ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot은 공식 OpenAI API를 기반으로 한 대화 모델을 사용하여 구현된 chatGPT와 유사한 로봇으로 Wechaty 프레임워크를 통해 WeChat에 배포되어 로봇 채팅을 구현합니다.
ChatGPT WechatBot은 OpenAI 공식 API를 기반으로 하고 대화 모델을 사용하는 일종의 chatGPT 로봇으로 Wechat 프레임워크를 통해 WeChat에 배포되어 로봇 채팅을 구현합니다.
참고 : 이 프로젝트는 로컬 Win10 구현이므로 서버 배포가 필요하지 않습니다. (서버 배포가 필요한 경우 서버에 Docker를 배포할 수 있습니다.)
(1), Windows10
(2) 도커 20.10.21
(3), 파이썬3.9
(4), 위챗티 0.10.7
1. 도커 다운로드
https://www.docker.com/products/docker-desktop/ 도커 다운로드
2. Win10 가상화를 켜세요
아래 그림과 같이 cmd에 control을 입력하여 제어판을 열고 프로그램을 입력합니다.
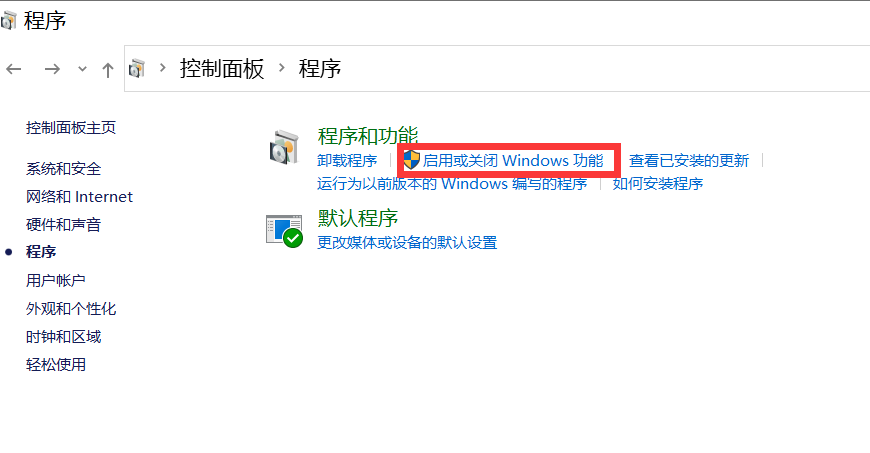
Windows 기능 켜기 또는 끄기 로 이동하여 Hyper-V를 켜십시오.
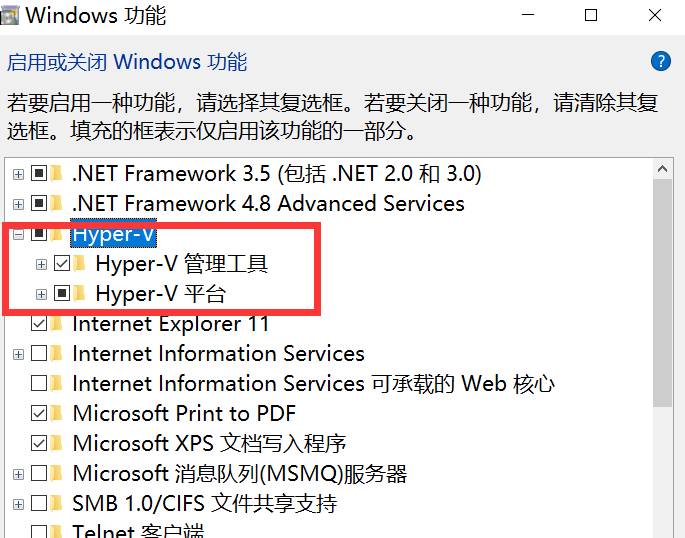
참고 : 컴퓨터에 Hyper-V가 없으면 다음 작업을 수행해야 합니다.
텍스트 문서를 만들고 다음 코드를 입력한 후 이름을 Hyper.cmd 로 지정하세요.
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL그런 다음 이 파일을 관리자로 실행하십시오. 스크립트 실행이 완료되면 컴퓨터를 다시 시작한 후 Hyper-V 노드가 생성됩니다.
3. 도커 실행
참고 : Docker를 처음 실행할 때 다음이 발생하는 경우:
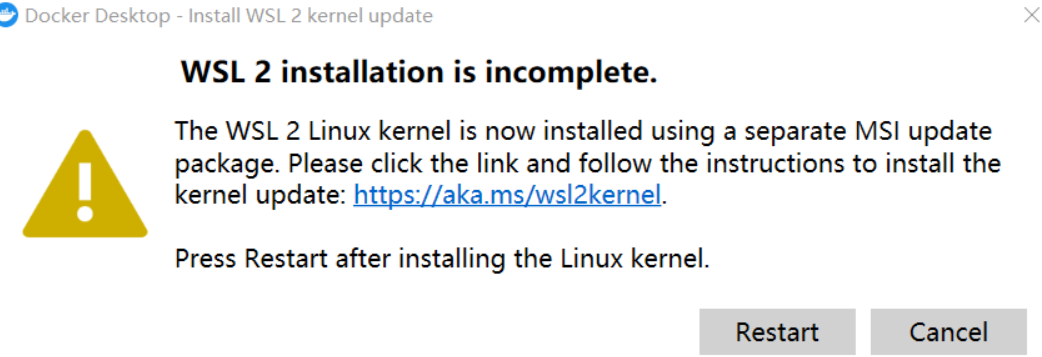
최신 WSL 2 패키지를 다운로드해야 합니다.
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
업데이트 후 메인 페이지에 진입한 후 docker 엔진에서 설정을 변경하고 이미지를 Alibaba Cloud의 국내 이미지로 교체할 수 있습니다.
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}이렇게 하면 거울을 빼는 속도가 더 빨라집니다. (국내 사용자의 경우)
4. Wechaty 이미지를 가져옵니다 .
docker pull wechaty:0 . 65테스트 중에 wechaty 버전 0.65가 가장 안정적인 것으로 나타났습니다.
이미지를 가져온 후:
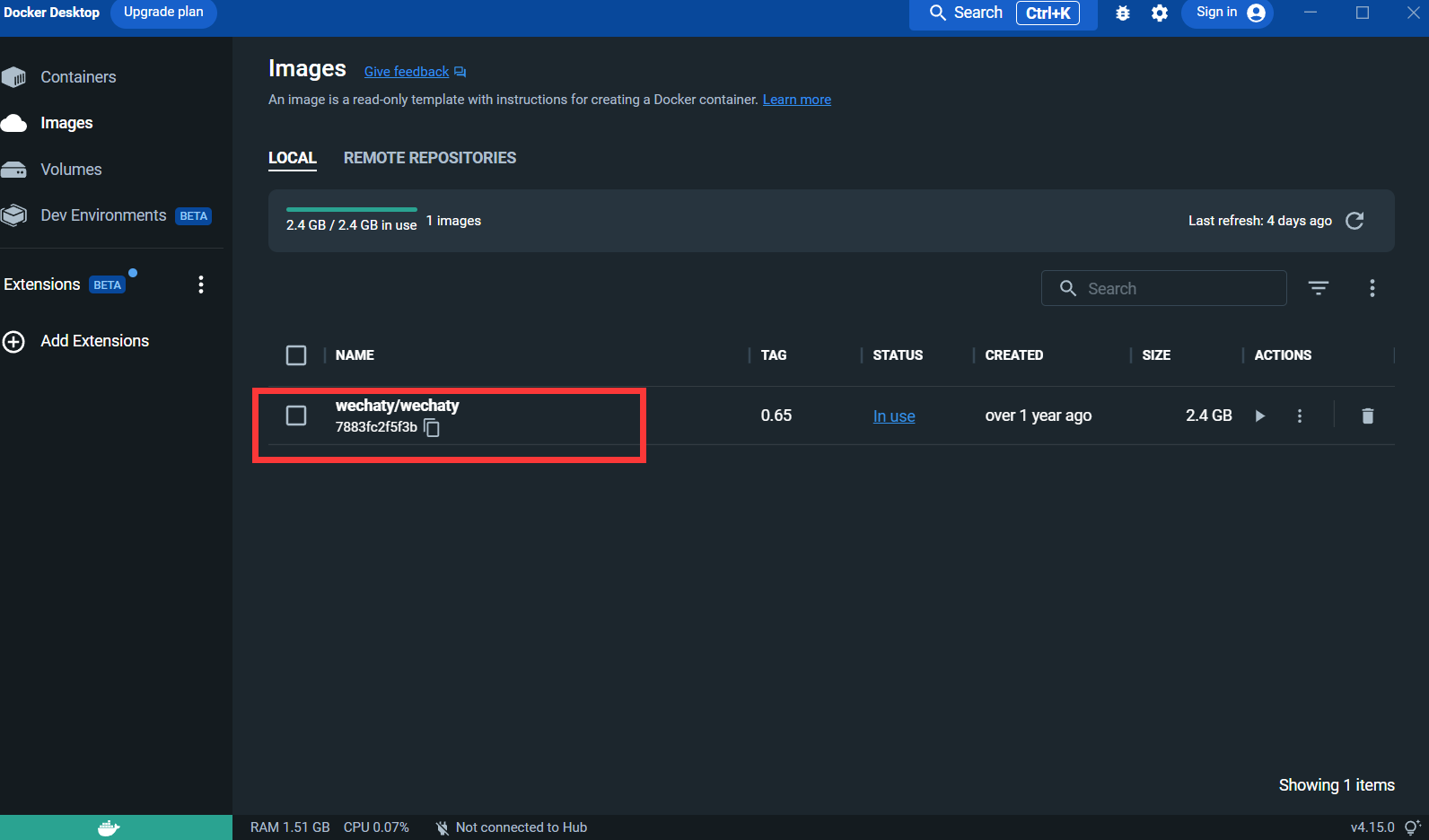
Puppet : Wechaty를 사용하여 WeChat 로봇을 개발하려면 미들웨어 Puppet을 사용하여 WeChat의 작동을 제어해야 합니다. Puppet의 공식 번역은 현재 다양한 버전의 Puppet이 있습니다. Puppet은 달성할 수 있는 다양한 로봇 기능을 제공합니다. 예를 들어 로봇이 사용자를 그룹 채팅에서 쫓아내도록 하려면 Pad 프로토콜에서 Puppet을 사용해야 합니다.
접속신청 : http://pad-local.com/#/login
참고 : 계정을 신청하면 7일 토큰을 받게 됩니다.
토큰 신청 후 cmd 창에서 다음 명령어를 실행하세요.
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
매개변수 설명:
WECHATY_PUPPET_PADLOCAL_TOKEN : 좋은 토큰을 신청하세요
**WECHATY_TOKEN **: 고유함이 보장되는 임의의 문자열을 작성하세요.
WECHATY_PUPPET_SERVER_PORT : 도커 서버 포트
wechaty/wechaty:0.65 : wechaty 이미지 버전
참고: - "8080:8080"*은 로컬 시스템 및 Docker 서버의 포트입니다. Docker 서버 포트는 WECHATY_PUPPET_SERVER_PORT와 일치해야 합니다.
실행 후 docker 데스크탑 패널에서 컨테이너를 확인합니다.
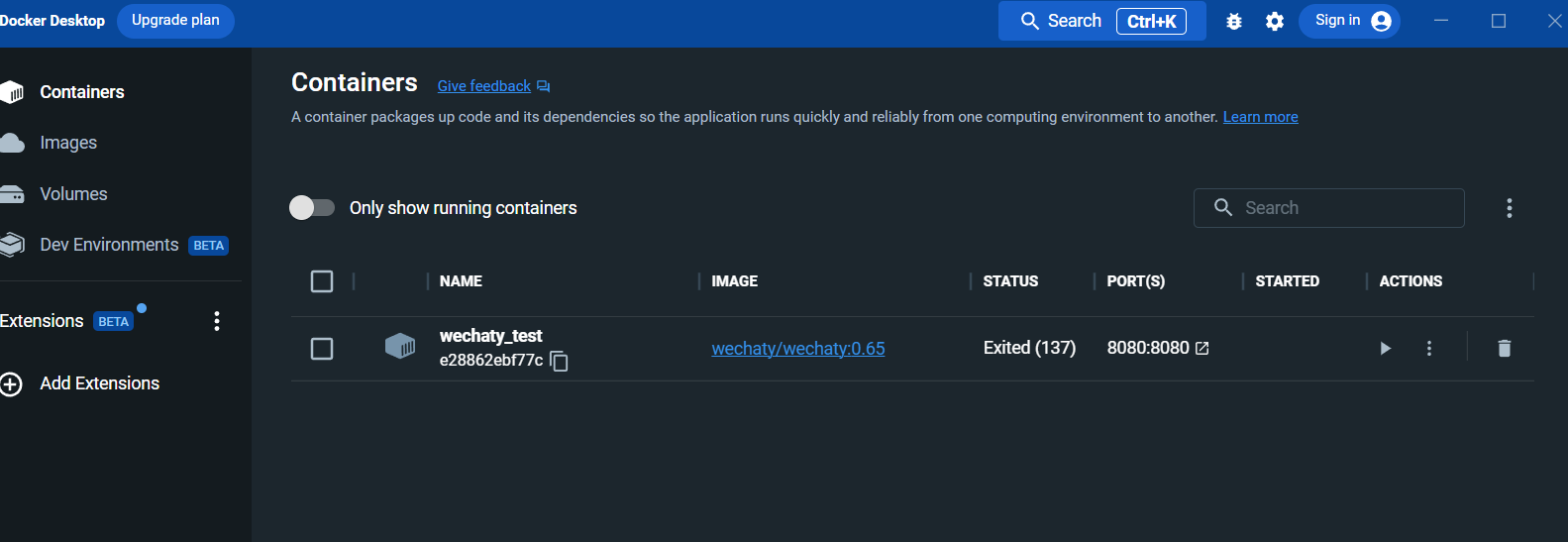
로그 인터페이스를 입력하십시오.
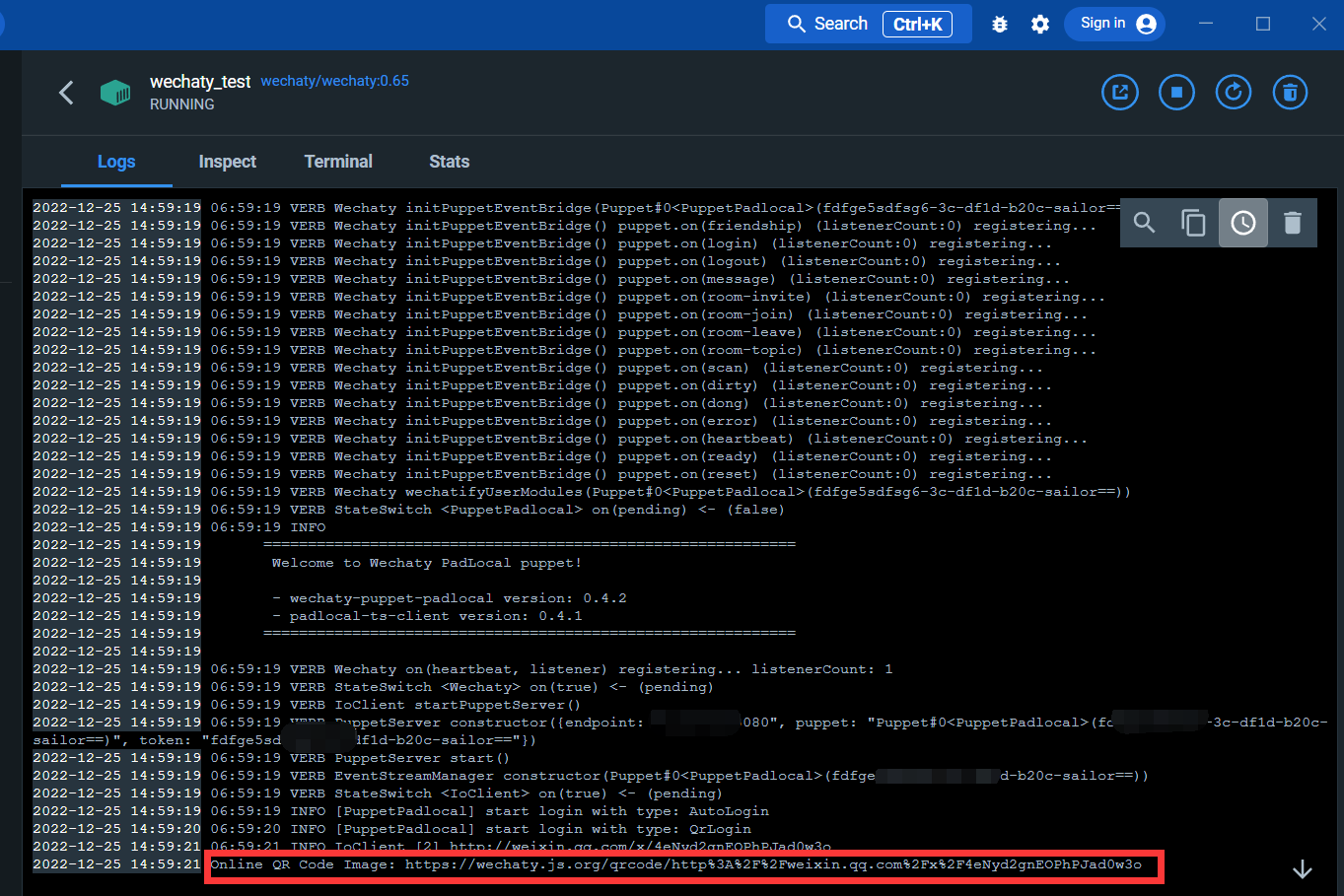
아래 링크를 통해 QR코드를 스캔하시면 위챗에 로그인하실 수 있습니다.
로그인하면 docker 서비스가 완료됩니다.
wechaty 및 openai 라이브러리 설치
cmd를 열고 다음 명령을 실행합니다.
pip install wechaty
pip install openaiopenAI에 로그인
https://beta.openai.com/
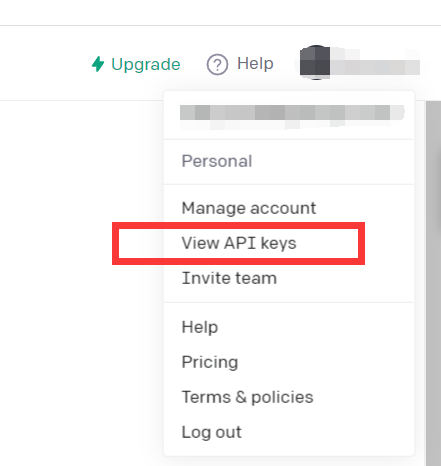
API 키 보기를 클릭하세요.
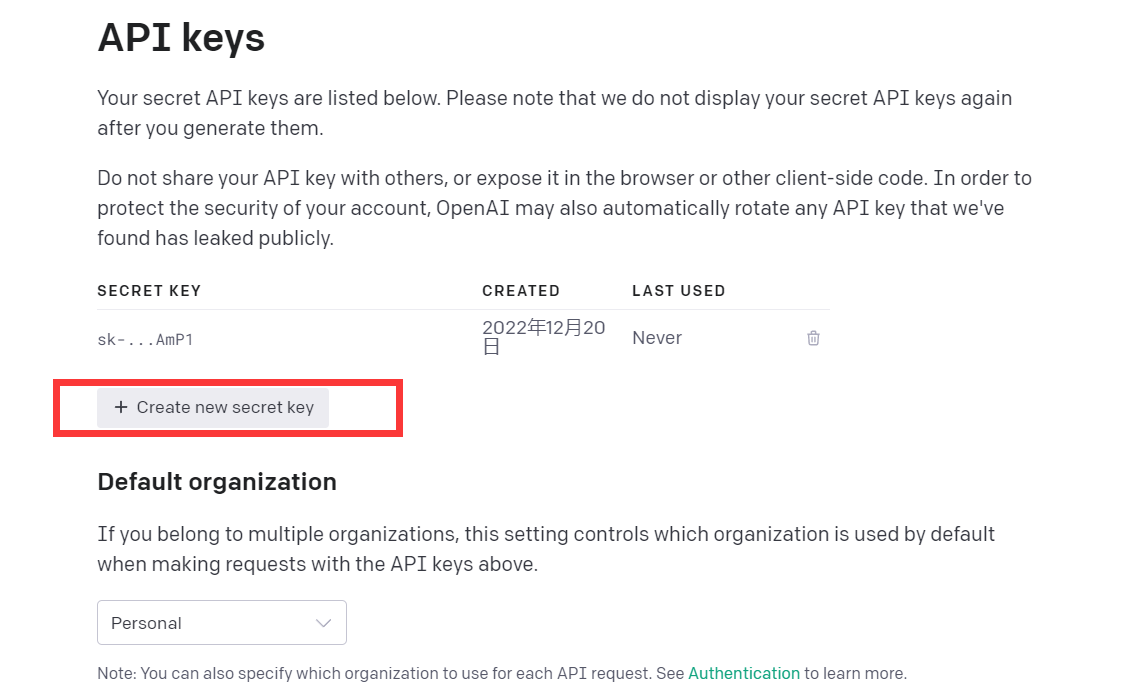
API 키를 받으세요
이 시점에서 환경이 설정되었습니다.
이 데모 코드를 읽어보세요
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
이 코드는 chatGPT와 동일한 모델인 CPT-3 모델을 호출하며 답변 효과도 좋습니다.
openAI의 GPT-3 모델은 다음과 같이 소개됩니다.
GPT-3 모델은 자연어를 이해하고 생성할 수 있으며, 다양한 작업에 적합한 다양한 수준의 성능을 갖춘 4가지 주요 모델을 제공하며, 가장 유능한 모델은 Ada입니다.
| 최신 모델 | 설명 | 최대 요청 | 훈련 데이터 |
|---|---|---|---|
| 텍스트-davinci-003 | 가장 유능한 GPT-3 모델. 다른 모델이 수행할 수 있는 모든 작업을 수행할 수 있으며, 종종 더 높은 품질, 더 긴 출력 및 더 나은 지침 따르기도 지원합니다. | 토큰 4,000개 | 2021년 6월까지 |
| 텍스트-퀴리-001 | 매우 유능하지만 Davinci보다 빠르고 저렴합니다. | 토큰 2,048개 | 2019년 10월까지 |
| 텍스트-배비지-001 | 간단한 작업을 매우 빠르고 저렴하게 수행할 수 있습니다. | 토큰 2,048개 | 2019년 10월까지 |
| 텍스트-ada-001 | 매우 간단한 작업이 가능하며 일반적으로 GPT-3 시리즈에서 가장 빠른 모델이며 비용이 가장 저렴합니다. | 토큰 2,048개 | 2019년 10월까지 |
일반적으로 Davinci가 가장 유능하지만 다른 모델은 상당한 속도나 비용 이점으로 특정 작업을 매우 잘 수행할 수 있습니다. 예를 들어 Curie는 Davinci와 동일한 작업을 대부분 수행할 수 있지만 더 빠르고 비용도 저렴합니다.
최상의 결과를 얻을 수 있으므로 실험하는 동안 Davinci를 사용하는 것이 좋습니다. 작업이 완료되면 다른 모델을 사용하여 더 짧은 대기 시간으로 동일한 결과를 얻을 수 있는지 확인하는 것이 좋습니다. 특정 작업에 맞게 모델을 미세 조정하여 모델의 성능을 향상시킵니다.
즉, 가장 강력한 GPT-3 모델입니다. 일반적으로 더 높은 품질, 더 긴 출력 및 더 나은 지시 사항을 통해 다른 모델이 할 수 있는 모든 작업을 수행할 수 있습니다. 텍스트에 완성을 삽입하는 것도 지원됩니다.
chatGPT의 단일 라운드 대화 효과를 달성하기 위해 text-davinci-003 모델을 직접 사용할 수 있지만 chatGPT와 동일한 다중 라운드 대화 효과를 더 잘 달성하기 위해 대화 모델을 설계할 수 있습니다.
기본 원칙: text-davinci-003 모델에 현재 대화의 맥락을 알려줍니다.
구현 방법: 현재 대화의 처음 k 라운드의 대화를 저장하도록 대화 메모리 큐를 설계하고, 질문하기 전에 text-davinci-003 모델에 처음 k 라운드의 대화 내용을 알려주고 현재 답변을 얻습니다. text-davinci-003 모델 컨텐츠를 통해
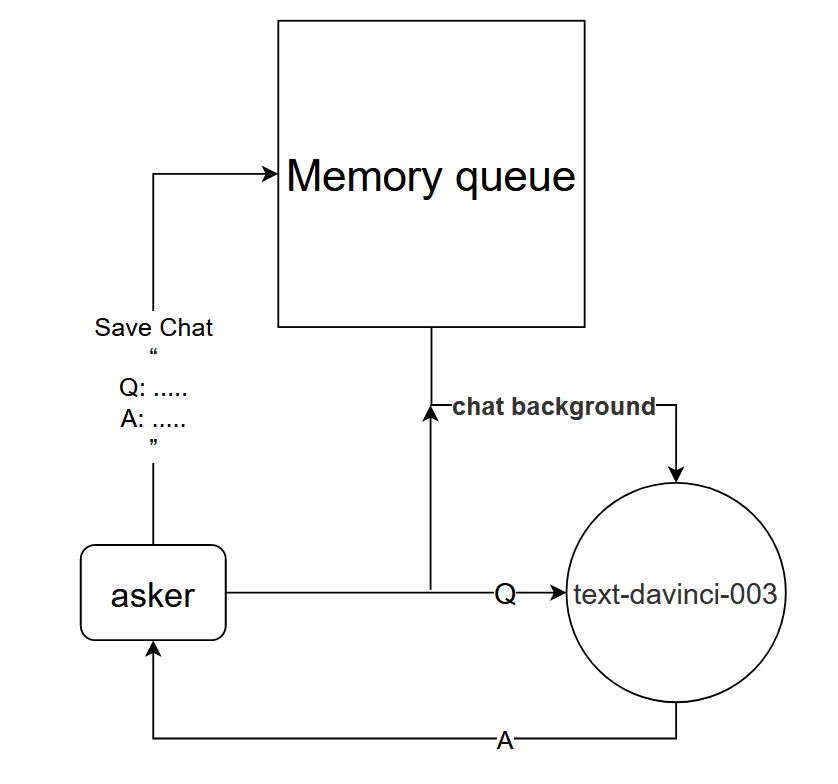
이 방법은 놀라울 정도로 효과적입니다! 채팅 기록을 좀 주세요
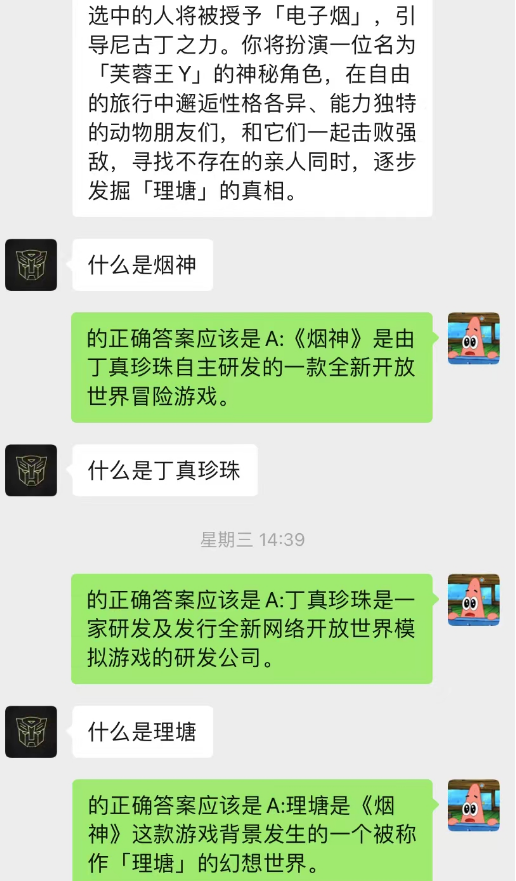
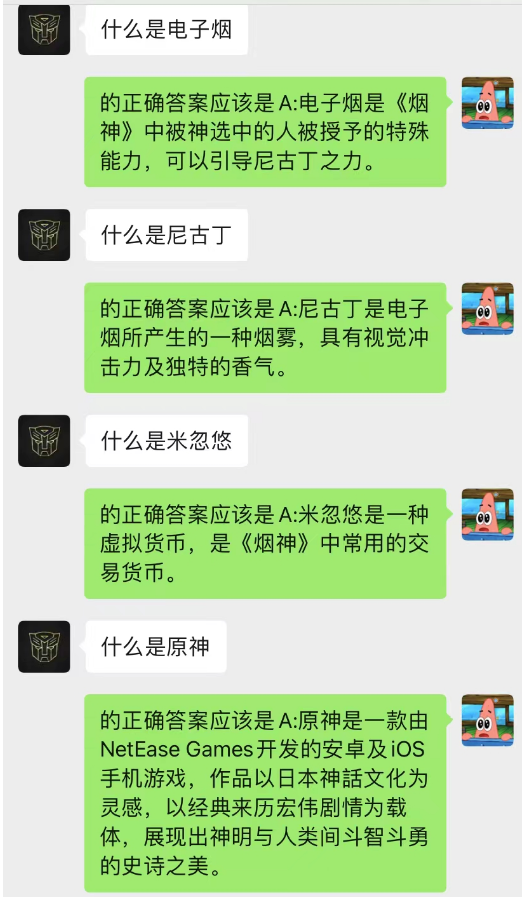
현재 채팅 배경을 사용하여 AI가 상황 학습을 완료할 수도 있음을 알 수 있습니다.
뿐만 아니라, chatGPT와 동일한 안내 기사 작성을 달성할 수도 있습니다.
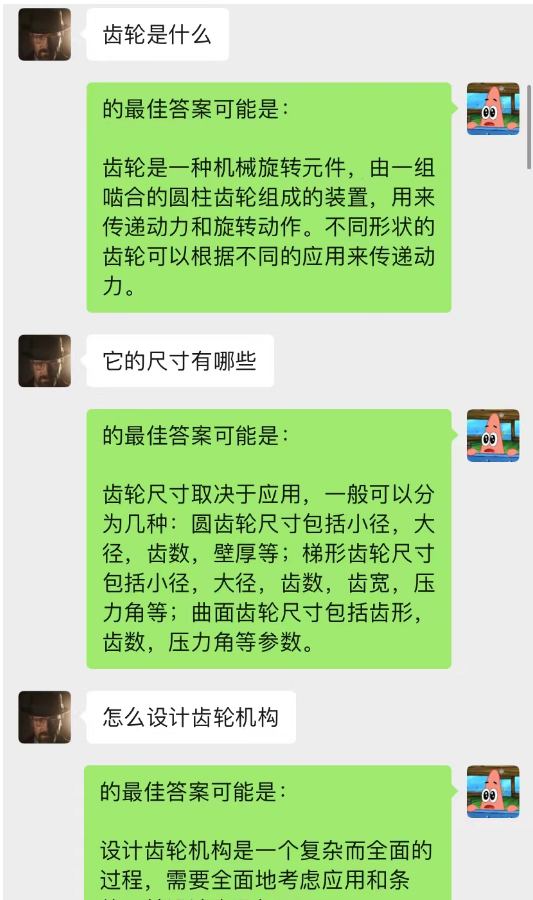
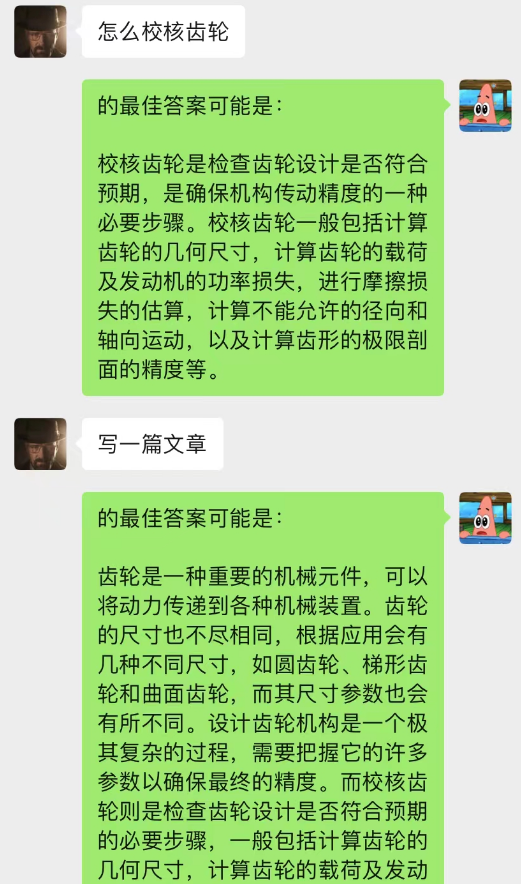
이 모델은 채팅 배경 대화 모델을 최적화하기 위해 현재 구상하고 있는 방법입니다. N이 동적으로 변경되고 현재 대화를 예측하기 위해 Markov 속성이 추가된다는 점을 제외하면 기본 논리는 N-gram 언어 모델과 동일합니다. 문맥을 분석하여 채팅 배경의 섹션이 가장 중요하다고 판단한 후 text-davinci-003 모델을 사용하여 가장 중요하게 기억된 대화 내용과 현재 문제를 기반으로 답변을 제공합니다(동등) AI 채팅 중에 하세요. 이전 채팅 내용을 활용하세요)
이 모델을 구현하려면 훈련을 위한 많은 양의 데이터가 필요하며 아직 코드가 완성되지 않았습니다.
------ Digging : 코드 구현 후 세부 단계 중 이 부분을 업데이트합니다.
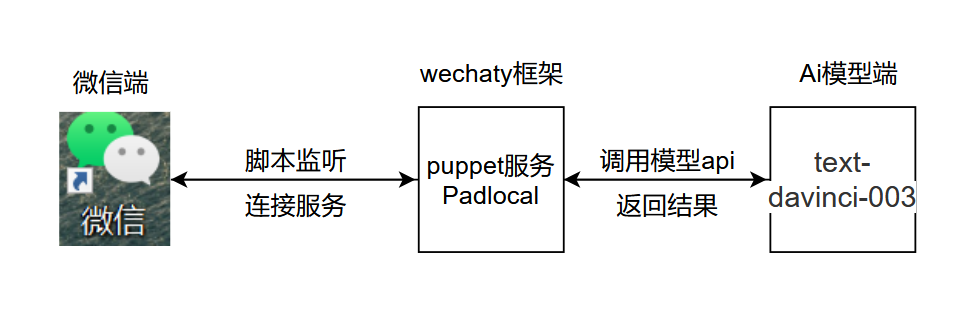
프로젝트의 기본 로직은 아래 그림과 같습니다.
 .py, 표시된 위치에서 chatGPT.py를 추가하고 열고, 표시된 위치에서 비밀 키를 추가하고 환경 변수를 구성합니다.
.py, 표시된 위치에서 chatGPT.py를 추가하고 열고, 표시된 위치에서 비밀 키를 추가하고 환경 변수를 구성합니다.

코드 설명 :
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
성공적으로 실행
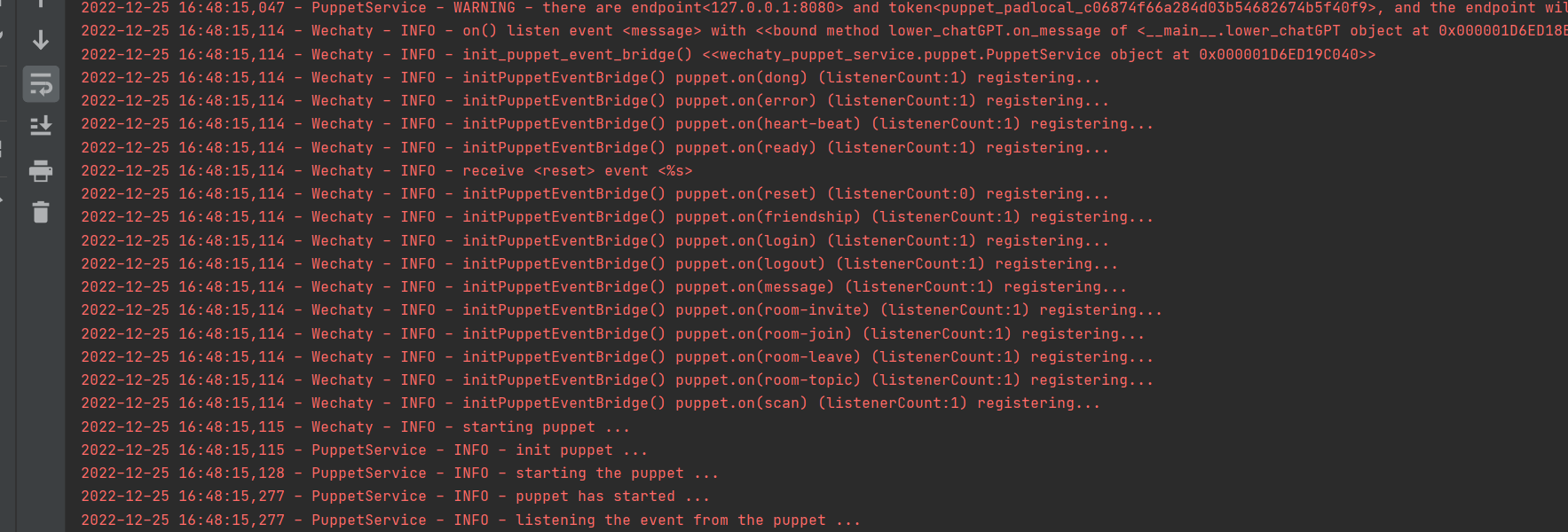
1. docker에 로그인하세요. Python에서는 wechaty 로그인을 사용하지 마세요.
2. 사람들이 메시지에 응답하는 속도를 시뮬레이션하려면 코드에서 time.sleep()을 설정하십시오.
3. 테스트할 때 큰 크기를 사용하지 않는 것이 가장 좋습니다. AI 테스트를 위한 전용 작은 크기를 만드는 것이 좋습니다.
본 프로젝트의 내용은 단지 기술 연구 및 과학 대중화를 위한 것이며 어떠한 결정적인 근거도 제공하지 않으며 어떠한 상업적인 응용 승인도 제공하지 않으며 어떠한 행위에 대해서도 책임을 지지 않습니다.
~~이메일: [email protected]


