toyCarIRL
1.0.0
강화 학습(RL) 은 시행착오 학습의 가장 기본적이고 가장 직관적인 형태이며, 특정 형태의 사고 능력을 가진 대부분의 살아있는 유기체가 학습하는 방식입니다. 탐색을 통한 학습이라고도 불리는 이는 새로 태어난 인간 아기가 첫 걸음을 내딛는 법을 배우는 방식입니다. 즉, 처음에는 무작위 행동을 취한 다음 앞으로 걷는 동작으로 이어지는 행동을 천천히 파악하는 방식입니다.
이 게시물은 강화 학습 프레임워크를 잘 이해하고 있다고 가정합니다. 이 멋진 온라인 코스 AI_Berkeley의 5주차와 6주차를 통해 RL에 익숙해지시기 바랍니다.
이제 제가 스스로에게 계속 묻고 있는 질문은 이러한 학습의 원동력이 무엇인지, 에이전트가 특정 행동을 수행하는 방식으로 학습하도록 강요하는 것이 무엇인지입니다. RL에 대해 더 많이 배우면서 나는 보상 이라는 아이디어를 발견했습니다. 기본적으로 에이전트는 특정 행동에서 얻는 보상이 최대화되는 방식으로 행동을 선택하려고 합니다. 이제 에이전트가 다른 행동을 수행하도록 하려면 보상 구조를 수정/이용해야 합니다. 하지만 우리가 전문가의 행동에 대한 지식만 가지고 있다고 가정하면 환경의 특정 행동에 따른 보상 구조를 어떻게 추정할 수 있을까요? 음, 이것이 바로 역 강화 학습(IRL) 의 문제입니다. 최적의 전문가 정책(실제로는 최적이라고 가정)이 주어지면 기본 보상 구조를 결정하려고 합니다.
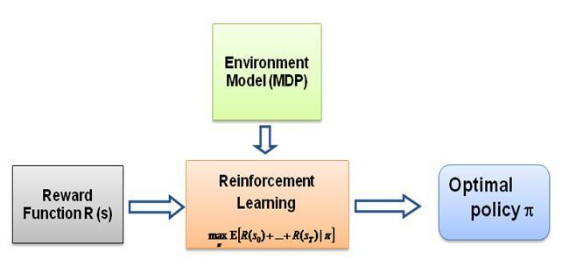
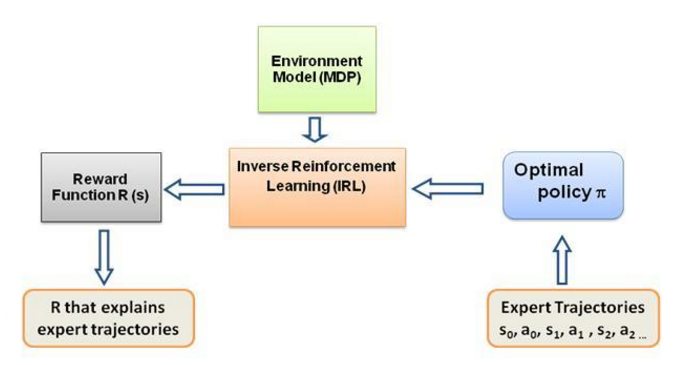
다시 말하지만, 이것은 역 강화 학습 게시물에 대한 소개가 아니라 자신의 문제에 대해 역 강화 학습 프레임워크를 사용/코딩하는 방법에 대한 튜토리얼입니다. 그러나 IRL은 그 핵심에 있으며 알아야 할 전형적인 것입니다. 먼저 그것. IRL은 과거에 광범위하게 연구되었으며 이를 위한 알고리즘이 개발되었습니다. 자세한 내용은 Ng 및 Russell, 2000 및 Abbeel 및 Ng, 2004 논문을 참조하십시오.
이 게시물은 IRL 문제를 해결하기 위해 Abbeel 및 Ng, 2004의 알고리즘을 적용합니다.
여기서 아이디어는 장애물로 가득 찬 2D 세계에서 간단한 에이전트를 프로그래밍하여 환경의 다양한 동작을 복사/복제하는 것입니다. 동작은 인간/컴퓨터 전문가가 수동으로 제공하는 전문가 궤적의 도움을 받아 입력됩니다. 전문가 시연을 통한 이러한 형태의 학습을 과학 문헌에서는 견습 학습이라고 하며, 그 핵심에는 역 강화 학습이 있으며, 우리는 이러한 다양한 행동에 대한 다양한 보상 기능을 알아내려고 노력하고 있습니다.
일반적으로 그렇습니다. 이는 데모(LfD)를 통해 학습한다는 의미와 동일합니다. 두 방법 모두 시연을 통해 학습하지만 서로 다른 점을 학습합니다.
역 강화 학습을 통한 견습 학습은 교사의 목표를 추론 하려고 시도합니다. 즉, 관찰을 통해 보상 함수를 학습한 후 강화 학습에 사용할 수 있습니다. 망치로 못을 치는 것이 목표인 경우 교사의 깜박임이나 긁힘은 목표와 관련이 없으므로 무시합니다.
모방 학습(일명 행동 복제)은 교사를 직접 복사 하려고 시도합니다. 이는 지도 학습만으로 달성할 수 있습니다. AI는 모든 동작을 복사하려고 시도합니다. 예를 들어 깜박이거나 긁는 등 관련 없는 동작, 심지어 실수까지 복사하려고 합니다. 여기서도 RL을 사용할 수 있지만 보상 기능이 있는 경우에만 가능합니다.
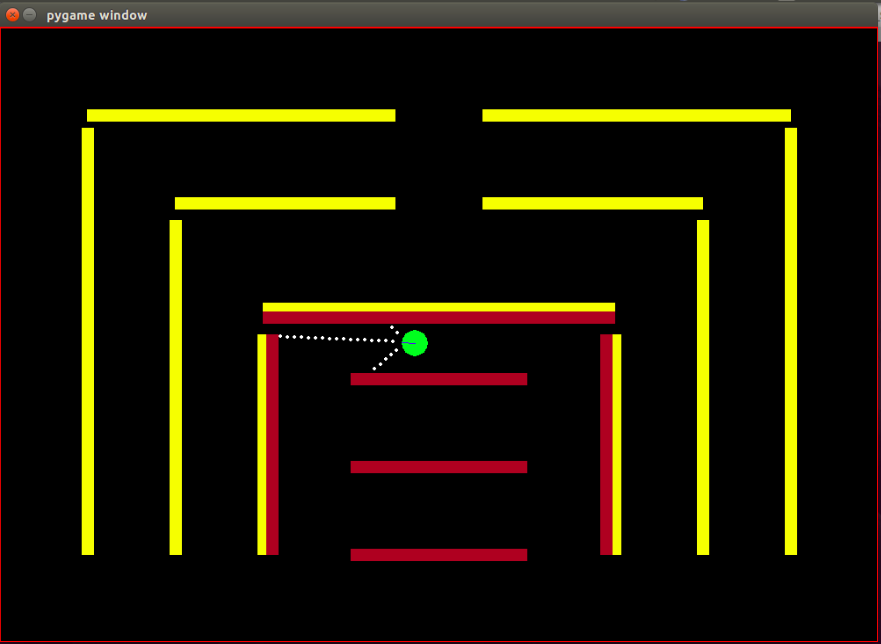
에이전트: 에이전트는 진행 방향이 파란색 선으로 표시된 작은 녹색 원입니다.
센서: 에이전트에는 3개의 거리 겸 컬러 센서가 장착되어 있으며 이는 에이전트가 환경에 대해 가지고 있는 유일한 정보입니다.
상태 공간: 에이전트의 상태는 관찰 가능한 8가지 특징으로 구성됩니다.
관찰 가능한 모든 특성 값이 IRL 알고리즘이 수렴하기 위한 보상에 대한 필수 조건인 [0,1] 범위에 있는지 확인하기 위해 정규화가 수행됩니다.
보상: 모든 프레임 이후의 보상은 해당 프레임에서 관찰된 특징 값의 가중 선형 조합으로 계산됩니다. 여기서 t번째 프레임의 보상 r_t는 가중치 벡터 w와 t번째 프레임의 특징값 벡터, 즉 상태 벡터 phi_t의 내적에 의해 계산됩니다. r_t = w^T x phi_t가 됩니다.
사용 가능한 작업: 모든 새 프레임에서 에이전트는 자동으로 앞으로 단계를 수행합니다. 사용 가능한 작업은 에이전트를 왼쪽 , 오른쪽 으로 돌리거나 단순한 앞으로 단계인 아무것도 수행하지 않을 수 있습니다. 회전 작업에는 앞으로 동작도 포함됩니다. 내부 회전이 아닙니다.
장애물: 환경은 의도적으로 다양한 색상으로 칠해진 단단한 벽으로 구성됩니다. 에이전트에는 장애물 유형을 구별하는 데 도움이 되는 색상 감지 기능이 있습니다. 환경은 IRL 알고리즘을 쉽게 테스트할 수 있도록 이러한 방식으로 설계되었습니다.
IRL 알고리즘에 따라 봇의 시작 위치(상태)는 고정되어 있으며 모든 반복에서 시작 상태가 동일해야 합니다.
RL 알고리즘은 Matt Harvey가 이 게시물에서 약간만 변경하여 완전히 채택했기 때문에 내가 변경한 사항에 대해 이야기하는 것이 완벽합니다. 또한 독자가 RL에 익숙하더라도 한 번 살펴보는 것이 좋습니다. 강화학습이 어떻게 진행되는지 이해하기 위한 게시물입니다.
에이전트가 3개 센서의 거리를 감지할 수 있을 뿐만 아니라 장애물의 색상을 감지하여 장애물을 구분할 수 있게 되면서 환경이 크게 바뀌었습니다. 또한 더 높은 해상도와 더 나은 성능을 얻기 위해 이제 에이전트의 크기가 더 작아지고 감지 점이 더 가까워졌습니다. IRL 알고리즘 테스트 과정을 단순화하기 위해 장애물은 지금은 정적으로 만들어야 했습니다. 이는 데이터의 과적합으로 이어질 수 있지만 지금은 걱정하지 않습니다. 위에서 설명한 대로 에이전트 상태에 충돌 기능이 포함되어 관찰 세트 또는 에이전트 상태가 3에서 8로 증가했습니다. 보상 구조가 완전히 변경되었습니다. 보상은 이제 이 8개 특성의 가중치 선형 조합입니다. 에이전트는 더 이상 장애물에 부딪힐 때 -500 보상을 받지 않습니다. 오히려 충돌 에 대한 특성 값은 +1이고 충돌하지 않으면 0입니다. 전문가의 행동을 기반으로 이 기능에 어떤 가중치를 할당해야 하는지 결정하는 것은 알고리즘에 있습니다.
Matt의 블로그에 명시된 바와 같이 여기서의 목표는 RL 에이전트에게 장애물을 피하도록 가르치는 것뿐만 아니라 보상 구조에 대해 가정해야 하는 이유를 의미하고 보상 구조가 전문가 시연의 알고리즘에 의해 완전히 결정되도록 하고 어떤 행동이 일어나는지 확인하는 것입니다. 특정 보상 설정이 달성됩니다!
기본적으로 상태에서 관찰할 수 있는 기능 또는 기본 함수 phi_i입니다. 현재 문제의 특징은 위의 상태 공간 섹션에서 논의되었습니다. 우리는 phi(s_t)를 다음과 같이 모든 기능 기대 phi_i의 합으로 정의합니다.
보상 r_t - 각 상태 s_t에서 관찰된 이러한 특성 값의 선형 조합입니다.
정책 pi의 특성 기대 mu(pi)는 할인된 특성 값 phi(s_t)의 합입니다.
정책의 기능 기대치는 가중치와 무관하며 실행 중에 방문한 상태(정책에 따라)와 0과 1 사이의 할인 계수 감마(예: 우리의 경우 0.9)에만 의존합니다. 정책의 기능 기대치를 얻으려면 에이전트와 함께 실시간으로 정책을 실행하고 방문한 상태와 얻은 기능 값을 기록해야 합니다.
전문가 정책 특징 기대 또는 전문가 특징 기대 mu(pi_E)는 전문가 행동에 따라 취해지는 조치에 의해 획득됩니다. 우리는 기본적으로 이 정책을 실행하고 다른 정책과 마찬가지로 기능 기대치를 얻습니다. 전문가 기능 기대치는 IRL 알고리즘에 제공되어 가중치에 해당하는 보상 기능이 전문가가 최대화하려고 하는 기본 보상 기능(일반적인 RL 언어)과 유사하도록 가중치를 찾습니다.
무작위 정책 기능 기대 - 무작위 정책을 실행하고 얻은 기능 기대를 사용하여 IRL을 초기화합니다.
매 반복 후에 얻은 정책 기능 기대치 목록을 유지하십시오.
처음에는 pi^1 -> 무작위 정책 기능 기대치만 있습니다.
볼록 최적화를 통해 w^1의 첫 번째 가중치 세트를 찾습니다. 문제는 전문가 기능 expec에 +1 레이블을 제공하려고 시도하는 SVM 분류기와 유사합니다. -기타 모든 정책 기능에 대한 레이블은 1개입니다.-
그렇게,
종료 조건:
이제 최적화를 한 번 반복한 후 가중치를 얻으면, 즉 새로운 보상 함수를 얻은 후에는 이 보상 함수가 발생시키는 정책을 배워야 합니다. 이는 획득된 보상 함수를 최대화하려는 정책을 찾는 것과 같습니다. 이 새로운 정책을 찾으려면 이 새로운 보상 함수로 강화 학습 알고리즘을 훈련하고 Q 값이 수렴될 때까지 훈련하여 정책의 적절한 추정치를 얻어야 합니다.
새로운 정책을 배운 후에는 이 새로운 정책에 해당하는 기능 기대치를 얻기 위해 이 정책을 온라인으로 테스트해야 합니다. 그런 다음 이러한 새로운 기능 기대치를 기능 기대 목록에 추가하고 수렴될 때까지 IRL 알고리즘의 다음 반복을 계속합니다.
이제 코드를 익히도록 합시다. 이 git repo에서 전체 코드를 찾으세요. 걱정해야 할 파일은 주로 3가지입니다.
manualControl.py - 에이전트를 수동으로 이동하여 전문가의 기능 기대치를 얻습니다. "python3 manualControl.py"를 실행하고 GUI가 로드될 때까지 기다린 다음 화살표 키를 사용하여 이동을 시작하세요. 복사할 동작을 지정합니다(복사할 것으로 예상하는 동작은 주어진 상태 공간에서 합리적이어야 합니다). 좋은 방법은 에이전트 대신 자신을 가정하고 현재 상태 공간에서만 주어진 동작을 구분할 수 있는지 생각하는 것입니다. 자세한 내용은 소스 파일을 참조하세요.
toy_car_IRL.py - 기본 파일이며 IRL 코드가 있는 곳입니다. 코드를 단계별로 살펴보겠습니다.
{% 요점 51542f27e97eac1559a00f06b757df1a %}
종속성을 가져오고 중요한 매개변수를 정의하고 필요에 따라 동작을 변경합니다. FRAMES는 RL 알고리즘이 실행할 프레임 수입니다. 100K는 괜찮고 약 2시간 정도 걸립니다.
{% 요점 49b602b9a3090773d492310175bb2e3f %}
표시된 대로 무작위 및 전문가 동작과 기타 중요한 매개변수를 사용하는 사용하기 쉬운 irlAgent 클래스를 만듭니다.
{% 요점 bc17c06a07ea3b915827e89f3c13a2ae %}
getRLAgentFE 함수는 강화 학습기의 IRL_helper를 사용하여 새 모델을 훈련하고 해당 모델을 2000회 반복 재생하여 기능 기대치를 얻습니다. 기본적으로 모든 가중치 세트(W)에 대한 기능 기대치를 반환합니다.
{% 요지 ce0ef99adc652c7469f1bc4303a3af41 %}
획득한 정책과 해당 t 값을 보관하는 사전을 업데이트합니다. 여기서 t = (weights.tanspose)x(expert-newPolicy)입니다.
{% 요점 be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
위에서 설명한 기본 IRL 알고리즘의 구현입니다. {% 요점 9faee18596467ee33ac5d91fd0cb675f %}
새로운 정책을 받을 때 가중치를 업데이트하는 볼록 최적화는 기본적으로 전문가 정책에 +1 라벨을 할당하고 다른 모든 정책에 -1 라벨을 할당하고 언급된 제약 조건에 따라 가중치를 최적화합니다. 이 최적화에 대해 자세히 알아보려면 사이트를 방문하세요.
{% 요점 30cf6c59b9915054f3cf6d278f8f8a11 %}
irlAgent를 생성하고 원하는 매개변수를 전달하고, 가중치를 학습하려는 전문가 행동 유형 중에서 선택한 다음,optimalWeightFinder() 함수를 실행하세요. 빨간색, 노란색 및 갈색 동작에 대한 기능 기대치를 이미 얻었습니다. 알고리즘이 종료된 후 'weights-red/yellow/brown.txt'에서 각각 선택된 동작과 함께 가중치 목록을 얻게 됩니다. 이제 획득한 모든 가중치에서 가능한 최상의 동작을 선택하려면 save-models_BEHAVIOR/evaluatedPolicies/ 디렉터리에 저장된 모델을 재생하세요. 모델은 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+ 형식으로 저장됩니다. 반복 횟수+ '-164-150-100-50000-100000' + '.h5' . 기본적으로 다양한 반복에 대해 서로 다른 가중치를 얻습니다. 먼저 모델을 재생하여 가장 잘 수행되는 모델을 찾은 다음 해당 모델의 반복 번호를 기록해 둡니다. 이 반복 번호에 따라 얻은 가중치는 전문가에게 가장 가까운 가중치입니다. 행동.
그리고 적어도 이 게시물의 내용에 대해서는 업데이트/수정할 필요가 없는 파일이 있습니다.
약 10-15번의 반복 후에 알고리즘은 선택한 4가지 다른 동작 모두에 수렴되었으며 다음과 같은 결과를 얻었습니다.
| 가중치 | 나는 노란색을 좋아한다 | 나는 브라운을 좋아한다 | 나는 레드를 사랑한다 | 나는 범핑을 좋아한다 |
|---|---|---|---|---|
| w1(왼쪽 센서 거리) | -0.0880 | -0.2627 | 0.2816 | -0.5892 |
| w2(중앙 센서 거리) | -0.0624 | 0.0363 | -0.5547 | -0.3672 |
| w3 (오른쪽 센서 거리) | 0.0914 | 0.0931 | -0.2297 | -0.4660 |
| w4 (블랙 색상) | -0.0114 | 0.0046 | 0.6824 | -0.0299 |
| w5 (노란색) | 0.6690 | -0.1829 | -0.3025 | -0.1528 |
| w6 (브라운 컬러) | -0.0771 | 0.6987 | 0.0004 | -0.0368 |
| w7 (빨간색) | -0.6650 | -0.5922 | 0.0525 | -0.5239 |
| w8 (충돌) | -0.2897 | -0.2201 | -0.0075 | 0.0256 |
처음 세 가지 행동의 범핑 특성에 속하는 가중치에는 높은 음수 값이 할당됩니다. 왜냐하면 이 세 가지 전문가 행동은 에이전트가 장애물에 부딪히는 것을 원하지 않기 때문입니다. 전문가 행동이 범핑을 옹호하므로 마지막 행동, 즉 Nasty 봇의 동일한 기능에 대한 가중치는 긍정적입니다.
분명히 색상 특징에 대한 가중치는 전문가 행동에 따라 다르며, 해당 색상이 필요할 경우 높으며, 그렇지 않으면 뚜렷한 행동을 얻기 위해 다소 낮거나 음수 값입니다.
거리 특성 가중치는 매우 모호하며(직관적이지 않음) 가중치에서 의미 있는 패턴을 찾는 것이 매우 어렵습니다. 내가 지적하고 싶은 유일한 점은 현재 설정에서 시계 방향과 시계 반대 방향 동작을 구별하는 것도 가능하며 거리 기능이 이 정보를 전달한다는 것입니다.
문제 구조를 설계하는 동안 인간으로서 현재 상태 세트(관찰)의 가용성을 사용하여 주어진 동작을 구분할 수 있는지 여부를 먼저 생각하는 것이 매우 중요합니다. 그렇지 않으면 필요한 정보를 완전히 제공하지 않고 알고리즘이 다른 가중치를 찾도록 강제할 수도 있습니다.
정말로 IRL에 들어가고 싶다면 에이전트에게 새로운 행동을 가르쳐 보는 것이 좋습니다. (현재 상태 세트에 대해 가능한 고유한 행동이 이미 활용되었기 때문에 환경을 수정해야 할 수도 있습니다. 적어도 나에 따르면).
다음을 사용하여 Pygame의 종속성을 설치하십시오.
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
그런 다음 Pygame 자체를 설치하십시오.
pip3 install hg+http://bitbucket.org/pygame/pygame
이것은 시뮬레이션에 사용되는 물리 엔진입니다. 꽤 중요한 재작성(v5)을 거쳤으므로 이전 v4 버전을 가져와야 합니다. v4는 Python 2용으로 작성되었으므로 몇 가지 추가 단계가 있습니다.
집으로 돌아가거나 다운로드하여 Pymunk 4를 받으세요.
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
포장을 푼다:
tar zxvf pymunk-4.0.0.tar.gz
Python 2에서 3으로 업데이트:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
설치하세요:
cd .. python3 setup.py install
이제 reinforcement-learning-car 복제한 위치로 돌아가서 모든 것이 빠른 python3 learning.py 로 작동하는지 확인하세요. 화면 주위에 작은 점이 날아다니는 모습이 보이면 시작할 준비가 된 것입니다!
먼저 모델을 훈련해야 합니다. 그러면 saved-models 폴더에 가중치가 저장됩니다. 를 실행하기 전에 이 폴더를 만들어야 할 수도 있습니다 . 다음을 실행하여 모델을 훈련할 수 있습니다.
python3 learning.py
네트워크의 복잡성과 샘플 크기에 따라 모델을 훈련하는 데 1시간에서 36시간까지 걸릴 수 있습니다. 하지만 25,000프레임마다 가중치를 내뿜기 때문에 훨씬 짧은 시간에 다음 단계로 넘어갈 수 있습니다.
playing.py 파일을 편집하여 로드하려는 모델의 경로 이름을 변경하세요. 죄송합니다. 명령줄 인수여야 한다는 것을 알고 있습니다.
그런 다음 자동차가 장애물을 피해 스스로 주행하는 모습을 지켜보세요!
python3 playing.py
그게 전부입니다.


