Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript 렌더링할 수 있나요?Browser대부분의 웹사이트를 웹스크래핑하는 것은 비교적 쉬울 수 있습니다. 이 주제는 이 튜토리얼에서 이미 자세히 다루었습니다. 하지만 같은 방법으로 스크랩할 수 없는 사이트도 많습니다. 그 이유는 이러한 사이트가 JavaScript를 사용하여 동적으로 콘텐츠를 로드하기 때문입니다.
이 기술은 AJAX(Asynchronous JavaScript and XML)라고도 합니다. 역사적으로 이 표준에는 전체 페이지를 다시 로드하지 않고 웹 서버에서 XML을 검색하기 위한 XMLHttpRequest 개체를 만드는 것이 포함되었습니다. 요즘에는 이 객체를 직접 사용하는 경우가 거의 없습니다. 일반적으로 jQuery와 같은 래퍼는 JSON, 부분 HTML 또는 이미지와 같은 콘텐츠를 검색하는 데 사용됩니다.
일반 웹페이지를 스크래핑하려면 최소한 두 개의 라이브러리가 필요합니다. requests 라이브러리가 페이지를 다운로드합니다. 이 페이지를 HTML 문자열로 사용할 수 있게 되면 다음 단계는 이를 BeautifulSoup 개체로 구문 분석하는 것입니다. 그런 다음 이 BeautifulSoup 개체를 사용하여 특정 데이터를 찾을 수 있습니다.
다음은 id firstHeading 으로 설정된 h1 요소 내부의 텍스트를 인쇄하는 간단한 예제 스크립트입니다.
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert Einstein우리는 Beautiful Soup 라이브러리 버전 4로 작업하고 있습니다. 이전 버전은 단종되었습니다. Beautiful Soup 4가 단지 Beautiful Soup, BeautifulSoup 또는 bs4로 쓰여 있는 것을 볼 수 있습니다. 그들은 모두 동일한 아름다운 Soup 4 라이브러리를 참조합니다.
사이트가 동적이면 동일한 코드가 작동하지 않습니다. 예를 들어, 동일한 사이트의 https://quotes.toscrape.com/js/ 에 동적 버전이 있습니다(이 URL 끝에 js가 있음을 참고하세요).
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output 그 이유는 두 번째 사이트가 JavaScript 사용하여 데이터가 생성되는 동적 사이트이기 때문입니다.
이와 같은 사이트를 처리하는 방법에는 두 가지가 있습니다.
이 두 가지 접근 방식은 이 튜토리얼에서 자세히 다룹니다.
하지만 먼저 사이트가 동적인지 확인하는 방법을 이해해야 합니다.
Chrome이나 Edge를 사용하여 웹사이트가 동적인지 확인하는 가장 쉬운 방법은 다음과 같습니다. (이 두 브라우저 모두 내부적으로 Chromium을 사용합니다.)
F12 키를 눌러 개발자 도구를 엽니다. 초점이 개발자 도구에 있는지 확인하고 CTRL+SHIFT+P 키 조합을 눌러 명령 메뉴를 엽니다.
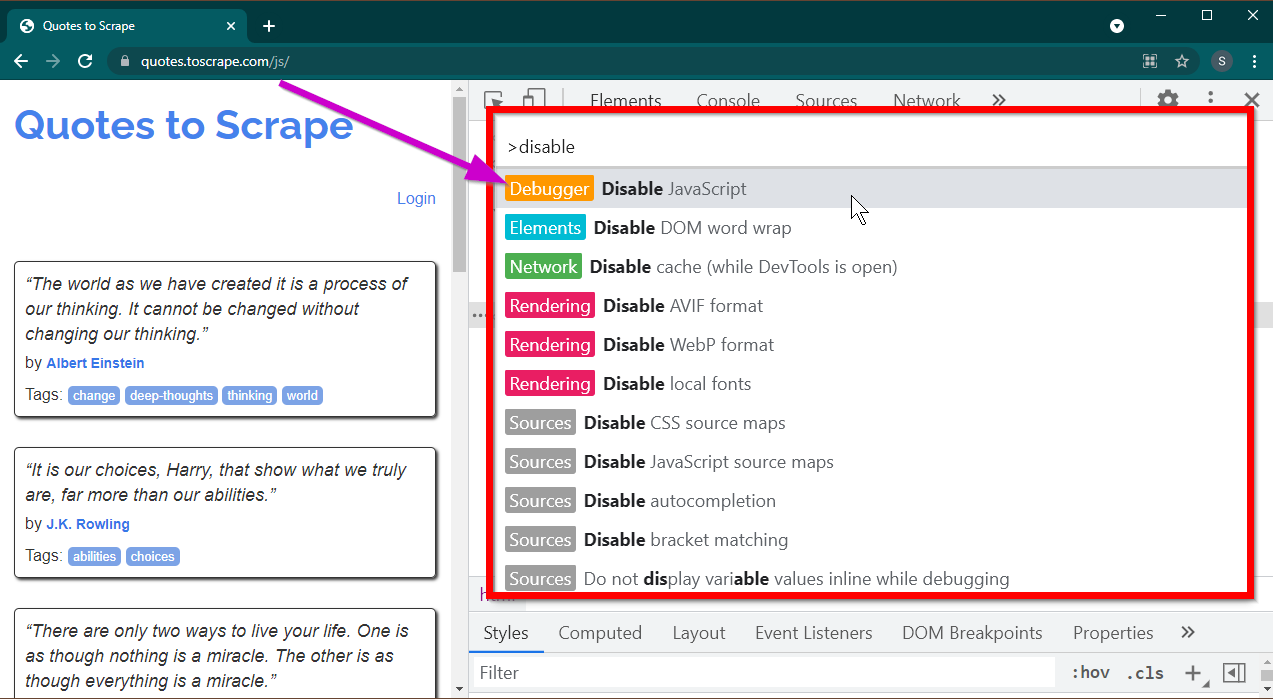
많은 명령이 표시됩니다. disable 입력하기 시작하면 명령이 필터링되어 Disable JavaScript 표시됩니다. JavaScript 비활성화하려면 이 옵션을 선택하십시오.
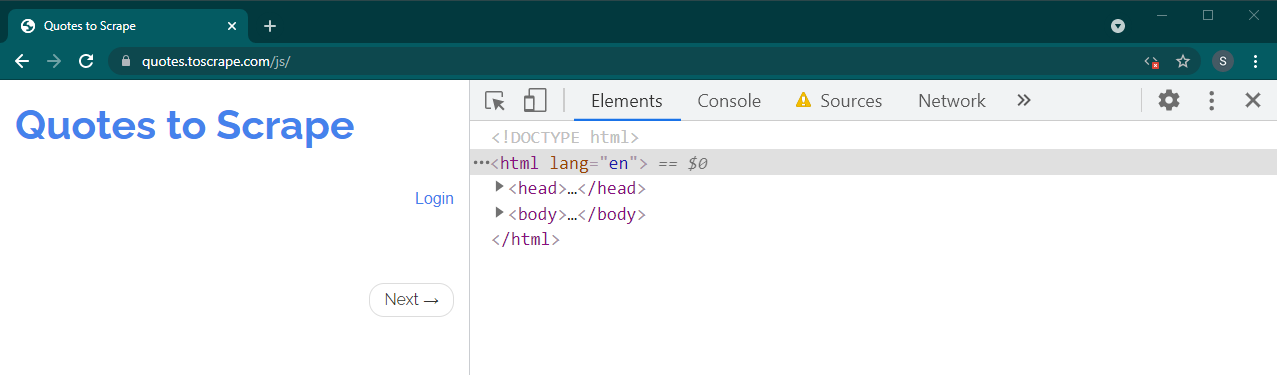
이제 Ctrl+R 또는 F5 눌러 이 페이지를 다시 로드하세요. 페이지가 다시 로드됩니다.
동적 사이트인 경우 많은 콘텐츠가 사라집니다.
어떤 경우에는 사이트에 데이터가 계속 표시되지만 기본 기능으로 되돌아갑니다. 예를 들어 이 사이트에는 무한 스크롤이 있습니다. JavaScript가 비활성화된 경우 일반 페이지 매김이 표시됩니다.
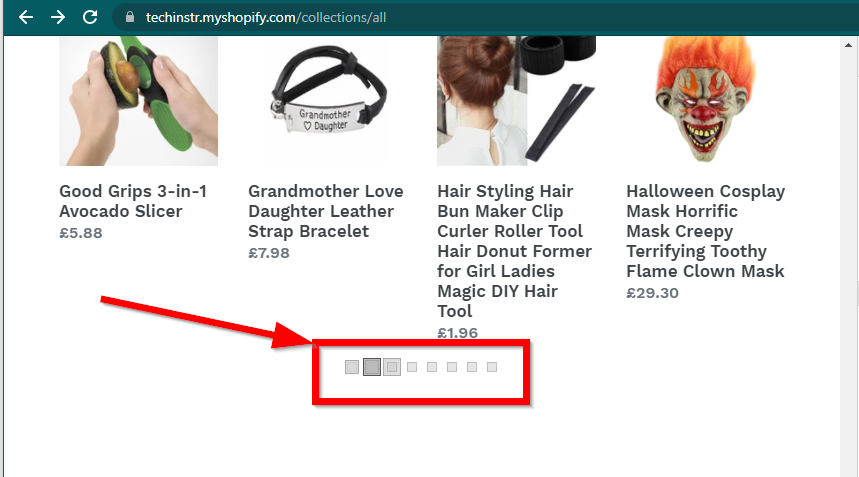 | 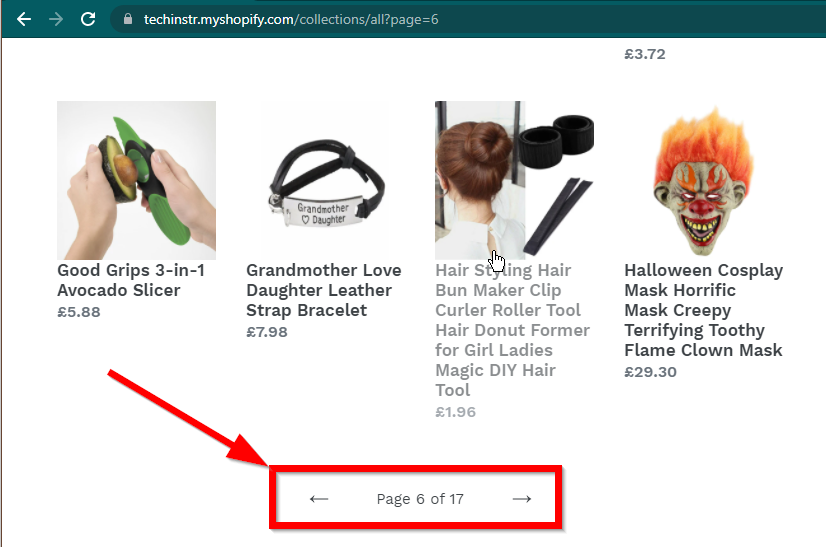 |
|---|---|
| 자바스크립트 활성화 | 자바스크립트 비활성화됨 |
대답해야 할 다음 질문은 BeautifulSoup의 기능입니다.
JavaScript 렌더링할 수 있나요?짧은 대답은 '아니요'입니다.
파싱(parsing), 렌더링(rendering)과 같은 단어를 이해하는 것이 중요합니다. 구문 분석은 단순히 Python 객체의 문자열 표현을 실제 객체로 변환하는 것입니다.
그렇다면 렌더링이란 무엇입니까? 렌더링은 본질적으로 HTML, JavaScript, CSS 및 이미지를 브라우저에서 볼 수 있는 것으로 해석하는 것입니다.
Beautiful Soup은 HTML 파일에서 데이터를 가져오는 Python 라이브러리입니다. 여기에는 HTML 문자열을 BeautifulSoup 개체로 구문 분석하는 작업이 포함됩니다. 구문 분석을 위해서는 먼저 문자열로 HTML이 필요합니다. 동적 웹사이트에는 HTML에 직접 데이터가 없습니다. 이는 BeautifulSoup이 동적 웹사이트에서 작동할 수 없음을 의미합니다.
Selenium 라이브러리는 Chrome 또는 Firefox와 같은 브라우저에서 웹사이트 로드 및 렌더링을 자동화할 수 있습니다. Selenium은 HTML에서 데이터를 가져오는 것을 지원하지만 완전한 HTML을 추출하고 대신 Beautiful Soup을 사용하여 데이터를 추출하는 것이 가능합니다.
먼저 Selenium을 사용하여 Python으로 동적 웹 스크래핑을 시작해 보겠습니다.
Selenium 설치에는 다음 세 가지 설치가 포함됩니다.
선택한 브라우저(이미 보유하고 있음):
브라우저용 드라이버:
Python 셀레늄 패키지:
pip install seleniumconda-forge 채널에서 설치할 수 있습니다. conda install -c conda-forge selenium 브라우저를 시작하고 페이지를 로드한 다음 브라우저를 닫는 Python 스크립트의 기본 골격은 간단합니다.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()이제 브라우저에 페이지를 로드할 수 있으므로 특정 요소를 추출하는 방법을 살펴보겠습니다. 요소를 추출하는 방법에는 Selenium과 Beautiful Soup의 두 가지 방법이 있습니다.
이 예제의 목표는 작성자 요소를 찾는 것입니다.
Chrome에서 https://quotes.toscrape.com/js/ 사이트를 로드하고 작성자 이름을 마우스 오른쪽 버튼으로 클릭한 다음 검사를 클릭합니다. 그러면 다음과 같이 강조 표시된 작성자 요소와 함께 개발자 도구가 로드됩니다.
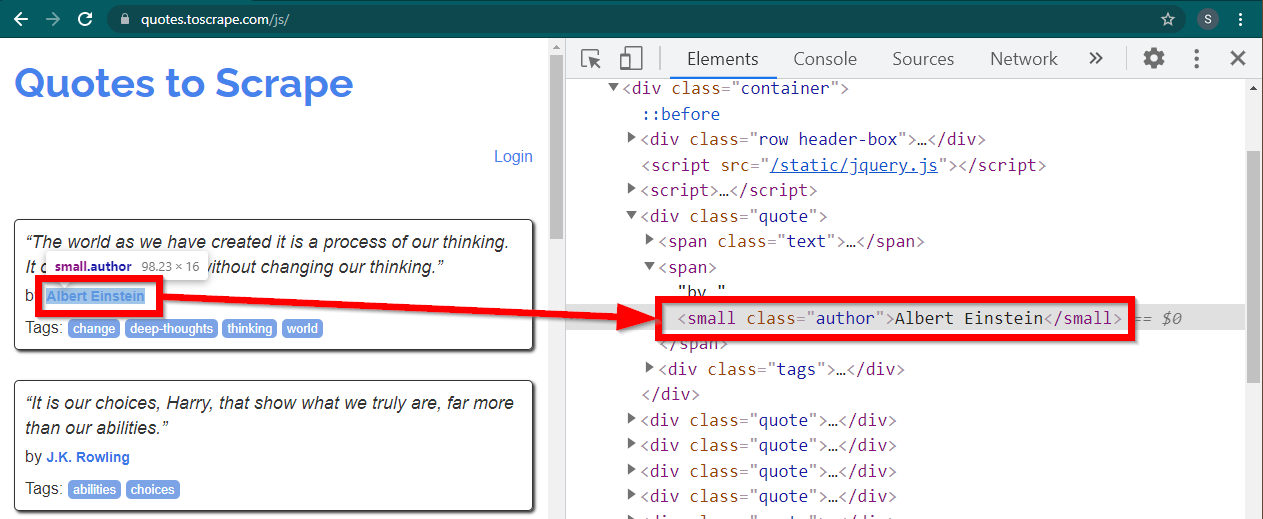
이는 class 속성이 author 로 설정된 small 요소입니다.
< small class =" author " > Albert Einstein </ small >Selenium을 사용하면 다양한 방법으로 HTML 요소를 찾을 수 있습니다. 이러한 메서드는 드라이버 개체의 일부입니다. 여기서 유용할 수 있는 몇 가지 방법은 다음과 같습니다.
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )다른 방법은 거의 없으며 다른 시나리오에 유용할 수 있습니다. 이러한 방법은 다음과 같습니다.
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) 아마도 가장 유용한 방법은 find_element(By.CSS_SELECTOR) 및 find_element(By.XPATH) 입니다. 이 두 가지 방법 중 하나를 사용하면 대부분의 시나리오를 선택할 수 있습니다.
제1저자가 인쇄될 수 있도록 코드를 수정해 보겠습니다.
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()모든 저자를 인쇄하려면 어떻게 해야 합니까?
모든 find_element 메소드에는 대응되는 find_elements 있습니다. 복수형에 주목하세요. 모든 저자를 찾으려면 한 줄만 바꾸면 됩니다.
elements = driver . find_elements ( By . CLASS_NAME , "author" )그러면 요소 목록이 반환됩니다. 간단히 루프를 실행하여 모든 작성자를 인쇄할 수 있습니다.
for element in elements :
print ( element . text )참고: 전체 코드는 selenium_example.py 코드 파일에 있습니다.
그러나 이미 BeautifulSoup에 익숙하다면 BeautifulSoup 객체를 생성할 수 있습니다.
첫 번째 예에서 보았듯이 Beautiful Soup 객체에는 HTML이 필요합니다. 웹 스크래핑 정적 사이트의 경우 requests 라이브러리를 사용하여 HTML을 검색할 수 있습니다. 다음 단계는 이 HTML 문자열을 BeautifulSoup 개체로 구문 분석하는 것입니다.
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )BeautifulSoup으로 동적 웹사이트를 스크래핑하는 방법을 알아봅시다.
다음 부분은 이전 예와 변경되지 않았습니다.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) 페이지의 렌더링된 HTML은 page_source 속성에서 사용할 수 있습니다.
soup = BeautifulSoup ( driver . page_source , "lxml" )수프 객체를 사용할 수 있게 되면 모든 Beautiful Soup 메소드를 평소대로 사용할 수 있습니다.
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )참고: 전체 소스 코드는 selenium_bs4.py에 있습니다.
Browser스크립트가 준비되면 스크립트가 실행될 때 브라우저가 표시될 필요가 없습니다. 브라우저를 숨길 수 있으며 스크립트는 계속해서 정상적으로 실행됩니다. 브라우저의 이러한 동작을 헤드리스 브라우저라고도 합니다.
브라우저를 헤드리스로 만들려면 ChromeOptions 가져옵니다. 다른 브라우저의 경우 자체 옵션 클래스를 사용할 수 있습니다.
from selenium . webdriver import ChromeOptions 이제 이 클래스의 객체를 생성하고 headless 속성을 True로 설정합니다.
options = ChromeOptions ()
options . headless = True마지막으로 Chrome 인스턴스를 생성하는 동안 이 개체를 보냅니다.
driver = Chrome ( ChromeDriverManager (). install (), options = options )이제 스크립트를 실행하면 브라우저가 표시되지 않습니다. 전체 구현은 selenium_bs4_headless.py 파일을 참조하세요.
브라우저를 로드하는 데는 비용이 많이 듭니다. 실제로 필요하지 않은 CPU, RAM 및 대역폭을 차지합니다. 웹사이트를 스크랩할 때 중요한 것은 데이터입니다. 모든 CSS, 이미지 및 렌더링은 실제로 필요하지 않습니다.
Python으로 동적 웹 페이지를 스크랩하는 가장 빠르고 효율적인 방법은 데이터가 있는 실제 장소를 찾는 것입니다.
이 데이터를 찾을 수 있는 위치는 두 곳입니다.
<script> 태그에 포함된 JSON 형식의 기본 페이지 자체몇 가지 예를 살펴보겠습니다.
Chrome에서 https://quotes.toscrape.com/js를 엽니다. 페이지가 로드되면 Ctrl+U를 눌러 소스를 확인하세요. Ctrl+F를 눌러 검색창을 열고 Albert를 검색하세요.
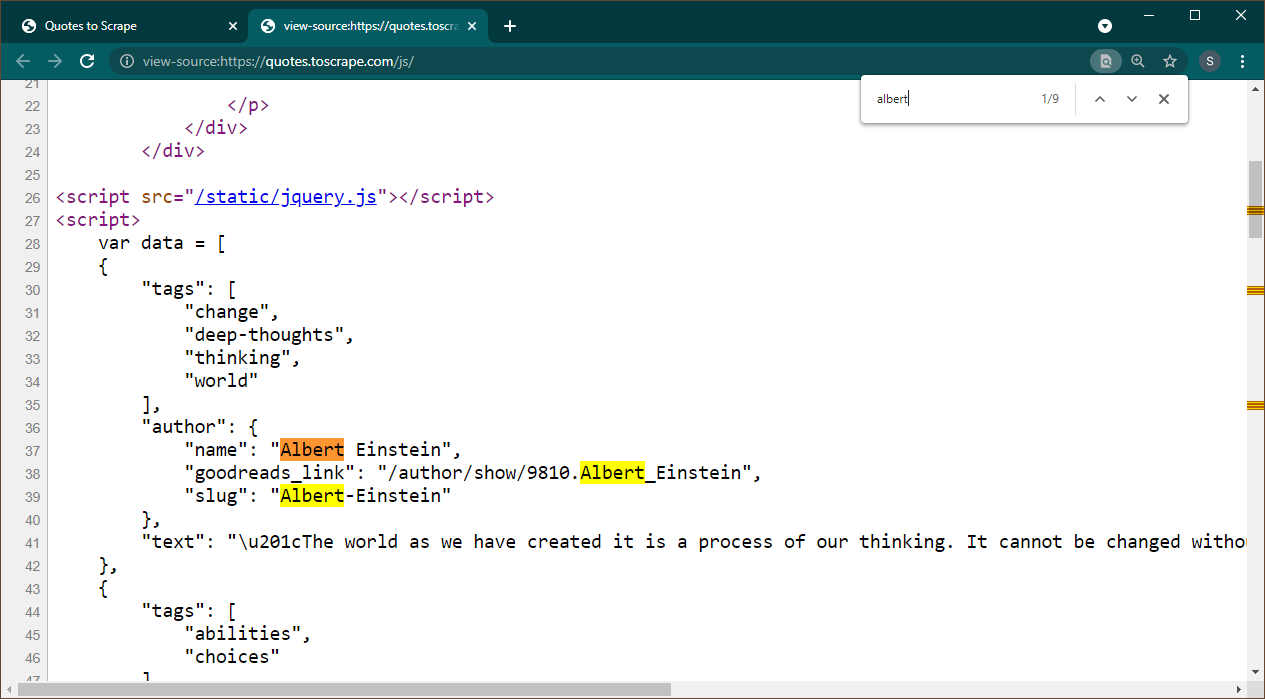
데이터가 페이지에 JSON 개체로 포함되어 있음을 즉시 확인할 수 있습니다. 또한 이는 이 데이터가 변수 data 에 할당되는 스크립트의 일부입니다.
이 경우 요청 라이브러리를 사용하여 페이지를 가져오고 Beautiful Soup을 사용하여 페이지를 구문 분석하고 스크립트 요소를 가져올 수 있습니다.
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) <script> 요소가 여러 개 있다는 점에 유의하세요. 필요한 데이터가 포함된 데이터에는 src 속성이 없습니다. 이를 사용하여 스크립트 요소를 추출해 보겠습니다.
script_tag = soup . find ( "script" , src = None )이 스크립트에는 우리가 관심 있는 데이터 외에 다른 JavaScript 코드가 포함되어 있다는 점을 기억하세요. 이러한 이유로 우리는 이 데이터를 추출하기 위해 정규식을 사용할 것입니다.
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )데이터 변수는 하나의 항목을 포함하는 목록입니다. 이제 JSON 라이브러리를 사용하여 이 문자열 데이터를 Python 개체로 변환할 수 있습니다.
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )출력은 Python 객체가 됩니다.
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................이 목록은 필요에 따라 어떤 형식으로도 변환할 수 없습니다. 또한 각 항목에는 작성자 페이지에 대한 링크가 포함되어 있습니다. 이는 이러한 링크를 읽고 스파이더를 생성하여 모든 페이지에서 데이터를 얻을 수 있음을 의미합니다.
이 전체 코드는 data_in_same_page.py에 포함되어 있습니다.
웹 스크래핑 동적 사이트는 완전히 다른 경로를 따를 수 있습니다. 때로는 데이터가 별도의 페이지에 완전히 로드되는 경우도 있습니다. 그러한 예 중 하나가 Librivox입니다.
개발자 도구를 열고 네트워크 탭으로 이동하여 XHR로 필터링하세요. 이제 이 링크를 열거나 책을 검색해 보세요. 데이터가 JSON에 포함된 HTML임을 알 수 있습니다.
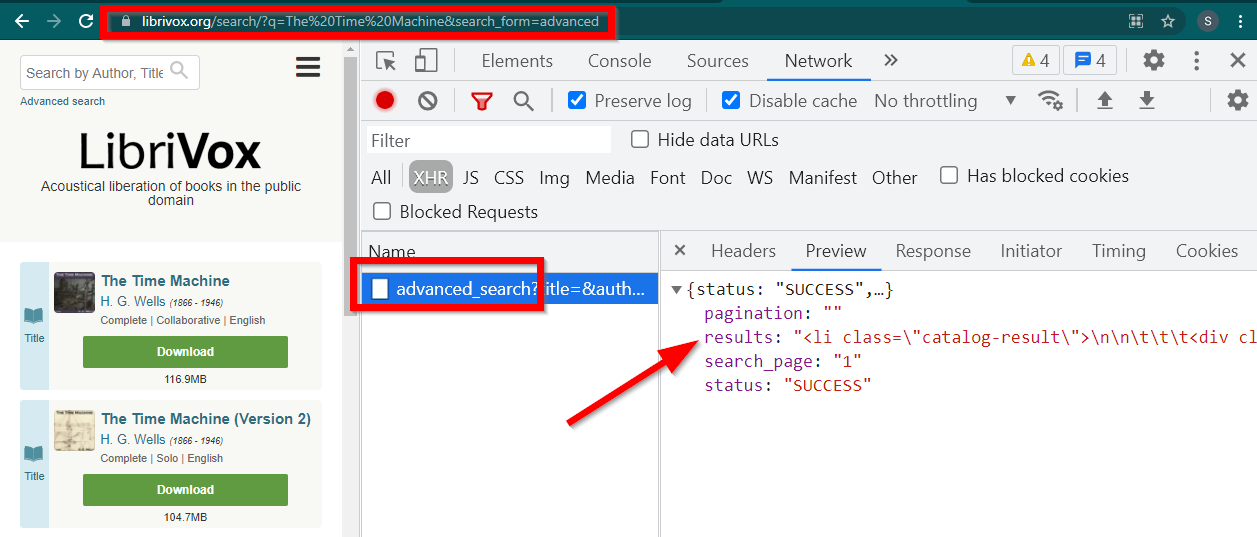
몇 가지 사항에 유의하세요.
브라우저에 표시되는 URL은 https://librivox.org/search/?q=... 입니다.
데이터는 https://librivox.org/advanced_search?.... 에 있습니다.
헤더를 보면 Advanced_search 페이지에 특수 헤더 X-Requested-With: XMLHttpRequest 전송되는 것을 알 수 있습니다.
다음은 이 데이터를 추출하는 스니펫입니다.
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )전체 코드는 librivox.py 파일에 포함되어 있습니다.


