musiclm pytorch
0.2.8
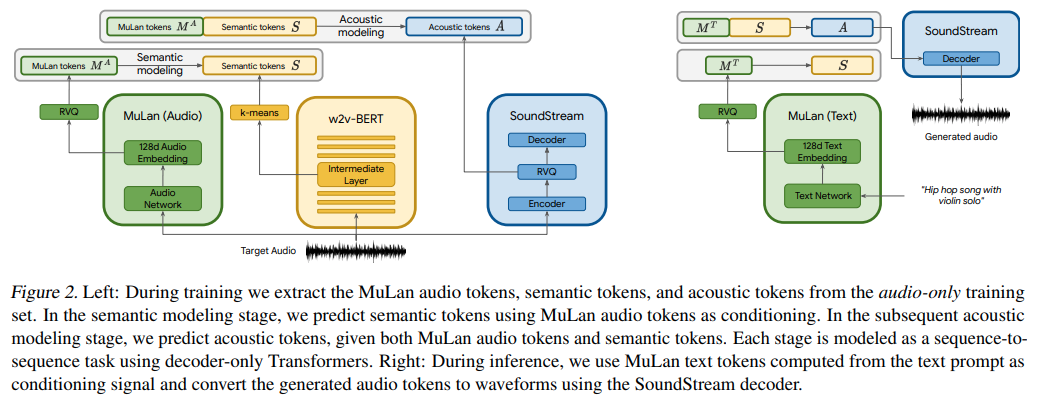
주의 네트워크를 사용하여 음악 생성을 위한 Google의 새로운 SOTA 모델인 MusicLM을 Pytorch에서 구현합니다.
그들은 기본적으로 텍스트 조건이 적용된 AudioLM을 사용하고 있지만 놀랍게도 MuLan이라는 텍스트-오디오 대조 학습 모델의 임베딩을 사용합니다. MuLan은 여기에서 음악 생성 요구 사항을 지원하기 위해 다른 저장소에서 수정된 AudioLM을 사용하여 이 저장소에 구축될 것입니다.
LAION 커뮤니티와 함께 복제 작업에 도움을 주고 싶으시다면 가입해 주세요.
루이스 부차드(Louis Bouchard)의 AI란 무엇인가?
Stability.ai 작업 및 오픈소스 최첨단 인공지능 연구에 대한 아낌없는 후원
? 가속 훈련 라이브러리를 위한 Huggingface
$ pip install musiclm-pytorch
MuLaN 먼저 훈련시켜야 합니다.
import torch
from musiclm_pytorch import MuLaN , AudioSpectrogramTransformer , TextTransformer
audio_transformer = AudioSpectrogramTransformer (
dim = 512 ,
depth = 6 ,
heads = 8 ,
dim_head = 64 ,
spec_n_fft = 128 ,
spec_win_length = 24 ,
spec_aug_stretch_factor = 0.8
)
text_transformer = TextTransformer (
dim = 512 ,
depth = 6 ,
heads = 8 ,
dim_head = 64
)
mulan = MuLaN (
audio_transformer = audio_transformer ,
text_transformer = text_transformer
)
# get a ton of <sound, text> pairs and train
wavs = torch . randn ( 2 , 1024 )
texts = torch . randint ( 0 , 20000 , ( 2 , 256 ))
loss = mulan ( wavs , texts )
loss . backward ()
# after much training, you can embed sounds and text into a joint embedding space
# for conditioning the audio LM
embeds = mulan . get_audio_latents ( wavs ) # during training
embeds = mulan . get_text_latents ( texts ) # during inference AudioLM 의 일부인 세 개의 변환기에 대한 조절 임베딩을 얻으려면 MuLaNEmbedQuantizer 를 사용해야 합니다.
from musiclm_pytorch import MuLaNEmbedQuantizer
# setup the quantizer with the namespaced conditioning embeddings, unique per quantizer as well as namespace (per transformer)
quantizer = MuLaNEmbedQuantizer (
mulan = mulan , # pass in trained mulan from above
conditioning_dims = ( 1024 , 1024 , 1024 ), # say all three transformers have model dimensions of 1024
namespaces = ( 'semantic' , 'coarse' , 'fine' )
)
# now say you want the conditioning embeddings for semantic transformer
wavs = torch . randn ( 2 , 1024 )
conds = quantizer ( wavs = wavs , namespace = 'semantic' ) # (2, 8, 1024) - 8 is number of quantizers AudioLM 의 일부인 세 개의 변환기를 훈련(또는 미세 조정)하려면 훈련을 위해 audiolm-pytorch 의 지침을 따르지만 MulanEmbedQuantizer 인스턴스를 audio_conditioner 키워드 아래의 훈련 클래스에 전달합니다.
전. SemanticTransformerTrainer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
audio_text_condition = True # this must be set to True (same for CoarseTransformer and FineTransformers)
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
audio_conditioner = quantizer , # pass in the MulanEmbedQuantizer instance above
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () 세 가지 변환기(의미론적, 대략적, 미세함)에 대한 많은 훈련을 마친 후 미세 조정되거나 처음부터 훈련된 AudioLM 및 MuLaNEmbedQuantizer 에 래핑된 MuLaN MusicLM 에 전달합니다.
# you need the trained AudioLM (audio_lm) from above
# with the MulanEmbedQuantizer (mulan_embed_quantizer)
from musiclm_pytorch import MusicLM
musiclm = MusicLM (
audio_lm = audio_lm , # `AudioLM` from https://github.com/lucidrains/audiolm-pytorch
mulan_embed_quantizer = quantizer # the `MuLaNEmbedQuantizer` from above
)
music = musiclm ( 'the crystalline sounds of the piano in a ballroom' , num_samples = 4 ) # sample 4 and pick the top match with mulan 뮬란은 분리된 대조 학습을 사용하는 것 같습니다. 이를 옵션으로 제공합니다.
mulan 래퍼로 mulan을 감싸고 출력을 양자화하고 audiolm 크기로 프로젝트
컨디셔닝 임베딩을 허용하도록 audiolm을 수정하고 선택적으로 별도의 프로젝션을 통해 다양한 차원을 처리합니다.
audiolm과 mulan은 musiclm에 들어가서 생성하고 mulan으로 필터링합니다.
AST의 self attention에 동적 위치 편향 제공
여러 샘플을 생성하고 MuLaN과 가장 일치하는 항목을 선택하는 MusicLM 구현
오디오 변환기의 마스킹을 통해 가변 길이 오디오 지원
클립을 열려면 뮬란 버전을 추가하세요
적절한 스펙트로그램 하이퍼파라미터를 모두 설정하세요.
@inproceedings { Agostinelli2023MusicLMGM ,
title = { MusicLM: Generating Music From Text } ,
author = { Andrea Agostinelli and Timo I. Denk and Zal{'a}n Borsos and Jesse Engel and Mauro Verzetti and Antoine Caillon and Qingqing Huang and Aren Jansen and Adam Roberts and Marco Tagliasacchi and Matthew Sharifi and Neil Zeghidour and C. Frank } ,
year = { 2023 }
} @article { Huang2022MuLanAJ ,
title = { MuLan: A Joint Embedding of Music Audio and Natural Language } ,
author = { Qingqing Huang and Aren Jansen and Joonseok Lee and Ravi Ganti and Judith Yue Li and Daniel P. W. Ellis } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.12415 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @article { Liu2022PatchDropoutEV ,
title = { PatchDropout: Economizing Vision Transformers Using Patch Dropout } ,
author = { Yue Liu and Christos Matsoukas and Fredrik Strand and Hossein Azizpour and Kevin Smith } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.07220 }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Shukor2022EfficientVP ,
title = { Efficient Vision-Language Pretraining with Visual Concepts and Hierarchical Alignment } ,
author = { Mustafa Shukor and Guillaume Couairon and Matthieu Cord } ,
booktitle = { British Machine Vision Conference } ,
year = { 2022 }
} @inproceedings { Zhai2023SigmoidLF ,
title = { Sigmoid Loss for Language Image Pre-Training } ,
author = { Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer } ,
year = { 2023 }
}유일한 진실은 음악이다. - 잭 케루악
음악은 인류의 보편적 언어이다. - 헨리 워즈워스 롱펠로


