atari
1.0.0

다양한 강화학습 알고리즘 구현을 위해 준비된 OpenAI의 Atari Gym 위에 구축된 Research Playground입니다.
다음 게임 중 하나를 에뮬레이트할 수 있습니다.
['Asterix', 'Asteroids', 'MsPacman', 'Kaboom', 'BankHeist', 'Kangaroo', 'Skiing', 'FishingDerby', 'Krull', 'Berzerk', 'Tutankham', 'Zaxxon', ' 벤처', '리버레이드', '지네', '어드벤처', '빔라이더', 'CrazyClimber', 'TimePilot', 'Carnival', 'Tennis', 'Seaquest', 'Bowling', 'SpaceInvaders', 'Freeway', 'YarsRevenge', 'RoadRunner', 'JourneyEscape', 'WizardOfWor', 'Gopher ', '브레이크아웃', '스타거너', '아틀란티스', 'DoubleDunk', 'Hero', 'BattleZone', 'Solaris', 'UpNDown', 'Frostbite', 'KungFuMaster', 'Pooyan', 'Pitfall', 'MontezumaRevenge', 'PrivateEye', 'AirRaid', 'Amidar ', 'Robotank', 'DemonAttack', 'Defender', 'NameThisGame', 'Phoenix', 'Gravitar', 'ElevatorAction', 'Pong', 'VideoPinball', 'IceHockey', 'Boxing', 'Assault', 'Alien', 'Qbert', 'Enduro', 'ChopperCommand', 'Jamesbond' ']
해당 매체 기사를 확인하세요: Atari - 심층 강화 학습? (1부: DDQN)
이 프로젝트의 궁극적인 목표는 Atari 게임을 공통분모로 하는 다양한 RL 접근 방식을 구현하고 비교하는 것입니다.
pip install -r requirements.txt .python atari.py --help 사용 가능한 모든 모드를 보려면 help 명령으로 시작하는 것이 좋습니다. * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
DeepMind의 심층 합성곱 신경망
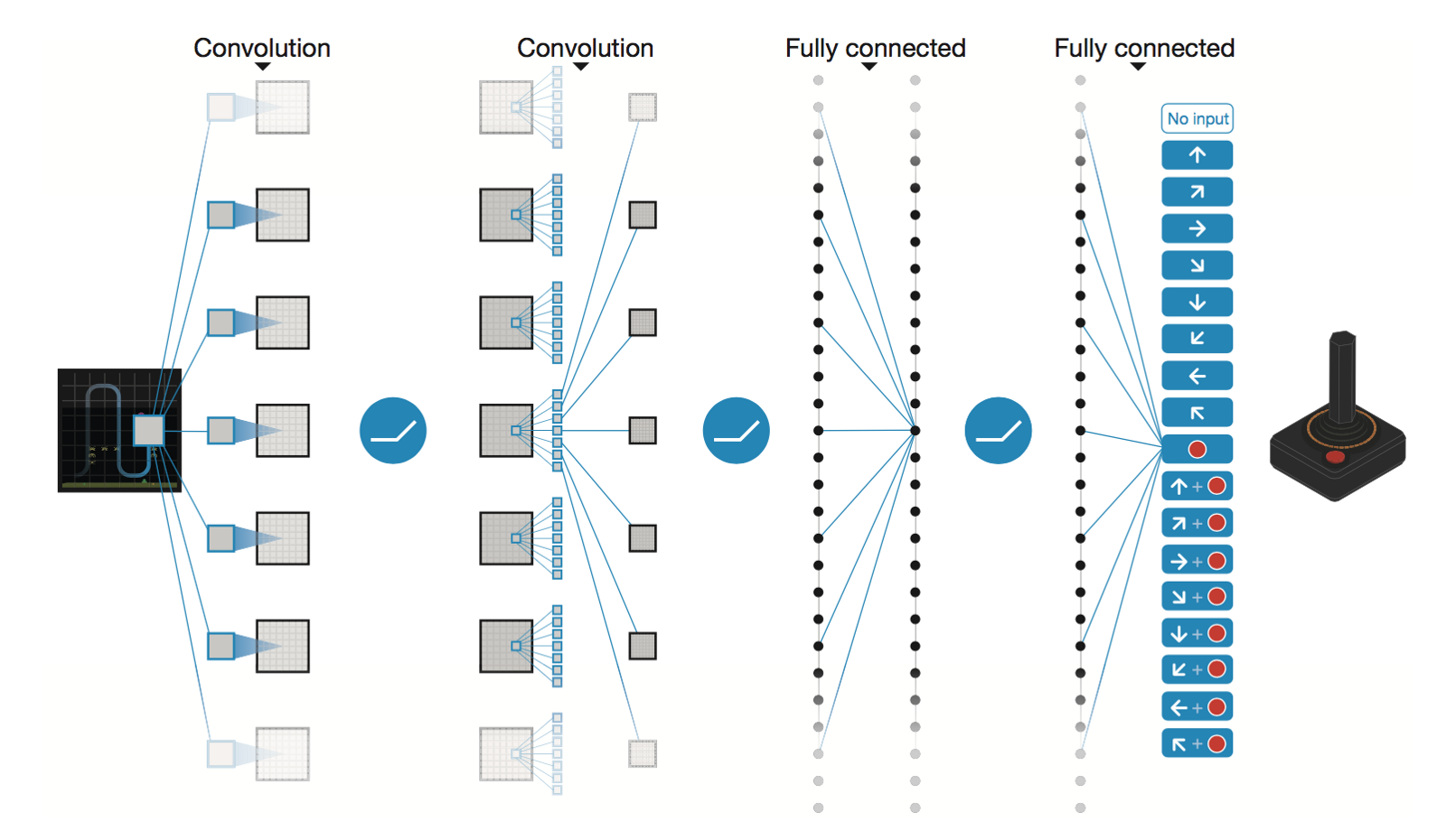
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
5M 단계 후(Tesla K80 GPU에서 ~40시간 또는 2.9 GHz Intel i7 쿼드 코어 CPU에서 ~90시간 ):
훈련:
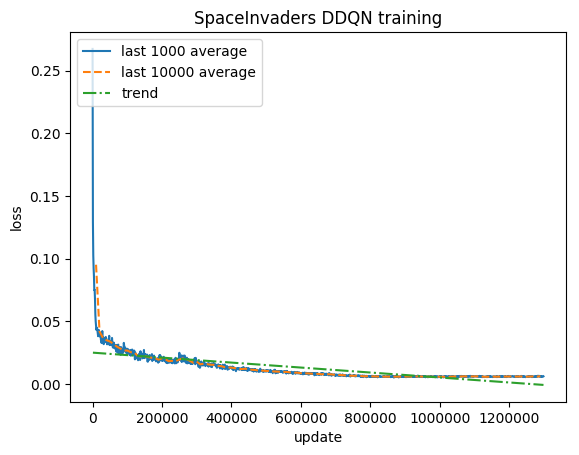
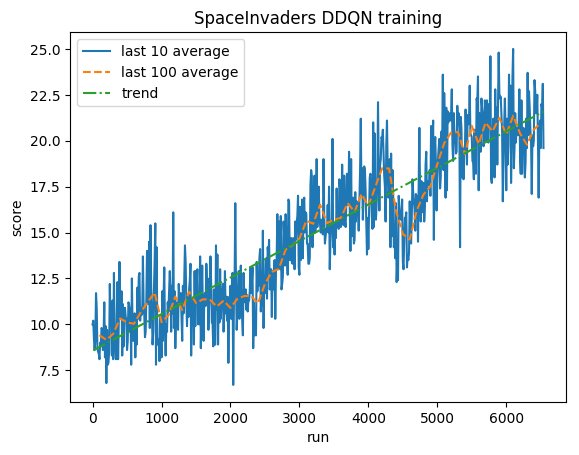
정규화된 점수 - 각 보상은 (-1, 1)로 잘립니다.
테스트:
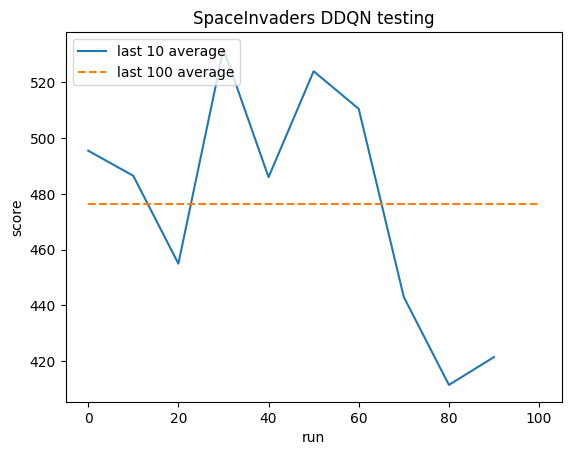
인간 평균: ~372
DDQN 평균: ~479(128%)
훈련:
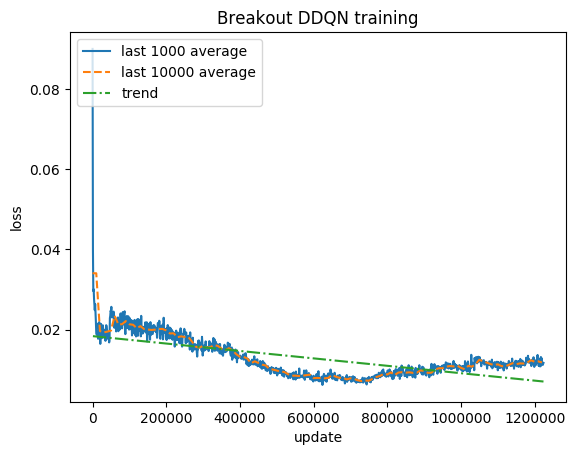
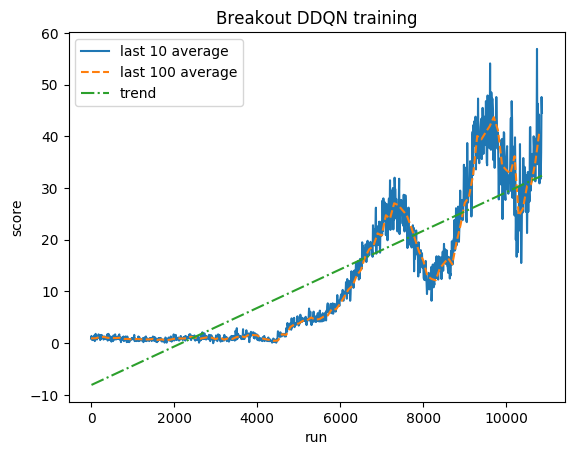
정규화된 점수 - 각 보상은 (-1, 1)로 잘립니다.
테스트:
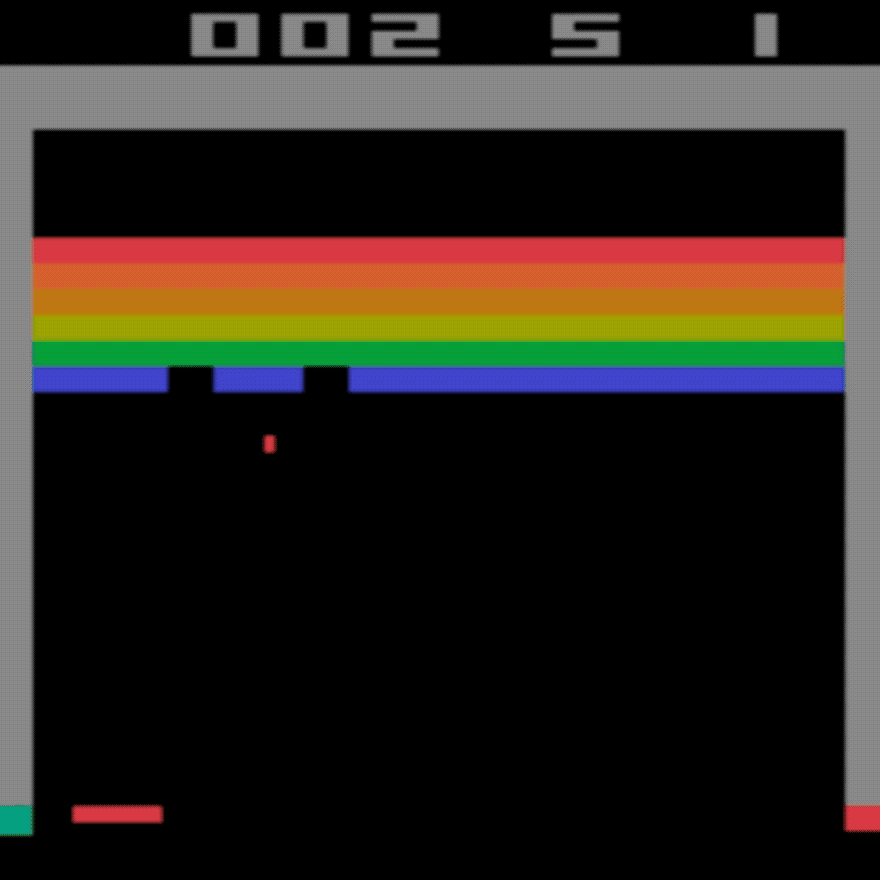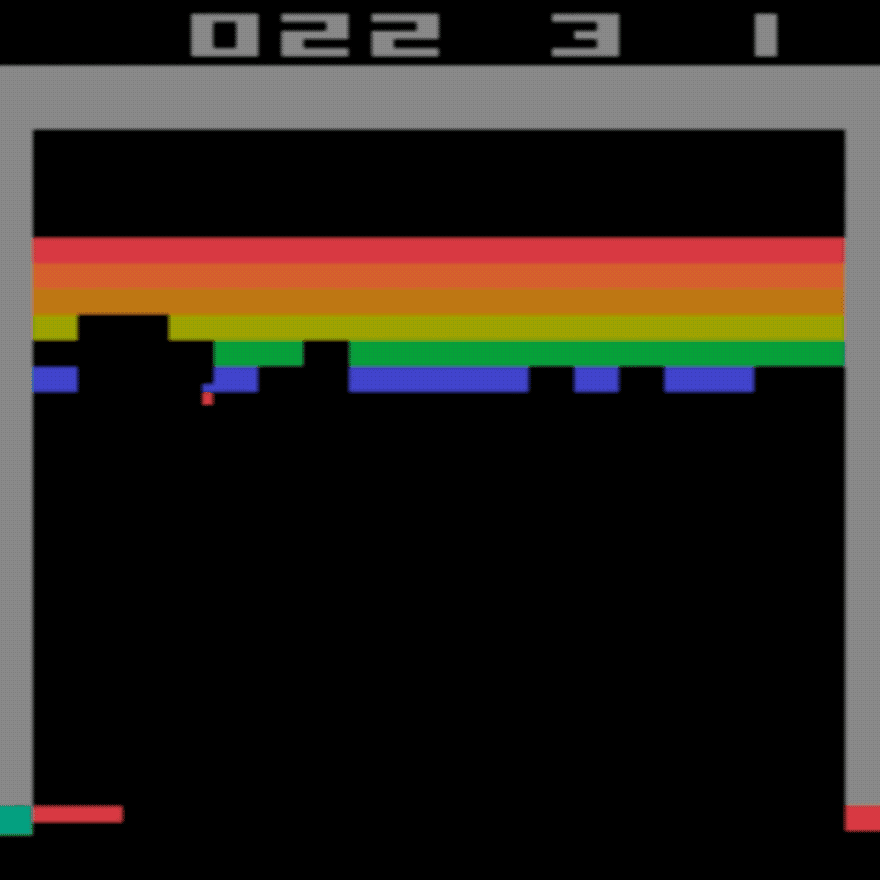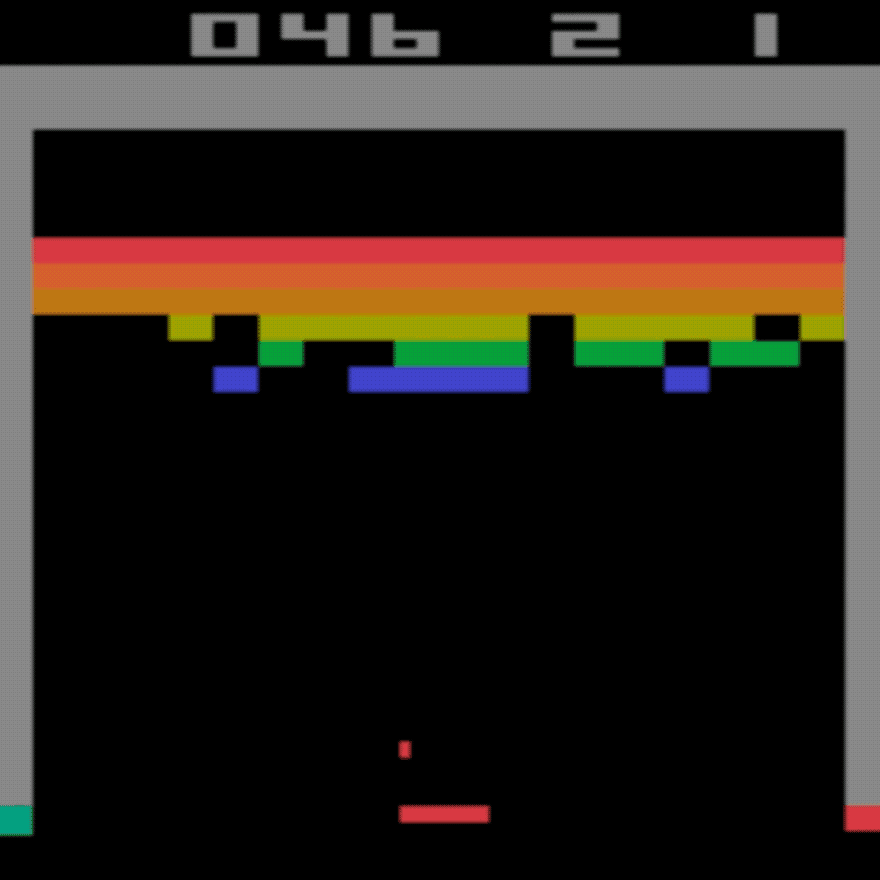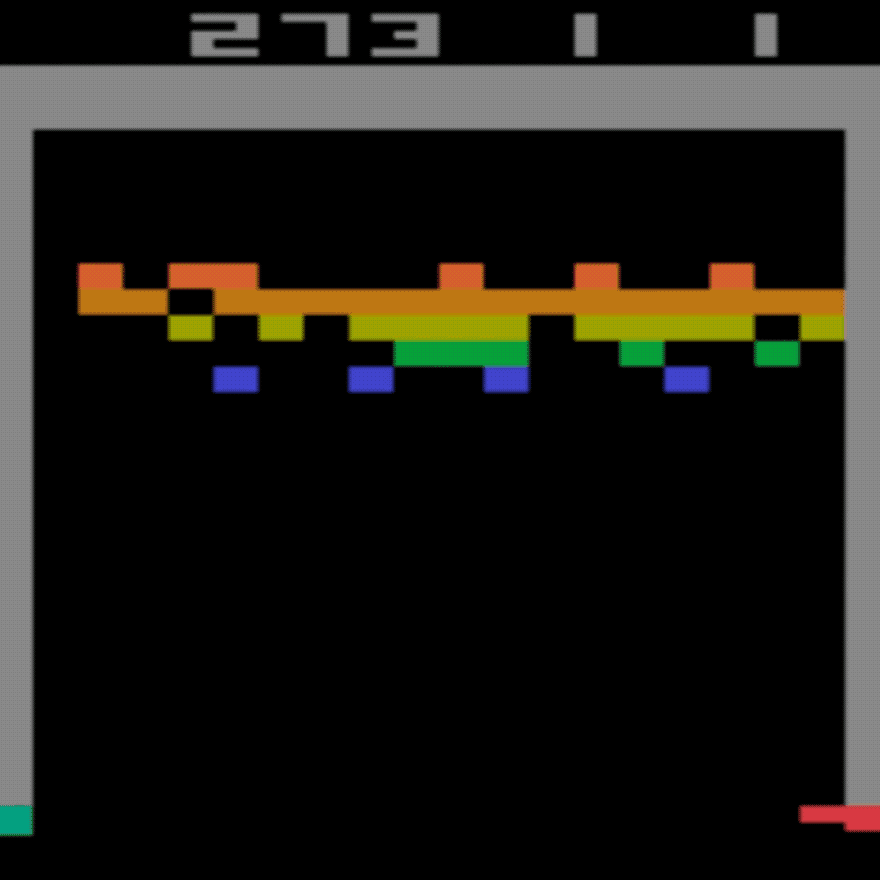
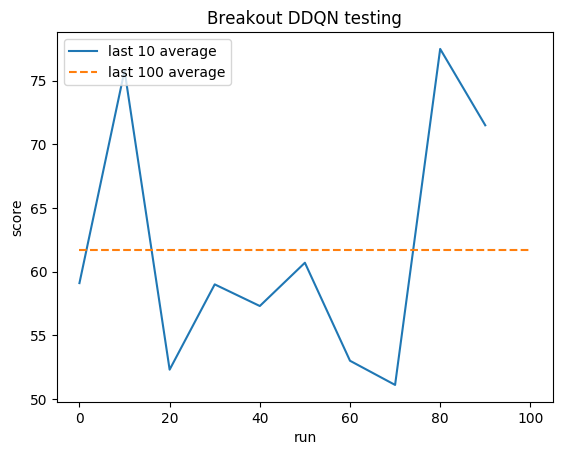
인간 평균: ~28
DDQN 평균: ~62(221%)
훈련:
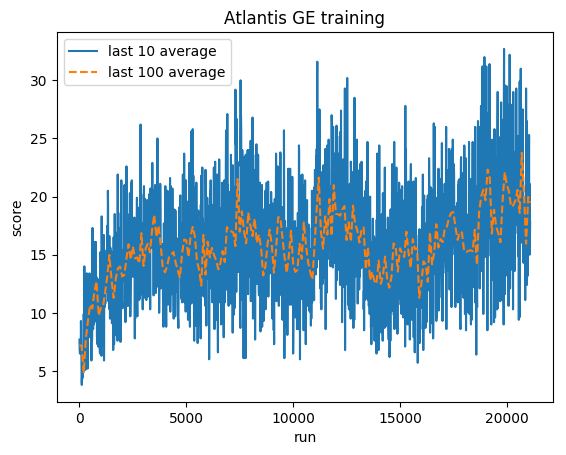
정규화된 점수 - 각 보상은 (-1, 1)로 잘립니다.
테스트:

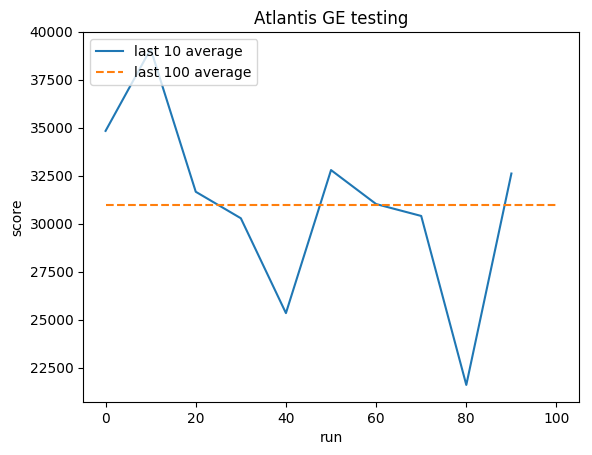
인간 평균: ~29,000
GE 평균: 31,000(106%)
그렉(Grzegorz) 수르마
포트폴리오
깃허브
블로그


