rotary embedding torch
0.8.6
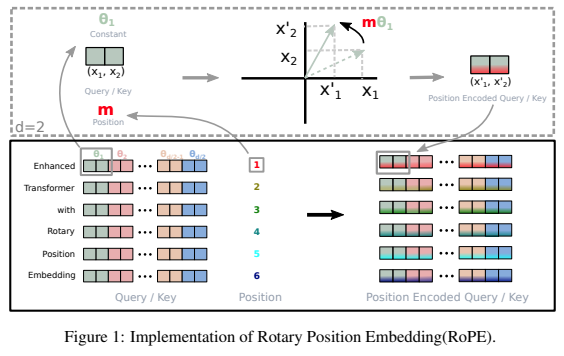
상대 위치 인코딩으로 성공을 거둔 Pytorch의 변환기에 회전식 임베딩을 추가하기 위한 독립 실행형 라이브러리입니다. 특히 위치 고정이든 학습이든 상관없이 정보를 텐서의 모든 축으로 쉽고 효율적으로 회전시킬 수 있습니다. 이 라이브러리는 적은 비용으로 위치 임베딩에 대한 최첨단 결과를 제공합니다.
내 직감은 또한 인공 신경망에서 활용될 수 있는 회전 외에 다른 것이 있다고 말합니다.
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usual위의 모든 단계를 올바르게 수행하면 훈련 중에 극적인 개선이 나타날 것입니다.
추론 시 키/값 캐시를 처리할 때 쿼리 위치는 key_value_seq_length - query_seq_length 로 오프셋되어야 합니다.
이를 쉽게 만들려면, rotate_queries_with_cached_keys 메소드를 사용하세요
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )다음과 같이 수동으로 이 작업을 수행할 수도 있습니다.
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])n차원 축 상대 위치 임베딩을 쉽게 사용할 수 있습니다. 비디오 변압기
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k ) 이 논문에서는 ALiBi와 유사한 붕괴를 제공하여 회전식 임베딩의 길이 외삽 문제를 해결할 수 있었습니다. 그들은 이 기술을 XPos라고 명명했으며, 초기화 시 use_xpos = True 설정하여 사용할 수 있습니다.
이는 자기회귀 변환기에만 사용할 수 있습니다.
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )이 MetaAI 논문은 사전 학습된 모델의 더 긴 컨텍스트 길이로 확장하기 위해 시퀀스 위치의 보간에 대한 간단한 미세 조정을 제안합니다. 그들은 이것이 동일한 시퀀스 위치에서 단순히 미세 조정하는 것보다 훨씬 더 나은 성능을 발휘하지만 더 확장된다는 것을 보여줍니다.
초기화 시 interpolate_factor 1. 보다 큰 값으로 설정하여 이를 사용할 수 있습니다. (예: 사전 훈련된 모델이 2048에서 훈련된 경우 interpolate_factor = 2. 설정하면 2048 x 2. = 4096 )
업데이트: 커뮤니티의 누군가가 제대로 작동하지 않는다고 보고했습니다. 긍정적이거나 부정적인 결과가 나타나면 이메일을 보내주세요.
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

