audiolm pytorch
2.2.3
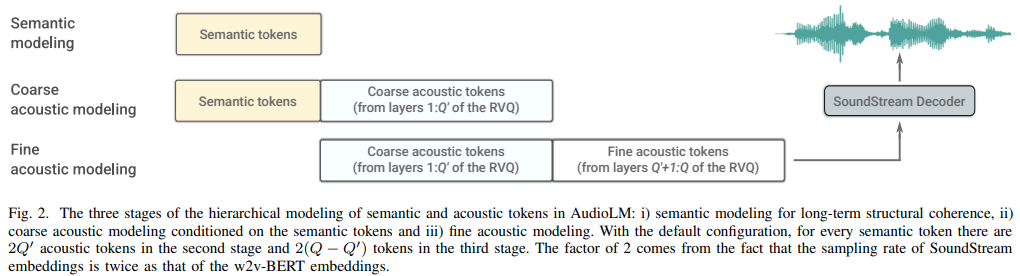
Pytorch에서 Google Research의 오디오 생성에 대한 언어 모델링 접근 방식인 AudioLM 구현
또한 T5를 사용하여 분류자 무료 안내를 통해 조건화 작업을 확장합니다. 이를 통해 논문에서는 제공되지 않는 텍스트-오디오 또는 TTS를 수행할 수 있습니다. 예, 이는 VALL-E가 이 저장소에서 훈련될 수 있음을 의미합니다. 본질적으로 동일합니다.
이 작품을 공개적으로 복제하는 데 관심이 있다면 가입하세요.
이제 이 저장소에는 SoundStream의 MIT 라이센스 버전도 포함되어 있습니다. 또한 이 글을 쓰는 시점에 MIT 라이선스를 받은 EnCodec과도 호환됩니다.
업데이트: AudioLM은 본질적으로 새로운 MusicLM에서 음악 생성을 '해결'하는 데 사용되었습니다.
미래에는 이 영화 클립이 더 이상 의미가 없게 될 것입니다. 대신 AI를 호출하면 됩니다.
Stability.ai 작업 및 오픈소스 최첨단 인공지능 연구에 대한 아낌없는 후원
? 놀라운 가속 및 변압기 라이브러리를 위한 Huggingface
Fairseq용 MetaAI 및 자유 라이센스
@eonglints와 Joseph은 전문적인 조언과 전문 지식은 물론 끌어오기 요청도 제공했습니다!
사운드스트림 디버깅에 도움을 주신 @djqualia, @yigityu, @inspirit 및 @BlackFox1197
코드를 검토하고 버그 수정을 제출해 주신 Allen 및 LWprogramming님!
다중 스케일 판별기 다운샘플링 문제를 찾아내고 사운드스트림 트레이너를 개선해 주신 Ilya
사운드스트림에서 누락된 손실을 식별하고 적절한 멜 스펙트로그램 하이퍼파라미터를 안내해 준 Andrey
훈련 사운드스트림을 통해 결과를 공유하고 로컬 어텐션 위치 임베딩과 관련된 몇 가지 문제를 해결한 Alejandro와 Ilya
인코딩 호환성을 추가하는 LW 프로그래밍!
FineTransformer 에서 샘플링할 때 EOS 토큰 처리 문제를 찾기 위한 LWprogramming !
@YoungloLee는 보폭을 고려하지 않는 패딩과 관련된 사운드 스트림에 대한 1D 인과 컨볼루션의 큰 버그를 식별했습니다!
Soundstream의 다중 스케일 판별기의 일부 불일치를 지적한 Hayden
$ pip install audiolm-pytorch신경 코덱에는 두 가지 옵션이 있습니다. 사전 훈련된 24kHz Encodec을 사용하려면 다음과 같이 Encodec 객체를 생성하면 됩니다.
from audiolm_pytorch import EncodecWrapper
encodec = EncodecWrapper ()
# Now you can use the encodec variable in the same way you'd use the soundstream variables below. 그렇지 않으면 원본 논문에 더 충실하려면 SoundStream 사용할 수 있습니다. 첫째, SoundStream 대규모 오디오 데이터 모음에 대해 교육을 받아야 합니다.
from audiolm_pytorch import SoundStream , SoundStreamTrainer
soundstream = SoundStream (
codebook_size = 4096 ,
rq_num_quantizers = 8 ,
rq_groups = 2 , # this paper proposes using multi-headed residual vector quantization - https://arxiv.org/abs/2305.02765
use_lookup_free_quantizer = True , # whether to use residual lookup free quantization - there are now reports of successful usage of this unpublished technique
use_finite_scalar_quantizer = False , # whether to use residual finite scalar quantization
attn_window_size = 128 , # local attention receptive field at bottleneck
attn_depth = 2 # 2 local attention transformer blocks - the soundstream folks were not experts with attention, so i took the liberty to add some. encodec went with lstms, but attention should be better
)
trainer = SoundStreamTrainer (
soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 4 ,
grad_accum_every = 8 , # effective batch size of 32
data_max_length_seconds = 2 , # train on 2 second audio
num_train_steps = 1_000_000
). cuda ()
trainer . train ()
# after a lot of training, you can test the autoencoding as so
soundstream . eval () # your soundstream must be in eval mode, to avoid having the residual dropout of the residual VQ necessary for training
audio = torch . randn ( 10080 ). cuda ()
recons = soundstream ( audio , return_recons_only = True ) # (1, 10080) - 1 channel 그러면 훈련된 SoundStream 오디오용 일반 토크나이저로 사용할 수 있습니다.
audio = torch . randn ( 1 , 512 * 320 )
codes = soundstream . tokenize ( audio )
# you can now train anything with the codebook ids
recon_audio_from_codes = soundstream . decode_from_codebook_indices ( codes )
# sanity check
assert torch . allclose (
recon_audio_from_codes ,
soundstream ( audio , return_recons_only = True )
) AudioLMSoundStream 및 MusicLMSoundStream 각각 가져와서 AudioLM 및 MusicLM 에 특정한 사운드 스트림을 사용할 수도 있습니다.
from audiolm_pytorch import AudioLMSoundStream , MusicLMSoundStream
soundstream = AudioLMSoundStream (...) # say you want the hyperparameters as in Audio LM paper
# rest is the same as above 버전 0.17.0 부터 이제 구성을 기억할 필요 없이 SoundStream 의 클래스 메서드를 호출하여 체크포인트 파일에서 로드할 수 있습니다.
from audiolm_pytorch import SoundStream
soundstream = SoundStream . init_and_load_from ( './path/to/checkpoint.pt' ) 가중치 및 편향 추적을 사용하려면 먼저 SoundStreamTrainer 에서 use_wandb_tracking = True 설정한 후 다음을 수행하세요.
trainer = SoundStreamTrainer (
soundstream ,
...,
use_wandb_tracking = True
)
# wrap .train() with contextmanager, specifying project and run name
with trainer . wandb_tracker ( project = 'soundstream' , run = 'baseline' ):
trainer . train () 그런 다음 세 개의 별도 변환기( SemanticTransformer , CoarseTransformer , FineTransformer )를 훈련해야 합니다.
전. SemanticTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
# hubert checkpoints can be downloaded at
# https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
flash_attn = True
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () 전. CoarseTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SoundStream , CoarseTransformer , CoarseTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
coarse_transformer = CoarseTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
codebook_size = 1024 ,
num_coarse_quantizers = 3 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = CoarseTransformerTrainer (
transformer = coarse_transformer ,
codec = soundstream ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train () 전. FineTransformer
import torch
from audiolm_pytorch import SoundStream , FineTransformer , FineTransformerTrainer
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
fine_transformer = FineTransformer (
num_coarse_quantizers = 3 ,
num_fine_quantizers = 5 ,
codebook_size = 1024 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = FineTransformerTrainer (
transformer = fine_transformer ,
codec = soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()이제 모두 함께
from audiolm_pytorch import AudioLM
audiolm = AudioLM (
wav2vec = wav2vec ,
codec = soundstream ,
semantic_transformer = semantic_transformer ,
coarse_transformer = coarse_transformer ,
fine_transformer = fine_transformer
)
generated_wav = audiolm ( batch_size = 1 )
# or with priming
generated_wav_with_prime = audiolm ( prime_wave = torch . randn ( 1 , 320 * 8 ))
# or with text condition, if given
generated_wav_with_text_condition = audiolm ( text = [ 'chirping of birds and the distant echos of bells' ])업데이트: 'VALL-E'를 고려하면 이것이 작동할 것 같습니다.
전. 의미 변환기
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = 500 ,
dim = 1024 ,
depth = 6 ,
has_condition = True , # this will have to be set to True
cond_as_self_attn_prefix = True # whether to condition as prefix to self attention, instead of cross attention, as was done in 'VALL-E' paper
). cuda ()
# mock text audio dataset (as an example)
# you will have to extend your own from `Dataset`, and return an audio tensor as well as a string (the audio description) in any order (the framework will autodetect and route it into the transformer)
from torch . utils . data import Dataset
class MockTextAudioDataset ( Dataset ):
def __init__ ( self , length = 100 , audio_length = 320 * 32 ):
super (). __init__ ()
self . audio_length = audio_length
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
mock_audio = torch . randn ( self . audio_length )
mock_caption = 'audio caption'
return mock_caption , mock_audio
dataset = MockTextAudioDataset ()
# instantiate semantic transformer trainer and train
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
dataset = dataset ,
batch_size = 4 ,
grad_accum_every = 8 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()
# after much training above
sample = trainer . generate ( text = [ 'sound of rain drops on the rooftops' ], batch_size = 1 , max_length = 2 ) # (1, < 128) - may terminate early if it detects [eos] 모든 트레이너 클래스가 ? Accelerator, accelerate 명령을 사용하면 쉽게 멀티 GPU 훈련을 할 수 있습니다.
프로젝트 루트에서
$ accelerate config그런 다음 동일한 디렉토리에서
$ accelerate launch train . py CoarseTransformer를 완료하세요.
임베딩에 fairseq vq-wav2vec 사용
조건 추가
분류자 무료 안내 추가
다음에 고유한 연속 추가
eonglints에서 권장하는 Hubert 중간 기능을 의미론적 토큰으로 사용하는 기능을 통합합니다.
가변 길이의 오디오를 수용하고 EOS 토큰을 가져옵니다.
거친 변압기를 사용하여 고유한 연속 작업을 수행하는지 확인하십시오.
모든 판별기 손실을 로그에 예쁘게 인쇄
의미론적 토큰을 생성할 때 마지막 로짓이 고유한 연속 처리를 고려할 때 반드시 시퀀스의 마지막이 아닐 수도 있음을 처리합니다.
Coarse 및 Fine Transformer 모두에 대한 완전한 샘플링 코드(까다로울 것임)
AudioLM 클래스에서 메시지를 표시하거나 표시하지 않고 전체 추론이 작동하는지 확인하세요.
판별자 훈련을 처리하여 사운드스트림에 대한 전체 훈련 코드를 완성합니다.
사운드 스트림의 판별자에 효율적인 그래디언트 페널티 추가
사운드 데이터 세트 -> 변환기에서 샘플 hz를 연결하고 훈련 중에 적절한 리샘플링을 갖습니다. 데이터 세트가 다양한 사운드 파일을 갖도록 허용할지 아니면 동일한 샘플 hz를 적용할지 생각해 보세요.
세 가지 변압기 모두에 대한 전체 변압기 교육 코드
리팩토링하여 의미론적 변환기에는 고유한 연속 문자와 wav를 Hubert 또는 vq-wav2vec로 처리하는 래퍼가 있습니다.
단순히 프롬프트 측의 EOS 토큰에 자체 주의를 기울이지 않습니다(거친 변환기의 경우 의미, 미세 변환기의 경우 거친 의미).
건망증 인과 마스킹에서 구조화된 드롭아웃을 추가합니다. 이는 기존 드롭아웃보다 훨씬 좋습니다.
fairseq에서 로그인을 억제하는 방법 알아보기
audiolm에 전달된 세 개의 변환기가 모두 호환되는지 확인
Coarse와 Fine 사이의 양자화기의 절대 매칭 위치를 기반으로 Fine Transformer의 특수한 상대 위치 임베딩을 허용합니다.
hifi-codec의 사운드 스트림에서 그룹화된 잔여 vq 허용(벡터-양자화-pytorch lib의 GroupedResidualVQ 사용)
NoPE로 순간의 관심을 더해보세요
AudioLM 의 프라임 웨이브를 오디오 파일의 경로로 허용하고 의미론적 대 음향적 자동 리샘플링
모든 변환기에 키/값 캐싱을 추가하여 추론 속도를 높입니다.
계층적 거친 변환기와 미세한 변환기 설계
사양 디코딩을 조사하고 먼저 x-transformer에서 테스트한 다음 해당하는 경우 포트 오버합니다.
잔여 vq에 그룹이 있는 경우 위치 임베딩을 다시 실행합니다.
초보자를 위한 음성 합성 테스트
audiolm generate <wav.file | text> 생성된 wav 파일을 로컬 디렉터리에 저장합니다.
가변 길이 오디오의 경우 웨이브 목록을 반환합니다.
원시 파동이 서로 다른 주파수에서 리샘플링되는 거친 변환기 텍스트 조건 훈련에서 가장자리 사례를 처리하세요. 길이에 따라 라우팅 방법을 자동 결정
@inproceedings { Borsos2022AudioLMAL ,
title = { AudioLM: a Language Modeling Approach to Audio Generation } ,
author = { Zal{'a}n Borsos and Rapha{"e}l Marinier and Damien Vincent and Eugene Kharitonov and Olivier Pietquin and Matthew Sharifi and Olivier Teboul and David Grangier and Marco Tagliasacchi and Neil Zeghidour } ,
year = { 2022 }
} @misc { https://doi.org/10.48550/arxiv.2107.03312 ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco } ,
publisher = { arXiv } ,
url = { https://arxiv.org/abs/2107.03312 } ,
year = { 2021 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @article { Ho2022ClassifierFreeDG ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.12598 }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/rivershavewings }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Liu2022FCMFC ,
title = { FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners } ,
author = { Hao Liu and Xinyang Geng and Lisa Lee and Igor Mordatch and Sergey Levine and Sharan Narang and P. Abbeel } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13432 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Li2021LocalViTBL ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and K. Zhang and Jie Cao and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2104.05707 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @article { Hu2017SqueezeandExcitationN ,
title = { Squeeze-and-Excitation Networks } ,
author = { Jie Hu and Li Shen and Gang Sun } ,
journal = { 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
year = { 2017 } ,
pages = { 7132-7141 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @article { Kazemnejad2023TheIO ,
title = { The Impact of Positional Encoding on Length Generalization in Transformers } ,
author = { Amirhossein Kazemnejad and Inkit Padhi and Karthikeyan Natesan Ramamurthy and Payel Das and Siva Reddy } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.19466 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

