CenterSnap
1.0.0

이 저장소는 우리 논문의 pytorch 구현입니다. 
CenterSnap: 단일 샷 다중 객체 3D 형상 재구성 및 범주형 6D 포즈 및 크기 추정
무하마드 주바이르 이르샤드 , 토마스 콜라, 마이클 라스키, 케빈 스톤, 졸트 키라
2022년 ICRA(로봇공학 및 자동화에 관한 국제 회의)
[프로젝트 페이지] [arXiv] [PDF] [동영상] [포스터]
후속 ECCV'22 작업:
ShAPO: 다중 객체 모양, 모양 및 포즈 최적화를 위한 암시적 표현
무하마드 주바이르 이르샤드 , 세르게이 자카로프, 라레스 암브루스, 토마스 콜라, 졸트 키라, 아드리앙 가이돈
컴퓨터 비전에 관한 유럽 회의(ECCV), 2022
[프로젝트 페이지] [arXiv] [PDF] [동영상] [포스터]

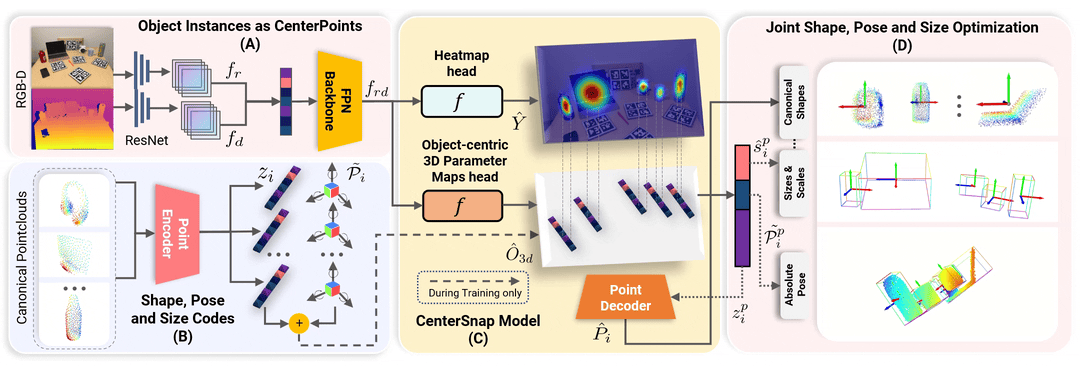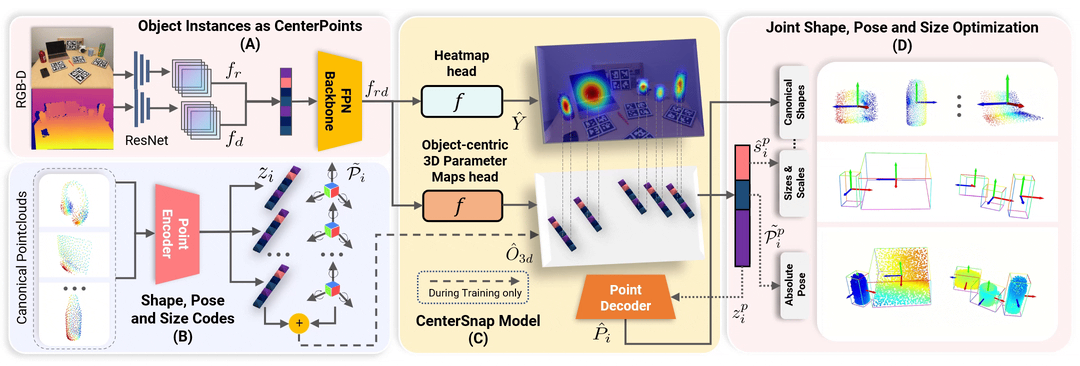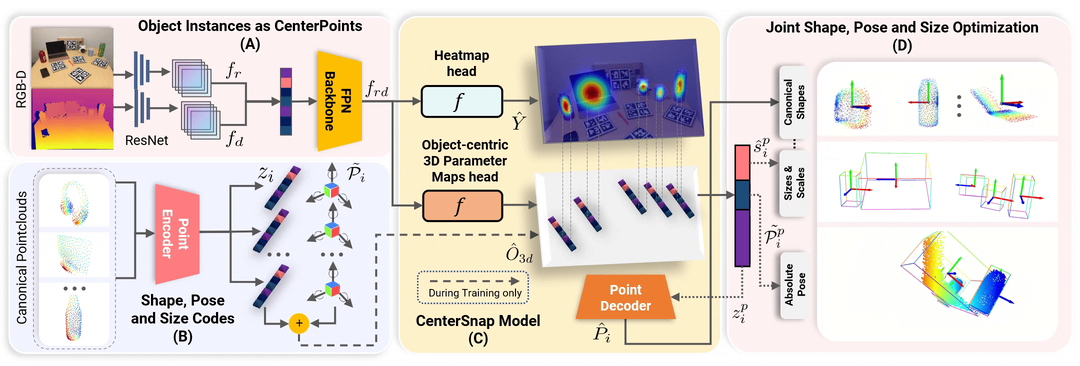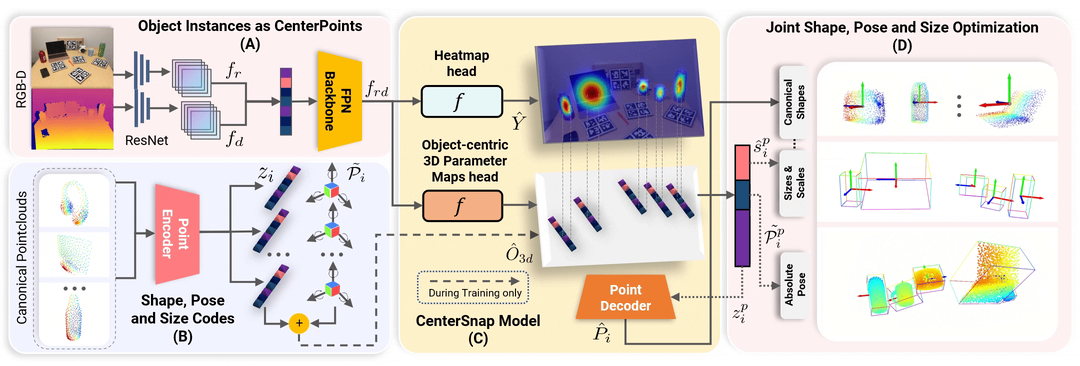
이 저장소가 유용하다고 생각되면 다음을 인용해 보세요.
@inproceedings{irshad2022centersnap,
title = {CenterSnap: Single-Shot Multi-Object 3D Shape Reconstruction and Categorical 6D Pose and Size Estimation},
author = {Muhammad Zubair Irshad and Thomas Kollar and Michael Laskey and Kevin Stone and Zsolt Kira},
journal = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2022}
}
@inproceedings{irshad2022shapo,
title = {ShAPO: Implicit Representations for Multi-Object Shape Appearance and Pose Optimization},
author = {Muhammad Zubair Irshad and Sergey Zakharov and Rares Ambrus and Thomas Kollar and Zsolt Kira and Adrien Gaidon},
journal = {European Conference on Computer Vision (ECCV)},
year = {2022}
}
Python 3.8 가상 환경을 만들고 요구 사항을 설치합니다.
cd $CenterSnap_Repo
conda create -y --prefix ./env python=3.8
conda activate ./env/
./env/bin/python -m pip install --upgrade pip
./env/bin/python -m pip install -r requirements.txt CUDA 버전에 따라 torch==1.7.1 torchvision==0.8.2 설치하세요. 코드는 cuda 10.2 에서 빌드되고 테스트되었습니다. cuda 10.2에 torch를 설치하는 샘플 명령은 다음과 같습니다:
pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2새로운 업데이트 : 몇 시간 안에 처음부터 자신의 데이터를 수집하려면 새로운 ECCV'22 작업 ShAPO 의 분산 스크립트를 확인하세요. 해당 분산 스크립트는 CenterSnap 에서 요구하는 것과 동일한 형식으로 데이터를 수집합니다. 단, 해당 저장소에 언급된 대로 몇 가지 사소한 수정이 필요합니다.
CenterSnap 모델을 훈련하고 평가하려면 사전 처리된 데이터 세트를 다운로드하는 것이 좋습니다. 합성(868GB) 및 실제(70GB) 데이터세트를 다운로드하고 압축을 해제하세요. 이 파일에는 결과를 복제하는 데 필요한 모든 교육 및 검증이 포함되어 있습니다.
cd $CenterSnap_REPO/data
wget https://tri-robotics-public.s3.amazonaws.com/centersnap/CAMERA.tar.gz
tar -xzvf CAMERA.tar.gz
wget https://tri-robotics-public.s3.amazonaws.com/centersnap/Real.tar.gz
tar -xzvf Real.tar.gz
데이터 디렉터리 구조는 다음과 같아야 합니다.
data
├── CAMERA
│ ├── train
│ └── val_subset
├── Real
│ ├── train
└── └── test
./runner.sh net_train.py @configs/net_config.txtrunner.sh는 Python을 사용하여 스크립트를 실행하는 것과 동일합니다. 또한 PYTHONPATH 및 CenterSnap 환경 경로를 자동으로 설정합니다.
./runner.sh net_train.py @configs/net_config_real_resume.txt --checkpoint p ath t o b est c heckpoint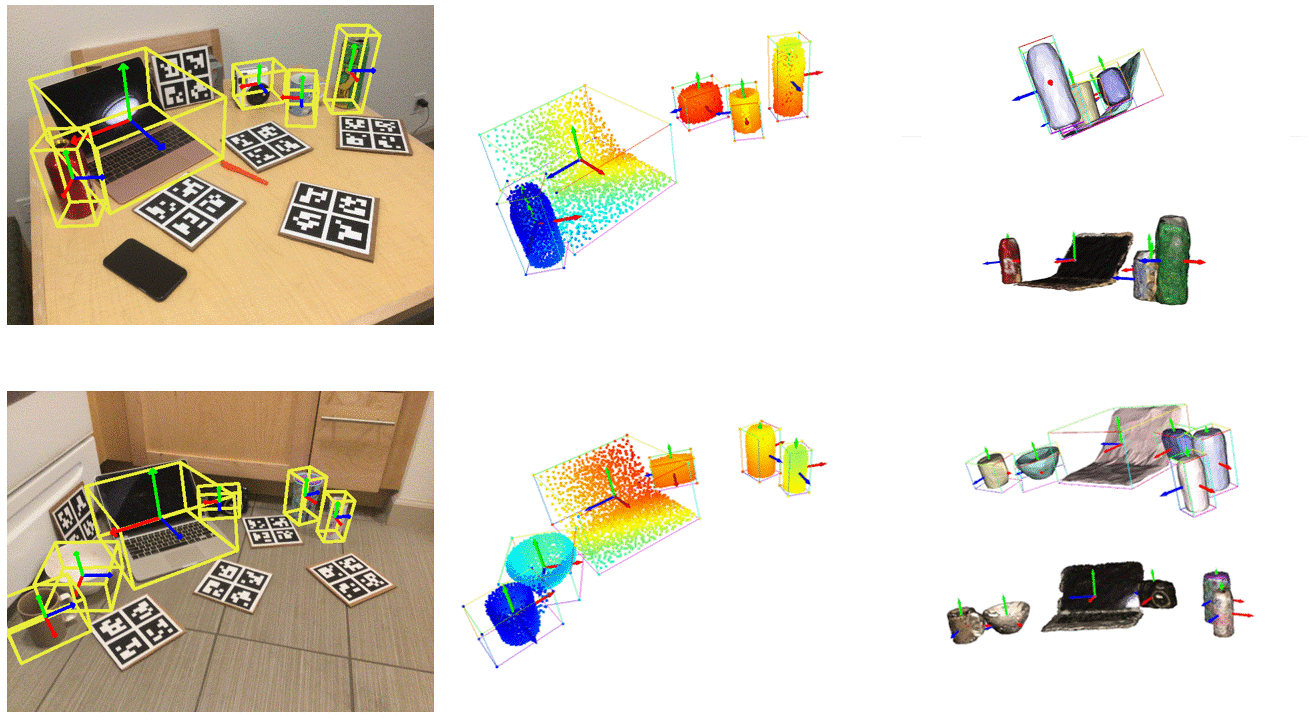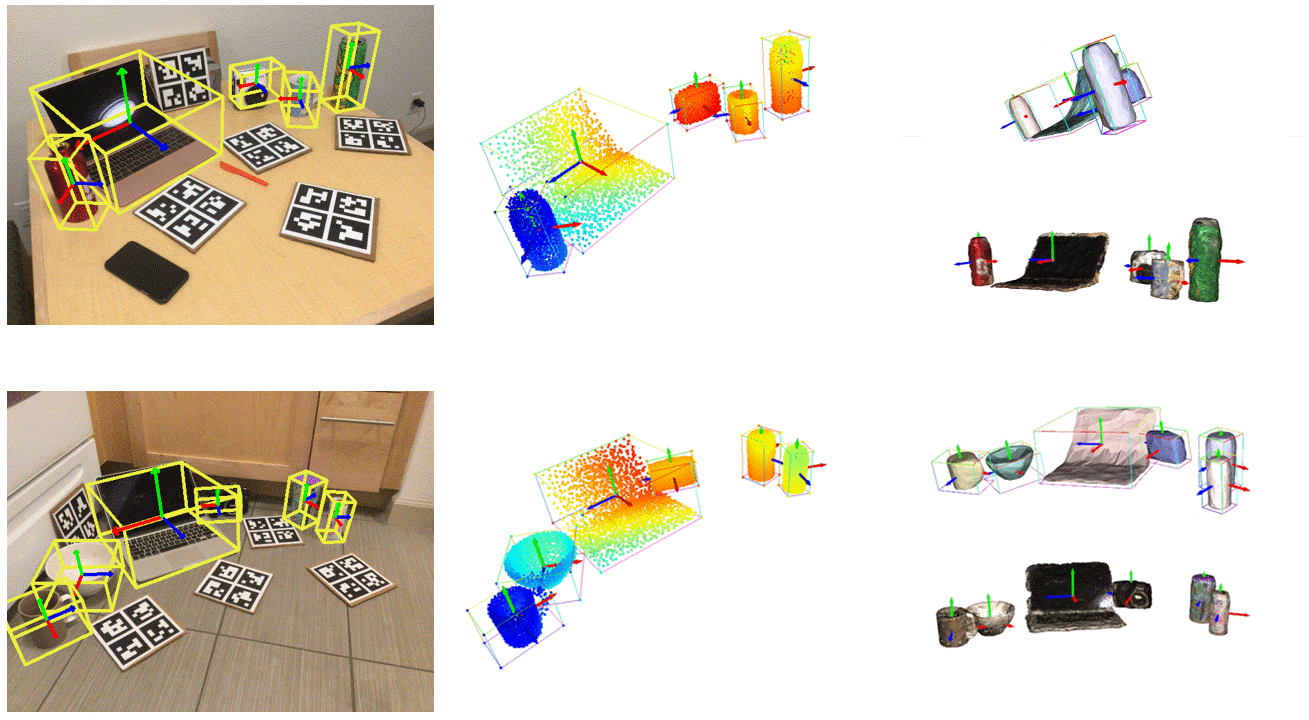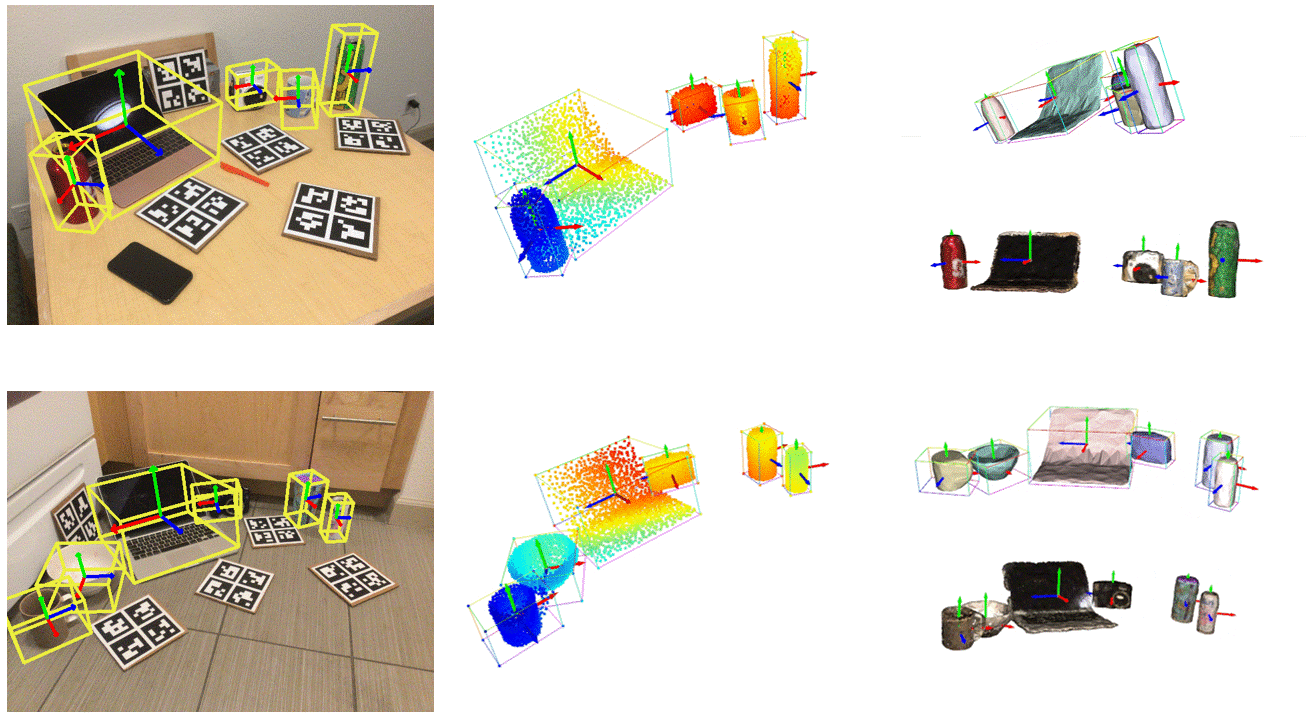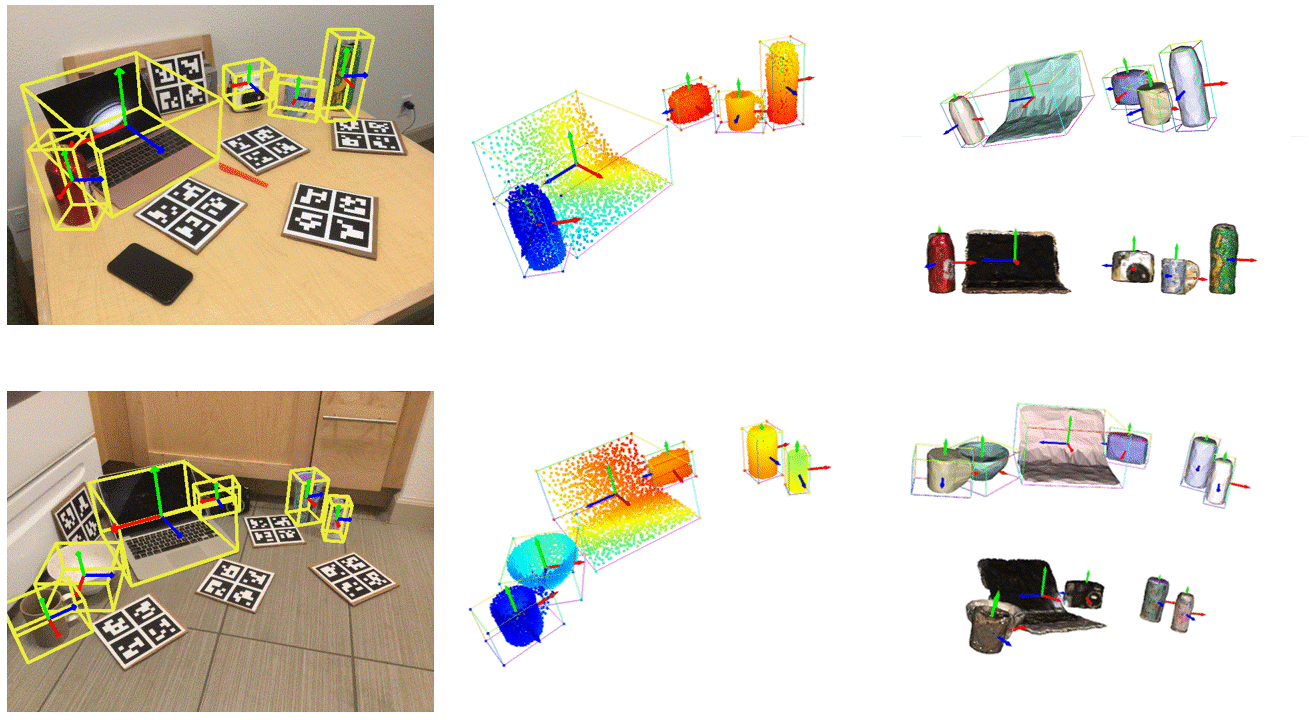
[여기]에서 작은 NOCS Real 하위 집합을 다운로드하세요.
./runner.sh inference/inference_real.py @configs/net_config.txt --data_dir path_to_nocs_test_subset --checkpoint checkpoint_path_here results/CenterSnap 에 저장된 시각화가 표시되어야 합니다. *config.txt에서 --ouput_path를 변경하여 다른 폴더에 저장하세요.
데이터 수집 및 추론에 사용될 형상 자동 인코더에 대한 사전 훈련된 모델을 제공합니다. 우리 코드베이스에서는 모양 자동 인코더를 별도로 훈련할 필요가 없지만 그렇게 하려는 경우 external/shape_pretraining 아래에 추가 스크립트를 제공합니다.
1. Realsense, OAK-D 또는 기타 사용자 정의 카메라 이미지에서 좋은 성능을 얻지 못합니다.
2. HSR 로봇 카메라에서 좋은 제로샷 결과를 생성하는 방법:
3. Colab을 실행하는 동안 no cuda GPUs available .
Make sure that you have enabled the GPU under Runtime-> Change runtime type!
4. raise RuntimeError('received %d items of ancdata' % RuntimeError: received 0 items of ancdata
uimit -n 2048 통해 ulimit를 2048 또는 8096으로 늘립니다. 5. RuntimeError: CUDA error: no kernel image is available for execution on the device You requested GPUs: [0] But your machine only has: []
cuda 10.2 설치 및 요구사항.txt에서 동일한 스크립트 실행
관련 Pytorch cuda 버전 설치, 즉 요구사항.txt에서 이 줄 변경
torch==1.7.1
torchvision==0.8.2
6. wandb 에 값이 0인 메트릭이 표시됩니다.
후속 ECCV 작업:
기타 후속 작품(훌륭한 작품을 만든 작가에게 감사 인사):


