lion pytorch
0.2.3
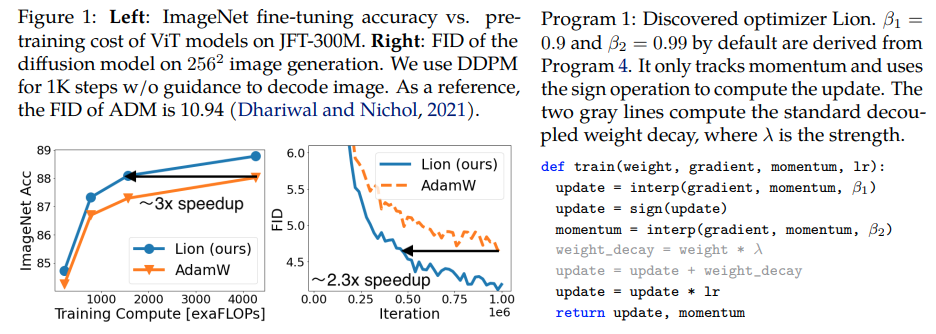
Lion, Evo 는 Pytorch에서 Adam(w)보다 더 나은 것으로 알려진 Google Brain이 발견한 새로운 최적화 프로그램인 Sign Momentum 을 제공했습니다. 이것은 약간의 수정을 가한 거의 그대로 복사한 것입니다.
너무 간단해서 모든 사람이 최대한 빨리 접근하고 사용하여 훌륭한 모델을 훈련할 수 있다면 어떨까요?
학습 속도 및 체중 감쇠: 저자는 섹션 5에 썼습니다. Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. 학습률 일정의 초기값, 최고값, 종료값은 연구자가 입증한 AdamW와 동일한 비율로 동시에 변경되어야 합니다.
학습 속도 일정: 저자는 논문에서 Lion에 대해 AdamW와 동일한 학습 속도 일정을 사용합니다. 그럼에도 불구하고 그들은 역 제곱근 일정에 비해 ViT를 훈련하기 위해 코사인 붕괴 일정을 사용할 때 더 큰 이득을 관찰합니다.
β1 및 β2: 저자는 섹션 5에 썼습니다. The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. 사람들이 안정성을 향상시키기 위해 AdamW에서 β2를 0.99 이하로 줄이고 ε를 1e-6으로 늘리는 것과 유사하게, 저자가 제안한 것처럼 Lion에서 β1=0.95, β2=0.98 사용하는 것도 훈련 중 불안정성을 완화하는 데 도움이 될 수 있습니다. 이는 한 연구원에 의해 확인되었습니다.
업데이트: 내 로컬 enwik8 자동 회귀 언어 모델링에 작동하는 것 같습니다.
업데이트 2: 실험은 학습 속도가 일정하게 유지되면 Adam보다 훨씬 더 나빠 보입니다.
업데이트 3: 학습률을 3으로 나누면 Adam보다 더 나은 초기 결과를 볼 수 있습니다. 아마도 아담은 거의 10년 후에 왕위에서 물러났을 것입니다.
업데이트 4: 논문에서 경험적으로 10배 더 작은 학습률 규칙을 사용하면 최악의 결과가 나왔습니다. 그래서 아직은 튜닝이 좀 필요한 것 같아요.
이전 업데이트 요약: 실험에서 볼 수 있듯이 학습 속도가 3배 더 작은 Lion이 Adam을 능가합니다. 학습률이 10배 작아지면 결과가 더 나빠지므로 여전히 약간의 조정이 필요합니다.
업데이트 5: 올바르게 수행되면 지금까지 언어 모델링에 대한 모든 긍정적인 결과를 들었습니다. 약간의 조정이 필요하기는 하지만 중요한 텍스트-이미지 교육에 대한 긍정적인 결과도 들었습니다. 부정적인 결과는 논문에서 평가된 것 이외의 문제 및 아키텍처(RL, 피드포워드 네트워크, LSTM + 컨볼루션 등이 포함된 이상한 하이브리드 아키텍처)에 있는 것 같습니다. 부정적인 일화는 또한 이 기술이 배치 크기, 데이터 양/확대에 민감하다는 것을 확인합니다. . 최적의 학습률 일정이 무엇인지, 쿨다운이 결과에 영향을 미치는지 여부는 미정입니다. 또한 흥미롭게도 오픈 클립에서는 긍정적인 결과를 얻었는데, 이는 모델 크기가 확대됨에 따라 부정적이 되었습니다(그러나 해결 가능할 수도 있음).
업데이트 6: 작성자가 더 높은 초기 온도를 설정하여 클립 열기 문제를 해결했습니다.
업데이트 7: 높은 배치 크기(64 이상) 설정에서만 이 최적화 프로그램을 권장합니다.
$ pip install lion-pytorch
또는 conda를 사용하여 다음을 수행합니다.
$ conda 설치 lion-pytorch
# 장난감 모델import torchfrom torch import nnmodel = nn.Linear(10, 1)# Lion을 가져오고 매개변수로 인스턴스화from lion_pytorch import Lionopt = Lion(model.parameters(), lr=1e-4, Weight_decay=1e-2)# 앞으로 및 backwardsloss = model(torch.randn(10))loss.backward()# 최적화기 stepopt.step()opt.zero_grad()
매개변수 업데이트를 위해 융합 커널을 사용하려면 먼저 pip install triton -U --pre 다음
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # Triton lang이 포함된 cuda 커널을 사용하려면 이를 True로 설정합니다(Tillet 외))
Stability.ai 작업 및 오픈소스 최첨단 인공지능 연구에 대한 아낌없는 후원
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {Chen, Xiangning 및 Liang, Chen 및 Huang, Da 및 Real, Esteban 및 Wang, Kaiyuan 및 Liu, Yao 및 Pham, Hieu 및 Dong, Xuanyi 및 Luong, Thang 및 Hsieh, Cho-Jui 및 Lu, Yifeng 및 Le, Quoc V.},제목 = {최적화 알고리즘의 기호적 발견}, 출판사 = {arXiv}, 연도 = {2023}} @article{Tillet2019TritonAI,title = {Triton: 타일식 신경망 계산을 위한 중간 언어 및 컴파일러},author = {Philippe Tillet 및 H. Kung 및 D. Cox},journal = {제3회 ACM SIGPLAN 기계에 대한 국제 워크숍 진행 학습 및 프로그래밍 언어}, 연도 = {2019}} @misc{Schaipp2024,author = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {신중한 최적화 도구: 한 줄의 코드로 교육 개선},author = {Kaizhao Liang 및 Lizhang Chen 및 Bo Liu 및 Qiang Liu},연도 = {2024},url = {https://api .semanticscholar.org/CorpusID:274234738}} 

