작성자: Buqian Zheng(buqianz) 및 Yongkang Huang(yongkan1)
포스터
우리는 Swift와 Metal의 딥 러닝 프레임워크인 Corgy를 구현했습니다. Corgy는 macOS 및 iOS 애플리케이션 모두에 내장될 수 있으며 훈련된 신경망을 구축하고 쉽게 평가하는 데 사용할 수 있습니다. 우리는 다양한 GPU를 사용하는 다양한 장치에서 60배 이상의 속도 향상을 달성했습니다.

Metal 2 프레임워크는 iPhone/iPad 및 Mac의 그래픽 처리 장치(GPU)에 거의 직접적으로 액세스할 수 있도록 Apple에서 제공하는 인터페이스입니다. 그래픽 외에도 Metal 2에는 다양한 종류의 Apple 장치에서 실행할 수 있는 필수 선형 대수 연산 및 신호 처리 기능에 대한 뛰어난 병렬화 지원을 제공하는 여러 라이브러리가 통합되어 있습니다. 이러한 라이브러리를 통해 우리는 다른 프레임워크에서 제공하는 훈련된 모델을 기반으로 iOS 장치에서 잘 구현된 GPU 가속 딥 러닝 모델을 구축할 수 있었습니다. 1
일반적으로 훈련된 신경망의 추론 단계는 계산 집약적입니다. 특히 레이어 수가 상당히 많거나 고해상도 이미지를 처리하는 데 필요한 시나리오에 적용되는 모델의 경우 더욱 그렇습니다. 성능을 최적화하기 위해 병렬화된 작업을 적용하는 데 적합한 엄청난 양의 행렬 계산(예: 컨볼루셔널 레이어) 이 있다는 점은 주목할 가치가 있습니다.
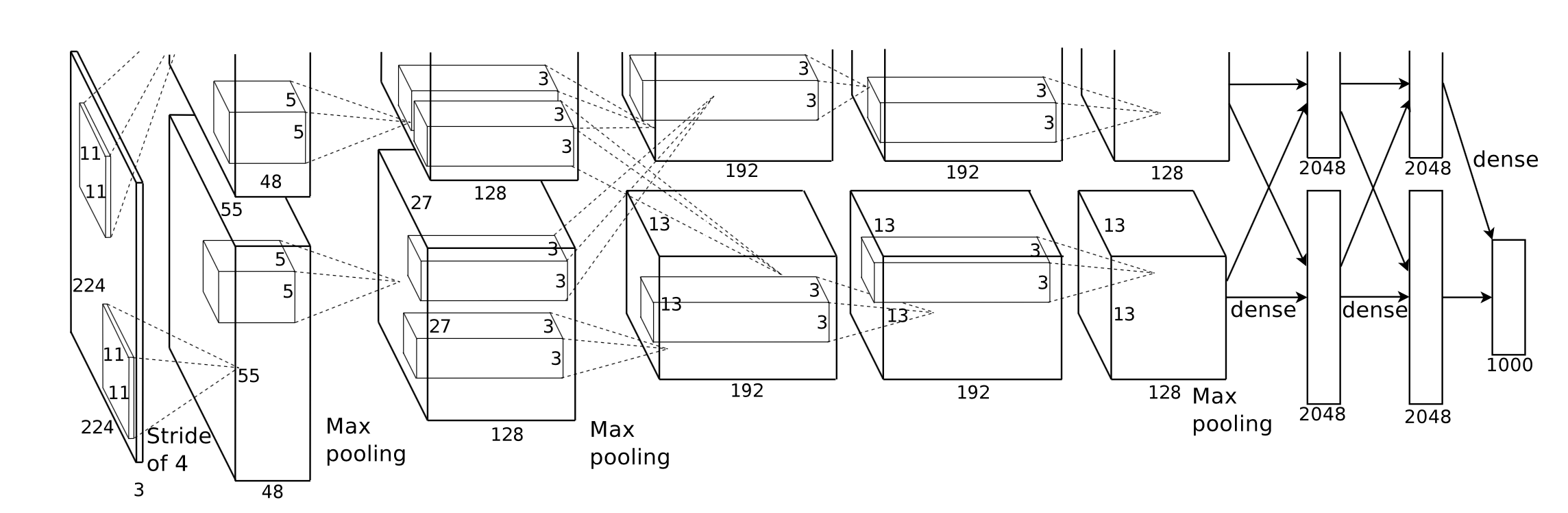
우리가 직면한 첫 번째 과제는 사용자가 사용하기 쉬운 낮은 학습 곡선으로 표현력이 뛰어나고 사용하기 쉬운 애플리케이션 프로그래밍 인터페이스의 좋은 추상화를 설계하는 것입니다.
전체 개발 프로세스 동안 우리는 공개 API를 가능한 한 단순하게 유지하면서 Swift에서 제공하는 함수형 프로그래밍 메커니즘을 활용하여 필요한 모든 구성 요소를 생성하는 데 필요한 모든 속성을 유지하기 위해 최선의 노력을 기울였습니다. 또한 학습 곡선을 원활하게 하기 위해 Metal에서 제공하는 불필요한 하드웨어 추상화를 의도적으로 숨겼습니다.
다양한 네트워크의 훈련된 모델은 인터넷에서 쉽게 얻을 수 있지만, 다양한 종류의 도구를 적용하는 서로 다른 구현으로 인해 발생하는 이들 간의 이질성으로 인해 범용 모델 임포터를 만드는 작업이 어려워졌습니다.
일부 계산은 개념적으로 이해하기 쉽지만 추상화하여 효과적인 구현을 만들려면 세심한 생각이 필요합니다. 컨볼루션(Convolution)이 대표적인 예이다.
컨볼루션 작업의 본질적인 속성은 좋은 지역성을 갖지 않으며 바닐라 구현은 이해하기 어렵고 복잡한 for 루프로 인해 비효율적입니다. 또한 Metal 2가 제공하는 추상화를 고려하고 데이터 표현과 메모리 레이아웃을 신중하게 고려하여 호스트와 장치 간에 필요한 정보와 데이터 구조를 공유하는 편리한 방법을 만들어야 합니다.
개발 단계에서 우리는 두 플랫폼 모두에서 성능 저하 없이 macOS와 iOS에서 정상적으로 실행되는 코드 기능을 신중하게 처리합니다. 우리는 두 플랫폼 모두에서 컴파일하고 실행할 수 있는 코드 라이브러리를 유지하기 위해 최선의 노력을 기울였습니다. 우리는 서로 다른 대상 간에 공유되는 코드를 최대화하고 가능한 한 코드를 재사용하는 데 주의를 기울였습니다.
신경망 계층의 완전히 구현된 구성 요소는 구성 요소를 충분히 사용할 수 있도록 하는 합리적인 양의 매개 변수를 지원해야 하기 때문에 구성 요소의 복잡성은 실제로 매우 인상적입니다. 예를 들어 컨벌루션 레이어는 패딩, 확장 보폭 등을 포함하는 매개변수를 지원해야 하며 합리적인 성능을 달성하는 병렬화를 수행할 때 이들 모두를 신중하게 고려해야 합니다. 회귀 테스트를 수행하기 위해 몇 가지 간단한 네트워크를 구축했습니다. 모든 구현이 올바르게 작동하는지 확인하기 위해 다른 프레임워크(주로 PyTorch 및 Keras)에서 테스트 케이스가 생성됩니다.
Swift는 2010년 7월에 처음 개발되어 2014년에 공개 및 오픈 소스화되었습니다. 공개된 지 거의 4년이 지났지만 영향력 있는 라이브러리의 부족은 여전히 무시할 수 없는 문제입니다. 이러한 상황이 발생한 데에는 어떤 이유가 있을 수 있는데, Apple의 지배적 역할과 Swift의 빠른 반복적 성격이 이러한 현상의 원인일 수 있습니다. 우리에게 중요한 일부 라이브러리는 우리의 요구에 부응할 만큼 강력하지 않거나 기능적이지 않거나, 이를 발명한 개별 개발자가 잘 관리하지 않습니다. 우리는 우리의 요구에 맞게 잘 작동하는 텐서 클래스 Variable 구현하는 데 많은 시간을 보냈습니다.
또한 이는 파일 및 문자열 처리 기능이 매우 제한적인 성능을 가지고 있기 때문에 범용 모델 파서의 개발을 방해하는 또 다른 이유입니다.
또한 개발 및 디버깅 도구는 기본적으로 Xcode로 제한되어 있지만 더 일반적인 다른 선택 사항이 있지만 Xcode는 여전히 우리 개발을 위한 사실상의 표준 도구입니다.
모바일 장치의 성능 조정에 대해 Apple은 SoC에 대한 자세한 하드웨어 사양을 제공하지 않으며 마케팅 이름은 미디어에서 널리 사용되며 특정 하드웨어 기능의 정확한 영향을 추론하고 구현 성능을 미세 조정하는 것은 어렵습니다. .
우리는 Swift 프로그래밍 언어, 특히 지금까지 최신 버전인 Swift 4.2를 사용하고 있습니다. Metal 2 프레임워크 및 Metal Performance Shader에서 제공하는 일부 라이브러리 함수(기본적으로 선형 대수 함수). Apple은 2017년 봄에 Convolutional Neural Network에 대한 일부 지원을 통합한 CoreML SDK를 출시했지만 Corgy에서는 이를 사용하여 네트워크 계층의 병렬 구현을 개발하는 귀중한 경험을 얻고 좋은 유용성과 원활한 학습 곡선을 갖춘 간결하고 직관적인 API를 제공하지 않습니다. 사용자가 다른 프레임워크의 모델을 쉽게 마이그레이션할 수 있습니다.
대상 컴퓨터는 iMac, MacBook, iPhone, iPad 등 macOS 및 iOS를 실행하는 모든 장치입니다. 구체적으로 MPS 선형 대수 라이브러리를 지원하는 플랫폼(예: iOS 10.0 및 macOS 10.13 이후)을 갖춘 장치입니다. 즉, iPhone은 iPhone 5 이후에 출시되고, iPad는 iPad(4세대) 이후에 출시되고, iPod Touch(6세대)가 출시된다는 의미입니다. iOS 플랫폼으로 지원됩니다. Mac 제품 라인은 2009년 말 이후에 생산된 iMac, 2010년 중반 이후 출시된 모든 MacBook 시리즈 및 iMac Pro를 포함하여 훨씬 더 폭넓은 적용 범위를 갖습니다.
Metal 2의 병렬 추상화는 CUDA와 매우 유사합니다. 컴퓨터 패스를 GPU로 보낼 때 프로그래머는 먼저 각 스레드에서 실행할 커널 함수를 작성한 다음 그리드에서 스레드 그룹(CUDA의 블록이라고도 함) 수를 지정하고 각 스레드 그룹의 스레드 수에 따라 Metal은 이 그리드에서 커널을 실행하며 커널은 Metal shading 언어라는 C++14 방언으로 구현됩니다. 각 스레드 그룹 내부에는 SIMD 그룹이라는 더 작은 단위가 있습니다. 이는 동일한 SIMD 명령어를 공유하는 스레드 묶음을 의미합니다. 그러나 우리의 구현에서는 이것을 고려할 필요가 없습니다.
Metal은 GPU에서 커밋되고 실행되는 인코딩된 명령을 저장하는 MTLCommandBuffer라는 API를 제공합니다. GPU에서 수행할 작업을 시작하려고 할 때마다 미리 컴파일된 커널 함수는 GPU 명령으로 인코딩되고 Metal shading 파이프라인에 포함되어 MTLCommandBuffer로 전송됩니다. 장치에 전달되어야 하는 계산 매개변수를 저장하는 데 사용되는 Metal 버퍼도 이 단계에서 설정됩니다. 그런 다음 지정된 수의 스레드 그룹 및 그룹당 스레드를 사용하여 명령 버퍼에서 처리되는 명령이 완전히 인코딩되고 모두 장치에 커밋되도록 설정됩니다. GPU는 작업을 예약하고 실행이 완료된 후 작업을 제출하는 CPU 스레드에 알립니다.
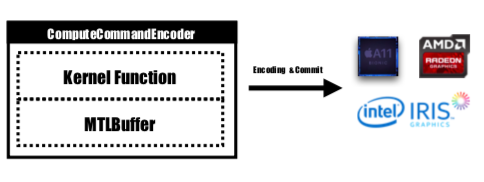
커널 기능은 MTLComputeCommandEncoder 에 의해 인코딩되며 지원되는 모든 플랫폼에 대해 작업이 생성됩니다.
구현에서 우리는 요소를 GPU 스레드에 매핑하는 직관적인 방법을 널리 활용했습니다. 즉, 현재 레이어의 출력 텐서에 있는 각 요소를 하나의 GPU 스레드에 매핑합니다. 각 스레드는 출력의 정확히 하나의 요소를 계산하고 업데이트하며 입력은 다음과 같습니다. 읽기 전용이므로 스레드 간 동기화에 대해 걱정할 필요가 없습니다. 이 매핑에서 연속 ID를 가진 스레드는 다양한 메모리 위치에서 입력 데이터를 읽을 수 있지만 항상 연속 메모리 위치에 씁니다. 따라서 SIMD 그룹이 메모리에 쓸 때 분산 작업이 발생하지 않습니다.
우리는 모든 구현의 기초로 텐서 클래스 Variable 설계했으며, 구현의 복잡성을 줄이기 위해 주요 초점이 아닌 작업을 심층적으로 다루기 위해 추가 커널을 작성하는 대신 선형 대수 연산을 Variable 클래스에 활용하고 캡슐화했습니다. 네트워크 계층을 가속화하는 데 집중할 시간을 절약합니다.
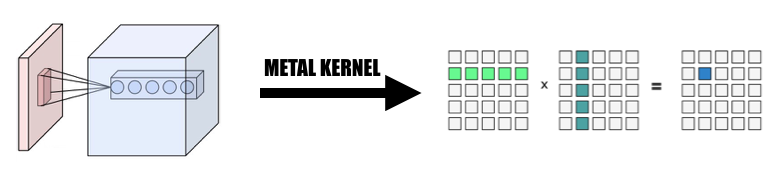
1. 컨벌루션을 거대 행렬 곱셈으로 변경
우리는 병렬화된 방식으로 입력으로부터 데이터를 수집하여 입력 변수와 가중치 모두의 거대한 행렬을 형성합니다. 재계산을 피하기 위해 각 컨볼루셔널 레이어의 가중치를 캐시합니다. 컨벌루션 레이어의 패딩은 계산 중 병렬화 변환 중에 생성된 다음 거대 행렬에 MPSMatrixMultiply를 호출하고 거대 행렬의 데이터를 우리가 만든 일반 텐서 클래스로 다시 변환합니다. 방법은 수업 슬라이드에 설명되어 있습니다.
2. Variable 클래스의 설계 및 구현
변수 클래스는 텐서 표현으로 구현하는 기초입니다. 우리는 변수에 대한 MPSMatrixMultiplication을 캡슐화했습니다(유니코드 곱셈 기호(×)를 중위 연산자로 정의하여 우아하게 표현합니다 :-)).
변수의 기본 데이터 구조는 데이터 유형을 가리키는 UnsafemutableBufferPointer 이며 단순화를 위해 32비트 Float를 선택했습니다. Variable 클래스는 두 개의 데이터 크기를 유지했는데, count 는 실제로 저장된 요소 번호를 보유하고, actualCount 는 getpagesize() 사용하여 얻은 플랫폼의 페이지 크기로 반올림된 모든 요소의 크기입니다.
makeBuffer(bytesNoCopy:) 지정된 VM 영역에 직접 버퍼를 생성하고 오버헤드를 줄이는 중복 재할당을 방지하기 위해 이 두 값을 유지합니다. Metal에 전달될 메모리가 페이지 정렬되지 않은 경우 Metal은 이 메모리를 입력 또는 출력 버퍼로 사용할 수 없습니다. 새로운 버퍼를 생성하고 입력 메모리 위치에서 데이터를 복사하는 makeBuffer(bytes:) 메소드를 사용해야 합니다. 따라서 Variable 의 모든 메모리가 페이지 정렬되도록 하려면 항상 필요한 것보다 더 많은 메모리를 할당해야 합니다. 따라서 이 메모리 덩어리의 크기와 사용해야 하는 크기를 추적하려면 두 개의 값이 필요합니다.
3. 단일 스레드가 처리하는 요소 수
우리는 하나의 스레드를 스레드당 2개에서 16개 요소까지 여러 요소에 매핑하려고 시도했지만 성능은 거의 동일하지만 프로젝트에 많은 복잡성이 추가되므로 이 접근 방식을 폐기했습니다.
아래에 언급된 모든 CPU 버전은 SIMD 최적화가 없는 순진한 단일 스레드 CPU 코드입니다. -Ofast 수준의 컴파일러 최적화가 적용됩니다.
구현 성능은 좋지만 충분하지는 않습니다.
벤치마크 플랫폼으로는 iPhone 6s와 15인치 MacBook Pro를 적용했습니다. 하드웨어는 다음과 같이 지정됩니다.
MacBook Pro(Retina 15인치, 2015년 중반)
아이폰 6S
병렬 처리가 없는 순진한 CPU 버전 구현과 비교할 때 GPU 버전은 60배 이상 빠릅니다 .
MNIST 모델은 너무 작기 때문에 결과가 정확한 속도 향상을 반영하지 못할 수 있습니다. 그리고 잘 구현된 단일 스레드 버전이 없어 정확한 속도 향상 수치를 제공할 수 없습니다. CPU 버전이 너무 느리기 때문에 Tiny YOLO의 속도 향상은 믿을 수 없을 만큼 큽니다.
실험 네트워크 속성:
MNIST:
욜로:
측정 결과:
| 아이폰 6s | MNIST | 작은 욜로 |
|---|---|---|
| CPU | 1500ms | 753s |
| GPU | 0.025초 | 0.5초 |
| 속도를 높이다 | ~60배 | ~1500x |
| 맥북 프로 | MNIST | 작은 욜로 |
|---|---|---|
| CPU | 650ms | 729 |
| GPU | 10ms | 0.028초 |
| 속도를 높이다 | ~65배 | ~26000x |
위의 벤치마크를 기반으로 문제 크기가 증가함에 따라
우리의 속도 향상이 충분하지 않다고 말하는 이유는 무엇입니까? MPSCNNConvolution 의 Apple 공식 구현과 비교할 때 속도는 약 1/3에 불과하며 이는 여전히 최적화 공간이 많다는 것을 의미합니다. 이 비교는 초당 최대 5개의 이미지를 인식할 수 있는 공식 MPSCNNConvolution 사용하여 iPhone에서 YOLO의 오픈 소스 구현을 기반으로 한 반면, 우리의 구현은 초당 최대 2개의 이미지만 달성할 수 있습니다.
그리고 제한된 시간으로 인해 벤치마크를 수행하기 위한 더 나은 기본 버전과 CPU 병렬 버전을 만들 수 없었기 때문에 속도 향상 수치가 너무 큽니다.
또한 다양한 문제 크기에 대한 성능 향상을 보고하는 것도 가치가 있습니다. 보시다시피 MNIST의 가중치는 10만 개에 불과한 반면 Tiny YOLO의 가중치는 1,700만 개입니다. Tiny YOLO는 MNIST보다 훨씬 더 복잡하지만 GPU 버전의 실행 시간은 그다지 확장되지 않았습니다. 이는 다시 암달의 법칙 때문입니다. GPU 작업이 시작될 때마다 해당 GPU 명령을 명령 버퍼로 인코딩해야 합니다. 이 프로세스는 본질적으로 연속적입니다. 문제 크기가 작은 경우 이 프로세스는 총 실행 시간에 많은 영향을 미치므로 MINST의 신경망 추론 단계를 병렬화해도 실행 시간 오버헤드가 무시할 수 있는 Tiny YOLO와 동일한 속도 향상을 얻지 못할 수 있습니다.
속도 향상을 제한하는 요인은 무엇입니까?
if s 및 for s가 있습니다.심층 분석: 다양한 단계의 실행 시간을 분석합니다.
Tiny YOLO를 예로 들어 Macbook에서 총 실행 시간이 227ms인 샘플 실행에서 컨벌루션 레이어는 총 실행 시간의 92%인 207ms를 사용했습니다. Pooling 레이어는 14ms(6%)를 사용했고, ReLU는 6ms(2%)를 사용했습니다. 암달의 법칙에 따르면, 성능을 더욱 향상시키려면 반드시 컨볼루셔널 레이어에 대한 작업을 계속해야 합니다.
전반적으로 우리는 iOS 및 macOS 장치에서 신경망 가속을 수행하기 위해 Metal 프레임워크를 선택하는 것이 타당하다고 믿습니다. 특히 iOS 장치의 경우 더욱 그렇습니다. 코어 수가 적기 때문에 SIMD 명령어를 사용하더라도 잘 조정된 CPU 버전은 GPU 버전과 유사한 성능을 얻을 가능성이 적습니다.
두 팀원 모두 동일한 작업을 수행합니다.
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


