disclosure backend static
1.0.0
disclosure-backend-static 저장소는 Open Disclosure California를 지원하는 백엔드입니다.
이는 2016년 선거를 앞두고 서둘러 만들어졌으며 "완료" 철학을 중심으로 설계되었습니다. 그 당시 우리는 이미 API를 설계하고 (대부분) 프런트엔드를 구축했습니다. 이 저장소는 가능한 한 빨리 이를 구현하기 위해 만들어졌습니다.
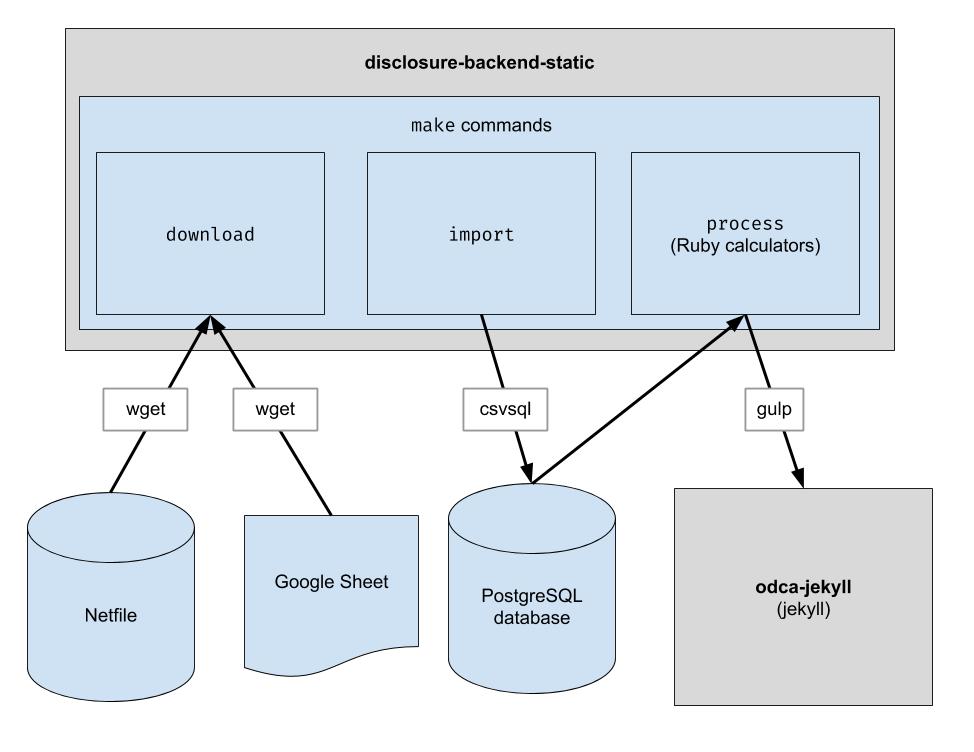
이 프로젝트는 오클랜드 넷파일 데이터를 다운로드하고, 오클랜드에 대해 사람이 선별한 CSV 데이터를 다운로드하고, 두 가지를 결합하는 기본 ETL 파이프라인을 구현합니다. 출력은 기존 API 구조를 모방하는 JSON 파일의 디렉터리이므로 클라이언트 코드 변경이 필요하지 않습니다.
.ruby-version 의 버전 참조) 참고: 프런트엔드에서 개발하기 위해 이러한 명령을 실행할 필요는 없습니다. 당신이 해야 할 일은 프런트엔드 저장소에 인접한 저장소를 복제하는 것뿐입니다.
백엔드 코드를 수정하려는 경우 다음 단계에 따라 새로운 PostgreSQL 데이터베이스 및 Python 3을 포함하여 필요한 모든 개발 종속성을 설정하세요.
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
pip 대신 python3 -m pip 사용하세요. python3 -m pip install ...
pip Python 3을 가리키는 경우 pip 직접 사용할 수 있습니다. pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
이 저장소는 Codespaces 아래의 컨테이너에서 작동하도록 설정되었습니다. 즉, 로컬 환경을 설정하는 데 필요한 설치 단계를 수행할 필요 없이 이미 설정된 환경을 시작할 수 있습니다. 이는 코드가 프로덕션 파이프라인에 커밋되기 전에 문제를 해결하는 방법으로 사용될 수 있습니다. 다음 정보는 Codespaces 사용을 시작하는 데 도움이 될 수 있습니다.
Code 버튼을 클릭하고 드롭다운에서 Codespaces 탭을 클릭하세요./workspace 의 터미널 프롬프트가 웹 페이지에 표시될 때까지 기다립니다. 이전에 VS Code를 사용해 본 적이 있다면 익숙해 보일 것입니다.make download 와 같은 다음 섹션의 명령 실행을 시작할 수 있습니다.psql 입력하여 서버에 연결할 수 있습니다.make import 명령은 Postgres 데이터베이스를 채웁니다.git push 를 수행하지 않으면 GitHub 저장소에 저장되지 않습니다.이 리포지토리는 Docker 컨테이너 내에서 실행되도록 구성되어 있습니다. 이는 원하는 IDE 및 로컬 설정을 사용할 수 있다는 점을 제외하면 Codespaces와 유사합니다. VSCode와 함께 Docker 사용을 시작하는 방법은 다음과 같습니다.
원시 데이터 파일을 다운로드합니다. 최신 데이터를 얻으려면 가끔씩만 이 작업을 실행하면 됩니다.
$ make download
더 쉬운 처리를 위해 데이터를 데이터베이스로 가져옵니다. 새 데이터를 다운로드한 후에만 이 작업을 실행하면 됩니다.
$ make import
계산기를 실행하세요. 모든 것이 "build" 폴더에 출력됩니다.
$ make process
선택적으로 빌드 출력을 Algolia로 다시 인덱싱합니다. (재인덱싱에는 ALGOLIASEARCH_APPLICATION_ID 및 ALGOLIASEARCH_API_KEY 환경 변수가 필요합니다.)
$ make reindex
로컬 웹 서버를 통해 정적 JSON 파일을 제공하려면 다음을 수행하세요.
$ make run
make import 실행되면 다운로드한 데이터를 가져오기 위해 여러 개의 postgres 테이블이 생성됩니다. 이러한 테이블의 스키마는 dbschema 디렉토리에 명시적으로 정의되어 있으며 향후 데이터를 수용하기 위해 나중에 업데이트해야 할 수도 있습니다. 문자열 데이터를 보유하는 열의 크기는 향후 데이터에 비해 충분히 크지 않을 수 있습니다. 예를 들어 이름 열이 최대 20자의 이름을 허용하고 나중에 이름 길이가 21자인 데이터가 있는 경우 데이터 가져오기가 실패합니다. 이런 일이 발생하면 더 많은 문자를 지원하도록 dbschema 의 해당 스키마 파일을 업데이트해야 합니다. 간단히 변경하고 make import 다시 실행하여 성공하는지 확인하세요.
이 저장소는 웹사이트에서 사용되는 데이터 파일을 생성하는 데 사용됩니다. make process 실행된 후 데이터 파일이 포함된 build 디렉터리가 생성됩니다. 이 디렉터리는 저장소에 체크인되고 나중에 웹 사이트를 생성할 때 체크아웃됩니다. 코드를 변경한 후에는 생성된 build 디렉터리를 코드 변경 전에 생성된 build 디렉터리와 비교하고 코드 변경으로 인한 변경 사항이 예상한 대로인지 확인하는 것이 중요합니다.
build 디렉터리의 모든 콘텐츠를 엄격하게 비교하면 항상 코드 변경과 관계없이 발생하는 변경 사항이 포함되므로 모든 개발자는 이 검사를 수행하기 위해 예상되는 변경 사항에 대해 알아야 합니다. 이에 대한 필요성을 제거하려면 특정 파일 bin/create-digests.py 가 예상되는 변경 사항을 제외시킨 후 build 디렉터리에 JSON 데이터에 대한 다이제스트를 생성합니다. 예상되는 변경 사항을 제외한 변경 사항을 찾으려면 build/digests.json 파일에서 변경 사항을 찾으세요.
현재 다음은 코드 변경과 관계없이 발생할 것으로 예상되는 변경 사항입니다.
build 디렉터리의 데이터에 대한 다이제스트를 생성하기 전에 예상되는 변경 사항이 제외됩니다. 이에 대한 논리는 bin/create-digests.py 파일에 있는 clean_data 함수에서 찾을 수 있습니다. 예상되는 변경 사항이 더 이상 존재하지 않도록 코드가 수정된 후에는 clean_data 에서 해당 변경 사항의 제외를 제거할 수 있습니다. 예를 들어, 환경의 차이로 인해 make process 실행될 때마다 float의 반올림이 일관되게 동일하지 않습니다. 데이터가 변경되지 않는 한 float의 반올림이 동일하도록 코드가 수정되면 clean_data 의 round_float 호출을 제거할 수 있습니다.
후보자의 합계를 비교할 수 있는 보고서를 생성하기 위해 추가 스크립트가 생성되었습니다. 스크립트는 bin/report-candidates.py 이며 build/candidates.csv 및 build/candidates.xlsx 생성합니다. 보고서에는 모든 후보자 목록과 합산하여 동일한 숫자가 되어야 하는 여러 가지 방법으로 계산된 총계가 포함됩니다.
데이터베이스 스키마 변경 사항이 풀 요청에 표시되도록 하기 위해 전체 postgres 스키마가 build 디렉터리의 schema.sql 파일에도 저장됩니다. PR의 각 분기에 대해 build 디렉터리가 자동으로 다시 빌드되고 리포지토리에 커밋되므로 코드 변경으로 인해 발생한 스키마 변경 사항은 PR을 검토할 때 schema.sql 파일에 차이점이 표시됩니다.
후보자에 대한 각 지표는 독립적으로 계산됩니다. 측정항목은 "받은 총 기부금"과 같은 것일 수도 있고 "100달러 미만의 기부금 비율"과 같은 더 복잡한 것일 수도 있습니다.
새로운 계산을 추가할 때 가장 먼저 공식 양식 460부터 시작하는 것이 좋습니다. 찾고 있는 데이터가 해당 양식에 보고되어 있습니까? 그렇다면 가져오기 프로세스 후에 데이터베이스에서 해당 항목을 찾을 수 있을 것입니다. Form 496과 같이 우리가 가져오는 몇 가지 다른 양식도 있습니다. ( input 디렉터리에 있는 파일의 이름입니다. 확인해 보세요.)
각 양식의 각 일정은 별도의 postgres 테이블로 가져옵니다. 예를 들어, 양식 460의 스케줄 A를 A-Contributions 테이블로 가져옵니다.
이제 데이터를 쿼리하는 방법이 있으므로 얻으려는 값을 계산하는 SQL 쿼리를 작성해야 합니다. 계산을 SQL로 표현할 수 있으면 다음과 같이 계산기 파일에 넣으세요.
calculators/[your_thing]_calculator.rb 라는 새 파일을 만듭니다. # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID 열을 선택하는지 확인해야 합니다.candidate.save_calculation 호출을 업데이트하세요. 해당 메서드는 두 번째 인수를 JSON으로 직렬화하므로 모든 종류의 데이터를 저장할 수 있습니다.candidate.calculation(:your_thing) 으로 검색할 수 있습니다. 이것을 process.rb 파일의 API 응답에 추가하고 싶을 것입니다. 이것이 데이터가 백엔드를 통해 흐르는 방식입니다. 재무 데이터는 후보자 이름, 사무실, 투표 법안 등과 같은 투표 정보에 파일러 ID를 매핑하는 Google 시트로 보완되는 Netfile에서 가져옵니다. 일단 데이터가 필터링, 집계 및 변환되면 프런트 엔드에서 이를 사용하고 정적 HTML을 구축합니다. 프런트 엔드.
번들 설치 중
error: use of undeclared identifier 'LZMA_OK'
노력하다:
brew unlink xz
bundle install
brew link xz
make download 동안
wget: command not found
brew install wget 실행하십시오.
make import 동안
Apple Chip을 사용하는 Macintosh 시스템에 문제가 있는 것 같습니다.
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
다음을 시도해 보세요:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


