PaLM rlhf pytorch
0.3.9
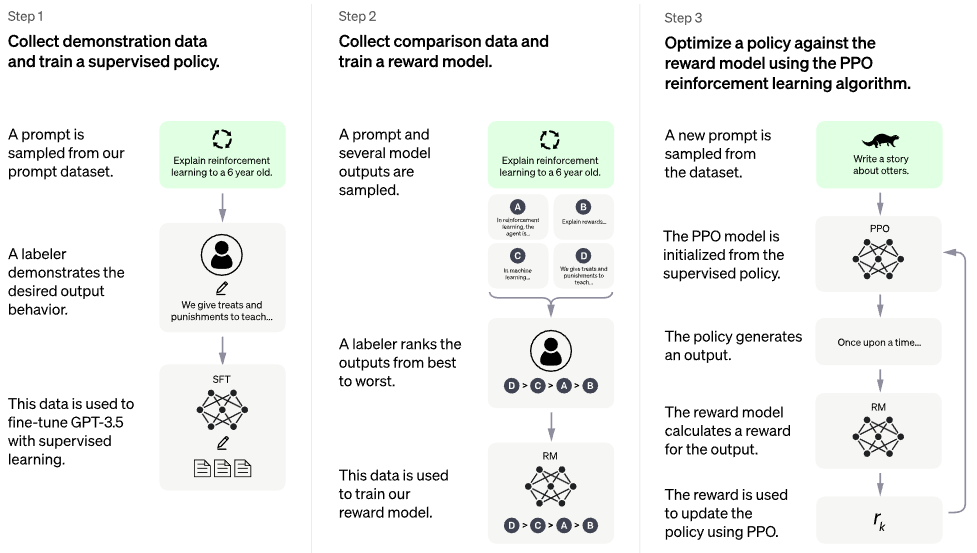
공식 chatgpt 블로그 포스트
PaLM 아키텍처 위에 RLHF(인간 피드백을 통한 강화 학습) 구현. 아마도 RETRO처럼 검색 기능도 추가할 것입니다.
ChatGPT와 같은 것을 공개적으로 복제하는 데 관심이 있다면 Laion 가입을 고려해 보세요.
잠재적 후계자: 직접 선호 최적화 - 이 저장소의 모든 코드는 ~ 바이너리 교차 엔트로피 손실, < 5 loc가 됩니다. 보상 모델과 PPO에 대한 많은 것
훈련된 모델이 없습니다. 이것은 단지 배와 전체 지도입니다. 고차원 매개변수 공간에서 올바른 지점으로 항해하려면 여전히 수백만 달러의 컴퓨팅 + 데이터가 필요합니다. 그럼에도 불구하고 실제로 격동의 시기를 거쳐 해당 지점까지 배를 안내하려면 전문 선원(Stable Diffusion으로 유명한 Robin Rombach와 같은)이 필요합니다.
CarperAI는 ChatGPT가 출시되기 전 수개월 동안 대규모 언어 모델을 위한 RLHF 프레임워크 작업을 진행해 왔습니다.
Yannic Kilcher는 또한 오픈 소스 구현을 위해 노력하고 있습니다.
AI Coffeebreak with Letitia | 코드 엠포리움 | 코드 엠포리움 파트 2
최첨단 인공지능 연구를 위한 Stability.ai의 아낌없는 후원
? Hugging Face와 CarperAI는 블로그 게시물 Illustating Reinforcement Learning from Human Feedback(RLHF)을 작성했고 전자는 가속화 라이브러리를 작성했습니다.
코드 검토 및 버그 발견을 위한 @kisseternity 및 @taynoel84
Pytorch 2.0에서 Flash Attention을 통합한 Enrico
$ pip install palm-rlhf-pytorch 다른 자기회귀 변환기와 마찬가지로 첫 번째 훈련 PaLM
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048) 그런 다음 선별된 인간 피드백을 사용하여 보상 모델을 훈련하세요. 원본 논문에서는 과적합 없이 사전 학습된 변환기에서 미세 조정되는 보상 모델을 얻을 수 없었지만, 아직 공개 연구이기 때문에 어쨌든 LoRA 사용하여 미세 조정할 수 있는 옵션을 제공했습니다.
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask ) 그런 다음 변환기와 보상 모델을 RLHFTrainer 에 전달합니다.
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) 평론가를 위한 별도의 lora가 있는 클론 베이스 변환기
LoRA 기반이 아닌 미세 조정도 허용
마스크된 버전을 가질 수 있도록 정규화를 다시 실행하세요. 누군가가 토큰당 보상/값을 사용할 것인지 확실하지 않지만 구현하는 것이 좋습니다.
최선의 관심을 기울이다
Hugging Face를 추가하고 wandb 계측을 가속화하고 테스트하세요.
RL 분야가 여전히 진행 중이라는 가정 하에 PPO용 최신 SOTA가 무엇인지 알아보려면 문헌을 검색해 보세요.
사전 훈련된 감정 네트워크를 보상 모델로 사용하여 시스템 테스트
memmapped numpy 파일에 PPO의 메모리를 씁니다.
병목 현상이 인간의 피드백이기 때문에 필요하지 않더라도 다양한 길이의 프롬프트로 샘플링을 수행합니다.
사전 훈련된 경우를 가정하여 배우나 평론가에서만 두 번째 N 레이어를 미세 조정할 수 있습니다.
Letitia의 동영상을 바탕으로 Sparrow의 몇 가지 학습 포인트를 통합합니다.
사람의 피드백을 수집하기 위한 django + htmx를 사용한 간단한 웹 인터페이스
RLAIF를 고려해보세요
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

