mmdit
0.2.1
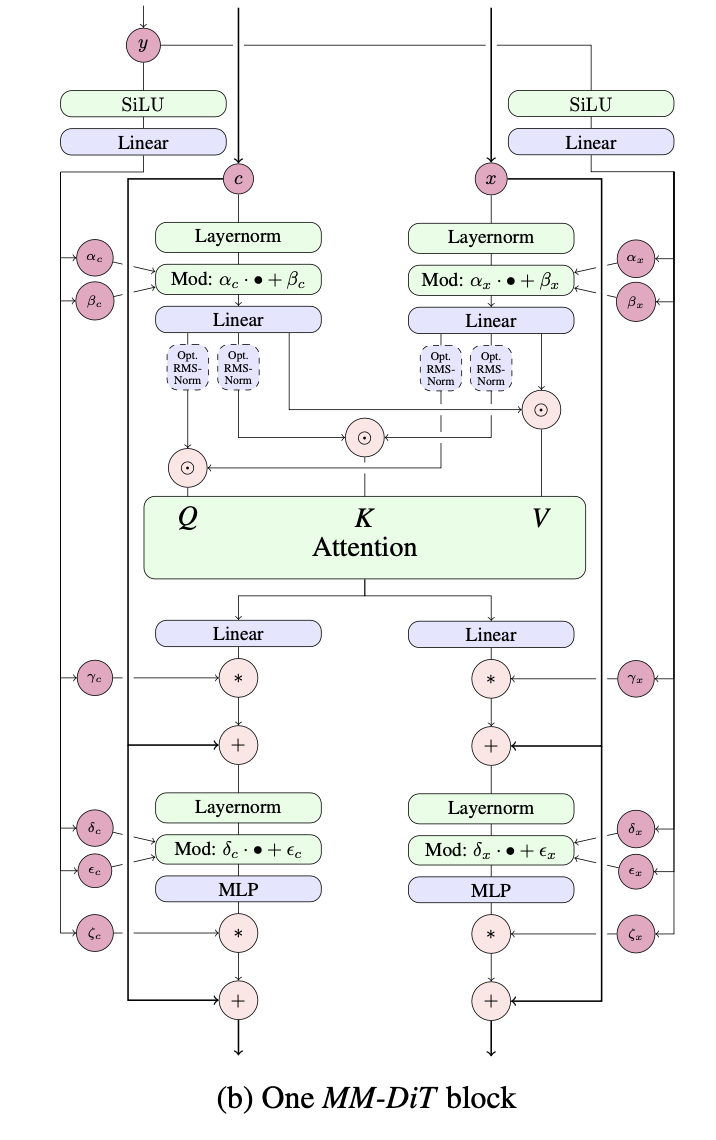
Esser 등이 제안한 MMDiT의 단일 레이어 구현. Stable Diffusion 3, Pytorch에서
직접 재생산 외에도 이미지, 오디오 및 텍스트에 대한 MMDiT를 구상할 수 있으므로 2가지 이상의 양식으로 일반화합니다.
또한 학습된 게이팅을 통해 사용할 가중치를 적응적으로 선택하는 self attention의 즉석 변형도 제공합니다. 이 아이디어는 Kang et al.이 적용한 적응형 컨볼루션에서 나왔습니다. GigaGAN용.
$ pip install mmdit import torch
from mmdit import MMDiTBlock
# define mm dit block
block = MMDiTBlock (
dim_joint_attn = 512 ,
dim_cond = 256 ,
dim_text = 768 ,
dim_image = 512 ,
qk_rmsnorm = True
)
# mock inputs
time_cond = torch . randn ( 2 , 256 )
text_tokens = torch . randn ( 2 , 512 , 768 )
text_mask = torch . ones (( 2 , 512 )). bool ()
image_tokens = torch . randn ( 2 , 1024 , 512 )
# single block forward
text_tokens_next , image_tokens_next = block (
time_cond = time_cond ,
text_tokens = text_tokens ,
text_mask = text_mask ,
image_tokens = image_tokens
)일반화된 버전을 다음과 같이 사용할 수 있습니다.
import torch
from mmdit . mmdit_generalized_pytorch import MMDiT
mmdit = MMDiT (
depth = 2 ,
dim_modalities = ( 768 , 512 , 384 ),
dim_joint_attn = 512 ,
dim_cond = 256 ,
qk_rmsnorm = True
)
# mock inputs
time_cond = torch . randn ( 2 , 256 )
text_tokens = torch . randn ( 2 , 512 , 768 )
text_mask = torch . ones (( 2 , 512 )). bool ()
video_tokens = torch . randn ( 2 , 1024 , 512 )
audio_tokens = torch . randn ( 2 , 256 , 384 )
# forward
text_tokens , video_tokens , audio_tokens = mmdit (
modality_tokens = ( text_tokens , video_tokens , audio_tokens ),
modality_masks = ( text_mask , None , None ),
time_cond = time_cond ,
) @article { Esser2024ScalingRF ,
title = { Scaling Rectified Flow Transformers for High-Resolution Image Synthesis } ,
author = { Patrick Esser and Sumith Kulal and A. Blattmann and Rahim Entezari and Jonas Muller and Harry Saini and Yam Levi and Dominik Lorenz and Axel Sauer and Frederic Boesel and Dustin Podell and Tim Dockhorn and Zion English and Kyle Lacey and Alex Goodwin and Yannik Marek and Robin Rombach } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2403.03206 } ,
url = { https://api.semanticscholar.org/CorpusID:268247980 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}

