imagen pytorch
2.1.0
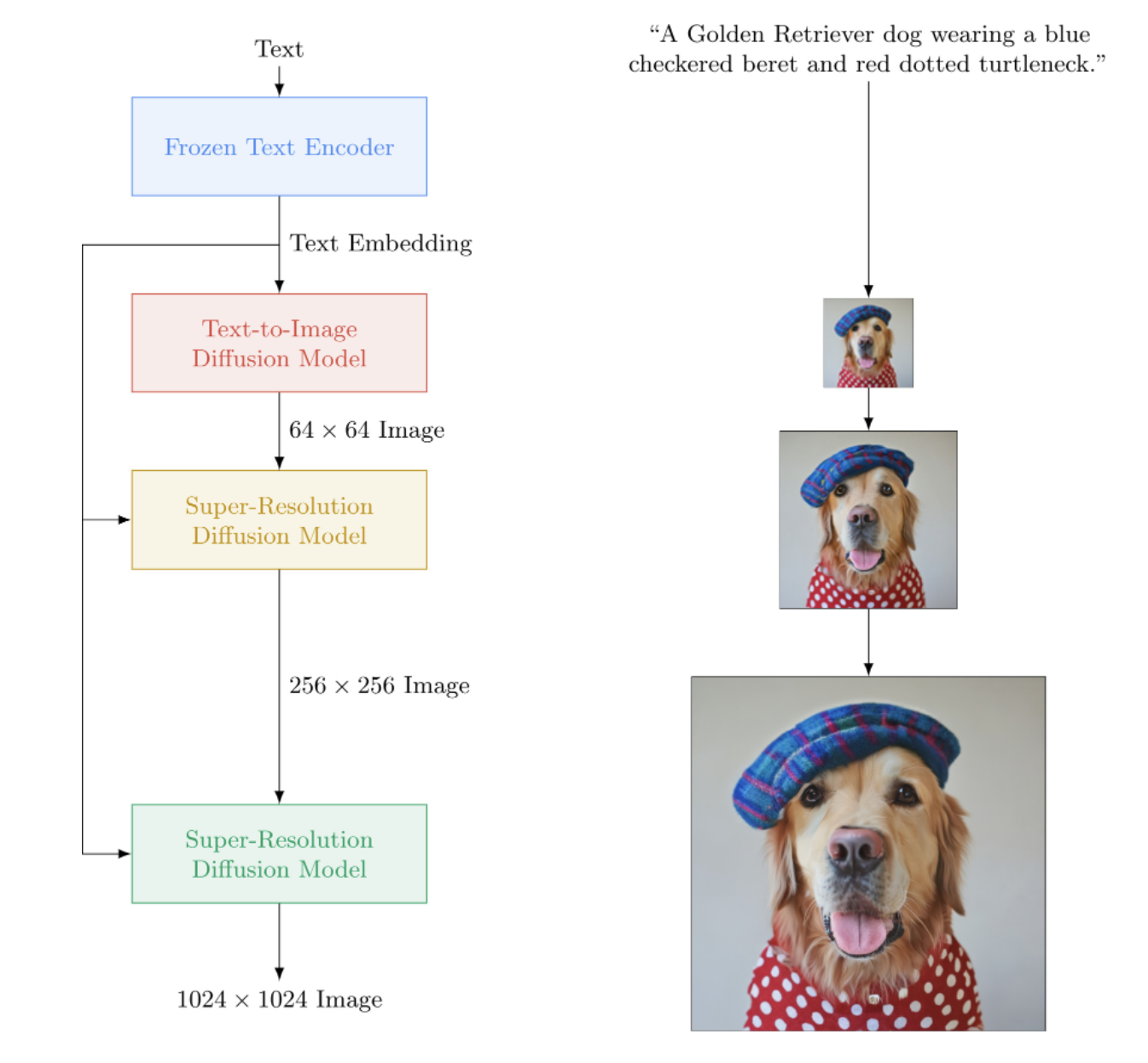
Pytorch에서 DALL-E2를 능가하는 Google의 텍스트-이미지 신경망인 Imagen을 구현합니다. 텍스트-이미지 합성을 위한 새로운 SOTA입니다.
구조적으로는 실제로 DALL-E2보다 훨씬 간단합니다. 이는 미리 훈련된 대규모 T5 모델(주의 네트워크)의 텍스트 임베딩을 조건으로 하는 계단식 DDPM으로 구성됩니다. 또한 향상된 분류자 없는 안내, 잡음 수준 조절 및 메모리 효율적인 unet 설계를 위한 동적 클리핑이 포함되어 있습니다.
결국 CLIP이나 사전 네트워크가 필요하지 않은 것 같습니다. 그래서 연구가 계속됩니다.
Letitia와 함께하는 AI 커피 브레이크 | 조립 AI | 야닉 킬처
LAION 커뮤니티와 함께 복제 작업에 도움을 주고 싶으시다면 가입해 주세요.
넉넉한 후원을 위한 StabilityAI와 저의 다른 후원자들
? 놀라운 트랜스포머 라이브러리를 위한 Huggingface. 텍스트 인코더 부분은 그 때문에 거의 관리됩니다.
자신의 논문을 통해 생성 인공 지능에 혁명을 가져온 조나단 호(Jonathan Ho)
이 저장소가 분산 교육에 사용하는 Accelerate 라이브러리의 Sylvain 및 Zachary
Einops용 Alex, 텐서 조작에 없어서는 안 될 도구
T5 로딩 코드에 도움을 주고 올바른 T5 버전에 대한 조언을 주신 Jorge Gomes
Katherine Crowson, 가우스 확산의 연속 시간 버전을 이해하는 데 도움이 된 아름다운 코드
코드 검토, 실험 결과 공유 및 디버깅 지원을 위한 Marunine 및 Netruk44
메모리 효율적인 u-net의 색상 이동 문제에 대한 잠재적인 솔루션을 제공하는 Marunine. 기본 및 메모리 효율적인 unets 간의 실험적 비교를 공유해 주신 Jacob에게 감사드립니다.
수많은 버그를 발견하고, 크기 조정 문제를 해결하고, 실험 구성 및 결과를 공유한 Marunine
체크보드 아티팩트를 수정하기 위해 픽셀 셔플 업샘플러 사용을 제안한 MalumaDev
unet의 불충분한 건너뛰기 연결을 지적한 Valentin과 부록의 base-unet에서 주의 조건을 조절하는 구체적인 방법
추론 시 연속 시간 가우스 확산 노이즈 레벨 컨디셔닝으로 큰 버그를 잡아낸 BIGJUN
저해상도 조절 이미지를 사용하여 샘플링 및 정규화 순서와 노이즈를 사용하여 버그를 식별하는 Bingbing
Imagen의 한 줄 명령 훈련에 기여한 Kay!
의료 데이터 세트에서 텍스트-비디오를 테스트하고 결과를 공유하며 문제를 식별한 Hadrien Reynaud!
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)더 간단한 훈련을 위해 텍스트 인코딩을 미리 계산하는 대신 텍스트 문자열을 직접 제공할 수 있습니다. (확장을 위해 텍스트 임베딩 + 마스크를 미리 계산하는 것이 좋습니다)
이 경로를 사용하는 경우 텍스트 캡션 수는 이미지의 배치 크기와 일치해야 합니다.
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () ImagenTrainer 래퍼 클래스를 사용하면 계단식 DDPM의 모든 U-net에 대한 지수 이동 평균이 update 호출할 때 자동으로 처리됩니다.
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)다음과 같이 텍스트 없이 Imagen을 훈련할 수도 있습니다(무조건 이미지 생성).
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)아니면 초고해상도 유닛만 훈련하세요.
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) 언제든지 save 및 load 방법을 사용하여 트레이너 및 모든 관련 상태를 저장하고 로드할 수 있습니다. 트레이너 내부에서 일부 장치 메모리 관리가 수행되므로 state_dict 호출을 통해 수동으로 저장하는 대신 이러한 방법을 사용하는 것이 좋습니다.
전.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 ImagenTrainer 사용하여 DataLoader 인스턴스를 자동으로 훈련할 수도 있습니다. images (무조건적인 경우) 또는 텍스트 안내 생성을 위한 ('images', 'text_embeds') 이미지를 반환하도록 DataLoader 작성하기만 하면 됩니다.
전. 무조건적인 훈련
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )덕분에? 가속, 두 단계로 쉽게 멀티 GPU 훈련을 할 수 있습니다.
먼저 훈련 스크립트와 동일한 디렉터리에서 accelerate config 호출해야 합니다(예: 이름이 train.py ).
$ accelerate config 다음으로, 단일 GPU에서처럼 python train.py 호출하는 대신 가속 CLI를 사용합니다.
$ accelerate launch train.py그게 다야!
Imagen은 CLI를 통해 직접 사용할 수도 있습니다.
전.
$ imagen config또는
$ imagen config --path ./configs/config.json구성에서 트레이너, 데이터 세트 및 imagen 구성에 대한 설정을 변경할 수 있습니다.
Imagen 구성 매개변수는 여기에서 찾을 수 있습니다.
Elucidated Imagen 구성 매개변수는 여기에서 찾을 수 있습니다.
Imagen Trainer 구성 매개변수는 여기에서 찾을 수 있습니다.
데이터세트 매개변수의 경우 모든 데이터로더 매개변수를 사용할 수 있습니다.
이 명령을 사용하면 모델을 훈련하거나 훈련을 재개할 수 있습니다.
전.
$ imagen train또는
$ imagen train --unet 2 --epoches 10훈련 명령에 다음 인수를 전달할 수 있습니다.
--config 훈련에 사용할 구성 파일을 지정합니다. [기본값: ./imagen_config.json]--unet 훈련할 unet의 인덱스 [기본값: 1]--epoches [기본값: 50]체크포인트를 샘플링할 때 사용 가능한 결과를 얻으려면 모든 unets를 교육해야 합니다.
전.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.png샘플 명령에 다음 인수를 전달할 수 있습니다.
--model 샘플링에 사용할 모델 파일을 지정합니다.--cond_scale 조건 조정 규모(분류자 자유 지침)(디코더)--load_ema 가능한 경우 unets의 EMA 버전을 로드합니다. 이 기능과 함께 저장된 체크포인트를 사용하려면 구성 클래스, ImagenConfig 및 ElucidatedImagenConfig 사용하여 Imagen 인스턴스를 인스턴스화하거나 CLI를 통해 직접 체크포인트를 생성해야 합니다.
적절한 교육을 위해서는 어쨌든 구성 기반 교육을 설정하는 것이 좋습니다.
전.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminal정말 그렇게 간단해야합니다
또한 이 체크포인트 파일을 전달할 수 있으며 누구나 자신의 데이터를 계속해서 미세 조정할 수 있습니다.
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning Inpainting은 최근 Repaint 논문에서 제시한 공식을 따릅니다. inpaint_images 및 inpaint_masks Imagen 또는 ElucidatedImagen 의 sample 함수에 전달하기만 하면 됩니다.
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) 비디오의 경우 마찬가지로 .sample 의 inpaint_videos 키워드에 비디오를 전달합니다. 인페인팅 마스크는 모든 프레임 (batch, height, width) 에서 동일하거나 다를 수 있습니다 (batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) StyleGAN으로 유명한 Tero Karras가 내 컴퓨터뿐만 아니라 여러 독립적인 연구자에 의해 확증된 결과를 담은 새로운 논문을 작성했습니다. 나는 텍스트 기반 계단식 생성을 위해 새로 밝혀진 DDPM을 사용할 수 있도록 Imagen 버전인 ElucidatedImagen 만들기로 결정했습니다.
간단히 ElucidatedImagen 가져온 다음 이전처럼 인스턴스를 인스턴스화하세요. 하이퍼파라미터는 이산 및 연속 시간 가우스 확산에 대한 일반적인 하이퍼파라미터와 다르며 캐스케이드의 각 unet에 대해 개별화될 수 있습니다.
전.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above 이 저장소는 또한 텍스트 안내 비디오 합성에 관한 새로운 연구를 축적하기 시작할 것입니다. 우선 비디오 확산 모델에서 Jonathan Ho가 설명한 3D unet 아키텍처를 채택합니다.
업데이트: Hadrien Reynaud의 작업이 확인되었습니다!
전.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) 먼저 텍스트-이미지 쌍을 학습할 수도 있습니다. Unet3D 는 이를 자동으로 단일 프레임 비디오로 변환하고 시간적 구성요소 없이( ignore_time = True 자동으로 설정하여) 1D 컨볼루션이든 시간에 따른 인과적 관심이든 학습합니다.
이것이 현재 모든 대형 인공지능 연구실(Brain, MetaAI, Bytedance)이 취하고 있는 접근 방식입니다.
Imagen은 Classifier Free Guidance라는 알고리즘을 사용합니다. 샘플링할 때 조건(이 경우 텍스트)에 1.0 보다 큰 배율을 적용합니다.
연구원 Netruk44는 5-10 최적이라고 보고했지만 10 보다 크면 깨질 수 있습니다.
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than average지금 당장은 아니지만, 빠르지는 않더라도 올해 안에 교육을 받고 오픈소스로 공개될 가능성이 높습니다. 참여하고 싶다면 Laion의 인공 신경망 트레이너 커뮤니티에 가입하고(위의 Readme에 디스코드 링크가 있음) 협업을 시작할 수 있습니다.
오늘부터 자신만의 모델 훈련을 시작해야 하는 더 많은 이유! 우리에게 마지막으로 필요한 것은 이 기술이 소수의 엘리트들의 손에 있다는 것입니다. 이 리포지토리를 통해 필요한 컴퓨팅을 찾고 자체적으로 큐레이트된 데이터 세트를 보강하는 작업을 줄일 수 있기를 바랍니다.
아무것! MIT 라이센스입니다. 즉, 자신의 연구를 위해 자유롭게 복사/붙여넣기를 할 수 있으며, 생각할 수 있는 방식에 따라 리믹스할 수 있습니다. 이익을 위해, 과학을 위해, 또는 단순히 당신 앞에서 신성한 무언가가 풀리는 것을 목격하는 개인적인 즐거움을 만족시키기 위해 놀라운 모델을 훈련하십시오.
심초음파 합성 [코드]
SOTA Hi-C 접촉 매트릭스 합성 [코드]
평면도 생성
초고해상도 조직병리학 슬라이드
합성 복강경 이미지
메타머티리얼 디자인
Flavio Schneider의 오디오 확산
Ryan O.의 미니 이미지 | AssemblyAI 작성
T5-작은 텍스트 임베딩을 위해 허깅페이스 변환기 사용
동적 임계값 추가
동적 임계값 DALE2 및 비디오 확산 저장소도 추가합니다.
T5-large로 설정 가능
부록의 의사 코드로 저해상도 노이즈 레벨을 추가하고 추론 시 수행하는 스윕이 무엇인지 알아보세요.
DALE2의 일부 학습 코드를 통해 포팅
unet마다 다른 노이즈 일정을 사용할 수 있어야 합니다(기본에는 코사인이 사용되었지만 SR에는 선형이 사용됨).
마스터 구성 가능한 unet 하나만 만드십시오.
완전한 resnet 블록(biggan에서 영감을 얻었지만 그룹 표준 포함) - 완전한 자기 주의
완전한 컨디셔닝 임베딩 블록(주의, 영화 등을 완전히 구성 가능하게 만듭니다)
주의 풀링 대신 https://github.com/lucidrains/flamingo-pytorch의 discoverer-resampler 사용을 고려해보세요.
교차 관심 및 영화 외에도 관심 풀링 옵션 추가
각 unet에 대해 워밍업과 함께 선택적인 코사인 감쇠 일정을 트레이너에 추가하세요.
모든 단계에 사용된 것처럼 보이기 때문에 이산화 대신 연속 시간 단계로 전환합니다. 먼저 변형 ddpm 논문 https://openreview.net/forum?id=2LdBqxc1Yv에서 선형 노이즈 일정 사례를 파악합니다.
알파 코사인 노이즈 일정에 대한 로그(snr)를 알아냅니다.
T5encoder만 사용되므로 변압기 경고를 억제합니다.
완전한 Attention을 사용할 수 없는 레이어에서 선형 Attention을 사용하도록 설정 가능
연속적인 시간의 경우 unets를 강제로 푸리어가 아닌 조건을 사용하도록 합니다(선택적 레이어 규범을 사용하여 MLP를 통해 로그(snr)를 전달하기만 하면 됩니다). 이것이 제가 로컬에서 작업하는 것입니다.
학습된 분산 제거
연속 시간 동안 p2 손실 가중치 추가
계단식 ddpm이 텍스트 조건 없이 훈련될 수 있는지 확인하고 연속 및 이산 시간 가우스 확산이 모두 작동하는지 확인하세요.
선형 주의에서 qkv 투영에 대한 프라이머의 깊이별 변환을 사용합니다(또는 투영 전에 토큰 이동을 사용합니다) - 또한 선형 주의와 잘 작동하는 것처럼 보이기 때문에 bayesformer가 제안한 새로운 드롭아웃을 사용합니다.
Unet 디코더에서 스킵 레이어 여기 탐색
통합 가속화
CLI 도구 구축 및 한 줄 이미지 생성
가속으로 인해 발생하는 모든 문제를 해결합니다.
리페인트 페이퍼의 리샘플러를 사용하여 인페인팅 기능 추가 https://arxiv.org/abs/2201.09865
폴더로 지원되는 간단한 검사점 시스템 구축
unet squared paper 및 일부 이전 unet 작업에 사용되는 모든 업샘플 블록의 출력에서 건너뛰기 연결을 추가합니다.
클라우드/로컬 파일 시스템에 구애받지 않는 체크포인트 지속성을 위해 Romain @rom1504가 권장하는 fsspec을 추가하세요.
https://github.com/fsspec/gcsfs를 사용하여 gcs의 지속성을 테스트하세요.
Ho의 비디오 ddpm 논문에서와 같이 축 시간 주의를 사용하여 비디오 생성으로 확장
설명된 이미지를 어떤 형태로든 일반화할 수 있도록 허용
이미지를 어떤 형태로든 일반화할 수 있도록 허용
비디오 시간에 걸쳐 최상의 길이 추정 유형을 위해 동적 위치 편향을 추가합니다.
시간 추정을 시도할 것이므로 비디오 프레임을 샘플 기능으로 이동합니다.
널 키/값에 대한 주의 편향은 헤드 차원의 학습된 스칼라여야 합니다.
ddpm-pytorch에 이미 코딩된 비트 확산 용지에서 자체 조절 기능을 추가합니다.
Imagen 비디오 논문의 v-매개변수화(https://arxiv.org/abs/2202.00512)를 추가하세요. 유일한 새로운 점입니다.
make-a-video(https://makeavideo.studio/)에서 배운 모든 내용을 통합합니다.
훈련을 위한 CLI 도구 구축, 구성 파일에서 훈련 재개
특정 단계에서 시간적 보간을 허용합니다.
시간적 보간이 인페인팅과 함께 작동하는지 확인하세요.
모든 보간 모드를 사용자 정의할 수 있는지 확인하십시오(일부 연구자는 삼선형을 사용하여 더 나은 결과를 찾고 있습니다).
imagen-video : 비디오의 이전(및 향후) 프레임에 대한 조건을 허용합니다. 해당 시나리오에서는 시간 무시가 허용되어서는 안 됩니다.
비디오 프레임 조절을 위해 시간적 다운/업샘플링을 자동으로 처리하되 이를 끌 수 있는 옵션을 허용하세요.
인페인팅이 비디오에서 작동하는지 확인하세요.
비디오용 인페인팅 마스크가 프레임별로 사용자 정의될 수 있는지 확인하세요.
플래시 주의 추가
cogvideo를 다시 읽고 프레임 속도 조절이 어떻게 사용될 수 있는지 알아보세요.
unet3d의 self attention 레이어에 대한 attention 전문 지식 가져오기
NUWA의 3D 컨볼루셔널 어텐션을 고려해보세요
시간적 주의 블록에서 Transformer-XL 메모리를 고려하십시오.
과거 시간에 주의를 기울이는 지각자-AR 접근 방식을 고려하십시오.
정규화 효과와 훈련 시간 단축을 모두 달성하기 위해 주의 중 프레임 드롭아웃
Frank Wood의 주장을 https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch 조사하고 계층적 샘플링 기술을 추가하거나 사람들에게 그 결함에 대해 알리십시오.
연구자가 텍스트에서 비디오로 분기할 수 있는 단선 훈련 가능한 기준선으로 도전적인 이동 mnist(분산 개체 포함)를 제공합니다.
텍스트를 memmapped 임베딩으로 사전 인코딩
이전 시대 스타일을 기반으로 데이터로더 반복자를 생성하고 셔플링 등을 구성할 수도 있습니다.
인수를 전달할 수도 있습니다(모델의 모든 키워드 인수를 전달하도록 요구하는 대신).
3d unet용 revnet에서 가역 블록을 가져와 메모리 부담을 줄입니다.
초해상도 네트워크만 훈련하는 기능 추가
dpm-solver를 읽고 연속 시간 가우스 확산에 적용 가능한지 확인하십시오.
임의의 절대 시간으로 비디오 프레임을 조절할 수 있습니다(시간적 주의 동안 RPE 계산).
꿈의 부스 미세 조정 수용
텍스트 반전 추가
imagen 인스턴스화 시 추출될 정리 자체 조절
최종 dreambooth가 imagen-video와 작동하는지 확인하세요.
비디오 확산을 위한 프레임 속도 조절 추가
비디오 프레임을 프롬프트로 동시에 조건화할 수 있을 뿐만 아니라 모든 프레임에 걸쳐 일부 컨디셔닝 이미지를 조정할 수 있는지 확인하십시오.
일관성 모델에서 증류 기술을 테스트하고 추가합니다.
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

