LongNet
0.4.8

이것은 Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei가 쓴 LongNet: Scaling Transformers to 1,000,000,000 Tokens 논문의 오픈 소스 구현입니다. LongNet은 더 짧은 시퀀스에서 성능을 저하시키지 않고 시퀀스 길이를 최대 10억 개 이상의 토큰으로 확장하도록 설계된 Transformer 변형입니다.
pip install longnet LongNet을 설치한 후에는 다음과 같이 DilatedAttention 클래스를 사용할 수 있습니다.
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerLayernorm이 포함된 피드포워드, SWIGLU 및 병렬 변압기 블록을 갖춘 확장된 변압기 블록을 갖춘 완벽하게 훈련 가능한 변압기 모델
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
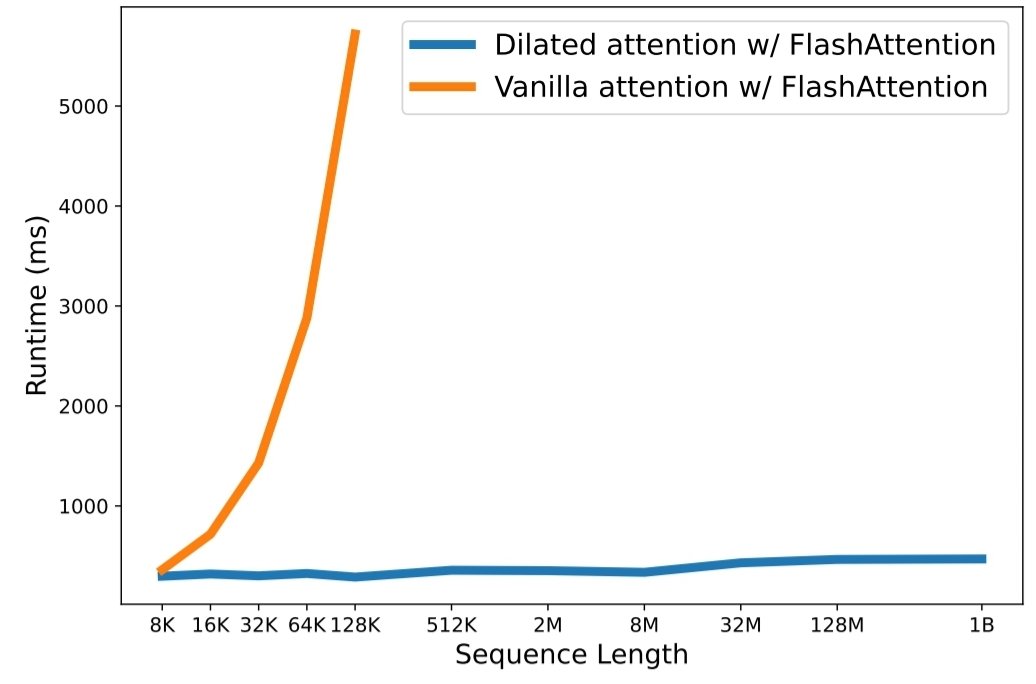
python3 train.py 실행하세요. 확장 시퀀스 길이는 대규모 언어 모델 시대에 중요한 병목 현상이 되었습니다. 그러나 기존 방법은 계산 복잡성이나 모델 표현성 문제로 인해 최대 시퀀스 길이가 제한됩니다. 이 문서에서는 더 짧은 시퀀스의 성능을 저하시키지 않으면서 시퀀스 길이를 10억 개 이상의 토큰으로 확장할 수 있는 Transformer 변형인 LongNet을 소개합니다. 구체적으로 그들은 거리가 멀어짐에 따라 주의력 영역을 기하급수적으로 확장하는 확장된 주의를 제안합니다.
LongNet에는 다음과 같은 중요한 이점이 있습니다.
실험 결과는 LongNet이 긴 시퀀스 모델링과 일반 언어 작업 모두에서 강력한 성능을 제공한다는 것을 보여줍니다. 그들의 작업은 매우 긴 시퀀스를 모델링하는 데 새로운 가능성을 열어줍니다. 예를 들어 전체 자료 또는 전체 인터넷을 시퀀스로 처리하는 것입니다.
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

