MambaTransformer
1.0.0

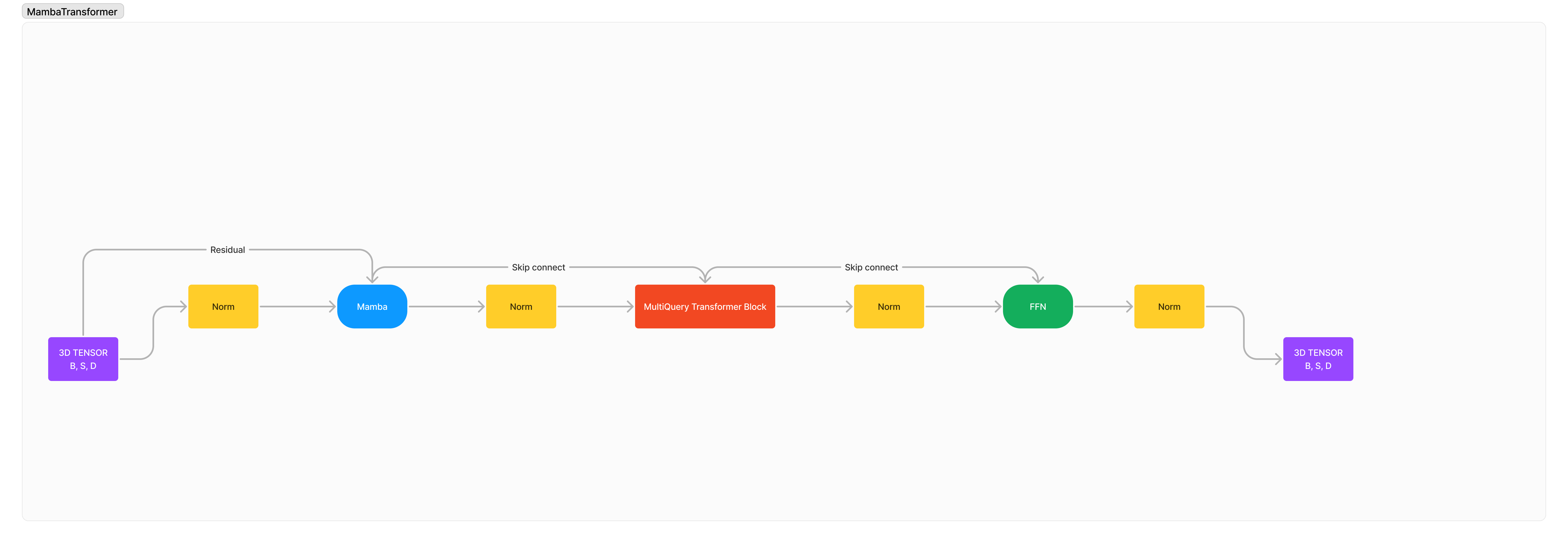
향상된 긴 컨텍스트 및 고품질 시퀀스 모델링을 위해 Mamba/SSM을 Transformer와 통합합니다.
이것은 우리의 오래된 한계를 뛰어넘기 위한 목적으로 완전히 새로운 고급 아키텍처에 대한 SSM과 Attention의 강점과 약점을 결합하기 위해 제가 설계한 100% 새로운 아키텍처입니다. 더 빠른 처리 속도, 더 긴 컨텍스트 길이, 긴 시퀀스에 대한 더 낮은 복잡성, 작고 컴팩트한 상태를 유지하면서 향상되고 우수한 추론.
아키텍처는 기본적으로 x -> norm -> mamba -> norm -> transformer -> norm -> ffn -> norm -> out .
나는 기본적으로 2개의 외국 아키텍처가 서로 통합되어 훈련 안정성이 심각하게 저하될 것이라고 믿기 때문에 많은 정규화를 추가했습니다.
pip3 install mambatransformer
import torch
from mamba_transformer import MambaTransformer
# Generate a random tensor of shape (1, 10) with values between 0 and 99
x = torch . randint ( 0 , 100 , ( 1 , 10 ))
# Create an instance of the MambaTransformer model
model = MambaTransformer (
num_tokens = 100 , # Number of tokens in the input sequence
dim = 512 , # Dimension of the model
heads = 8 , # Number of attention heads
depth = 4 , # Number of transformer layers
dim_head = 64 , # Dimension of each attention head
d_state = 512 , # Dimension of the state
dropout = 0.1 , # Dropout rate
ff_mult = 4 , # Multiplier for the feed-forward layer dimension
return_embeddings = False , # Whether to return the embeddings,
transformer_depth = 2 , # Number of transformer blocks
mamba_depth = 10 , # Number of Mamba blocks,
use_linear_attn = True , # Whether to use linear attention
)
# Pass the input tensor through the model and print the output shape
out = model ( x )
print ( out . shape )
# After many training
model . eval ()
# Would you like to train this model? Zeta Corporation offers unmatchable GPU clusters at unbeatable prices, let's partner!
# Tokenizer
model . generate ( text )
MIT


