CoLT5 attention
0.11.1
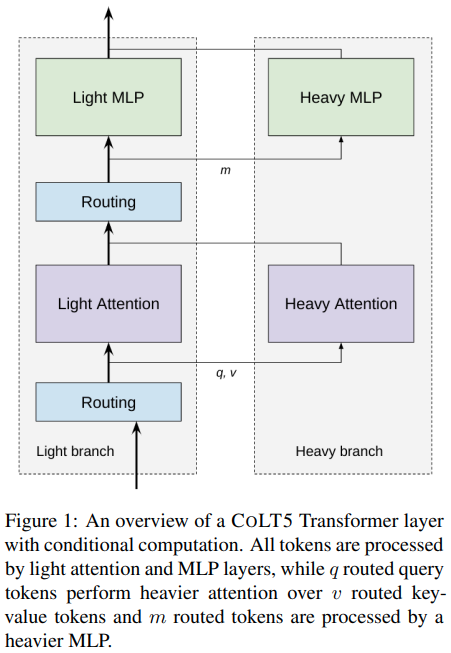
제안된 CoLT5 아키텍처의 조건부 라우팅 효율적인 주의를 Pytorch에서 구현합니다.
그들은 피드포워드 및 어텐션 블록의 '무거운' 분기에 대한 토큰 하위 집합을 라우팅하기 위해 이 문서(원래 Wright 등의 주요 알고리즘)의 좌표 하강을 사용했습니다.
업데이트: 키-값에 대한 라우팅 정규화 점수가 어떻게 사용되는지 확실하지 않습니다. 즉흥적으로 예상 값의 크기를 조정했지만 답을 알고 있다고 생각되면 문제를 열어주세요.
업데이트 2: 위의 즉흥 연주와 잘 어울리는 것 같습니다.
최첨단 인공지능 연구를 위한 Stability.ai의 아낌없는 후원
내 삶을 편하게 해주는 einops
수천 줄의 CUDA 코드를 작성할 필요 없이 단 2일 만에 통합 구현을 통해 좌표 하강 속도를 높일 수 있게 해 준 Triton
$ pip install colt5-attention import torch
from colt5_attention import (
ConditionalRoutedFeedForward ,
ConditionalRoutedAttention ,
ConditionalRoutedTransformerBlock
)
# mock input, say it is 32768 length
tokens = torch . randn ( 2 , 32768 , 512 )
mask = torch . ones ( 2 , 32768 ). bool () # can handle variable lengthed sequences
# feedforward
ff = ConditionalRoutedFeedForward (
dim = 512 ,
light_ff_mult = 0.5 , # hidden dimension ratio of light branch
heavy_ff_mult = 4 , # hidden dimension ratio of heavy branch
num_heavy_tokens = 1024 # heavy branch receives only 1024 routed tokens of 32768
)
ff_out = ff ( tokens , mask = mask ) # (2, 32768, 512) - light and heavy branch summed
# attention
attn = ConditionalRoutedAttention (
dim = 512 ,
light_dim_head = 64 , # attention head dimension of light branch
light_heads = 8 , # number of attention heads for light branch
light_window_size = 128 , # local attention receptive field for light
heavy_dim_head = 64 , # attention head dimension of heavy branch
heavy_heads = 8 , # number of attention heads for heavy branch
num_heavy_tokens_q = 1024 , # heavy branch receives only 1024 routed tokens of 32768
num_heavy_tokens_kv = 1024 # heavy branch receives only 1024 routed tokens of 32768
)
attn_out = attn ( tokens , mask = mask ) # (2, 32768, 512) - light and heavy branch summed
# both attention and feedforward with residual
# the complete transformer block
# a stack of these would constitute the encoder of CoLT5
block = ConditionalRoutedTransformerBlock (
dim = 512 ,
light_dim_head = 64 ,
light_heads = 8 ,
light_window_size = 128 ,
heavy_dim_head = 64 ,
heavy_heads = 8 ,
light_ff_mult = 0.5 ,
heavy_ff_mult = 4 ,
num_heavy_ff_tokens = 1024 ,
num_heavy_attn_tokens_q = 1024 ,
num_heavy_attn_tokens_kv = 1024
)
block_out = block ( tokens , mask = mask ) # (2, 32768, 512)또한 교차 주의를 위한 조건부 라우팅 주의의 변형이 포함되어 있으며, Transformer-xl에서 긴 상황 기억으로 시도됩니다.
import torch
from colt5_attention import ConditionalRoutedCrossAttention
# mock input, let us say it is a transformer of 1024 length attending to 1 million context past memories
tokens = torch . randn ( 1 , 1024 , 512 ). cuda ()
tokens_mask = torch . ones ( 1 , 1024 ). bool (). cuda ()
memories = torch . randn ( 1 , 1_048_576 , 512 ). cuda ()
memories_mask = torch . ones ( 1 , 1_048_576 ). bool (). cuda ()
# conditionally routed cross attention
cross_attn = ConditionalRoutedCrossAttention (
dim = 512 ,
dim_head = 64 ,
heads = 8 ,
num_tokens_q = 512 , # only 512 routed from 1024
num_tokens_kv = 1024 , # only 1024 routed from 1 million
kv_routing_tokens = 2 , # say you want 2 routing tokens to route different sets of key / values to the queries. 4 attention heads will be allocated to each routed set in this example (8 / 2)
use_triton = True , # use cuda kernel
route_block_size = 131072 # route in blocks of 131072
). cuda ()
cross_attn_out = cross_attn (
tokens ,
context = memories ,
mask = tokens_mask ,
context_mask = memories_mask
)
cross_attn_out . shape # (1, 1024, 512) - same as tokens이 저장소에는 자동 회귀 주의를 위한 즉석 버전도 있습니다. 이를 달성한 방법은 창에서 시퀀스를 보는 것이었습니다. 각 창은 과거의 키/값 창에만 주의를 기울일 수 있습니다. 빛 가지의 국소적 관심은 창 내 관심을 커버합니다.
좌표 하강은 Triton으로 작성된 CUDA 커널을 통해 실행 가능해졌습니다. 마지막으로 자동 회귀 생성이 제대로 작동하도록 하려면 라우팅되지 않은 토큰(쿼리용)이 단지 0이 아닌 학습된 출력 임베딩을 출력하는지 확인해야 했습니다.
현재 반복 횟수가 20을 초과하면 그라디언트(매우 작은 부분의 요소에 대해 1e-1만큼 높음) 간의 간헐적인 차이가 나타납니다. 그러나 enwik8은 잘 훈련된 것으로 보이며 라우팅의 효과를 볼 수 있습니다. 훈련도 놀라울 정도로 안정적이다
전.
import torch
from colt5_attention import ConditionalRoutedAutoregressiveAttention
# mock input, say it is 8192 length
tokens = torch . randn ( 2 , 8192 , 512 ). cuda ()
# attention
attn = ConditionalRoutedAutoregressiveAttention (
dim = 512 ,
light_dim_head = 64 , # attention head dimension of light branch
light_heads = 8 , # number of attention heads for light branch
light_window_size = 128 , # local attention receptive field for light
heavy_window_size = 128 , # the windowing for the routed heavy attention, by default, will be equal to the light window size. be aware if this is any greater than the light window size, there may be tokens that would be missed by attention
heavy_dim_head = 64 , # attention head dimension of heavy branch
heavy_heads = 8 , # number of attention heads for heavy branch
num_heavy_tokens_q = 32 , # heavy branch receives only 32 out of 128 of the windowed queries (1024 query tokens total)
num_heavy_tokens_kv = 1024 , # heavy branch receives only 1024 routed tokens for key-values
num_routed_kv = 2 , # one can split the attention heads so that groups of heads attend to different sets of key - values (2 routing tokens in this case)
use_triton = True , # will need to use Triton for this to be viable, otherwise it is too slow and memory efficient with the number of iterations
use_flash_attn = True # use flash attention in heavy branch
). cuda ()
attn_out = attn ( tokens ) + tokens # (2, 8192, 512) - output of attention with residual (prenorm is included)마지막으로 이 저장소에는 이미지 기능 맵 버전이 포함되어 있습니다. 일반적으로 많은 연구 논문은 32 x 32보다 큰 크기의 이미지 특징 맵에 주의를 기울일 수 없습니다. 이 경로화된 주의는 가벼운 분기에 로컬 창 패치를 사용하고 무거운 분기에 대해 라우팅된 주의를 사용합니다.
전.
import torch
from colt5_attention import ConditionalRoutedImageAttention
attn = ConditionalRoutedImageAttention (
dim = 32 ,
light_dim_head = 64 , # attention head dimension of light branch
light_heads = 8 , # number of attention heads for light branch
light_window_size = 32 , # height and width of local window attention on the image feature map
channel_first = True , # whether to accept images with channel first than last
heavy_dim_head = 64 , # attention head dimension of heavy branch
heavy_heads = 8 , # number of attention heads for heavy branch
num_heavy_tokens_q = 1024 , # heavy branch receives only 1024 routed tokens of 65536
num_heavy_tokens_kv = 1024 # heavy branch receives only 1024 routed tokens of 65536
). cuda ()
fmap = torch . randn ( 1 , 32 , 256 , 256 ). cuda () # image feature map is too large for attention, given 256 ^ 2 == 65536 tokens
out = attn ( fmap )좌표 하강으로 주의를 라우팅하고 피드포워드를 사용하는 간단한 ViT
import torch
from colt5_attention . vit import ConditionalRoutedViT
vit = ConditionalRoutedViT (
image_size = 256 , # image size
patch_size = 32 , # patch size
num_classes = 1000 , # number of output classes
dim = 1024 , # feature dimension
depth = 6 , # depth
attn_num_heavy_tokens_q = 16 , # number of routed queries for heavy attention
attn_num_heavy_tokens_kv = 16 , # number of routed key/values for heavy attention
attn_heavy_dim_head = 64 , # dimension per attention head for heavy
attn_heavy_heads = 8 , # number of attention heads for heavy
attn_light_window_size = 4 , # the local windowed attention for light branch
attn_light_dim_head = 32 , # dimension per head for local light attention
attn_light_heads = 4 , # number of attention heads for local windowed attention
ff_num_heavy_tokens = 16 , # number of tokens routed for heavy feedforward
ff_heavy_mult = 4 , # the expansion factor of the heavy feedforward branch
ff_light_mult = 2 # expansion factor of the light feedforward branch
)
images = torch . randn ( 1 , 3 , 256 , 256 )
logits = vit ( images ) # (1, 1000) 미분 가능한 topk 위해 좌표 하강 주위에 작은 래퍼를 사용하십시오.
import torch
from colt5_attention import topk
x = torch . randn ( 1024 , 512 )
values , indices , coor_descent_values , gates = topk ( x , k = 10 , fused = True )
# you can either use the topk indices + gates, or use the values directly (values have already been multiplied with the gates within the function) @inproceedings { Ainslie2023CoLT5FL ,
title = { CoLT5: Faster Long-Range Transformers with Conditional Computation } ,
author = { Joshua Ainslie and Tao Lei and Michiel de Jong and Santiago Ontan'on and Siddhartha Brahma and Yury Zemlyanskiy and David Uthus and Mandy Guo and James Lee-Thorp and Yi Tay and Yun-Hsuan Sung and Sumit Sanghai } ,
year = { 2023 }
} @article { Tillet2019TritonAI ,
title = { Triton: an intermediate language and compiler for tiled neural network computations } ,
author = { Philippe Tillet and H. Kung and D. Cox } ,
journal = { Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages } ,
year = { 2019 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Lei2023ConditionalAP ,
title = { Conditional Adapters: Parameter-efficient Transfer Learning with Fast Inference } ,
author = { Tao Lei and Junwen Bai and Siddhartha Brahma and Joshua Ainslie and Kenton Lee and Yanqi Zhou and Nan Du and Vincent Zhao and Yuexin Wu and Bo Li and Yu Zhang and Ming-Wei Chang } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2304.04947 }
} @article { Beyer2022BetterPV ,
title = { Better plain ViT baselines for ImageNet-1k } ,
author = { Lucas Beyer and Xiaohua Zhai and Alexander Kolesnikov } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2205.01580 }
}

