신경망을 사용하여 매트릭스를 반전시킵니다.
반전 행렬은 신경망에 대한 고유 한 과제를 제시합니다. 주로 곱셈 및 활성화 분할과 같은 정확한 산술 작업을 수행하는 데있어 고유 한 제한으로 인해 발생합니다. 전통적인 조밀 한 네트워크는 종종 매트릭스 역전과 관련된 복잡성을 처리하도록 명시 적으로 설계되지 않았기 때문에 이러한 작업에 도움이 필요합니다. 단순한 조밀 한 신경망으로 수행 된 실험은 정확한 매트릭스 역전을 달성하는 중대한 어려움을 보여주었습니다. 아키텍처 및 교육 프로세스를 최적화하려는 다양한 시도에도 불구하고 결과는 종종 개선이 필요합니다. 그러나 7 층 잔류 네트워크 (RESNET) 인보다 복잡한 아키텍처로 전환하면 성능이 크게 향상되었습니다.
잔류 연결을 통해 깊은 표현을 배울 수있는 능력으로 알려진 RESNET 아키텍처는 매트릭스 역전을 해결하는 데 효과적인 것으로 입증되었습니다. 수백만 개의 매개 변수를 사용하면이 네트워크는 단순한 모델이 할 수없는 데이터 내에서 복잡한 패턴을 캡처 할 수 있습니다. 그러나 이러한 복잡성은 비용이 많이 듭니다. 효과적인 일반화를 위해서는 상당한 교육 데이터가 필요합니다.
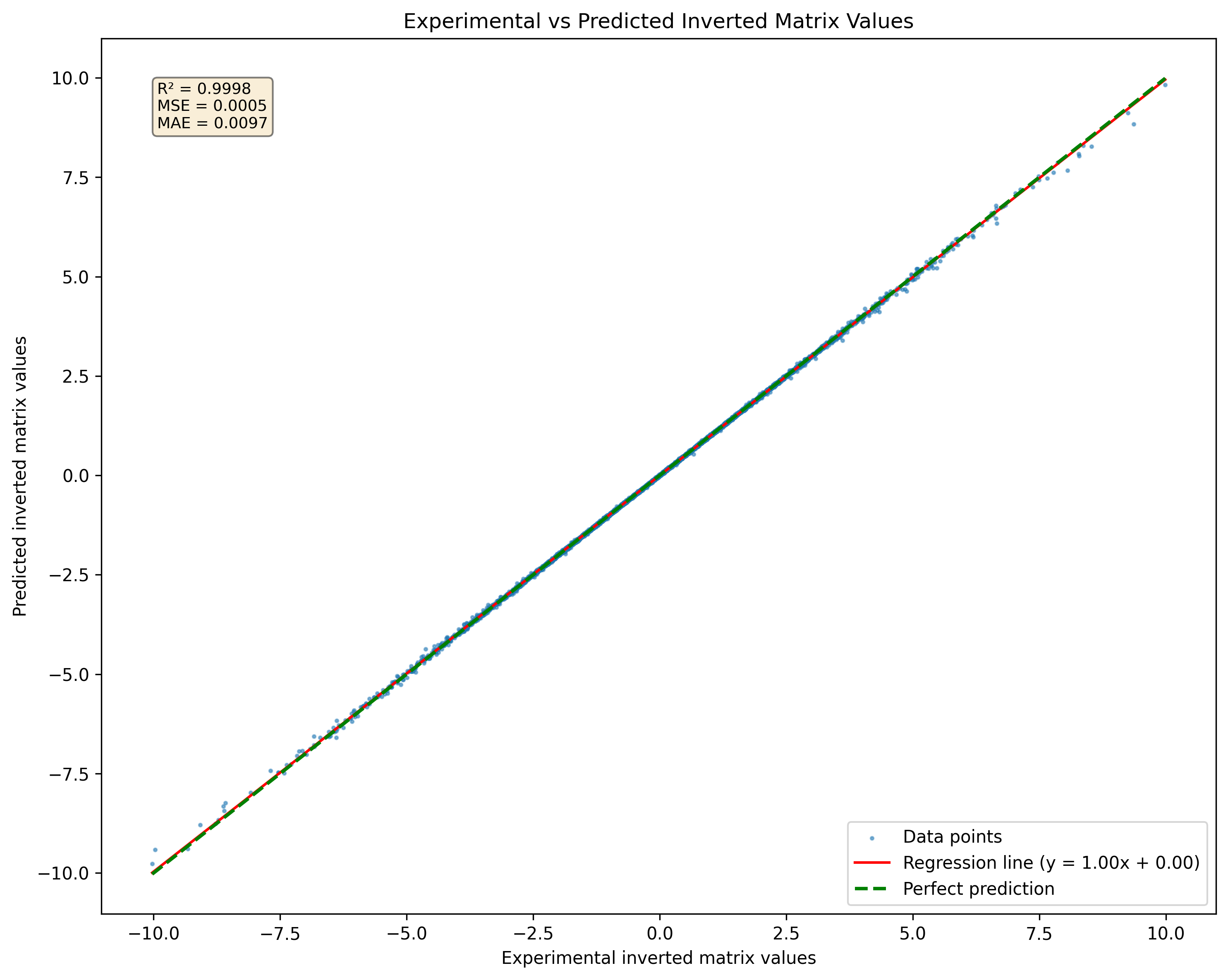 그림 1 : 데이터 세트에서 볼 수없는 행렬 세트 3x3에 대한 신경망 예측 반전 매트릭스의 시각화
그림 1 : 데이터 세트에서 볼 수없는 행렬 세트 3x3에 대한 신경망 예측 반전 매트릭스의 시각화
매트릭스 역전을 예측할 때 신경망의 성능을 평가하기 위해 특정 손실 함수가 사용됩니다.
이 방정식에서 :
목표는 정체성 매트릭스와 원래 행렬의 곱 사이의 차이와 예측 된 역수의 차이를 최소화하는 것입니다. 이 손실 기능은 예측 된 역이 얼마나 가까운 지 효과적으로 측정합니다.
또한 if
이 손실 함수는 평균 제곱 오차 (MSE) 또는 평균 절대 오차 (MAE)와 같은 기존 손실 함수에 비해 뚜렷한 이점을 제공합니다.
역전 정확도의 직접 측정 행렬 역전의 주요 목표는 매트릭스의 생성물과 그 역이 정체성 매트릭스를 생성하도록하는 것입니다. 손실 함수는 ID 매트릭스의 편차를 측정 하여이 요구 사항을 직접 캡처합니다. 대조적으로, MSE와 MAE는 행렬 역전의 기본 속성을 명시 적으로 다루지 않고 예측 된 값과 실제 값의 차이에 중점을 둡니다.
제품 AA -1AA -1이 II에 얼마나 가까운지를 평가하는 손실 함수를 사용하여 구조적 무결성에 중점을두면 관련된 행렬의 구조적 무결성을 유지하는 것을 강조합니다. 이것은 선형 관계를 보존하는 응용 분야에서 특히 중요합니다. MSE 및 MAE와 같은 전통적인 손실 기능은 이러한 구조적 측면을 설명하지 않으므로 오류를 최소화하지만 매트릭스 역전의 수학적 요구 사항을 충족시키지 못하는 솔루션으로 이어집니다.
비-소싱 매트릭스에 대한 적용 가능성이 손실 함수는 본질적으로 역전 된 행렬이 비-싱글 (즉, 뒤집을 수 없음)이라고 가정한다. 단일 행렬이 존재하는 시나리오에서, 전통적인 손실 기능은 유효한 역수를 얻을 수 없기 때문에 오해의 소지가있는 결과를 낳을 수 있습니다. 제안 된 손실 함수는 단일 행렬을 반전하려고 할 때 더 큰 오류를 생성 함으로써이 제한을 강조합니다.
매트릭스 역전에 신경망을 사용할 때의 중요한 한 가지 중 하나는 단일 행렬을 효과적으로 처리 할 수 없다는 것입니다. 단일 매트릭스는 역전이 없습니다. 따라서, 이러한 매트릭스에 대한 역을 예측하려는 신경망에 의한 모든 시도는 잘못된 결과를 산출 할 것이다. 실제로, 훈련 또는 추론 중에 단일 매트릭스가 제시되는 경우 네트워크는 여전히 결과를 출력 할 수 있지만이 출력은 유효하거나 의미가 없습니다. 이 제한은 훈련 데이터가 가능할 때마다 비 싱글 매트릭스로 구성되도록 보장하는 것의 중요성을 강조합니다.
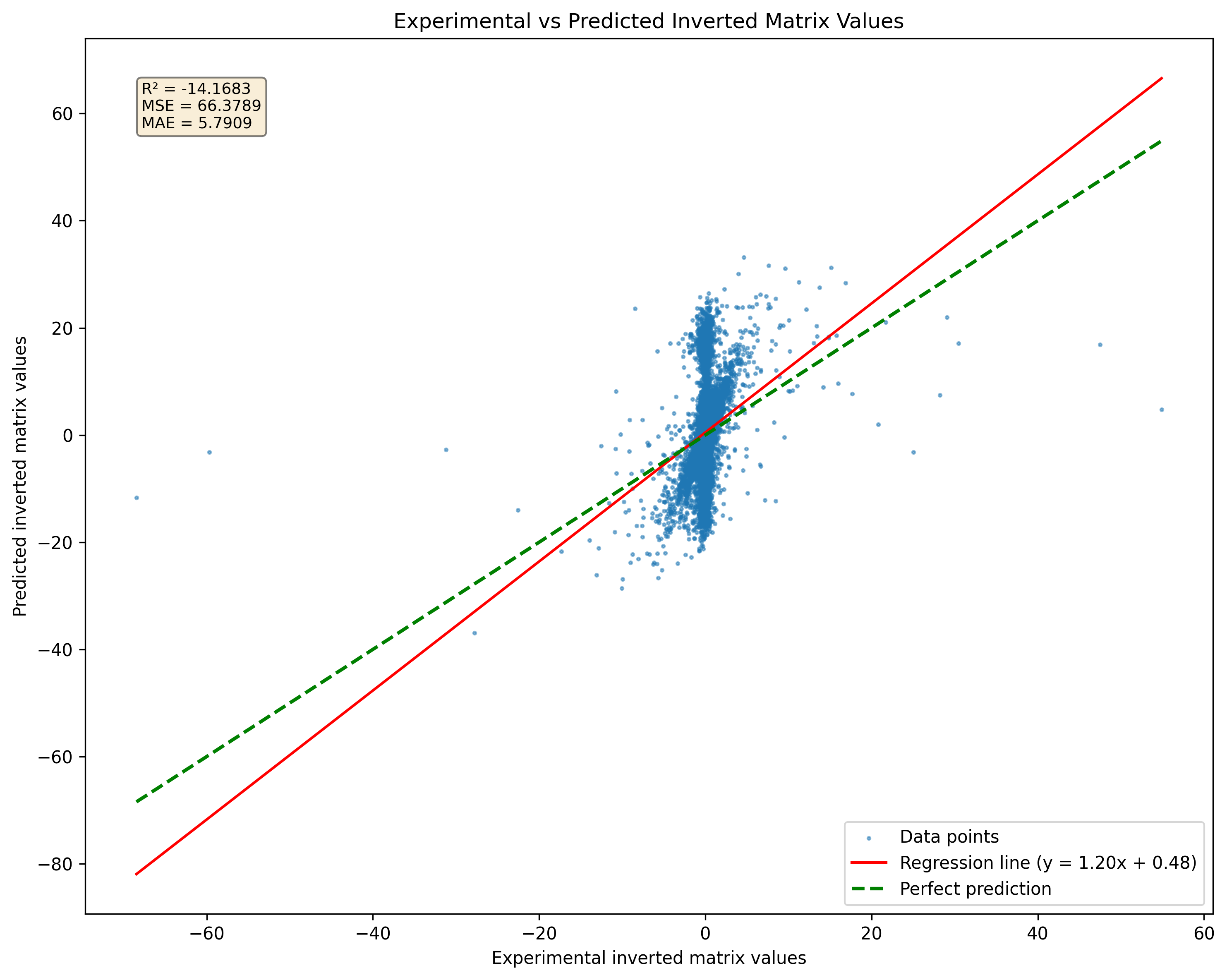 그림 2 : 단수 매트릭스 대 유사 전환에 대한 모델 예측 비교. 모델은 행렬 특이성에 관계없이 결과를 생성합니다.
그림 2 : 단수 매트릭스 대 유사 전환에 대한 모델 예측 비교. 모델은 행렬 특이성에 관계없이 결과를 생성합니다.
연구에 따르면 RESNET 모델은 정확도의 상당한 손실없이 많은 양의 샘플을 외울 수 있습니다. 그러나 데이터 세트 크기를 1 천만 샘플로 늘리면 심각한 과적이 될 수 있습니다. 이 과결한 데이터는 대량의 데이터에도 불구하고 발생하며, 단순히 데이터 세트 크기를 증가시키는 것이 복잡한 모델의 일반화가 향상되는 것을 보장하지는 않는다는 것을 강조합니다. 이 문제를 해결하기 위해 지속적인 데이터 생성 전략을 채택 할 수 있습니다. 정적 데이터 세트에 의존하는 대신 샘플을 즉시 생성하고 생성 될 때 네트워크에 공급 될 수 있습니다. 오버 피팅을 완화하는 데 결정적인이 접근법은 다양한 교육 예제를 제공 할뿐만 아니라 모델이 지속적으로 진화하는 데이터 세트에 노출되도록합니다.
요약하면, 산술 작동의 한계로 인해 매트릭스 역전은 본질적으로 신경망에 대해 도전적이지만 RESNET과 같은 고급 아키텍처를 활용하면 더 나은 결과를 얻을 수 있습니다. 그러나 데이터 요구 사항과 과적에 적합한 위험을 신중하게 고려해야합니다. 훈련 샘플을 지속적으로 생성하면 모델의 학습 프로세스를 향상시키고 매트릭스 역전 작업의 성능을 향상시킬 수 있습니다. 이 버전은 비 개인적인 톤을 유지하면서 매트릭스 역전을위한 신경 네트워크를 훈련시키는 데 어려움과 전략을 논의합니다.
DeepMatrixInversion은 LGPLV3 라이센스에 따라 배포됩니다
라이센스의 작동 방식에 대해 자세히 알아 보려면 "라이센스"파일을 읽거나 "http://www.gnu.org/licenses/lgpl-3.0.html"로 이동하십시오.
DeepMatrixinversion은 현재 Giuseppe Marco Randazzo의 재산입니다.
DeepMatrixinversion 저장소를 설치하려면시, PIP 또는 PIPX를 사용하는 중에서 선택할 수 있습니다.
git clone https://github.com/gmrandazzo/DeepMatrixInversion.git
cd DeepMatrixInversion
python3 -m venv .venv
. .venv/bin/activate
pip install poetry
poetry install
이렇게하면 DeepMatrixInversion을 실행하기 위해 필요한 모든 패키지로 환경이 설정됩니다.
가상 환경을 만들고 PIP로 deppmatrixinversion을 설치하십시오
python3 -m venv .venv
. .venv/bin/activate
pip install git+https://github.com/gmrandazzo/DeepMatrixInversion.git
분리 된 환경에 Python 응용 프로그램을 설치할 수있는 PIPX를 사용하려는 경우 다음 단계를 따르십시오.
python3 -m pip install --user pipx
apt-get install pipx
brew install pipx
sudo dnf install pipx
PIPX 설치 git+https : //github.com/gmrandazzo/deepmatrixinversion.git
행렬 역전을 수행 할 수있는 모델을 훈련 시키려면 DMXTRAIN 명령을 사용합니다. 이 명령을 사용하면 매트릭스의 크기, 값 범위 및 훈련 기간과 같은 교육 프로세스를 제어하는 다양한 매개 변수를 지정할 수 있습니다.
dmxtrain --msize < matrix_size > --rmin < min_value > --rmax < max_value > --epochs < number_of_epochs > --batch_size < size_of_batches > --n_repeats < number_of_repeats > --mout < output_model_path > dmxtrain --msize --rmin -1 --rmax 1 --epochs 5000 --batch_size 1024 --n_repeats 3 --mout ./Model_3x3
--msize <matrix_size>: Specifies the size of the square matrices to be generated for training. For example, 3 for 3x3 matrices.
--rmin <min_value>: Sets the minimum value for the random elements in the matrices. For instance, -1 will allow negative values.
--rmax <max_value>: Sets the maximum value for the random elements in the matrices. For example, 1 will limit values to a maximum of 1.
--epochs <number_of_epochs>: Defines how many epochs (complete passes through the training dataset) to run during training. A higher number typically leads to better performance; in this case, 5000.
--batch_size <size_of_batches>: Determines how many samples are processed before the model is updated. A batch size of 1024 means that 1024 samples are used in each iteration.
--n_repeats <number_of_repeats>: Indicates how many times to repeat the training process with different random seeds or initializations. This can help ensure robustness; for instance, repeating 3 times.
--mout <output_model_path>: Specifies where to save the trained model. In this example, it saves to ./Model_3x3.
모델을 교육 한 후에는 모델을 사용하여 새로운 입력 행렬에서 매트릭스 역전을 수행 할 수 있습니다. 추론 명령은 DMXINVERT이며 입력 행렬을 사용하여 역수를 출력합니다.
경고 : DMXINVERT는 셔먼-모리슨-우드 베리 매트릭스 블록 반전 공식을 통해 모델을 훈련시키는 데 사용 된 것보다 더 큰 매트릭스를 반전시킬 수 있습니다. 이 기능은 블록 크기를 알림없이 모델 교육 블록 크기로 나눌 수있는 행렬에서만 작동합니다. 이 기능은 매우 실험적이며 수정해야 할 수도 있습니다.
dmxinvert --inputmx <input_matrix_file> --inverseout <output_csv_file> --model <model_path>
dmxinvert --inputmx input_matrix.csv --inverseout output_inverse.csv --model ./Model_3x3_*
--inputmx <input_matrix_file>: Specifies the path to the input matrix file that you want to invert. This file should contain a valid matrix format (e.g., CSV).
--inverseout <output_csv_file>: Indicates where to save the resulting inverted matrix. The output will be saved in CSV format.
--model <model_path>: Provides the path to the trained model that will be used for performing the inversion.
입력 매트릭스 및 출력으로 인공 데이터 세트를 생성하면 DMX DMXDATASETGENERARTOR가 수행됩니다.
dmxdatasetgenerator 3 10 -1 1 test_3x3_range_-1+1
이렇게하면 크기 3x3의 10 개 매트릭스가 -1에서 +1 범위의 숫자를 생성합니다.
dmxdatasetgenerator [matrix size] [number of samples] [range min] [range max] [outname_prefix]
그런 다음 DMXDATASETVERIFY를 사용하여 데이터 세트를 검증 할 수 있습니다
dmxdatasetverify test_3x3_range_-1+1_matrices_3x3.mx test_3x3_range_-1+1_matrices_inverted_3x3.mx invertible
Dataset valid.
dmxdatasetverify [dataset matrix to invert] [dataset matrix inverted] [type: invertible or singular]
입력 행렬 파일은 다음과 같이 형식화되어야합니다.
0.24077047370124594,-0.5012474139608847,-0.5409542929032876
-0.6257864520097793,-0.030705148203584942,-0.13723920334288975
-0.48095686716222064,0.19220406568380666,-0.34750000491973854
END
0.4575368007107925,0.9627977617090073,-0.4115240560547333
0.5191433428806012,0.9391491187187144,-0.000952683255491138
-0.17757763984424968,-0.7696584771443977,-0.9619759413623306
END
-0.49823271153034154,0.31993947803488587,0.9380291202366384
0.443652116558352,0.16745965310481048,-0.267270356721347
0.7075720067281346,-0.3310912886946993,-0.12013367141105102
END
각 숫자 블록은 별도의 행렬을 나타내고 해당 행렬의 끝을 나타내는 엔드 마커를 나타냅니다.


