iTransformer
0.8.0
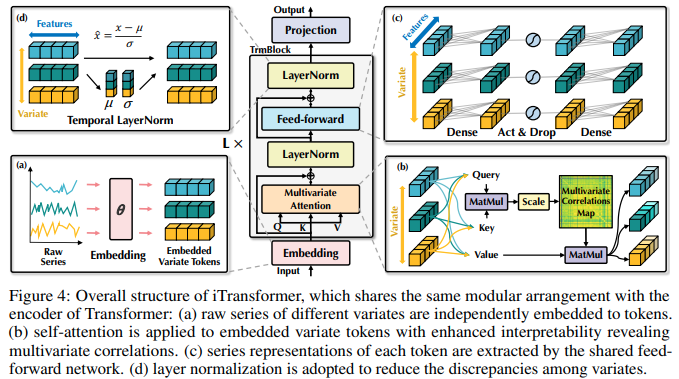
iTransformer 구현 - Tsinghua/Ant 그룹의 Attention 네트워크를 사용한 SOTA 시계열 예측
"주의가 필요한 전부입니다"라고 진정으로 선언하기 전에 남은 것은 표 형식 데이터(여기서는 여전히 xgboost가 여전히 챔피언임)뿐입니다.
Apple이 저자에게 이름을 변경하기 전에.
공식 구현이 여기에 공개되었습니다!
안정성AI와? 현재 인공 지능 기술을 오픈 소스로 사용할 수 있는 독립성을 제공해준 다른 후원자와 관대한 후원에 감사드립니다.
iTransformer 및 일부 즉석 변형에서 실행한 실험을 공유한 Greg DeVos
$ pip install iTransformer import torch
from iTransformer import iTransformer
# using solar energy settings
model = iTransformer (
num_variates = 137 ,
lookback_len = 96 , # or the lookback length in the paper
dim = 256 , # model dimensions
depth = 6 , # depth
heads = 8 , # attention heads
dim_head = 64 , # head dimension
pred_length = ( 12 , 24 , 36 , 48 ), # can be one prediction, or many
num_tokens_per_variate = 1 , # experimental setting that projects each variate to more than one token. the idea is that the network can learn to divide up into time tokens for more granular attention across time. thanks to flash attention, you should be able to accommodate long sequence lengths just fine
use_reversible_instance_norm = True # use reversible instance normalization, proposed here https://openreview.net/forum?id=cGDAkQo1C0p . may be redundant given the layernorms within iTransformer (and whatever else attention learns emergently on the first layer, prior to the first layernorm). if i come across some time, i'll gather up all the statistics across variates, project them, and condition the transformer a bit further. that makes more sense
)
time_series = torch . randn ( 2 , 96 , 137 ) # (batch, lookback len, variates)
preds = model ( time_series )
# preds -> Dict[int, Tensor[batch, pred_length, variate]]
# -> (12: (2, 12, 137), 24: (2, 24, 137), 36: (2, 36, 137), 48: (2, 48, 137)) 시간 토큰(및 원래 변수별 토큰)에 걸쳐 세부적인 주의를 기울이는 즉석 버전의 경우 iTransformer2D 가져오고 추가 num_time_tokens 를 설정하면 됩니다.
업데이트: 작동합니다! 여기서 실험을 진행해준 Greg DeVos에게 감사드립니다!
업데이트 2: 이메일을 받았습니다. 예, 아키텍처가 문제를 해결하는 경우 이에 대한 논문을 자유롭게 작성할 수 있습니다. 게임에 스킨이 없습니다.
import torch
from iTransformer import iTransformer2D
# using solar energy settings
model = iTransformer2D (
num_variates = 137 ,
num_time_tokens = 16 , # number of time tokens (patch size will be (look back length // num_time_tokens))
lookback_len = 96 , # the lookback length in the paper
dim = 256 , # model dimensions
depth = 6 , # depth
heads = 8 , # attention heads
dim_head = 64 , # head dimension
pred_length = ( 12 , 24 , 36 , 48 ), # can be one prediction, or many
use_reversible_instance_norm = True # use reversible instance normalization
)
time_series = torch . randn ( 2 , 96 , 137 ) # (batch, lookback len, variates)
preds = model ( time_series )
# preds -> Dict[int, Tensor[batch, pred_length, variate]]
# -> (12: (2, 12, 137), 24: (2, 24, 137), 36: (2, 36, 137), 48: (2, 48, 137)) iTransformer 및 푸리에 토큰 포함(시계열의 FFT는 자체 토큰으로 투영되고 끝에 연결되는 가변 토큰과 함께 참석됨)
import torch
from iTransformer import iTransformerFFT
# using solar energy settings
model = iTransformerFFT (
num_variates = 137 ,
lookback_len = 96 , # or the lookback length in the paper
dim = 256 , # model dimensions
depth = 6 , # depth
heads = 8 , # attention heads
dim_head = 64 , # head dimension
pred_length = ( 12 , 24 , 36 , 48 ), # can be one prediction, or many
num_tokens_per_variate = 1 , # experimental setting that projects each variate to more than one token. the idea is that the network can learn to divide up into time tokens for more granular attention across time. thanks to flash attention, you should be able to accommodate long sequence lengths just fine
use_reversible_instance_norm = True # use reversible instance normalization, proposed here https://openreview.net/forum?id=cGDAkQo1C0p . may be redundant given the layernorms within iTransformer (and whatever else attention learns emergently on the first layer, prior to the first layernorm). if i come across some time, i'll gather up all the statistics across variates, project them, and condition the transformer a bit further. that makes more sense
)
time_series = torch . randn ( 2 , 96 , 137 ) # (batch, lookback len, variates)
preds = model ( time_series )
# preds -> Dict[int, Tensor[batch, pred_length, variate]]
# -> (12: (2, 12, 137), 24: (2, 24, 137), 36: (2, 36, 137), 48: (2, 48, 137)) @misc { liu2023itransformer ,
title = { iTransformer: Inverted Transformers Are Effective for Time Series Forecasting } ,
author = { Yong Liu and Tengge Hu and Haoran Zhang and Haixu Wu and Shiyu Wang and Lintao Ma and Mingsheng Long } ,
year = { 2023 } ,
eprint = { 2310.06625 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { burtsev2020memory ,
title = { Memory Transformer } ,
author = { Mikhail S. Burtsev and Grigory V. Sapunov } ,
year = { 2020 } ,
eprint = { 2006.11527 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @Article { AlphaFold2021 ,
author = { Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and {v{Z}}{'i}dek, Augustin and Potapenko, Anna and Bridgland, Alex and Meyer, Clemens and Kohl, Simon A A and Ballard, Andrew J and Cowie, Andrew and Romera-Paredes, Bernardino and Nikolov, Stanislav and Jain, Rishub and Adler, Jonas and Back, Trevor and Petersen, Stig and Reiman, David and Clancy, Ellen and Zielinski, Michal and Steinegger, Martin and Pacholska, Michalina and Berghammer, Tamas and Bodenstein, Sebastian and Silver, David and Vinyals, Oriol and Senior, Andrew W and Kavukcuoglu, Koray and Kohli, Pushmeet and Hassabis, Demis } ,
journal = { Nature } ,
title = { Highly accurate protein structure prediction with {AlphaFold} } ,
year = { 2021 } ,
doi = { 10.1038/s41586-021-03819-2 } ,
note = { (Accelerated article preview) } ,
} @inproceedings { kim2022reversible ,
title = { Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift } ,
author = { Taesung Kim and Jinhee Kim and Yunwon Tae and Cheonbok Park and Jang-Ho Choi and Jaegul Choo } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=cGDAkQo1C0p }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.17897 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}

