WeClone
1.0.0
WeChat 채팅 기록을 사용하여 대규모 언어 모델을 미세 조정하면서 약 20,000개의 통합된 유효 데이터를 사용했습니다. 최종 결과는 만족스럽지 않다고 할 수 있지만 때로는 정말 웃깁니다.
중요한
현재 프로젝트에서는 chatglm3-6b 모델을 기본으로 사용하고 있으며 LoRA 방식을 사용하여 sft 스테이지를 미세 조정하는데 약 16GB의 비디오 메모리가 필요합니다. 비디오 메모리를 덜 차지하는 LLaMA Factory에서 지원하는 다른 모델과 방법을 사용할 수도 있습니다. 템플릿의 시스템 프롬프트 단어와 기타 관련 구성을 직접 수정해야 합니다.
예상 비디오 메모리 요구 사항:
| 훈련 방법 | 정확성 | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| 전체 매개변수 | 16 | 160GB | 320GB | 600GB | 1200GB | 900GB |
| 일부 매개변수 | 16 | 20GB | 40GB | 120GB | 240GB | 200GB |
| 로라 | 16 | 16GB | 32GB | 80GB | 160GB | 120GB |
| QLoRA | 8 | 10GB | 16GB | 40GB | 80GB | 80GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 32GB |
| 필수의 | 적어도 | 추천하다 |
|---|---|---|
| 파이썬 | 3.8 | 3.10 |
| 토치 | 1.13.1 | 2.2.1 |
| 변압기 | 4.37.2 | 4.38.1 |
| 데이터 세트 | 2.14.3 | 2.17.1 |
| 가속하다 | 0.27.2 | 0.27.2 |
| 페프트 | 0.9.0 | 0.9.0 |
| 트롤 | 0.7.11 | 0.7.11 |
| 선택 과목 | 적어도 | 추천하다 |
|---|---|---|
| 쿠다 | 11.6 | 12.2 |
| 딥스피드 | 0.10.0 | 0.13.4 |
| 비트샌드바이트 | 0.39.0 | 0.41.3 |
| 플래시 Attn | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txt훈련 및 추론 관련 구성은 settings.json 파일에 통합됩니다.
WeChat 채팅 기록을 추출하려면 PyWxDump를 사용하세요. 소프트웨어를 다운로드하고 데이터베이스를 해독한 후 내보내기 유형은 CSV입니다. 그런 다음 ./data wxdump_tmp/export 에 있는 내보낸 csv 폴더를 다른 폴더에 배치합니다. 사람들의 채팅 기록 폴더는 ./data/csv 에 함께 배치됩니다. 예제 데이터는 data/example_chat.csv에 있습니다.
기본적으로 프로젝트는 데이터에서 휴대전화 번호, ID 번호, 이메일 주소, 웹사이트 주소를 제거합니다. 또한 필터링해야 하는 단어와 문장을 추가할 수 있는 금지어 데이터베이스인blocked_words를 제공합니다(금지어를 포함한 전체 문장은 기본적으로 제거됩니다). ./make_dataset/csv_to_json.py 스크립트를 실행하여 데이터를 처리합니다.
같은 사람이 여러 문장에 연속적으로 대답하는 경우 이를 처리하는 세 가지 방법이 있습니다.
| 문서 | 가공방법 |
|---|---|
| csv_to_json.py | 쉼표로 연결하세요 |
| csv_to_json-단일 문장 Answer.py(사용되지 않음) | 가장 긴 답변만 최종 데이터로 선택 |
| csv_to_json-단일 문장 여러 rounds.py | 프롬프트 단어의 '기록'에 배치됩니다. |
첫 번째 선택은 Hugging Face에서 ChatGLM3 모델을 다운로드하는 것입니다. Hugging Face 모델을 다운로드하는 데 문제가 발생하는 경우 다음 방법을 통해 MoDELSCOPE 커뮤니티를 사용할 수 있습니다. 후속 교육 및 추론을 위해 먼저 export USE_MODELSCOPE_HUB=1 실행하여 MoDELSCOPE 커뮤니티 모델을 사용해야 합니다.
모델의 크기가 크기 때문에 다운로드 과정에 시간이 오래 걸리므로 잠시 기다려 주십시오.
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(선택 사항) settings.json을 수정하여 로컬로 다운로드된 다른 모델을 선택합니다.
per_device_train_batch_size 및 gradient_accumulation_steps 수정하여 비디오 메모리 사용량을 조정하세요.
자신의 데이터 세트의 수량과 품질에 따라 num_train_epochs , lora_rank , lora_dropout 과 같은 매개변수를 수정할 수 있습니다.
src/train_sft.py 실행하여 sft 단계를 미세 조정합니다. 손실이 약 3.5로 줄어들었습니다. 너무 많이 줄이면 과적합이 발생할 수 있습니다.
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.py메모
pt 단계를 먼저 미세 조정할 수도 있습니다. 개선 효과가 분명하지 않은 것 같습니다. 웨어하우스에서는 pt 단계 데이터 세트의 전처리 및 학습을 위한 코드도 제공합니다.
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.py중요한
WeChat에서는 계정 폐쇄의 위험이 있습니다. 소액 계정을 사용하는 것이 좋으며, 사용하려면 은행 카드를 연결해야 합니다.
python ./src/api_service.py # 先启动api服务
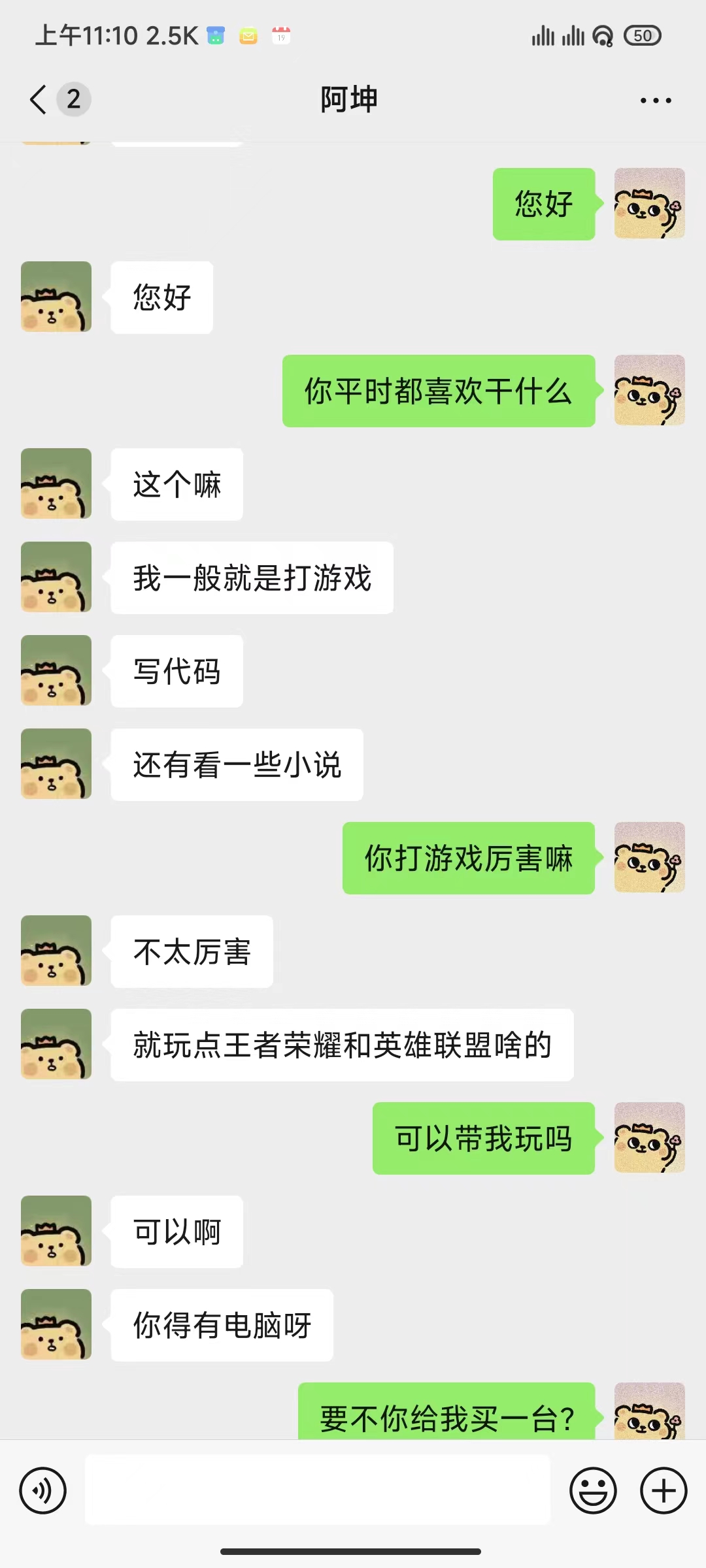
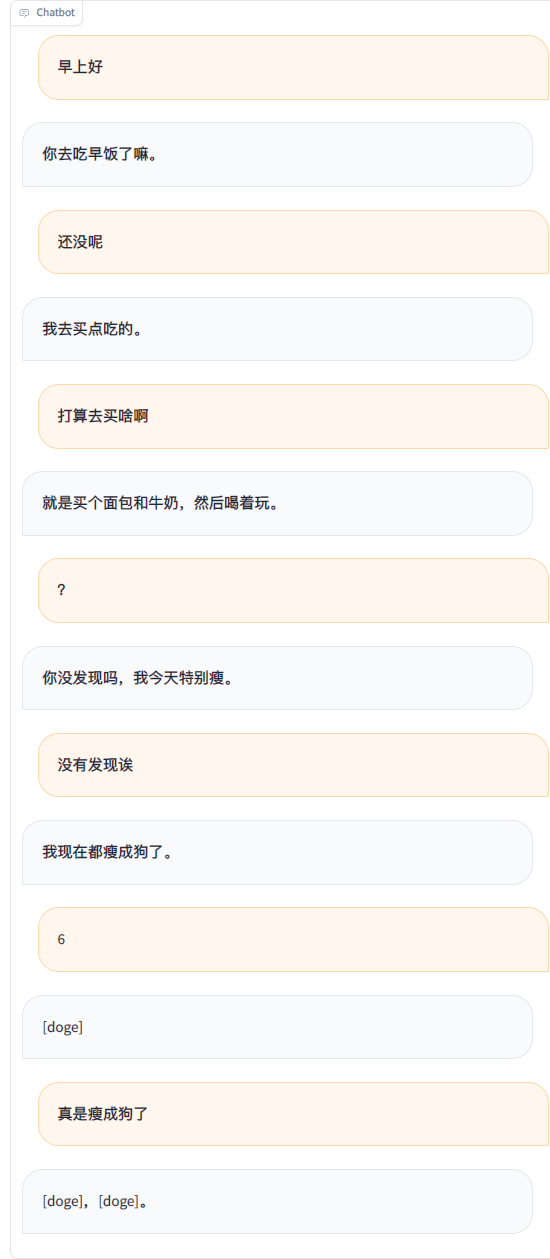
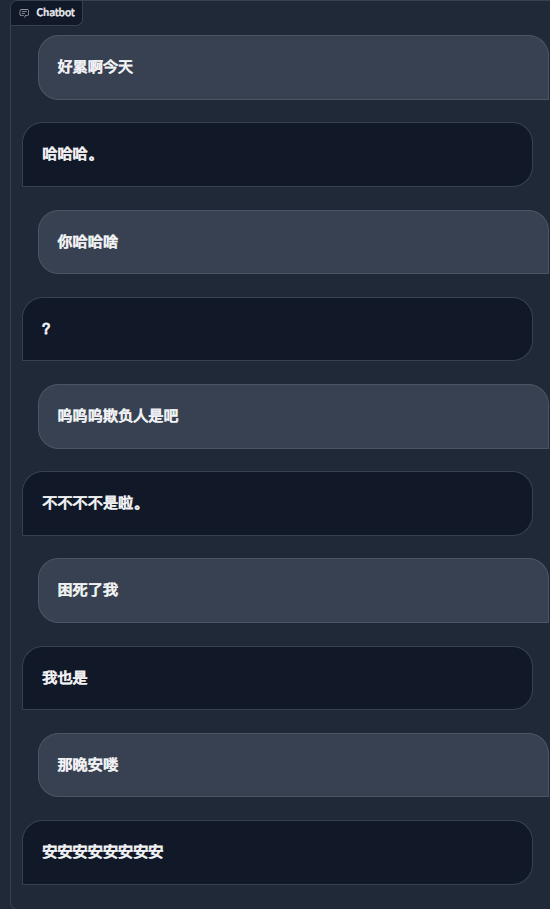
python ./src/wechat_bot/main.py 기본적으로 QR 코드는 단말기에 표시되며, 코드를 스캔하여 로그인하면 됩니다. 비공개 채팅이나 그룹 채팅 @bot에서 사용할 수 있습니다.

토도
토도


