RoboFlamingo
1.0.0
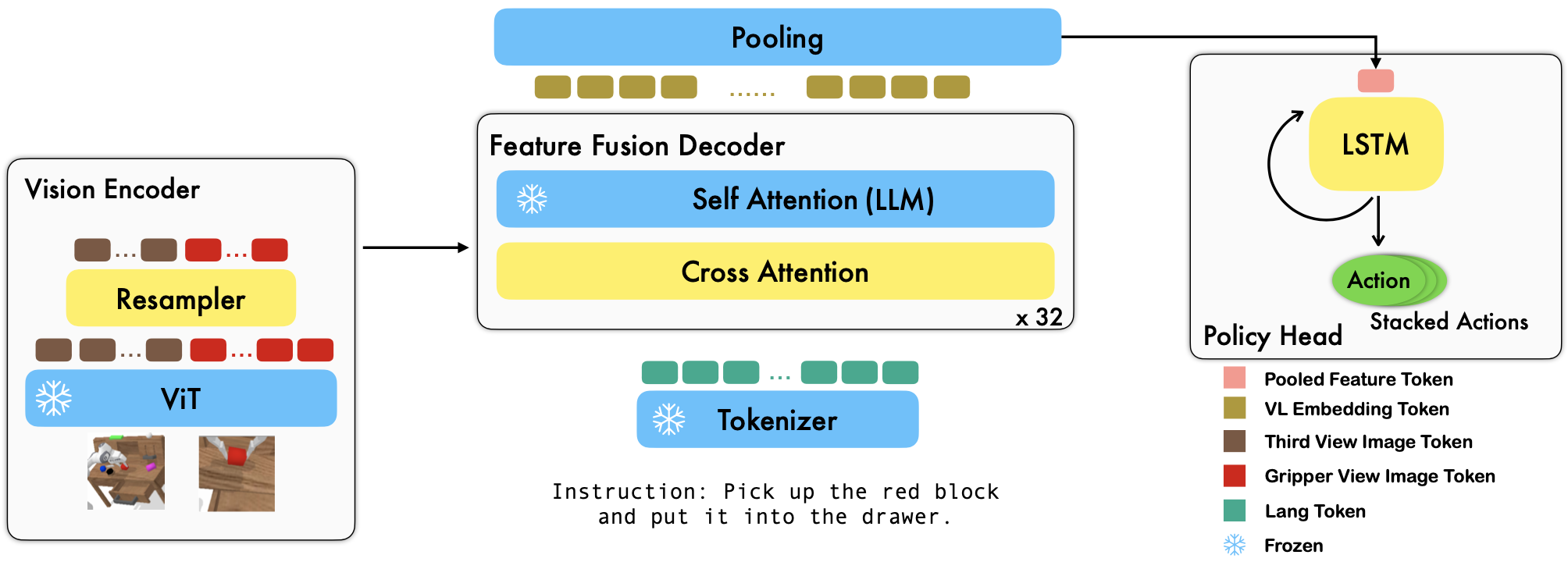
RoboFlamingo 는 오프라인 자유 형식 모방 데이터 세트를 미세 조정하여 다양한 언어 조절 로봇 기술을 학습하는 사전 훈련된 VLM 기반 로봇 학습 프레임워크입니다. CALVIN 벤치마크에서 큰 차이로 최첨단 성능을 초과함으로써 RoboFlamingo가 VLM을 로봇 제어에 적용하는 효과적이고 경쟁력 있는 대안이 될 수 있음을 보여줍니다. 우리의 광범위한 실험 결과는 또한 조작 작업에 대한 사전 훈련된 다양한 VLM의 동작에 관한 몇 가지 흥미로운 결론을 보여줍니다. RoboFlamingo는 단일 GPU 서버에서 훈련하거나 평가할 수 있습니다 (GPU 메모리 요구 사항은 모델 크기에 따라 다름). 우리는 RoboFlamingo가 로봇 조작을 위한 비용 효율적이고 사용하기 쉬운 솔루션이 될 가능성이 있다고 믿습니다. 자체 로봇공학 정책을 미세 조정할 수 있는 능력.
이것은 또한 효과적인 로봇 모방자로서 Vision-Language Foundation Models 논문의 공식 코드 저장소이기도 합니다.
모든 실험은 8개의 Nvidia A100 GPU(80G)를 갖춘 단일 GPU 서버에서 수행되었습니다.
Hugging Face에서는 사전 훈련된 모델을 사용할 수 있습니다.
OpenAI의 사전 훈련된 모델이 포함된 OpenCLIP 패키지에서 사전 훈련된 비전 인코더를 지원합니다. 또한 MPT, RedPajama, LLaMA, OPT, GPT-Neo, GPT-J 및 Pythia 모델과 같은 transformers 패키지에서 사전 훈련된 언어 모델을 지원합니다.
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) cross_attn_every_n_layers 인수는 교차 주의 레이어가 적용되는 빈도를 제어하고 VLM과 일치해야 합니다. decoder_type 인수는 디코더의 유형을 제어합니다. 현재 우리는 lstm , fc , diffusion (데이터로더에 버그가 있음) 및 GPT 지원합니다.
CALVIN 벤치마크 결과를 보고합니다.
| 방법 | 훈련 데이터 | 테스트 분할 | 1 | 2 | 3 | 4 | 5 | 평균 길이 |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD(전체) | 디 | 0.373 | 0.027 | 0.002 | 0.000 | 0.000 | 0.40 |
| 훌크 | ABCD(전체) | 디 | 0.889 | 0.733 | 0.587 | 0.475 | 0.383 | 3.06 |
| HULC (재훈련) | ABCD(언어) | 디 | 0.892 | 0.701 | 0.548 | 0.420 | 0.335 | 2.90 |
| RT-1 (재훈련) | ABCD(언어) | 디 | 0.844 | 0.617 | 0.438 | 0.323 | 0.227 | 2.45 |
| 우리 것 | ABCD(언어) | 디 | 0.964 | 0.896 | 0.824 | 0.740 | 0.66 | 4.09 |
| MCIL | ABC (전체) | 디 | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0.31 |
| 훌크 | ABC (전체) | 디 | 0.418 | 0.165 | 0.057 | 0.019 | 0.011 | 0.67 |
| RT-1 (재훈련) | ABC(언어) | 디 | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 |
| 우리 것 | ABC(언어) | 디 | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.48 |
| 훌크 | ABCD(전체) | D (엔리치) | 0.715 | 0.470 | 0.308 | 0.199 | 0.130 | 1.82 |
| RT-1 (재훈련) | ABCD(언어) | D (엔리치) | 0.494 | 0.222 | 0.086 | 0.036 | 0.017 | 0.86 |
| 우리 것 | ABCD(언어) | D (엔리치) | 0.720 | 0.480 | 0.299 | 0.211 | 0.144 | 1.85 |
| 우리 것(동결-임베트) | ABCD(언어) | D (엔리치) | 0.737 | 0.530 | 0.385 | 0.275 | 0.192 | 2.12 |
OpenFlamingo 및 CALVIN의 지침에 따라 필요한 데이터 세트와 VLM 사전 학습 모델을 다운로드하세요.
CALVIN 데이터세트를 다운로드하고 다음을 사용하여 분할을 선택하세요.
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debug출시된 OpenFlamingo 모델을 다운로드하세요:
| # 매개변수 | 언어 모델 | 비전 엔코더 | Xattn 간격* | 코코 4샷 사이더 | VQAv2 4발 정확도 | 평균 길이 | 가중치 |
|---|---|---|---|---|---|---|---|
| 3B | 아나스-아와달라/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | 77.3 | 45.8 | 3.94 | 링크 |
| 3B | 아나스-아와달라/mpt-1b-redpajama-200b-dolly | openai CLIP ViT-L/14 | 1 | 82.7 | 45.7 | 4.09 | 링크 |
| 4B | 함께컴퓨터/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81.8 | 49.0 | 3.67 | 링크 |
| 4B | 함께컴퓨터/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85.8 | 49.0 | 3.79 | 링크 |
| 9B | 아나스-아와달라/mpt-7b | openai CLIP ViT-L/14 | 4 | 89.0 | 54.8 | 3.97 | 링크 |
사전 훈련된 각 VLM에 대해 robot_flamingo/models/factory.py 에 있는 경로 사전(예: mpt_dict )의 ${lang_encoder_path} 및 ${tokenizer_path} 자신의 경로로 바꿉니다.
이 저장소를 복제하세요
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
필수 패키지를 설치합니다:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} 는 CALVIN 데이터 세트의 경로입니다.
${lm_path} 는 사전 훈련된 LLM의 경로입니다.
${tokenizer_path} VLM 토크나이저의 경로입니다.
${openflamingo_checkpoint} 는 OpenFlamingo 사전 학습 모델에 대한 경로입니다.
${log_file} 은 로그 파일의 경로입니다.
또한 교육을 시작하기 위해 robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash 를 제공합니다. 이 bash는 모델을 훈련하기 위한 기본 하이퍼파라미터를 포함하고 논문의 최상의 결과에 해당하는 OpenFlamingo 모델의 MPT-3B-IFT 버전을 미세 조정합니다.
python eval_ckpts.py
eval_ckpts.py 에 체크포인트 이름과 디렉터리를 추가하면 스크립트가 자동으로 모델을 로드하고 평가합니다. 예를 들어 'your-checkpoint-path' 경로에서 체크포인트를 평가하려면 eval_ckpts.py에서 ckpt_dir 및 ckpt_names 변수를 수정하면 평가 결과가 'logs/your-checkpoint-prefix'로 저장됩니다. 통나무'.
아래에 표시된 결과는 공동 훈련이 VL 작업에서 VLM 백본의 대부분의 능력을 보존하는 동시에 로봇 작업에서 약간의 성능을 잃을 수 있음을 나타냅니다.
사용
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
CoCO, VQAV2 및 CALVIN과 함께 RoboFlamingo 공동 훈련을 시작합니다. robot_flamingo/data/data.py 의 get_coco_dataset 및 get_vqa_dataset 에서 CoCO 및 VQA 경로를 업데이트해야 합니다.
| 나뉘다 | SR 1 | SR 2 | SR 3 | SR 4 | SR 5 | 평균 길이 |
|---|---|---|---|---|---|---|
| 공동 훈련 | ABC->D | 82.9% | 63.6% | 45.3% | 32.1% | 23.4% |
| 미세 조정 | ABC->D | 82.4% | 61.9% | 46.6% | 33.1% | 23.5% |
| 공동 훈련 | ABCD->D | 95.7% | 85.8% | 73.7% | 64.5% | 56.1% |
| 미세 조정 | ABCD->D | 96.4% | 89.6% | 82.4% | 74.0% | 66.2% |
| 공동 훈련 | ABCD->D (풍부하게) | 67.8% | 45.2% | 29.4% | 18.9% | 11.7% |
| 미세 조정 | ABCD->D (풍부하게) | 72.0% | 48.0% | 29.9% | 21.1% | 14.4% |
| 머리 | VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU-1 | BLEU-2 | 블루-3 | 블루-4 | 유성 | ROUGE_L | 사과주 | 기미 | Acc | |
| 미세 조정(3B, 제로샷) | 0.156 | 0.051 | 0.018 | 0.007 | 0.038 | 0.148 | 0.004 | 0.006 | 4.09 |
| 미세 조정(3B, 4샷) | 0.166 | 0.056 | 0.020 | 0.008 | 0.042 | 0.158 | 0.004 | 0.008 | 3.87 |
| 코트레인(3B, 제로샷) | 0.225 | 0.158 | 0.107 | 0.072 | 0.124 | 0.334 | 0.345 | 0.085 | 36.37 |
| 오리지널 플라밍고(80B, 미세 조정) | - | - | - | - | - | - | 1.381 | - | 82.0 |
로고는 MidJourney를 사용하여 생성됩니다.
이 작업에서는 다음 오픈 소스 프로젝트 및 데이터 세트의 코드를 사용합니다.
원본: https://github.com/mees/calvin 라이센스: MIT
원본: https://github.com/openai/CLIP 라이센스: MIT
원본: https://github.com/mlfoundations/open_flamingo 라이센스: MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


