routing transformer
1.6.1
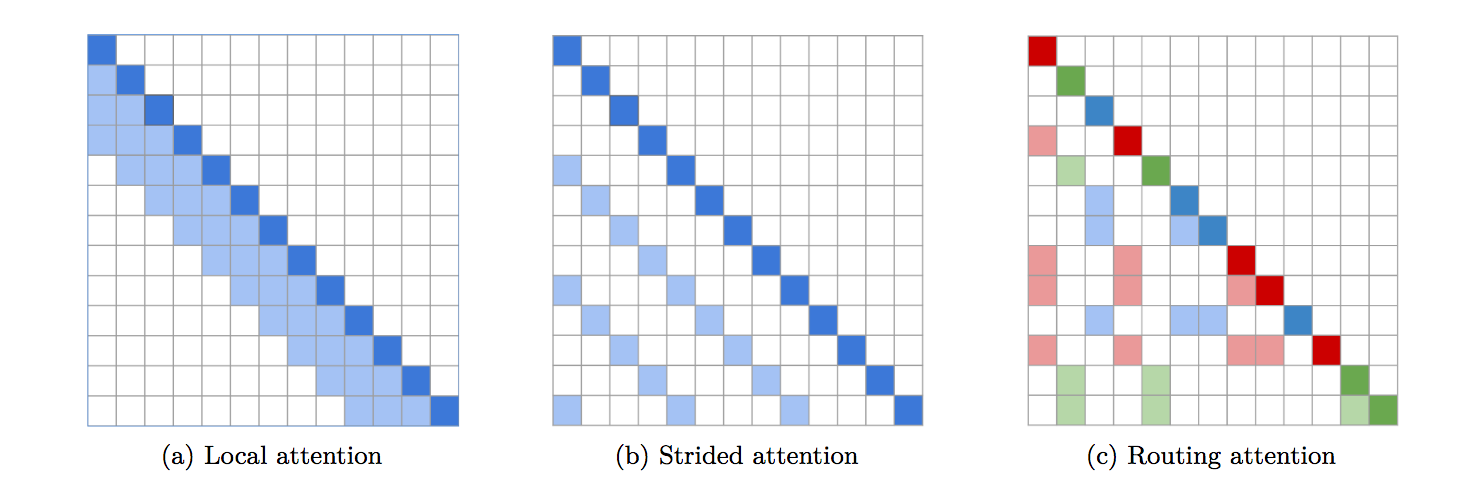
Routing Transformer의 모든 기능을 갖춘 구현입니다. 이 논문에서는 k-평균을 사용하여 유사한 쿼리/키를 동일한 클러스터로 라우팅하여 주의를 끌 것을 제안합니다.
131,000개 토큰
$ pip install routing_transformer간단한 언어 모델
import torch
from routing_transformer import RoutingTransformerLM
model = RoutingTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
causal = True , # auto-regressive or not
emb_dim = 128 , # embedding factorization, from Albert
weight_tie = False , # weight tie layers, from Albert
tie_embedding = False , # multiply final embeddings with token weights for logits
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
attn_dropout = 0.1 , # dropout after attention
attn_layer_dropout = 0. , # dropout after self attention layer
ff_dropout = 0.1 , # feedforward dropout
layer_dropout = 0. , # layer dropout
window_size = 128 , # target window size of each cluster
n_local_attn_heads = 4 , # number of local attention heads
reversible = True , # reversible networks for memory savings, from Reformer paper
ff_chunks = 10 , # feed forward chunking, from Reformer paper
ff_glu = True , # use GLU variant in feedforward
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
moe_layers = ( 3 , 6 ), # specify which layers to use mixture of experts
moe_num_experts = 4 , # number of experts in the mixture of experts layer, defaults to 4. increase for adding more parameters to model
moe_loss_coef = 1e-2 , # the weight for the auxiliary loss in mixture of experts to keep expert usage balanced
num_mem_kv = 8 , # number of memory key/values to append to each cluster of each head, from the 'All-Attention' paper. defaults to 1 in the causal case for unshared QK to work
use_scale_norm = False , # use scale norm, simplified normalization from 'Transformers without Tears' paper
use_rezero = False , # use Rezero with no normalization
shift_tokens = True # shift tokens by one along sequence dimension, for a slight improvement in convergence
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , 8192 )). long (). cuda ()
input_mask = torch . ones_like ( x ). bool (). cuda ()
y , aux_loss = model ( x , input_mask = input_mask ) # (1, 8192, 20000)
aux_loss . backward () # add auxiliary loss to main loss before backprop간단한 변압기
import torch
from routing_transformer import RoutingTransformer
model = RoutingTransformer (
dim = 512 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
window_size = 128 ,
n_local_attn_heads = 4
). cuda ()
x = torch . randn ( 1 , 8192 , 512 ). cuda ()
input_mask = torch . ones ( 1 , 8192 ). bool (). cuda ()
y , aux_loss = model ( x , input_mask = input_mask ) # (1, 8192, 512)
aux_loss . backward () # add auxiliary loss to main loss before backprop 전체 인코더, 디코더를 사용하려면 RoutingTransformerEncDec 클래스를 가져오기만 하면 됩니다. dim 키워드를 저장하면 다른 모든 키워드에는 각각 인코더 및 디코더 RoutingTransformerLM 클래스에 대해 enc_ 또는 dec_ 가 추가됩니다.
import torch
from routing_transformer import RoutingTransformerEncDec
model = RoutingTransformerEncDec (
dim = 512 ,
enc_num_tokens = 20000 ,
enc_depth = 4 ,
enc_heads = 8 ,
enc_max_seq_len = 4096 ,
enc_window_size = 128 ,
dec_num_tokens = 20000 ,
dec_depth = 4 ,
dec_heads = 8 ,
dec_max_seq_len = 4096 ,
dec_window_size = 128 ,
dec_reversible = True
). cuda ()
src = torch . randint ( 0 , 20000 , ( 1 , 4096 )). cuda ()
tgt = torch . randint ( 0 , 20000 , ( 1 , 4096 )). cuda ()
src_mask = torch . ones_like ( src ). bool (). cuda ()
tgt_mask = torch . ones_like ( tgt ). bool (). cuda ()
loss , aux_loss = model ( src , tgt , enc_input_mask = src_mask , dec_input_mask = tgt_mask , return_loss = True , randomly_truncate_sequence = True )
loss . backward ()
aux_loss . backward ()
# do your training, then to sample up to 2048 tokens based on the source sequence
src = torch . randint ( 0 , 20000 , ( 1 , 4096 )). cuda ()
start_tokens = torch . ones ( 1 , 1 ). long (). cuda () # assume starting token is 1
sample = model . generate ( src , start_tokens , seq_len = 2048 , eos_token = 2 ) # (1, <= 2048, 20000) PKM 사용의 이점을 보려면 값의 학습률을 나머지 매개변수보다 높게 설정해야 합니다. ( 1e-2 권장)
여기 지침에 따라 올바르게 설정할 수 있습니다 https://github.com/lucidrains/product-key-memory#learning-rates
kmeans_ema_decay = {defaults to 0.999}이는 k-평균을 업데이트하기 위한 지수 이동 평균 감쇠입니다. 이 값이 낮을수록 수단이 더 빨리 조정되지만 안정성이 저하됩니다.
commitment_factor = {defaults to 1e-4}토큰이 선택된 k-평균 중심에 더 가까워지도록(커밋) 장려하는 보조 손실의 가중치입니다.
다음 지침을 사용하면 kmeans를 수동으로 업데이트할 수 있습니다. 기본적으로 kmeans는 모든 역방향 패스에서 자동으로 업데이트됩니다.
import torch
from routing_transformer import RoutingTransformerLM , AutoregressiveWrapper
model = RoutingTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 6 ,
window_size = 256 ,
max_seq_len = 8192 ,
causal = True ,
_register_kmeans_update = False # set to False to disable auto-updating
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True )
loss . backward ()
# update kmeans with this call
model . update_kmeans ()이 아키텍처는 1 -> 최대 시퀀스 길이에서 토큰을 디코딩할 때 더 짧은 시퀀스 길이로 일반화하는 데 문제가 있습니다. 가장 간단하고 확실한 해결책은 훈련 중에 시퀀스를 무작위로 자르는 것입니다. 이는 장기간의 훈련 비용으로 네트워크와 kmean이 다양한 수의 토큰으로 일반화되는 데 도움이 됩니다.
시작 시 전체 시퀀스 길이로 네트워크를 프라이밍하는 경우 이 문제가 발생하지 않으며 이 훈련 절차를 건너뛸 수 있습니다.
import torch
from routing_transformer import RoutingTransformerLM , AutoregressiveWrapper
model = RoutingTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
window_size = 256 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000) 이 라이브러리로 발전한 Pytorch의 초기 구현을 부트스트래핑해준 Aran Komatsuzaki에게 특별히 감사드립니다.
@misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://arxiv.org/pdf/2003.05997.pdf }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @article { DBLP:journals/corr/abs-1907-01470 ,
author = { Sainbayar Sukhbaatar and
Edouard Grave and
Guillaume Lample and
Herv{'{e}} J{'{e}}gou and
Armand Joulin } ,
title = { Augmenting Self-attention with Persistent Memory } ,
journal = { CoRR } ,
volume = { abs/1907.01470 } ,
year = { 2019 } ,
url = { http://arxiv.org/abs/1907.01470 }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
} @article { 1910.05895 ,
author = { Toan Q. Nguyen and Julian Salazar } ,
title = { Transformers without Tears: Improving the Normalization of Self-Attention } ,
year = { 2019 } ,
eprint = { arXiv:1910.05895 } ,
doi = { 10.5281/zenodo.3525484 } ,
} @misc { bachlechner2020rezero ,
title = { ReZero is All You Need: Fast Convergence at Large Depth } ,
author = { Thomas Bachlechner and Bodhisattwa Prasad Majumder and Huanru Henry Mao and Garrison W. Cottrell and Julian McAuley } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2003.04887 }
} @misc { vaswani2017attention ,
title = { Attention Is All You Need } ,
author = { Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin } ,
year = { 2017 } ,
eprint = { 1706.03762 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
}

