glory admin
1.0.0
GloryAdmin은 springboot2.1.9.RELEASE 및 vue-admin-template을 기반으로 하는 백그라운드 프레임워크입니다.
GloryAdmin은 역할 기반 권한 관리를 사용합니다. 역할 트리는 "시스템 관리자"를 루트 노드로 하는 트리이고, 권한 트리는 여러 개의 하위 권한 트리로 구성됩니다. "시스템 관리자"는 모든 권한을 가집니다. 시스템 관리자가 아닌 역할은 현재 역할과 직속 하위 역할의 정보를 볼 수 있지만 직속 하위 역할의 정보만 추가, 삭제, 수정할 수 있습니다. (직속 하위 역할: A는 직속 역할입니다.) B의 하위 노드인 경우 A는 B의 하위 노드여야 합니다.
영광-관리자
| 프로젝트 | 기술 |
|---|---|
| 백엔드 프로젝트 | 스프링부트 |
| 프론트엔드 프로젝트 | 요소 UI 및 Vue.js |
| 데이터 베이스 | MySQL |
| 은닉처 | 레디스 |

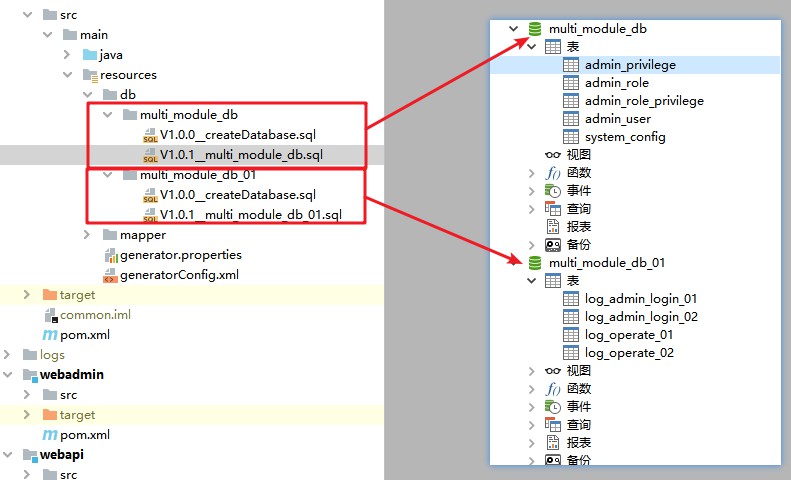
이 프로젝트는 mysql 데이터베이스를 사용합니다. 데이터베이스 스크립트를 사용하여 2개의 데이터베이스 multi_module_db multi_module_db_01을 생성할 수 있습니다.
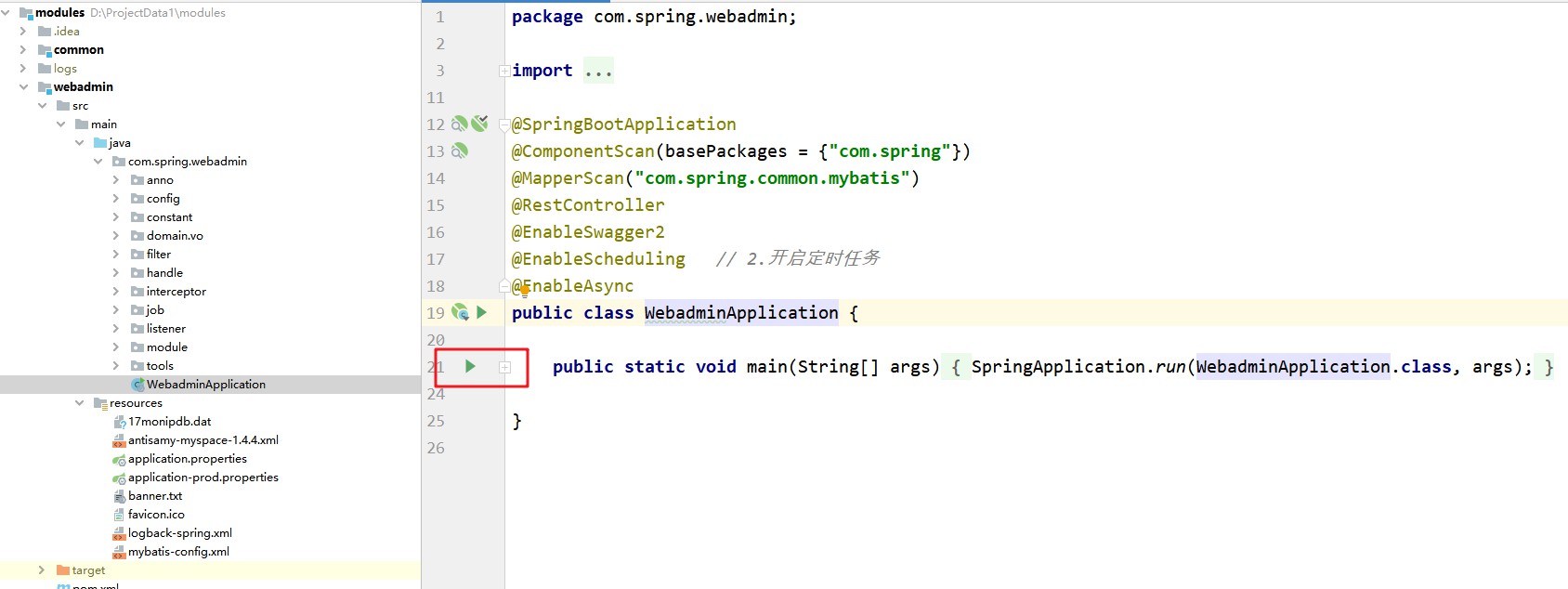
백그라운드에서 시작하고 포트 28081을 사용하십시오.
프런트 엔드를 시작하고 포트 9523을 사용하십시오.
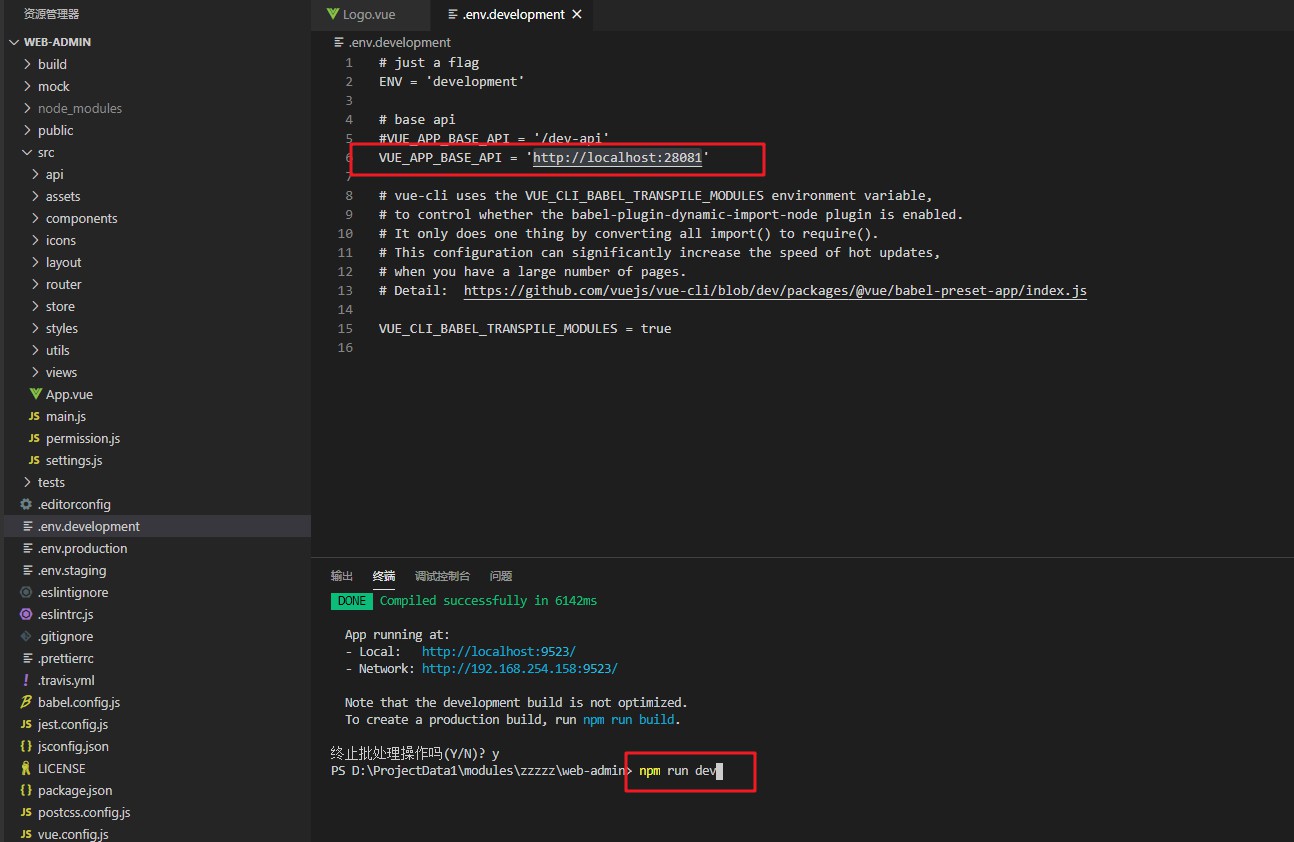
브라우저를 열고 http://localhost:9523 admin a123456을 방문하세요.
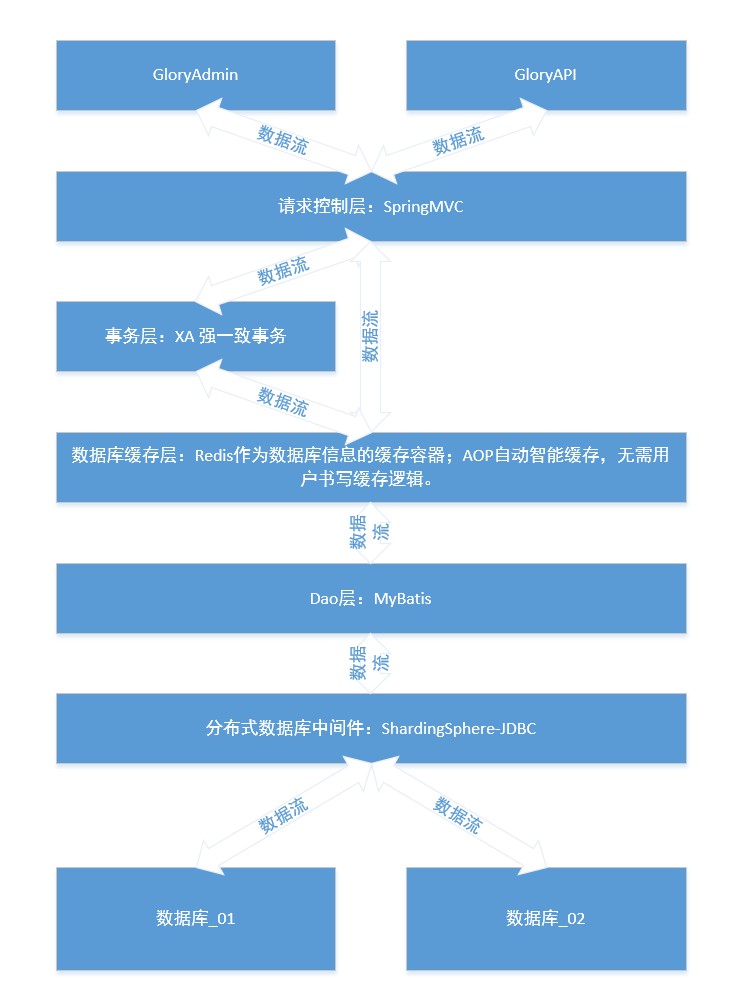
샤딩 또는 샤딩의 본질은 무어의 법칙이 실패한다는 것입니다. 단일 데이터 노드에 데이터를 중앙 집중식으로 저장하는 솔루션은 성능, 가용성, 운영 및 유지 관리 비용 측면에서 인터넷의 대규모 데이터 시나리오를 충족하기가 어려웠습니다.
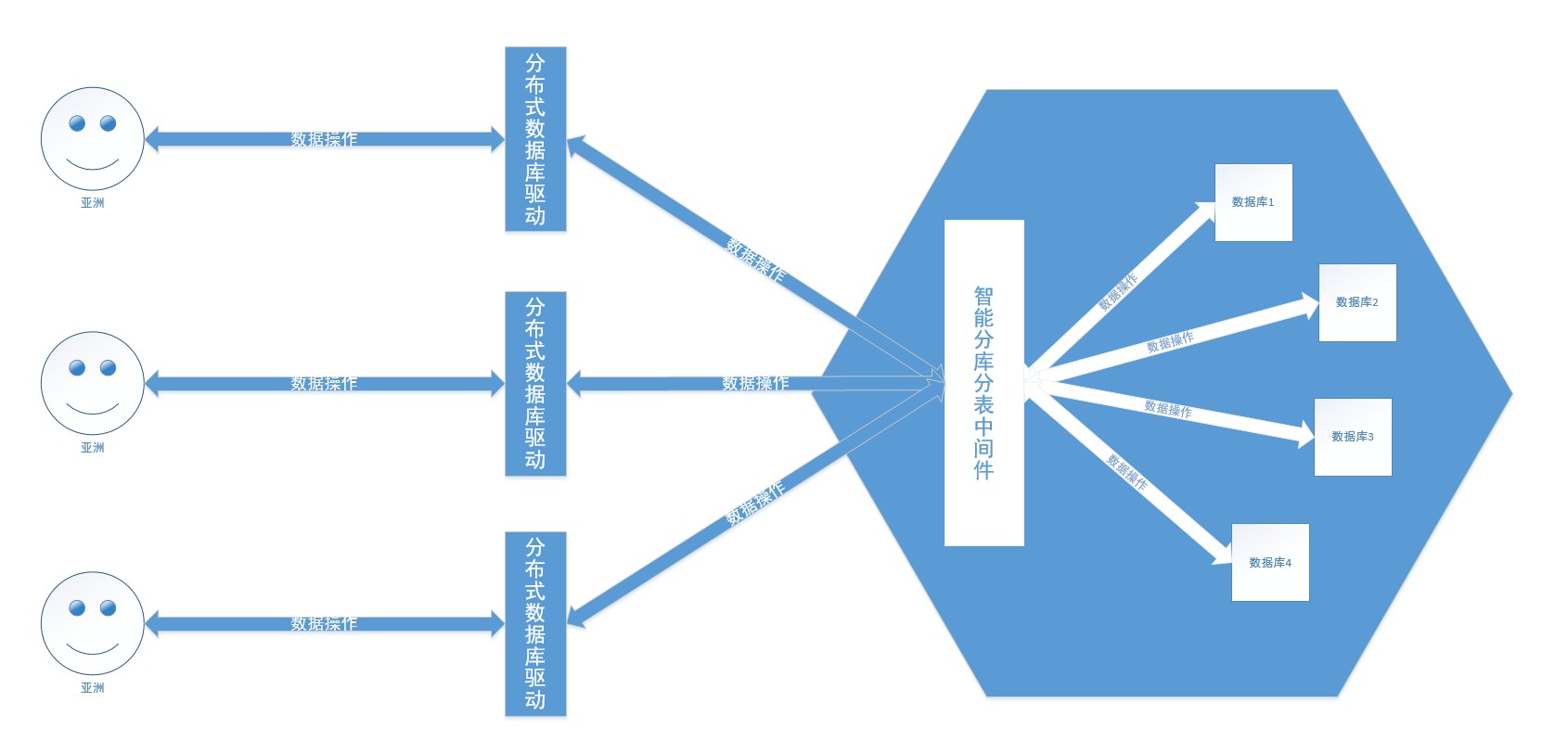
단일 데이터베이스로는 기존 업무를 지원할 수 없어 하위 데이터베이스와 테이블이 등장했고, 데이터 저장을 위해 여러 데이터베이스가 사용됐다. 하위 데이터베이스와 하위 테이블에 대한 간단한 이해는 바구니의 내용이 제한되어 검색 효율성과 용량에 영향을 미친다는 것입니다. 이는 용량 제약을 해소하고 쿼리 효율성을 향상시킵니다.
그렇다면 중국에서 가장 인기 있는 데이터베이스로는 Tencent의 TDSQL, Alibaba의 OceanBase, PolarDB, Huawei의 GaussDB 등이 있습니다. 기본적으로 이들은 강력한 일관성과 고가용성, 글로벌 배포 아키텍처, 분산형 무제한 수평 확장, 고성능, 수천억 개의 레코드, 수백 TB의 데이터에 대한 교차 행 및 교차 테이블 트랜잭션을 갖춘 독립적으로 개발되었습니다(예: 조국) . 분산 데이터베이스는 데이터베이스 샤딩 및 테이블 샤딩 전략을 숨기고 데이터를 데이터베이스와 테이블로 지능적으로 샤딩하여 데이터베이스를 운영하는 것처럼 사용합니다.
메모리 작업과 디스크 작업의 크기가 전혀 동일하지 않기 때문에 대규모 프로젝트에는 디스크 데이터를 메모리에 캐시하기 위해 디스크 유형 데이터베이스 에 대한 메모리 유형 버퍼 계층이 필요합니다. 데이터 캐싱 계층은 전체 데이터 계층의 데이터를 캐시하여 사이트 액세스 속도를 높이는 데 사용됩니다. 이 프로젝트는 AOP 기술 과 Redis 인메모리 데이터베이스를 데이터 캐시 계층으로 사용합니다. 자세한 내용은 com/spring/common/aop/CacheDaoAspect.java 코드를 확인하세요.
이 프로젝트는 샤딩 JDBC를 사용하여 데이터베이스와 데이터베이스의 테이블을 처리합니다. 비즈니스 시나리오에 따라 데이터를 직접 분할하세요.
일반적으로 프로젝트에는 하나의 데이터베이스만 있으며, Alibaba Cloud의 druid는 중국에서 데이터베이스 연결 풀로 더 자주 사용됩니다. 이 프로젝트에서는 mysql, druid, sharding JDBC를 사용합니다. 데이터 샤딩의 원칙은 프로그램에서 여러 데이터베이스 연결 풀을 유지하는 것이며 각 데이터베이스 연결 풀은 데이터베이스에 해당합니다. 샤딩된 데이터베이스와 샤딩된 테이블은 XA 프로토콜을 기반으로 하는 2단계 트랜잭션 처리를 사용합니다 . 구성 경로 com.spring.common.config.shardingJDBC
수직 분할: 비즈니스 분할 방법을 수직 샤딩이라고 하며 수직 분할이라고도 합니다. 업무에 따라 테이블을 서로 다른 데이터베이스에 분산함으로써 압력을 서로 다른 데이터베이스에 분산시킵니다.
수평 분할: 비즈니스 로직 분류에 신경 쓰지 않고, 특정 테이블의 특정 필드(또는 여러 필드)를 통해 특정 규칙에 따라 데이터를 여러 라이브러리나 테이블로 분산시킵니다. 여기에 있는 규칙과 관련된 알고리즘을 샤딩 알고리즘 이라고 합니다.
( 다음 내용은 shardingJDBC 문서에서 가져온 것입니다 .)
단일 키를 분할 키로 사용하여 = 및 IN 분할 시나리오를 처리하는 데 사용되는 PreciseShardingAlgorithm에 해당합니다. StandardShardingStrategy와 함께 사용해야 합니다.
단일 키를 분할 키로 사용하여 BETWEEN AND , > , < , >= 및 <= 사용하여 분할 시나리오를 처리하는 데 사용되는 RangeShardingAlgorithm에 해당합니다. StandardShardingStrategy와 함께 사용해야 합니다.
여러 키가 분할을 위한 분할 키로 사용되는 시나리오를 처리하는 데 사용되는 ComplexKeysShardingAlgorithm에 해당합니다. 여러 분할 키를 포함하는 논리는 복잡하며 애플리케이션 개발자가 직접 복잡성을 처리해야 합니다. ComplexShardingStrategy와 함께 사용해야 합니다.
Hint 행 샤딩이 사용되는 시나리오를 처리하는 데 사용되는 HintShardingAlgorithm에 해당합니다. HintShardingStrategy와 함께 사용해야 합니다.
사용자는 로그인하여 토큰을 획득하고 이를 로컬에 저장합니다(adminLogin).
사용자는 사용자 정보와 권한 정보를 얻기 위해 토큰을 보내고 이를 스토어에 저장합니다. F5를 누르면 저장소가 손실되므로 프런트 엔드 요청에 인터셉터가 추가됩니다. 사용자 정보 및 권한 정보가 없으면 사용자 정보 및 권한을 다시 얻습니다(getAdminInfo).
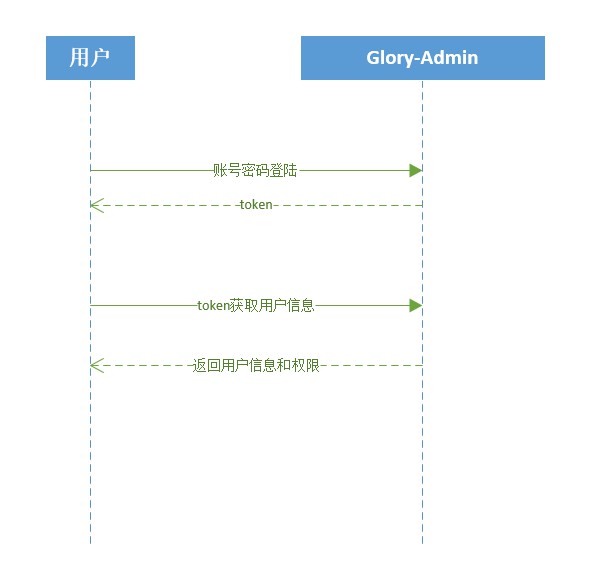
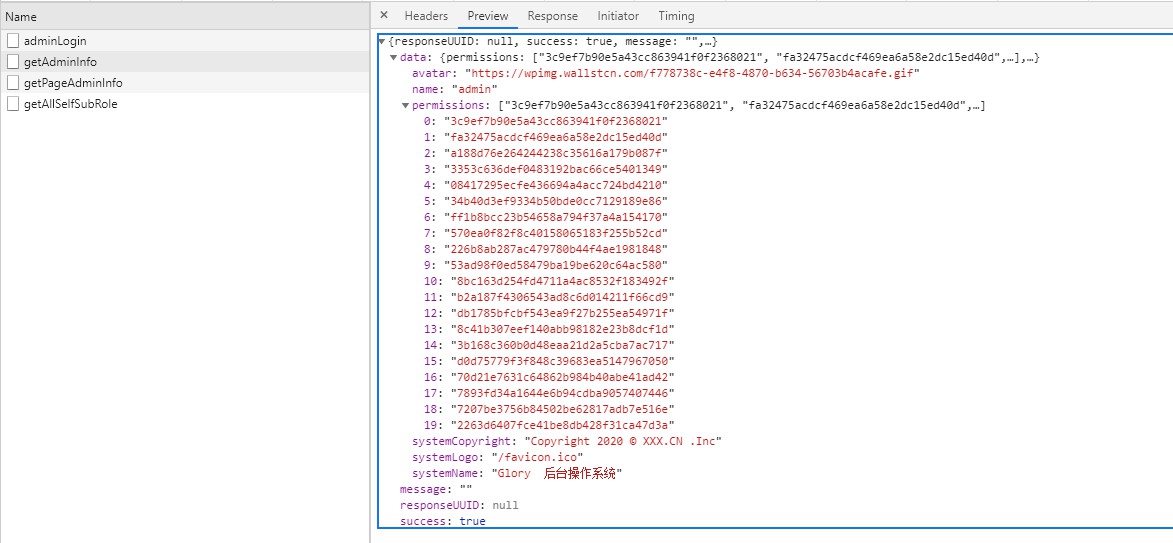
여기에 반환되는 것은 역할이 아닌 사용자의 모든 권한입니다. 사용자는 프런트 엔드 경로를 동적으로 생성합니다.
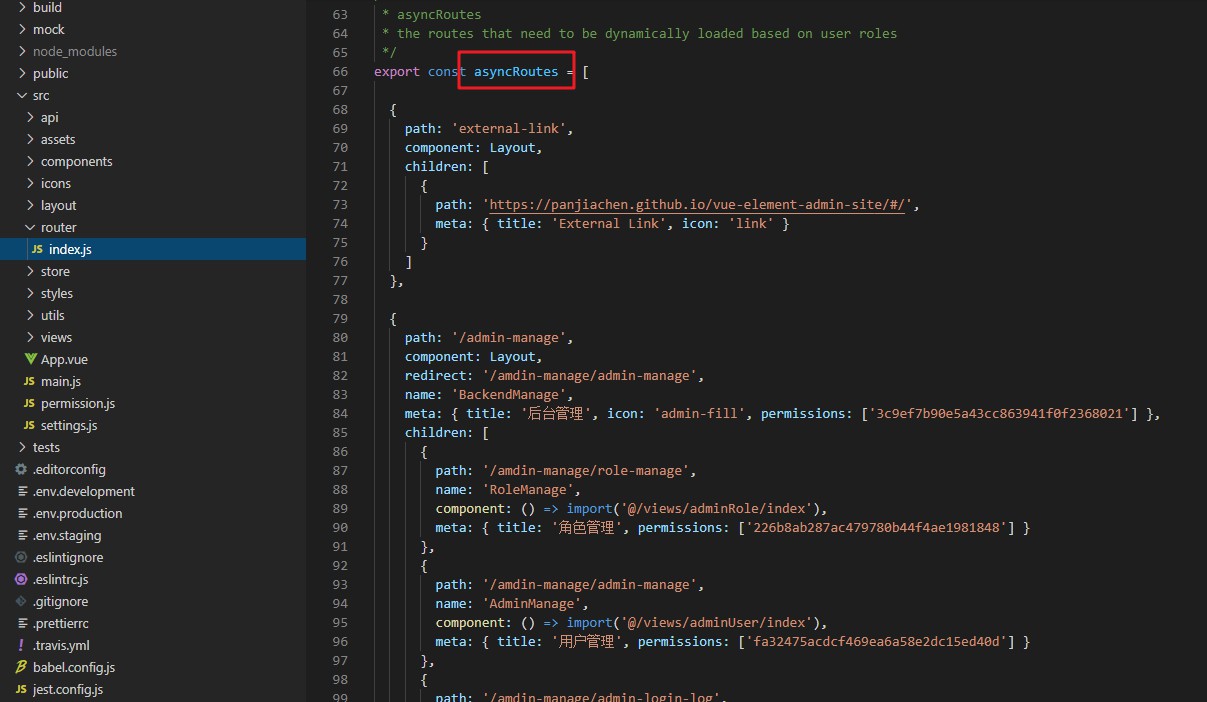
asyncRoutes는 동적으로 생성된 권한입니다. 사용자의 권한이 경로의 권한과 일치하면 표시됩니다.
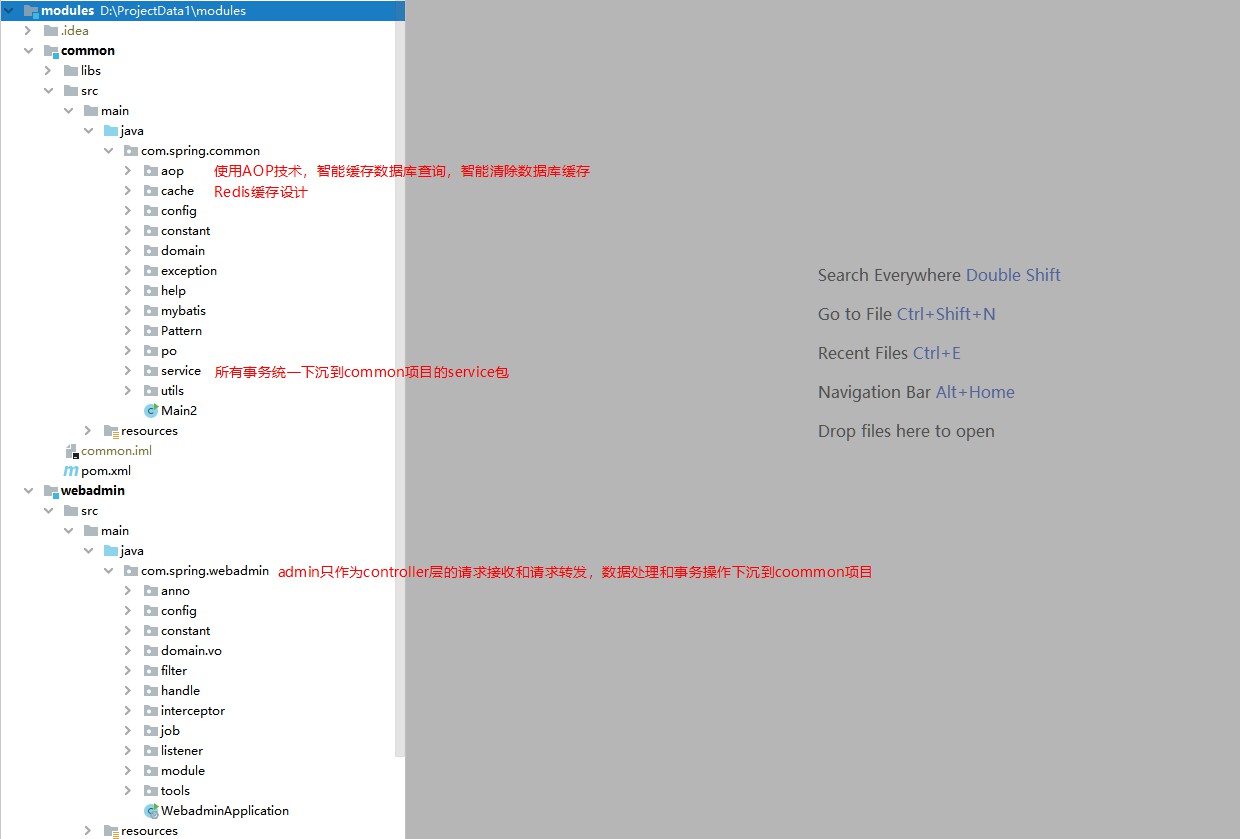
공통: 데이터 작업, 데이터 캐싱, 트랜잭션 작업
관리자는 사용자 요청과 백엔드 비즈니스 간의 전달을 처리하는 데 사용되는 컨트롤러 역할만 수행합니다. (이렇게 설계한 이유는 무엇입니까?) 일부 미들웨어 시스템에서는 요청 전달을 위해 RPC 프레임워크를 사용해야 하고, 일부 기밀 시스템에서는 springMVC 사용을 거부하고 요청 계층을 독립적으로 개발하기 위해 vertx를 선택하기 때문입니다.
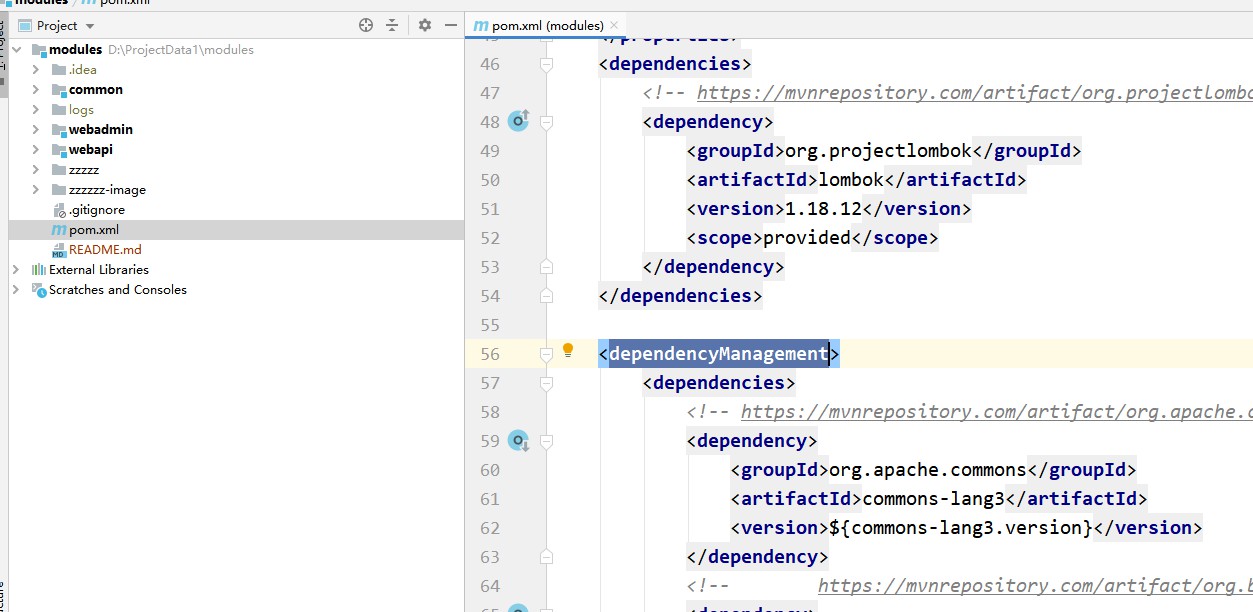
Maven 상속을 사용하여 프로젝트 종속성을 관리합니다. 모듈에서는 dependencyManagement를 통해 종속성이 도입되고 하위 프로젝트는 모듈을 상속하므로 종속성을 도입할 때 버전을 지정할 필요가 없습니다.
전역 로그 처리
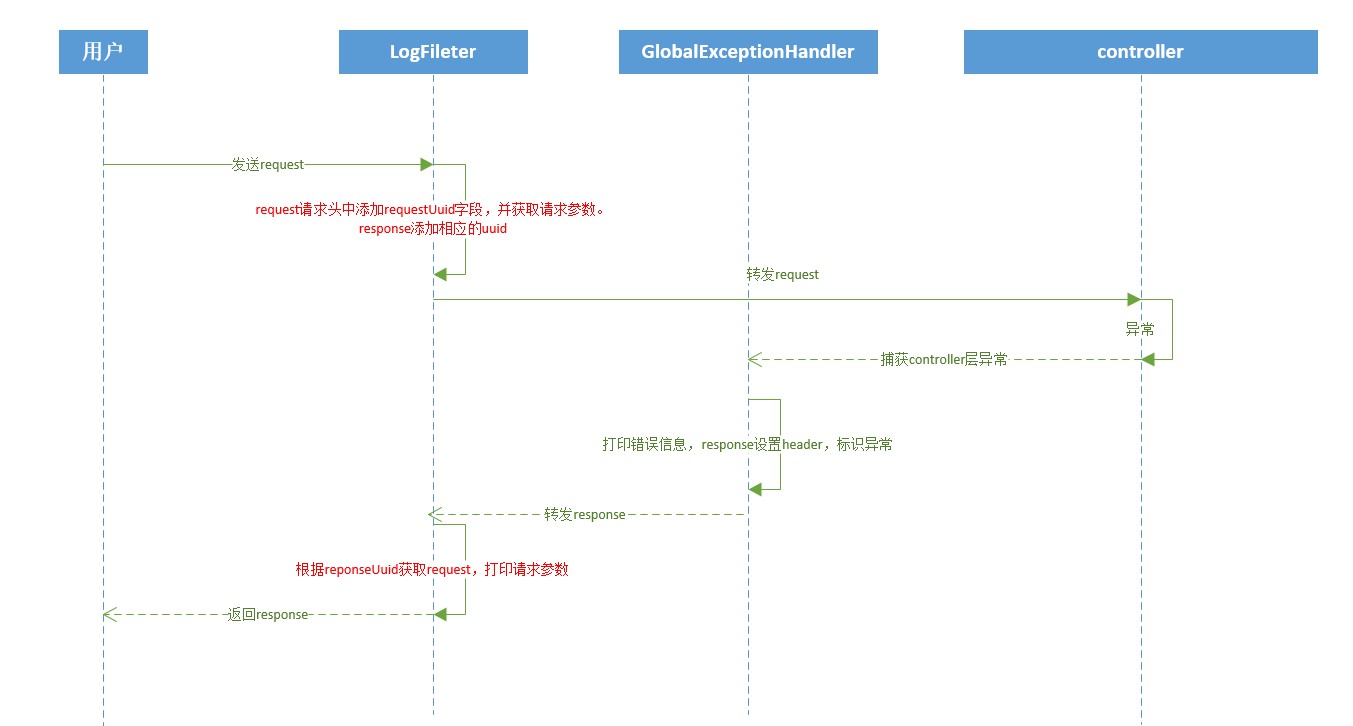
사용자 작업 로그는 주석 방법을 사용합니다. 이 메서드가 작업 로그를 기록해야 하는 경우 메서드 이름 위에 **@OperateLog** 주석을 추가하면 됩니다.
@ OperateLog
@ ApiOperation ( value = "登出" , notes = "登出" )
@ GetMapping ( Route . Admin . adminLogout )
public ResponseDate adminLogout ( HttpServletRequest httpServletRequest ) {
AdminInfoDTO adminInfoDTO = AdminTool . getAdminUser ( httpServletRequest );
AdminUser adminUser = adminUserMapper . selectByPrimaryKey ( adminInfoDTO . getAdminUk ());
adminUser . setNowToken ( "log-out" );
int result = adminUserService . updateAdminToken ( adminUser );
return ResponseDate . builder ()
. success ( result == 1 )
. build ();
}

