bottleneck transformer pytorch
0.1.4
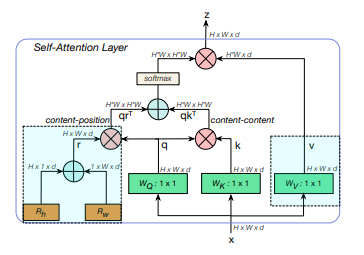
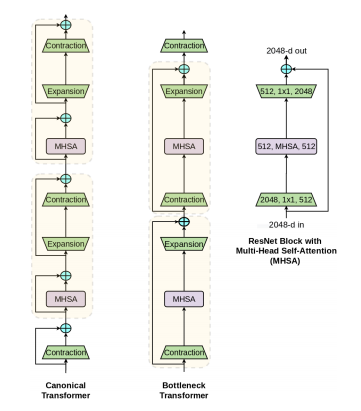
Pytorch에서 성능-컴퓨팅 트레이드오프 측면에서 EfficientNet 및 DeiT를 능가하는 컨볼루션 + 어텐션을 갖춘 Bottleneck Transformer인 SotA 시각적 인식 모델 구현
$ pip install bottleneck-transformer-pytorch import torch
from torch import nn
from bottleneck_transformer_pytorch import BottleStack
layer = BottleStack (
dim = 256 , # channels in
fmap_size = 64 , # feature map size
dim_out = 2048 , # channels out
proj_factor = 4 , # projection factor
downsample = True , # downsample on first layer or not
heads = 4 , # number of heads
dim_head = 128 , # dimension per head, defaults to 128
rel_pos_emb = False , # use relative positional embedding - uses absolute if False
activation = nn . ReLU () # activation throughout the network
)
fmap = torch . randn ( 2 , 256 , 64 , 64 ) # feature map from previous resnet block(s)
layer ( fmap ) # (2, 2048, 32, 32) resnet에서 간단한 모델 작업을 수행하면 'BotNet'(참 이상한 이름)을 훈련용으로 사용할 수 있습니다.
import torch
from torch import nn
from torchvision . models import resnet50
from bottleneck_transformer_pytorch import BottleStack
layer = BottleStack (
dim = 256 ,
fmap_size = 56 , # set specifically for imagenet's 224 x 224
dim_out = 2048 ,
proj_factor = 4 ,
downsample = True ,
heads = 4 ,
dim_head = 128 ,
rel_pos_emb = True ,
activation = nn . ReLU ()
)
resnet = resnet50 ()
# model surgery
backbone = list ( resnet . children ())
model = nn . Sequential (
* backbone [: 5 ],
layer ,
nn . AdaptiveAvgPool2d (( 1 , 1 )),
nn . Flatten ( 1 ),
nn . Linear ( 2048 , 1000 )
)
# use the 'BotNet'
img = torch . randn ( 2 , 3 , 224 , 224 )
preds = model ( img ) # (2, 1000) @misc { srinivas2021bottleneck ,
title = { Bottleneck Transformers for Visual Recognition } ,
author = { Aravind Srinivas and Tsung-Yi Lin and Niki Parmar and Jonathon Shlens and Pieter Abbeel and Ashish Vaswani } ,
year = { 2021 } ,
eprint = { 2101.11605 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

