metnet3 pytorch
0.0.12
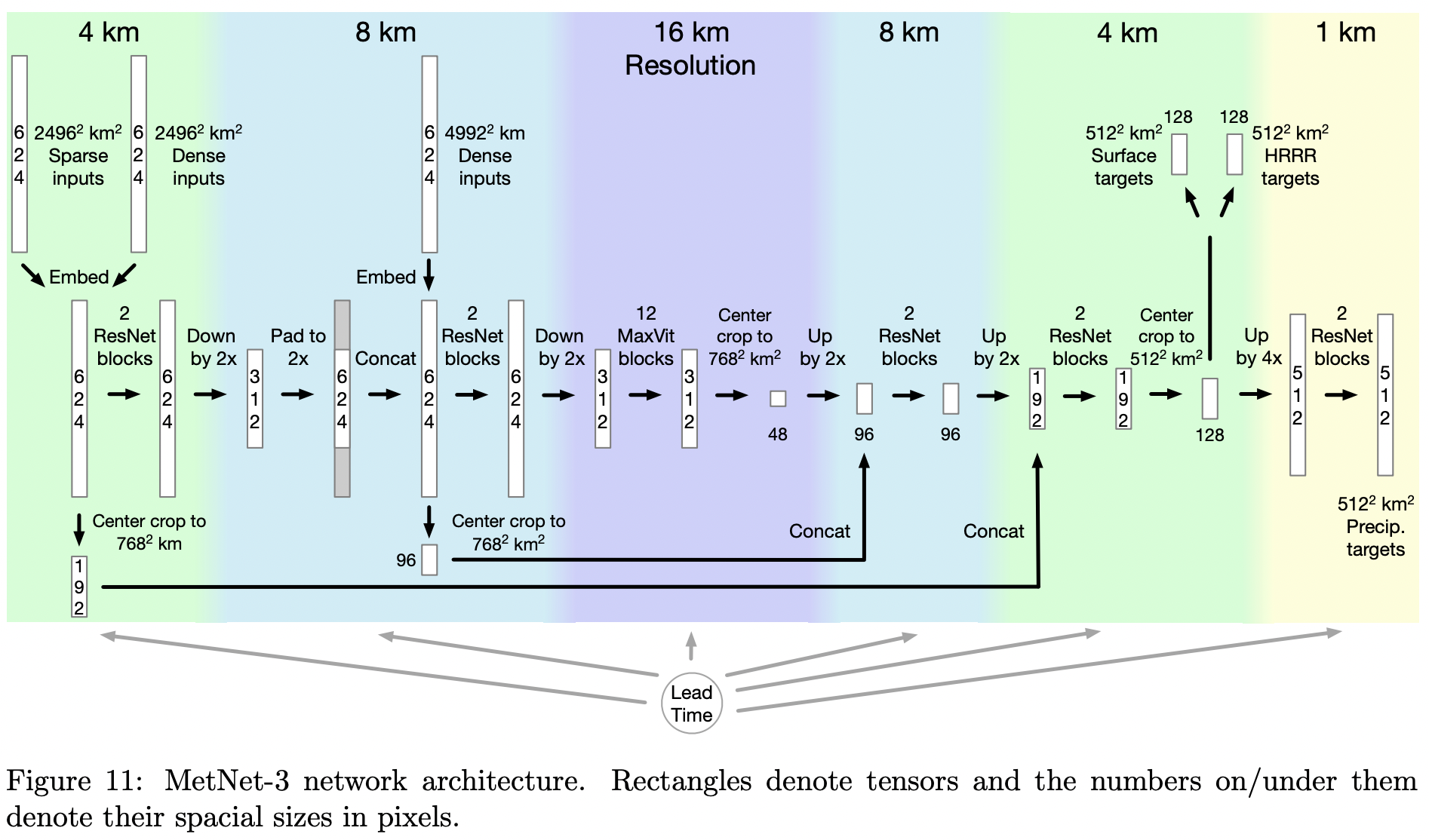
Pytorch에서 Google Deepmind의 SOTA 신경 기상 모델인 MetNet 3 구현
모델 아키텍처는 눈에 띄지 않습니다. 기본적으로 특정 성능이 뛰어난 비전 변환기를 갖춘 U-net입니다. 논문에서 가장 흥미로운 점은 섹션 4.3.2의 손실 스케일링일 수 있습니다.
$ pip install metnet3-pytorch import torch
from metnet3_pytorch import MetNet3
metnet3 = MetNet3 (
dim = 512 ,
num_lead_times = 722 ,
lead_time_embed_dim = 32 ,
input_spatial_size = 624 ,
attn_dim_head = 8 ,
hrrr_channels = 617 ,
input_2496_channels = 2 + 14 + 1 + 2 + 20 ,
input_4996_channels = 16 + 1 ,
precipitation_target_bins = dict (
mrms_rate = 512 ,
mrms_accumulation = 512 ,
),
surface_target_bins = dict (
omo_temperature = 256 ,
omo_dew_point = 256 ,
omo_wind_speed = 256 ,
omo_wind_component_x = 256 ,
omo_wind_component_y = 256 ,
omo_wind_direction = 180
),
hrrr_loss_weight = 10 ,
hrrr_norm_strategy = 'sync_batchnorm' , # this would use a sync batchnorm to normalize the input hrrr and target, without having to precalculate the mean and variance of the hrrr dataset per channel
hrrr_norm_statistics = None # you can also also set `hrrr_norm_strategy = "precalculated"` and pass in the mean and variance as shape `(2, 617)` through this keyword argument
)
# inputs
lead_times = torch . randint ( 0 , 722 , ( 2 ,))
hrrr_input_2496 = torch . randn (( 2 , 617 , 624 , 624 ))
hrrr_stale_state = torch . randn (( 2 , 1 , 624 , 624 ))
input_2496 = torch . randn (( 2 , 39 , 624 , 624 ))
input_4996 = torch . randn (( 2 , 17 , 624 , 624 ))
# targets
precipitation_targets = dict (
mrms_rate = torch . randint ( 0 , 512 , ( 2 , 512 , 512 )),
mrms_accumulation = torch . randint ( 0 , 512 , ( 2 , 512 , 512 )),
)
surface_targets = dict (
omo_temperature = torch . randint ( 0 , 256 , ( 2 , 128 , 128 )),
omo_dew_point = torch . randint ( 0 , 256 , ( 2 , 128 , 128 )),
omo_wind_speed = torch . randint ( 0 , 256 , ( 2 , 128 , 128 )),
omo_wind_component_x = torch . randint ( 0 , 256 , ( 2 , 128 , 128 )),
omo_wind_component_y = torch . randint ( 0 , 256 , ( 2 , 128 , 128 )),
omo_wind_direction = torch . randint ( 0 , 180 , ( 2 , 128 , 128 ))
)
hrrr_target = torch . randn ( 2 , 617 , 128 , 128 )
total_loss , loss_breakdown = metnet3 (
lead_times = lead_times ,
hrrr_input_2496 = hrrr_input_2496 ,
hrrr_stale_state = hrrr_stale_state ,
input_2496 = input_2496 ,
input_4996 = input_4996 ,
precipitation_targets = precipitation_targets ,
surface_targets = surface_targets ,
hrrr_target = hrrr_target
)
total_loss . backward ()
# after much training from above, you can predict as follows
metnet3 . eval ()
surface_preds , hrrr_pred , precipitation_preds = metnet3 (
lead_times = lead_times ,
hrrr_input_2496 = hrrr_input_2496 ,
hrrr_stale_state = hrrr_stale_state ,
input_2496 = input_2496 ,
input_4996 = input_4996 ,
)
# Dict[str, Tensor], Tensor, Dict[str, Tensor] 모든 교차 엔트로피와 MSE 손실을 파악합니다.
훈련 중 목표의 실행 평균 및 분산을 추적하여 HRRR의 모든 채널에서 정규화를 자동 처리합니다(해킹으로 동기화 배치표준 사용).
연구원이 HRRR에 대한 자체 정규화 변수를 전달할 수 있도록 허용
모든 입력을 사양에 맞게 구축하고, hrrr 입력이 정규화되었는지 확인하고, hrrr 예측을 비정규화하는 옵션을 제공합니다.
hrrr 표준을 처리하는 다양한 방법으로 모델을 쉽게 저장하고 로드할 수 있는지 확인하세요.
토폴로지 임베딩을 파악하고 신경 기상 연구원과 상담하세요.
@article { Andrychowicz2023DeepLF ,
title = { Deep Learning for Day Forecasts from Sparse Observations } ,
author = { Marcin Andrychowicz and Lasse Espeholt and Di Li and Samier Merchant and Alexander Merose and Fred Zyda and Shreya Agrawal and Nal Kalchbrenner } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2306.06079 } ,
url = { https://api.semanticscholar.org/CorpusID:259129311 }
} @inproceedings { ElNouby2021XCiTCI ,
title = { XCiT: Cross-Covariance Image Transformers } ,
author = { Alaaeldin El-Nouby and Hugo Touvron and Mathilde Caron and Piotr Bojanowski and Matthijs Douze and Armand Joulin and Ivan Laptev and Natalia Neverova and Gabriel Synnaeve and Jakob Verbeek and Herv{'e} J{'e}gou } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2021 } ,
url = { https://api.semanticscholar.org/CorpusID:235458262 }
}

