soundstorm pytorch
0.5.0
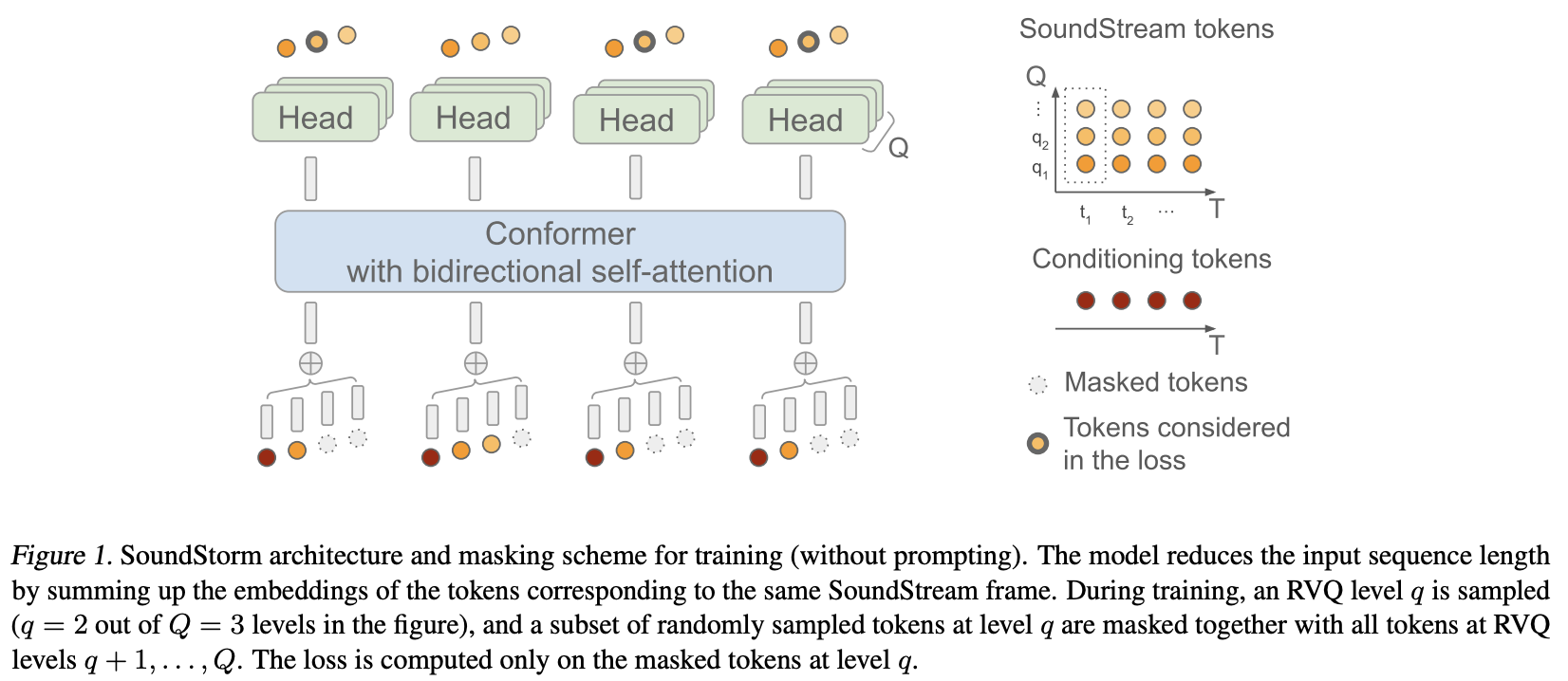
Google Deepmind의 효율적인 병렬 오디오 생성인 SoundStorm을 Pytorch에서 구현합니다.
그들은 기본적으로 Soundstream의 잔여 벡터 양자화 코드에 MaskGiT를 적용했습니다. 그들이 사용하기로 선택한 트랜스포머 아키텍처는 Conformer라는 오디오 도메인에 잘 맞는 아키텍처입니다.
프로젝트 페이지
안정성과? 최첨단 인공 지능 연구 및 오픈 소스 작업에 대한 아낌없는 후원을 위한 Huggingface
초기 훈련 코드, 음향 프롬프트 로직, 레벨별 양자화기 디코딩을 포함하여 수많은 기여를 해준 Lucas Newman!
? 교육을 위한 간단하고 강력한 솔루션 제공을 위한 Accelerate
신경망 구축을 재미있고, 쉽고, 기분 좋게 만드는 필수 추상화를 위한 Einops
올바른 마스킹 전략을 제출하고 저장소가 작동하는지 검증한 Steven Hillis!
Lucas Newman은 기본적으로 여러 저장소에 걸쳐 모델을 사용하여 소규모로 작동하는 Soundstorm을 교육하고 모든 작업이 엔드투엔드 방식으로 작동함을 보여주었습니다. 모델에는 SoundStream, Text-to-Semantic T5 및 마지막으로 SoundStorm 변환기가 포함됩니다.
반복적인 마스킹 해제에서 중요한 버그를 식별해 주신 @Jiang-Stan!
$ pip install soundstorm-pytorch import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
model = SoundStorm (
conformer ,
steps = 18 , # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# get your pre-encoded codebook ids from the soundstream from a lot of raw audio
codes = torch . randint ( 0 , 1024 , ( 2 , 1024 , 12 )) # (batch, seq, num residual VQ)
# do the below in a loop for a ton of data
loss , _ = model ( codes )
loss . backward ()
# model can now generate in 18 steps. ~2 seconds sounds reasonable
generated = model . generate ( 1024 , batch_size = 2 ) # (2, 1024) 원시 오디오를 직접 훈련하려면 사전 훈련된 SoundStream SoundStorm 에 전달해야 합니다. audiolm-pytorch에서 자신만의 SoundStream 훈련할 수 있습니다.
import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper , Conformer , SoundStream
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
soundstream = SoundStream (
codebook_size = 1024 ,
rq_num_quantizers = 12 ,
attn_window_size = 128 ,
attn_depth = 2
)
model = SoundStorm (
conformer ,
soundstream = soundstream # pass in the soundstream
)
# find as much audio you'd like the model to learn
audio = torch . randn ( 2 , 10080 )
# course it through the model and take a gazillion tiny steps
loss , _ = model ( audio )
loss . backward ()
# and now you can generate state-of-the-art speech
generated_audio = model . generate ( seconds = 30 , batch_size = 2 ) # generate 30 seconds of audio (it will calculate the length in seconds based off the sampling frequency and cumulative downsamples in the soundstream passed in above) 완전한 텍스트 음성 변환은 훈련된 TextToSemantic 인코더/디코더 변환기에 의존합니다. 그런 다음 가중치를 로드하고 이를 spear_tts_text_to_semantic 으로 SoundStorm 에 전달합니다.
spear-tts-pytorch 사전 훈련 + 의사 라벨링 + 역번역 논리가 아닌 모델 아키텍처만 완료되어 있으므로 이는 진행 중인 작업입니다.
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic (
dim = 512 ,
source_depth = 12 ,
target_depth = 12 ,
num_text_token_ids = 50000 ,
num_semantic_token_ids = 20000 ,
use_openai_tokenizer = True
)
# load the trained text-to-semantic transformer
text_to_semantic . load ( '/path/to/trained/model.pt' )
# pass it into the soundstorm
model = SoundStorm (
conformer ,
soundstream = soundstream ,
spear_tts_text_to_semantic = text_to_semantic
). cuda ()
# and now you can generate state-of-the-art speech
generated_speech = model . generate (
texts = [
'the rain in spain stays mainly in the plain' ,
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - raw waveform decoded from soundstream 사운드스트림 통합
생성할 때 길이는 초 단위로 정의할 수 있습니다(샘플링 주파수 등이 고려됨)
그룹화된 rvq가 지원되는지 확인하세요. 그룹 차원 전체의 합이 아닌 임베딩 연결
순응자를 복사하고 회전식 임베딩을 사용하여 Shaw의 상대 위치 임베딩을 다시 실행하세요. 아무도 더 이상 쇼를 사용하지 않습니다.
기본 플래시 주의는 사실입니다.
Batchnorm을 제거하고 단지 layernorm을 사용하되 swish 이후(norformformer 용지에서와 같이)
가속 기능이 있는 트레이너 - @lucasnewman에게 감사드립니다
forward mask 전달하고 generate 하여 가변 길이의 시퀀스 훈련 및 생성을 허용합니다.
생성 시 오디오 파일 목록을 반환하는 옵션
명령줄 도구로 전환
교차 주의 및 적응형 레이어 규범 조건화 추가
@misc { borsos2023soundstorm ,
title = { SoundStorm: Efficient Parallel Audio Generation } ,
author = { Zalán Borsos and Matt Sharifi and Damien Vincent and Eugene Kharitonov and Neil Zeghidour and Marco Tagliasacchi } ,
year = { 2023 } ,
eprint = { 2305.09636 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

