감각을 제공합니다: 적대적 사례에 대한 방어 우회}, 책제목 = {기계에 관한 35차 국제 회의의 회보 학습, {ICML} 2018}, 연도 = {2018}, 월 = 7월, URL = {https://arxiv.org/abs/1802.00420},
} 

