Megatron LM
NVIDIA Megatron Core 0.9.0
이 저장소는 Megatron-LM 및 Megatron-Core라는 두 가지 필수 구성 요소로 구성됩니다. Megatron-LM은 LLM(대규모 언어 모델) 교육을 위해 Megatron-Core를 활용하는 연구 중심 프레임워크 역할을 합니다. 반면 Megatron-Core는 버전이 지정된 API 및 일반 릴리스를 포함한 공식 제품 지원과 함께 제공되는 GPU 최적화 교육 기술 라이브러리입니다. 엔드투엔드 및 클라우드 네이티브 솔루션을 위해 Megatron-LM 또는 Nvidia NeMo Framework와 함께 Megatron-Core를 사용할 수 있습니다. 또는 Megatron-Core의 빌딩 블록을 선호하는 교육 프레임워크에 통합할 수 있습니다.
2019년에 처음 소개된 Megatron(1, 2, 3)은 AI 커뮤니티에 혁신의 물결을 촉발하여 연구원과 개발자가 이 라이브러리의 기반을 활용하여 LLM을 더욱 발전시킬 수 있도록 했습니다. 오늘날 가장 인기 있는 LLM 개발자 프레임워크 중 다수는 오픈 소스 Megatron-LM 라이브러리에서 영감을 얻어 직접 활용하여 구축되었으며, 이는 기초 모델 및 AI 스타트업의 물결을 촉발시켰습니다. Megatron-LM을 기반으로 구축된 가장 인기 있는 LLM 프레임워크로는 Colossal-AI, HuggingFace Accelerate 및 NVIDIA NeMo 프레임워크가 있습니다. 메가트론을 직접 활용한 프로젝트 목록은 여기에서 확인할 수 있습니다.
Megatron-Core는 GPU 최적화 기술과 최첨단 시스템 수준 최적화가 포함된 오픈 소스 PyTorch 기반 라이브러리입니다. 이를 구성 가능한 모듈식 API로 추상화하여 개발자와 모델 연구자가 NVIDIA 가속 컴퓨팅 인프라에서 대규모로 맞춤형 변환기를 교육할 수 있는 완전한 유연성을 제공합니다. 이 라이브러리는 NVIDIA Hopper 아키텍처에 대한 FP8 가속 지원을 포함하여 모든 NVIDIA Tensor Core GPU와 호환됩니다.
Megatron-Core는 어텐션 메커니즘, 변환기 블록 및 레이어, 정규화 레이어, 임베딩 기술과 같은 핵심 빌딩 블록을 제공합니다. 활성화 재계산, 분산 체크포인트와 같은 추가 기능도 기본적으로 라이브러리에 내장되어 있습니다. 빌딩 블록과 기능은 모두 GPU에 최적화되어 있으며 NVIDIA 가속 컴퓨팅 인프라에서 최적의 훈련 속도와 안정성을 위한 고급 병렬화 전략으로 구축될 수 있습니다. Megatron-Core 라이브러리의 또 다른 주요 구성 요소에는 고급 모델 병렬 처리 기술(텐서, 시퀀스, 파이프라인, 컨텍스트 및 MoE 전문가 병렬 처리)이 포함됩니다.
Megatron-Core는 엔터프라이즈급 AI 플랫폼인 NVIDIA NeMo와 함께 사용할 수 있습니다. 또는 여기에서 기본 PyTorch 훈련 루프를 사용하여 Megatron-Core를 탐색할 수 있습니다. 자세한 내용은 Megatron-Core 설명서를 참조하세요.
우리의 코드베이스는 모델과 데이터 병렬성을 모두 사용하여 대규모 언어 모델(즉, 수천억 개의 매개변수가 있는 모델)을 효율적으로 훈련할 수 있습니다. 여러 GPU 및 모델 크기로 소프트웨어가 어떻게 확장되는지 보여주기 위해 20억 개의 매개변수에서 4,620억 개의 매개변수에 이르는 GPT 모델을 고려합니다. 모든 모델은 131,072의 어휘 크기와 4096의 시퀀스 길이를 사용합니다. 특정 모델 크기에 도달하기 위해 숨겨진 크기, 주의 헤드 수 및 레이어 수를 변경합니다. 모델 크기가 증가함에 따라 배치 크기도 약간 증가합니다. 우리의 실험에서는 최대 6144개의 H100 GPU를 사용합니다. 우리는 데이터 병렬( --overlap-grad-reduce --overlap-param-gather ), 텐서 병렬( --tp-comm-overlap ) 및 파이프라인 병렬 통신(기본적으로 활성화됨)의 세밀한 중첩을 수행합니다. 확장성을 향상시키기 위한 계산. 보고된 처리량은 엔드투엔드 교육을 위해 측정되며 데이터 로드, 최적화 단계, 통신 및 로깅을 포함한 모든 작업을 포함합니다. 우리는 이러한 모델을 수렴하도록 훈련하지 않았습니다.
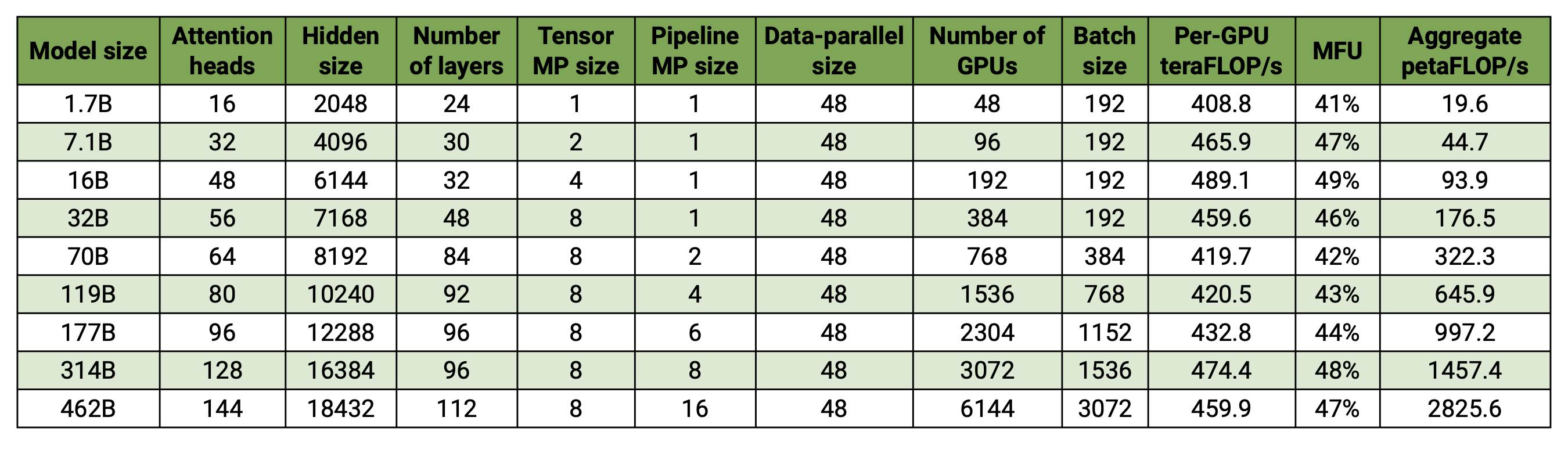
약한 스케일링 결과는 초선형 스케일링을 보여줍니다(MFU는 가장 작은 모델의 경우 41%에서 가장 큰 모델의 경우 47-48%로 증가). 이는 더 큰 GEMM이 더 높은 산술 강도를 가지며 결과적으로 실행이 더 효율적이기 때문입니다.
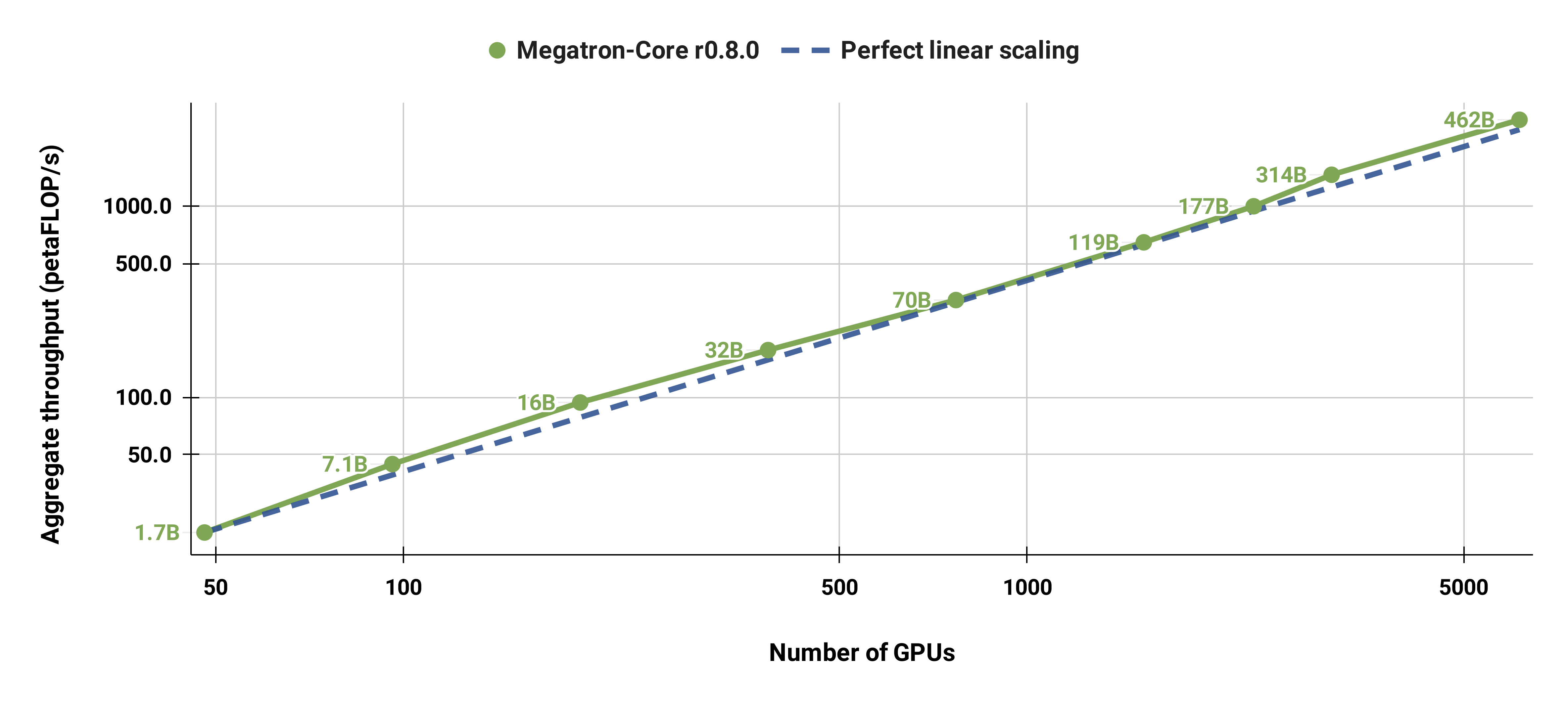
또한 표준 GPT-3 모델(우리 버전에는 더 큰 어휘 크기로 인해 1,750억 개가 넘는 매개 변수가 있음)을 96개의 H100 GPU에서 4608 GPU로 강력하게 확장했으며 전체적으로 1152개 시퀀스의 동일한 배치 크기를 사용했습니다. 대규모로 통신이 더 많이 노출되어 MFU가 47%에서 42%로 감소합니다.
DGX 노드와 함께 NGC PyTorch 컨테이너의 최신 릴리스를 사용하는 것이 좋습니다. 어떤 이유로든 이를 사용할 수 없는 경우 최신 pytorch, cuda, nccl 및 NVIDIA APEX 릴리스를 사용하세요. 데이터 전처리에는 NLTK가 필요하지만 훈련, 평가 또는 다운스트림 작업에는 필요하지 않습니다.
다음 Docker 명령을 사용하여 PyTorch 컨테이너의 인스턴스를 시작하고 Megatron, 데이터 세트 및 체크포인트를 탑재할 수 있습니다.
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
우리는 다운스트림 작업을 평가하거나 미세 조정하기 위해 사전 훈련된 BERT-345M 및 GPT-345M 체크포인트를 제공했습니다. 이러한 체크포인트에 액세스하려면 먼저 NGC(NVIDIA GPU Cloud) 레지스트리 CLI에 등록하고 설정하세요. 모델 다운로드에 대한 추가 문서는 NGC 문서에서 찾을 수 있습니다.
또는 다음을 사용하여 체크포인트를 직접 다운로드할 수 있습니다.
BERT-345M-비케이스: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M 케이스: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
모델을 실행하려면 어휘 파일이 필요합니다. BERT WordPiece 어휘 파일은 Google의 사전 학습된 BERT 모델(언케이스, 케이스 포함)에서 추출할 수 있습니다. GPT 어휘 파일과 병합 테이블을 직접 다운로드할 수 있습니다.
설치 후 몇 가지 가능한 워크플로가 있습니다. 가장 포괄적인 것은 다음과 같습니다:
그러나 1단계와 2단계는 위에서 언급한 사전 학습된 모델 중 하나를 사용하여 대체할 수 있습니다.
우리는 MNLI, RACE, WikiText103 및 LAMBADA 평가를 포함하여 제로샷 및 미세 조정된 다운스트림 작업을 위한 스크립트뿐만 아니라 BERT 및 GPT를 모두 사전 훈련하기 위한 여러 스크립트를 examples 디렉터리에 제공했습니다. GPT 대화형 텍스트 생성을 위한 스크립트도 있습니다.
훈련 데이터에는 전처리가 필요합니다. 먼저 훈련 데이터를 느슨한 json 형식으로 배치하고 한 줄에 텍스트 샘플이 포함된 하나의 json을 사용합니다. 예를 들어:
{"src": "www.nvidia.com", "text": "빠른 갈색 여우", "type": "Eng", "id": "0", "title": "첫 번째 부분"}
{"src": "인터넷", "text": "게으른 개를 뛰어 넘다", "type": "Eng", "id": "42", "title": "두 번째 부분"}
preprocess_data.py 에서 --json-key 플래그를 사용하여 json의 text 필드 이름을 변경할 수 있습니다. 다른 메타데이터는 선택 사항이며 교육에 사용되지 않습니다.
느슨한 json은 훈련을 위해 바이너리 형식으로 처리됩니다. json을 mmap 형식으로 변환하려면 preprocess_data.py 사용하세요. BERT 교육을 위한 데이터를 준비하는 예제 스크립트는 다음과 같습니다.
파이썬 도구/preprocess_data.py
--input my-corpus.json
--output-prefix my-bert
--vocab-파일 bert-vocab.txt
--tokenizer 유형 BertWordPieceLowerCase
--분할 문장
출력은 두 개의 파일(이 경우 my-bert_text_sentence.bin 및 my-bert_text_sentence.idx 이 됩니다. 이후 BERT 교육에 지정된 --data-path 전체 경로와 새 파일 이름이지만 파일 확장자는 없습니다.
T5의 경우 BERT와 동일한 전처리를 사용하고 이름을 다음과 같이 바꿀 수 있습니다.
--출력 접두사 my-t5
GPT 데이터 전처리에는 병합 테이블 추가, 문서 끝 토큰, 문장 분할 제거, 토크나이저 유형 변경 등 몇 가지 사소한 수정이 필요합니다.
파이썬 도구/preprocess_data.py
--input my-corpus.json
--output-prefix my-gpt2
--vocab-파일 gpt2-vocab.json
--tokenizer 유형 GPT2BPETokenizer
--병합 파일 gpt2-merges.txt
--첨부-eod
여기서 출력 파일의 이름은 my-gpt2_text_document.bin 및 my-gpt2_text_document.idx 입니다. 이전과 마찬가지로 GPT 학습에서는 --data-path 와 같이 확장자가 없는 긴 이름을 사용합니다.
추가 명령줄 인수는 소스 파일 preprocess_data.py 에 설명되어 있습니다.
examples/bert/train_bert_340m_distributed.sh 스크립트는 단일 GPU 345M 매개변수 BERT 사전 훈련을 실행합니다. 코드 베이스와 명령줄 인수는 고도로 분산된 훈련에 최적화되어 있으므로 디버깅은 단일 GPU 훈련의 주요 용도입니다. 대부분의 주장은 상당히 자명합니다. 기본적으로 학습 속도는 --lr 에서 시작하여 --lr-decay-iters 반복에 걸쳐 --min-lr 에 의해 설정된 최소값까지 선형적으로 감소합니다. 준비 작업에 사용되는 훈련 반복의 비율은 --lr-warmup-fraction 에 의해 설정됩니다. 이는 단일 GPU 훈련이지만 --micro-batch-size 로 지정된 배치 크기는 단일 정방향-역방향 경로 배치 크기이며 코드는 배치 크기인 global-batch-size 에 도달할 때까지 그래디언트 누적 단계를 수행합니다. 반복마다. 데이터는 학습/검증/테스트 세트에 대해 949:50:1 비율로 분할됩니다(기본값은 969:30:1). 이 분할은 즉시 발생하지만 동일한 무작위 시드(기본적으로 1234 또는 --seed 사용하여 수동으로 지정)를 사용하여 실행 전반에 걸쳐 일관성이 있습니다. 우리는 요청된 훈련 반복으로 train-iters 사용합니다. 또는 훈련할 총 샘플 수인 --train-samples 제공할 수 있습니다. 이 옵션이 있는 경우 --lr-decay-iters 대신 --lr-decay-samples 제공해야 합니다.
로깅, 체크포인트 저장, 평가 간격 옵션이 지정됩니다. --data-path 에는 이제 전처리에 추가된 추가 _text_sentence 접미사가 포함되지만 파일 확장자는 포함되지 않습니다.
추가 명령줄 인수는 소스 파일인 arguments.py 에 설명되어 있습니다.
train_bert_340m_distributed.sh 실행하려면 CHECKPOINT_PATH , VOCAB_FILE 및 DATA_PATH 에 대한 환경 변수 설정을 포함하여 원하는 대로 수정하세요. 이러한 변수를 컨테이너의 해당 경로로 설정해야 합니다. 그런 다음 Megatron과 필요한 경로가 마운트된(설정에 설명된 대로) 컨테이너를 시작하고 예제 스크립트를 실행합니다.
examples/gpt3/train_gpt3_175b_distributed.sh 스크립트는 단일 GPU 345M 매개변수 GPT 사전 훈련을 실행합니다. 위에서 언급했듯이 단일 GPU 훈련은 코드가 분산 훈련에 최적화되어 있으므로 주로 디버깅 목적으로 사용됩니다.
이전 BERT 스크립트와 거의 동일한 형식을 따르지만 몇 가지 눈에 띄는 차이점이 있습니다. 사용된 토큰화 체계는 WordPiece 대신 BPE(병합 테이블과 json 어휘 파일 필요)이며, 모델 아키텍처는 더 긴 시퀀스를 허용합니다(참고: 최대 위치 임베딩은 최대 시퀀스 길이보다 크거나 같아야 함) --lr-decay-style 코사인 붕괴로 설정되었습니다. --data-path 에는 이제 전처리에 추가된 추가 _text_document 접미사가 포함되지만 파일 확장자는 포함되지 않습니다.
추가 명령줄 인수는 소스 파일인 arguments.py 에 설명되어 있습니다.
train_gpt3_175b_distributed.sh BERT에 대해 설명한 것과 동일한 방식으로 시작할 수 있습니다. 환경 변수를 설정하고 기타 수정 작업을 수행한 후 적절한 마운트로 컨테이너를 시작하고 스크립트를 실행합니다. examples/gpt3/README.md 에서 자세한 내용을 확인하세요.
BERT 및 GPT와 매우 유사한 examples/t5/train_t5_220m_distributed.sh 스크립트는 단일 GPU "기본"(~220M 매개변수) T5 사전 훈련을 실행합니다. BERT와 GPT의 주요 차이점은 T5 아키텍처를 수용하기 위해 다음 인수가 추가된다는 것입니다.
--kv-channels 모델의 모든 주의 메커니즘의 "키" 및 "값" 행렬의 내부 차원을 설정합니다. BERT 및 GPT의 경우 이는 기본적으로 숨겨진 크기를 주의 헤드 수로 나눈 값이지만 T5에 대해 구성할 수 있습니다.
--ffn-hidden-size 변환기 계층 내의 피드포워드 네트워크에 숨겨진 크기를 설정합니다. BERT 및 GPT의 경우 기본값은 변환기 숨겨진 크기의 4배이지만 T5에 대해 구성할 수 있습니다.
--encoder-seq-length 및 --decoder-seq-length 인코더와 디코더의 시퀀스 길이를 별도로 설정합니다.
다른 모든 주장은 BERT 및 GPT 사전 학습에 대한 것과 동일하게 유지됩니다. 다른 스크립트에 대해 위에서 설명한 것과 동일한 단계를 사용하여 이 예제를 실행합니다.
자세한 내용은 examples/t5/README.md 를 참조하세요.
pretrain_{bert,gpt,t5}_distributed.sh 스크립트는 분산 교육을 위해 PyTorch 분산 실행 프로그램을 사용합니다. 이처럼 다중 노드 학습은 환경 변수를 적절하게 설정함으로써 달성할 수 있습니다. 이러한 환경 변수에 대한 자세한 설명은 공식 PyTorch 문서를 참조하세요. 기본적으로 다중 노드 학습에서는 nccl 분산 백엔드를 사용합니다. 간단한 추가 인수 세트와 torchrun Elastic Launcher( python -m torch.distributed.run 와 동일)와 함께 PyTorch 분산 모듈을 사용하는 것은 분산 교육을 채택하기 위한 유일한 추가 요구 사항입니다. 자세한 내용은 pretrain_{bert,gpt,t5}_distributed.sh 를 참조하세요.
우리는 데이터 병렬성과 모델 병렬성의 두 가지 유형의 병렬성을 사용합니다. 우리의 데이터 병렬 처리 구현은 megatron/core/distributed 에 있으며 --overlap-grad-reduce 명령줄 옵션이 사용될 때 역방향 전달과 기울기 감소의 중첩을 지원합니다.
둘째, 간단하고 효율적인 2차원 모델 병렬 접근 방식을 개발했습니다. 첫 번째 차원인 텐서 모델 병렬성(여러 GPU에 대한 단일 변환기 모듈의 실행 분할, 논문의 섹션 3 참조)을 사용하려면 --tensor-model-parallel-size 플래그를 추가하여 GPU 수를 지정하세요. 위에서 언급한 대로 분산 실행 프로그램에 전달된 인수와 함께 모델을 분할합니다. 두 번째 차원인 시퀀스 병렬성을 사용하려면 --sequence-parallel 지정하십시오. 이는 동일한 GPU에 걸쳐 분할되기 때문에 텐서 모델 병렬성을 활성화해야 합니다(자세한 내용은 본 문서의 섹션 4.2.2 참조).
파이프라인 모델 병렬 처리를 사용하려면(변환기 모듈을 각 단계에서 동일한 수의 변환기 모듈로 분할한 다음 배치를 더 작은 마이크로배치로 나누어 실행을 파이프라인하는 것, 논문의 섹션 2.2 참조) --pipeline-model-parallel-size 사용하세요. -모델을 분할할 단계 수를 지정하는 --pipeline-model-parallel-size 플래그(예: 4개 단계에 걸쳐 24개의 변환기 레이어가 있는 모델을 분할하면 각 단계가 각각 6개의 변환기 레이어를 갖게 됨을 의미함)
distributed_with_mp.sh 로 끝나는 예제 스크립트와 같이 두 가지 다른 형태의 모델 병렬성을 사용하는 방법에 대한 예가 있습니다.
이러한 사소한 변경 사항을 제외하면 분산 학습은 단일 GPU에서의 학습과 동일합니다.
인터리빙된 파이프라인 일정(자세한 내용은 본 문서의 섹션 2.2.2 참조)은 가상 단계의 변환기 레이어 수를 제어하는 --num-layers-per-virtual-pipeline-stage 인수를 사용하여 활성화할 수 있습니다(기본적으로). 인터리브되지 않은 일정을 사용하면 각 GPU는 NUM_LAYERS / PIPELINE_MP_SIZE 변환기 레이어가 있는 단일 가상 단계를 실행합니다. 변환기 모델의 총 레이어 수는 이 인수 값으로 나눌 수 있어야 합니다. 또한 이 일정을 사용할 때 파이프라인의 마이크로배치 수( GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) 로 계산됨)는 PIPELINE_MP_SIZE 로 나눌 수 있어야 합니다(이 조건은 코드의 어설션에서 확인됨). 2단계( PIPELINE_MP_SIZE=2 ) 파이프라인에는 인터리브 일정이 지원되지 않습니다.
대규모 모델을 훈련할 때 GPU 메모리 사용량을 줄이기 위해 다양한 형태의 활성화 체크포인트 및 재계산을 지원합니다. 전통적으로 딥러닝 모델의 경우처럼 역전파 중에 사용하기 위해 모든 활성화를 메모리에 저장하는 대신 모델의 특정 "체크포인트"에 있는 활성화만 메모리에 유지(또는 저장)되고 다른 활성화는 다시 계산됩니다. -역전파가 필요할 때 더 플라이(the-fly). 이러한 종류의 체크포인트인 활성화 체크포인트는 다른 곳에서 언급되는 모델 매개변수 및 최적화 프로그램 상태의 체크포인트와 매우 다릅니다.
우리는 selective 및 full 두 가지 수준의 재계산 세분성을 지원합니다. 선택적 재계산은 기본값이며 거의 모든 경우에 권장됩니다. 이 모드는 메모리 저장 공간을 적게 차지하고 재계산하는 데 비용이 더 많이 드는 활성화를 메모리에 유지하며, 메모리 저장 공간을 더 많이 차지하지만 재계산하는 데 상대적으로 비용이 적게 드는 활성화를 다시 계산합니다. 자세한 내용은 우리의 논문을 참조하세요. 이 모드는 활성화를 저장하는 데 필요한 메모리를 최소화하면서 성능을 최대화한다는 것을 알아야 합니다. 선택적 활성화 재계산을 활성화하려면 --recompute-activations 사용하세요.
메모리가 매우 제한적인 경우 full 재계산은 변환기 레이어, 변환기 레이어의 그룹 또는 블록에 대한 입력만 저장하고 나머지는 모두 다시 계산합니다. 전체 활성화 재계산을 활성화하려면 --recompute-granularity full 사용하세요. full 활성화 재계산을 사용하는 경우 --recompute-method 인수를 사용하여 선택된 두 가지 방법 uniform 및 block 이 있습니다.
uniform 방법은 변환기 계층을 계층 그룹(각 그룹 크기 --recompute-num-layers )으로 균일하게 나누고 각 그룹의 입력 활성화를 메모리에 저장합니다. 기준 그룹 크기는 1이며, 이 경우 각 변환기 계층의 입력 활성화가 저장됩니다. GPU 메모리가 부족한 경우 그룹당 레이어 수를 늘리면 메모리 사용량이 줄어들어 더 큰 모델을 학습할 수 있습니다. 예를 들어 --recompute-num-layers 4로 설정된 경우 4개의 변환기 레이어로 구성된 각 그룹의 입력 활성화만 저장됩니다.
block 방법은 파이프라인 단계당 개별 변환기 레이어의 특정 수( --recompute-num-layers 로 지정)의 입력 활성화를 다시 계산하고 파이프라인 단계에 나머지 레이어의 입력 활성화를 저장합니다. --recompute-num-layers 줄이면 더 많은 변환기 레이어에 입력 활성화가 저장되어 역전파에 필요한 활성화 재계산이 줄어들어 메모리 사용량이 늘어나면서 훈련 성능이 향상됩니다. 예를 들어, 파이프라인 단계당 8개 레이어를 다시 계산하기 위해 5개 레이어를 지정하면 처음 5개 변환기 레이어의 입력 활성화만 백프로프 단계에서 다시 계산되고 마지막 3개 레이어에 대한 입력 활성화는 저장됩니다. --recompute-num-layers 필요한 메모리 저장 공간이 사용 가능한 메모리에 맞을 만큼 작아질 때까지 점진적으로 늘릴 수 있습니다. 이를 통해 메모리 활용과 성능을 최대화할 수 있습니다.
사용법: --use-distributed-optimizer . 모든 모델 및 데이터 유형과 호환됩니다.
분산 최적화 프로그램은 메모리 절약 기술로, 최적화 프로그램 상태가 데이터 병렬 랭크 전체에 고르게 분산됩니다(데이터 병렬 랭크 전체에 최적화 프로그램 상태를 복제하는 기존 방법과 비교). ZeRO: 수조 개의 매개변수 모델 훈련을 위한 메모리 최적화에 설명된 대로, 우리의 구현은 모델 상태와 겹치지 않는 모든 최적화 상태를 배포합니다. 예를 들어, fp16 모델 매개변수를 사용할 때 분산 최적화 프로그램은 DP 순위에 분산되는 fp32 기본 매개변수 및 등급의 별도 복사본을 유지 관리합니다. 그러나 bf16 모델 매개변수를 사용하는 경우 분산 최적화 프로그램의 fp32 기본 등급은 모델의 fp32 등급과 동일하므로 이 경우 등급은 분산되지 않습니다(fp32 기본 매개변수는 bf16과 별개이므로 여전히 분산됩니다). 모델 매개변수).
이론적인 메모리 절약은 모델의 param dtype과 grad dtype의 조합에 따라 달라집니다. 우리 구현에서 매개변수당 이론적 바이트 수는 다음과 같습니다(여기서 'd'는 데이터 병렬 크기).
| 비분산 최적화 | 분산 최적화 | |
|---|---|---|
| fp16 매개변수, fp16 grads | 20 | 4 + 16/일 |
| bf16 매개변수, fp32 그래드 | 18 | 6 + 12/일 |
| fp32 매개변수, fp32 그래드 | 16 | 8 + 8/일 |
일반 데이터 병렬 처리와 마찬가지로 --overlap-grad-reduce 플래그를 사용하면 기울기 감소(이 경우 감소-분산)와 역방향 전달의 중첩이 용이해질 수 있습니다. 또한 all-gather 매개변수의 겹침은 --overlap-param-gather 사용하여 정방향 전달과 겹칠 수 있습니다.
사용법: --use-flash-attn . 최대 128개의 주의 머리 크기를 지원합니다.
FlashAttention은 정확한 주의를 계산하는 빠르고 메모리 효율적인 알고리즘입니다. 모델 훈련 속도를 높이고 메모리 요구 사항을 줄입니다.
FlashAttention을 설치하려면:
pip install flash-attn examples/gpt3/train_gpt3_175b_distributed.sh 에서 우리는 1024개의 GPU에서 1,750억 개의 매개변수로 GPT-3를 훈련하도록 Megatron을 구성하는 방법에 대한 예를 제공했습니다. 이 스크립트는 pyxis 플러그인을 사용하여 slurm용으로 설계되었지만 다른 스케줄러에도 쉽게 채택할 수 있습니다. 8방향 텐서 병렬성과 16방향 파이프라인 병렬성을 사용합니다. global-batch-size 1536 및 rampup-batch-size 16 16 5859375 옵션을 사용하면 훈련은 전역 배치 크기 16으로 시작하고 증분 단계 16을 사용하여 5,859,375개 샘플에 대해 전역 배치 크기를 1536으로 선형적으로 증가시킵니다. 훈련 데이터 세트는 다음 중 하나일 수 있습니다. 단일 세트 또는 가중치 세트와 결합된 여러 데이터세트.
1024개의 A100 GPU에서 전체 글로벌 배치 크기가 1536인 경우 각 반복에는 약 32초가 소요되어 GPU당 138teraFLOP가 생성됩니다. 이는 이론적 최고 FLOP의 44%입니다.
Retro(Borgeaud et al., 2022)는 검색 증강으로 사전 훈련된 자동 회귀 디코더 전용 언어 모델(LM)입니다. Retro는 수조 개의 토큰을 검색하여 처음부터 대규모 사전 학습을 지원하는 실용적인 확장성을 제공합니다. 검색을 통한 사전 훈련은 네트워크 매개변수 내에 암시적으로 사실 지식을 저장하는 것과 비교할 때 사실 지식의 보다 효율적인 저장 메커니즘을 제공하므로 모델 매개변수를 크게 줄이면서 표준 GPT보다 낮은 복잡성을 달성합니다. Retro는 또한 LM을 다시 교육하지 않고도 검색 데이터베이스를 업데이트하여 LM에 저장된 지식을 업데이트할 수 있는 유연성을 제공합니다(Wang et al., 2023a).
InstructRetro(Wang et al., 2023b)는 Retro의 크기를 48B로 더욱 확장하여 검색 기능으로 사전 훈련된 가장 큰 LLM을 특징으로 합니다(2023년 12월 기준). 획득된 기초 모델인 Retro 48B는 복잡성 측면에서 GPT 모델보다 훨씬 뛰어납니다. Retro의 명령 조정을 통해 InstructRetro는 제로샷 설정의 다운스트림 작업에서 명령 조정 GPT에 비해 상당한 개선을 보여줍니다. 특히 InstructRetro의 평균 개선은 8개의 짧은 QA 작업에서 GPT에 비해 7%, 4개의 까다로운 긴 QA 작업에서 GPT에 비해 10% 향상되었습니다. 또한 InstructRetro 아키텍처에서 인코더를 제거하고 InstructRetro 디코더 백본을 GPT로 직접 사용하면서 비슷한 결과를 얻을 수 있다는 사실도 발견했습니다.
이 저장소에서는 Retro 및 InstructRetro를 구현하기 위한 엔드투엔드 재현 가이드를 제공합니다.
자세한 개요는 tools/retro/README.md를 참조하세요.
자세한 내용은 예제/mamba를 참조하세요.
다양한 제로샷 및 미세 조정된 다운스트림 작업을 처리하기 위해 아래 나열된 스크립트에 자세히 설명된 여러 명령줄 인수를 제공합니다. 그러나 원하는 대로 다른 말뭉치의 사전 훈련된 체크포인트에서 모델을 미세 조정할 수도 있습니다. 그렇게 하려면 --finetune 플래그를 추가하고 원본 훈련 스크립트 내에서 입력 파일과 훈련 매개변수를 조정하기만 하면 됩니다. 반복 횟수는 0으로 재설정되고 최적화 프로그램과 내부 상태는 다시 초기화됩니다. 어떤 이유로든 미세 조정이 중단된 경우 계속하기 전에 --finetune 플래그를 제거해야 합니다. 그렇지 않으면 훈련이 처음부터 다시 시작됩니다.
평가에는 훈련보다 훨씬 적은 메모리가 필요하므로 다운스트림 작업에서 더 적은 수의 GPU에서 사용하기 위해 병렬로 훈련된 모델을 병합하는 것이 유리할 수 있습니다. 다음 스크립트는 이를 수행합니다. 이 예에서는 4방향 텐서 및 4방향 파이프라인 모델 병렬 처리가 있는 GPT 모델을 읽고 2방향 텐서 및 2방향 파이프라인 모델 병렬 처리가 있는 모델을 작성합니다.
파이썬 도구/체크포인트/convert.py
--모델 유형 GPT
--load-dir 체크포인트/gpt3_tp4_pp4
--저장 디렉터리 체크포인트/gpt3_tp2_pp2
--대상-텐서-병렬-크기 2
--대상-파이프라인-병렬-크기 2
아래에는 GPT 및 BERT 모델 모두에 대한 여러 다운스트림 작업이 설명되어 있습니다. 훈련 스크립트에 사용된 것과 동일한 변경 사항을 사용하여 분산 및 모델 병렬 모드에서 실행할 수 있습니다.
tools/run_text_generation_server.py 에 텍스트 생성에 사용할 간단한 REST 서버를 포함시켰습니다. 적절한 사전 훈련된 체크포인트를 지정하여 사전 훈련 작업을 시작하는 것처럼 실행합니다. temperature , top-k 및 top-p 와 같은 몇 가지 선택적 매개변수도 있습니다. 자세한 내용은 --help 또는 소스 파일을 참조하세요. 서버 실행 방법에 대한 예는 example/inference/run_text_ Generation_server_345M.sh를 참조하세요.
서버가 실행되면 tools/text_generation_cli.py 사용하여 쿼리할 수 있으며 서버가 실행 중인 호스트인 하나의 인수를 사용합니다.
도구/text_ Generation_cli.py localhost:5000
CURL이나 다른 도구를 사용하여 서버에 직접 쿼리할 수도 있습니다.
컬 'http://localhost:5000/api' -X 'PUT' -H '콘텐츠 유형: 애플리케이션/json; charset=UTF-8' -d '{"prompts":["Hello world"], "tokens_to_generate":1}'
더 많은 API 옵션은 megatron/inference/text_ Generation_server.py를 참조하세요.
examples/academic_paper_scripts/detxoify_lm/ 에 언어 모델의 생성 능력을 활용하여 언어 모델을 해독하는 예제가 포함되어 있습니다.
자체 생성 코퍼스를 사용하여 도메인 적응형 교육을 수행하고 LM을 해독하는 방법에 대한 단계별 자습서는 example/academic_paper_scripts/detxoify_lm/README.md를 참조하세요.
WikiText 난해성 평가 및 LAMBADA Cloze 정확도에 대한 GPT 평가를 위한 예제 스크립트가 포함되어 있습니다.
이전 작업과의 균일한 비교를 위해 단어 수준 WikiText-103 테스트 데이터 세트에서 당혹감을 평가하고 하위 단어 토크나이저를 사용할 때 토큰의 변화에 따른 당혹감을 적절하게 계산합니다.
우리는 345M 매개변수 모델에 대해 WikiText-103 평가를 실행하기 위해 다음 명령을 사용합니다.
태스크="WIKITEXT103"
VALID_DATA=<위키텍스트 경로>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=체크포인트/gpt2_345m
COMMON_TASK_ARGS="--num-layers 24
--숨겨진 크기 1024
--num-attention-heads 16
--seq 길이 1024
--최대 위치 임베딩 1024
--fp16
--vocab-파일 $VOCAB_FILE"
파이썬 작업/main.py
--작업 $TASK
$COMMON_TASK_ARGS
--유효 데이터 $VALID_DATA
--tokenizer 유형 GPT2BPETokenizer
--병합 파일 $MERGE_FILE
--$CHECKPOINT_PATH 로드
--마이크로 배치 크기 8
--로그 간격 10
--no-load-최적화
--no-load-rng
LAMBADA 클로즈 정확도(이전 토큰에 대해 마지막 토큰을 예측하는 정확도)를 계산하기 위해 LAMBADA 데이터세트의 토큰화 및 처리된 버전을 활용합니다.
다음 명령을 사용하여 345M 매개변수 모델에서 LAMBADA 평가를 실행합니다. 전체 단어 일치를 요구하려면 --strict-lambada 플래그를 사용해야 합니다. lambada 파일 경로의 일부인지 확인하세요.
작업="람바다"
VALID_DATA=<람바다 경로>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=체크포인트/gpt2_345m
COMMON_TASK_ARGS=<위의 WikiText Perplexity 평가와 동일>
파이썬 작업/main.py
--작업 $TASK
$COMMON_TASK_ARGS
--유효 데이터 $VALID_DATA
--tokenizer 유형 GPT2BPETokenizer
--엄격한-람바다
--병합 파일 $MERGE_FILE
--$CHECKPOINT_PATH 로드
--마이크로 배치 크기 8
--로그 간격 10
--no-load-최적화
--no-load-rng
추가 명령줄 인수는 소스 파일 main.py 에 설명되어 있습니다.
다음 스크립트는 RACE 데이터세트 평가를 위해 BERT 모델을 미세 조정합니다. TRAIN_DATA 및 VALID_DATA 디렉터리에는 RACE 데이터세트가 별도의 .txt 파일로 포함되어 있습니다. RACE의 경우 배치 크기는 평가할 RACE 쿼리 수입니다. 각 RACE 쿼리에는 4개의 샘플이 있으므로 모델을 통해 전달되는 효과적인 배치 크기는 명령줄에 지정된 배치 크기의 4배가 됩니다.
TRAIN_DATA="데이터/RACE/기차/중간"
VALID_DATA="데이터/RACE/dev/중간
데이터/RACE/dev/high"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=체크포인트/bert_345m
CHECKPOINT_PATH=체크포인트/bert_345m_race
COMMON_TASK_ARGS="--num-layers 24
--숨겨진 크기 1024
--num-attention-heads 16
--seq-길이 512
--최대 위치 임베딩 512
--fp16
--vocab-파일 $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--열차 데이터 $TRAIN_DATA
--유효 데이터 $VALID_DATA
--사전 훈련된 체크포인트 $PRETRAINED_CHECKPOINT
--저장 간격 10000
--$CHECKPOINT_PATH 저장
--로그 간격 100
--평가 간격 1000
--eval-iters 10
--중량 감쇠 1.0e-1"
파이썬 작업/main.py
--작업 RACE
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer 유형 BertWordPieceLowerCase
--에포크 3
--마이크로 배치 크기 4
--lr 1.0e-5
--lr-워밍업-분수 0.06
다음 스크립트는 MultiNLI 문장 쌍 코퍼스를 사용한 평가를 위해 BERT 모델을 미세 조정합니다. 일치하는 작업이 매우 유사하기 때문에 QQP(Quora 질문 쌍) 데이터 세트에서도 작동하도록 스크립트를 빠르게 조정할 수 있습니다.
TRAIN_DATA="데이터/glue_data/MNLI/train.tsv"
VALID_DATA="data/glue_data/MNLI/dev_matched.tsv
Data/Glue_data/Mnli/dev_mistatched.tsv "
pretrained_checkpoint = Checkpoints/bert_345m
vocab_file = bert-vocab.txt
Checkpoint_Path = CheckPoints/Bert_345M_MNLI
common_task_args = <위의 레이스 평가에서와 동일>
common_task_args_ext = <위의 레이스 평가와 동일>
Python 작업/main.py
-태스크 mnli
$ common_task_args
$ common_task_args_ext
-tokenizer-type bertwordpiecelowercase
--epochs 5
-마이크로 배치 크기 8
---lr 5.0E-5
--LR-WARMUP-FRACTION 0.065
LLAMA-2 모델 패밀리는 광범위한 벤치 마크에서 강력한 결과를 얻은 사전 상환 및 미세 튜닝 (채팅) 모델의 오픈 소스 세트입니다. 출시 당시 LLAMA-2 모델은 오픈 소스 모델의 최상의 결과 중에서 달성했으며 폐쇄 소스 GPT-3.5 모델과 경쟁했습니다 (https://arxiv.org/pdf/2307.09288.pdf 참조).
LLAMA-2 체크 포인트는 추론 및 미세 조정을 위해 메가 트론에로드 할 수 있습니다. 여기 문서를 참조하십시오.
Megatron-Core (Mcore) GPTModel 패밀리는 Tensorrt-LLM을 통한 고급 양자화 알고리즘 및 고성능 추론을 지원합니다.
llama2 및 nemotron3 예제의 Megatron 모델 최적화 및 배포를 참조하십시오.
우리는 GPT 또는 BERT 교육을위한 데이터 세트를 호스팅하지 않지만 결과를 재현 할 수 있도록 컬렉션을 자세히 설명합니다.
Google Research에서 지정된 Wikipedia 데이터 추출 프로세스를 따르는 것이 좋습니다. "권장 사전 처리는 최신 덤프를 다운로드하고 Wikiextractor.py를 사용하여 텍스트를 추출한 다음 필요한 텍스트로 변환하는 것이 좋습니다."
wikiextractor를 사용할 때 --json 인수를 사용하는 것이 좋습니다. Wikiextractor는 Wikipedia 데이터를 Loose JSON 형식 (한 줄 당 JSON 객체 1 개)으로 덤프하여 파일 시스템에서 더 관리하기 쉽고 CodeBase에서 쉽게 소비 할 수 있습니다. NLTK 구두점 표준화 로이 JSON 데이터 세트를 추가로 전처리하는 것이 좋습니다. Bert Training의 경우, 생성 된 인덱스에 문장 브레이크를 포함시키기 위해 위에서 설명한대로 --split-sentences 플래그를 preprocess_data.py 로 사용하십시오. GPT 교육에 Wikipedia 데이터를 사용하려면 여전히 NLTK/SPACY/FTFY로 청소해야하지만 --split-sentences 플래그를 사용하지 마십시오.
우리는 JCPeterson 및 Eukaryote31의 작업에서 공개적으로 사용 가능한 OpenWebText 라이브러리를 사용하여 URL을 다운로드합니다. 그런 다음 OpenWebText 디렉토리에 설명 된 절차에 따라 다운로드 된 모든 컨텐츠를 필터링, 청소 및 중간 복제합니다. 2018 년 10 월까지 콘텐츠에 해당하는 Reddit URL의 경우 약 37GB의 콘텐츠에 도착했습니다.
메가 트론 훈련은 약간 재현 할 수 있습니다. 이 모드를 사용하기 위해 --deterministic-mode 사용하십시오. 이는 동일한 HW 및 SW 환경에서 동일한 교육 구성이 동일한 모델 체크 포인트, 손실 및 정확도 메트릭 값을 생성해야 함을 의미합니다 (반복 시간 메트릭이 다를 수 있음).
현재 거의 동일한 훈련 실행을 생성하면서 재현성을 깨는 3 가지 알려진 메가 트론 최적화가 있습니다.
NCCL_ALGO 에 의해 지정됨)이 중요합니다. CollnetChain Ring 다음 ^NVLS 테스트 CollnetDirect Tree 이 코드는 ^NVLS 의 사용을 인정하며, 이로 인해 NCCL이 비 NVLS 알고리즘을 선택할 수 있습니다. 그 선택은 안정적 인 것 같습니다.--use-flash-attn 사용하지 마십시오.NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 도 설정해야합니다.또한, 결정은 23.12보다 최신 NGC Pytorch 컨테이너에서만 검증되었습니다. 다른 상황에서 메가 트론 훈련에서 비 정체주의를 관찰하면 문제를 열어주십시오.
다음은 Megatron을 직접 사용한 프로젝트 중 일부입니다.


