pba
1.0.0
새로운 기능: 노트북 pba.ipynb 사용하여 PBA 및 적용된 기능 보강을 시각화하세요!
이제 Python 3이 지원됩니다.
PBA(Population Based Augmentation)는 신경망 훈련을 위한 데이터 증강 기능을 빠르고 효율적으로 학습하는 알고리즘입니다. PBA는 1,000배 적은 컴퓨팅 성능으로 CIFAR의 최첨단 결과를 일치시켜 연구원과 실무자가 단일 워크스테이션 GPU를 사용하여 새로운 증강 정책을 효과적으로 배울 수 있도록 합니다.
이 저장소에는 TensorFlow 및 Python의 "Population Based Augmentation: Efficient Learning of Augmentation Schedules"(http://arxiv.org/abs/1905.05393) 작업에 대한 코드가 포함되어 있습니다. 여기에는 보고된 증강 일정을 사용한 모델 교육과 새로운 증강 정책 일정 검색이 포함됩니다.
증강 전략을 시각화하려면 아래를 참조하세요.

코드는 Python 2 및 3을 지원합니다.
pip install -r requirements.txtbash datasets/cifar10.sh
bash datasets/cifar100.sh| 데이터세트 | 모델 | 테스트 오류(%) |
|---|---|---|
| CIFAR-10 | Wide-ResNet-28-10 | 2.58 |
| 흔들기-흔들기(26 2x32d) | 2.54 | |
| 흔들기-흔들기(26 2x96d) | 2.03 | |
| 쉐이크-쉐이크(26 2x112d) | 2.03 | |
| 피라미드넷+ShakeDrop | 1.46 | |
| CIFAR-10 감소 | Wide-ResNet-28-10 | 12.82 |
| 흔들기-흔들기(26 2x96d) | 10.64 | |
| CIFAR-100 | Wide-ResNet-28-10 | 16.73 |
| 흔들기-흔들기(26 2x96d) | 15.31 | |
| 피라미드넷+ShakeDrop | 10.94 | |
| SVHN | Wide-ResNet-28-10 | 1.18 |
| 흔들기-흔들기(26 2x96d) | 1.13 | |
| SVHN 감소 | Wide-ResNet-28-10 | 7.83 |
| 흔들기-흔들기(26 2x96d) | 6.46 |
결과를 재현하기 위한 스크립트는 scripts/table_*.sh 에 있습니다. 모든 스크립트에는 하나의 인수인 모델 이름이 필요합니다. 사용 가능한 옵션은 wrn_28_10, ss_32, ss_96, ss_112, pyramid_net 중에서 백서의 표 2에 있는 각 데이터세트에 대해 보고된 옵션입니다. 하이퍼파라미터는 각 스크립트 파일 내부에도 위치합니다.
예를 들어 Wide-ResNet-28-10에서 CIFAR-10 결과를 재현하려면 다음을 수행하십시오.
bash scripts/table_1_cifar10.sh wrn_28_10Shake-Shake(26 2x96d)에서 감소된 SVHN 결과를 재현하려면:
bash scripts/table_4_svhn.sh rsvhn_ss_96시작하기 좋은 곳은 Wide-ResNet-28-10의 감소된 SVHN입니다. 이는 Titan XP GPU에서 91% 이상의 테스트 정확도에 도달하여 10분 이내에 완료할 수 있습니다.
1800세대에서 더 큰 모델을 실행하려면 며칠 간의 훈련이 필요할 수 있습니다. 예를 들어 CIFAR-10 PyramidNet+ShakeDrop은 Tesla V100 GPU에서 약 9일이 소요됩니다.
scripts/search.sh 파일을 사용하여 Wide-ResNet-40-2에서 PBA 검색을 실행합니다. 하나의 인수인 데이터세트 이름이 필요합니다. 선택 사항은 rsvhn 또는 rcifar10 입니다.
동일한 GPU에서 여러 평가판을 실행하려면 부분적인 GPU 크기가 지정됩니다. 축소된 SVHN은 Titan XP GPU에서 약 1시간이 걸리고 축소된 CIFAR-10은 약 5시간이 걸립니다.
CUDA_VISIBLE_DEVICES=0 bash scripts/search.sh rsvhn 검색에 사용된 결과 일정은 Ray 결과 디렉터리에서 검색할 수 있으며, 로그 파일은 pba/utils.py 의 parse_log() 함수를 사용하여 정책 일정으로 변환할 수 있습니다. 예를 들어, 200세대에 걸쳐 Reduced CIFAR-10에서 학습된 정책 일정은 확률 및 크기 하이퍼파라미터 값(각 증강 작업에 대한 두 값이 병합됨)으로 분할되어 아래에 시각화됩니다.
| 시간 경과에 따른 확률 초매개변수 | 시간 경과에 따른 크기 초매개변수 |
|---|---|
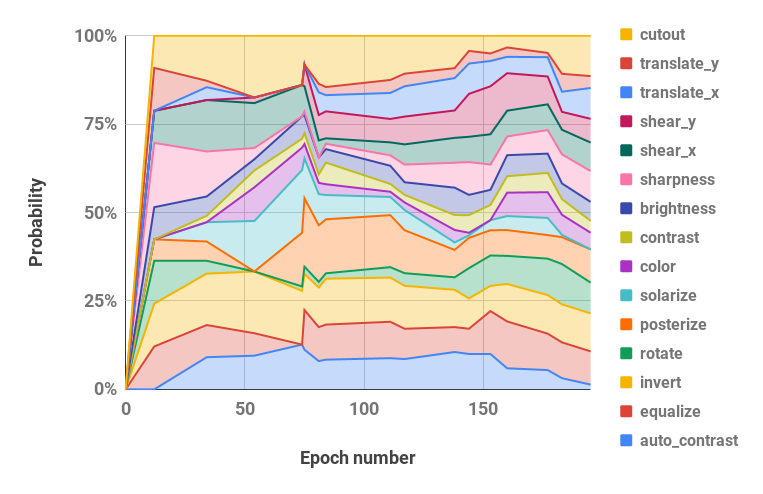 | 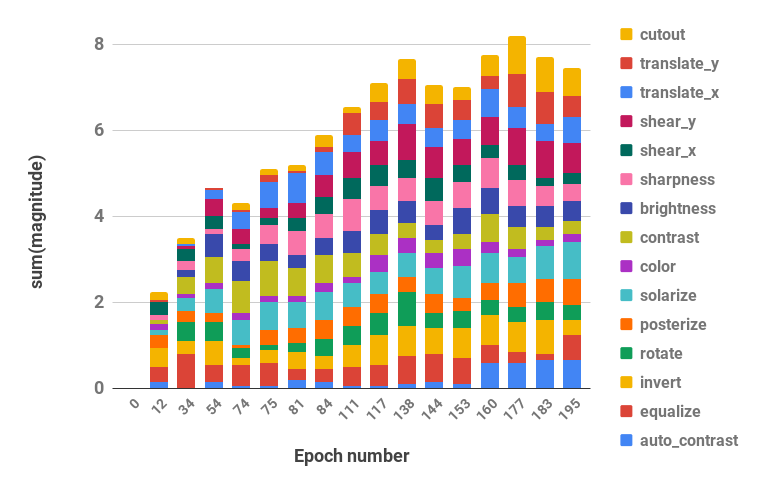 |
연구에 PBA를 사용하는 경우 다음을 인용해 주세요.
@inproceedings{ho2019pba,
title = {Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules},
author = {Daniel Ho and
Eric Liang and
Ion Stoica and
Pieter Abbeel and
Xi Chen
},
booktitle = {ICML},
year = {2019}
}


