SEQ2SEQ 모델을 사용하여 기계 번역을 수행하려면 REST API를 개발하십시오. 모델 배포는 Google Cant Platform을 사용하여 수행됩니다.
프로젝트는 다음과 함께 생성됩니다.
이 프로젝트의 데이터는 데이터 소스의 텍스트 파일로 사용할 수 있으며, 각 줄은 칸나다어에 문장이 있고 공간 구분 기호와 함께 영어로 번역됩니다. 우리는 각 예제가 의미가 있는지 확인하기 위해 무작위로 확인했습니다.
먼저 Gru RNN을 사용한주의 메커니즘으로 인코더 디코더 모델을 구축합니다. 교육은 여기에서 사용할 수있는 Python 스크립트를 사용하여 수행되었습니다
주소 http://127.0.0.1:5000/predict에서 로컬 머신에서 액세스 할 수있는 플라스크 응용 프로그램을 구축하십시오.
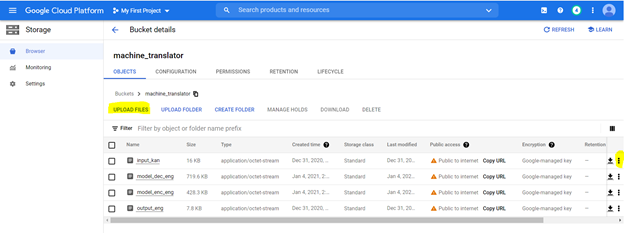
스크립트를 사용하여 모델을 훈련시킵니다. 모델을 교육 한 후 모델 가중치를 .pt 파일로 저장하고 Google Cloud Storage에 저장합니다. 우리는 또한 각 단어를 숫자로 색인하고 피클로 어휘 사전을 구축합니다. 이 피클 파일은 저장 파일에도 저장됩니다. 이 파일이 설치되면 여기에 액세스 할 수 있으며 아래 단계를 따라 배포를 수행 할 수 있습니다.
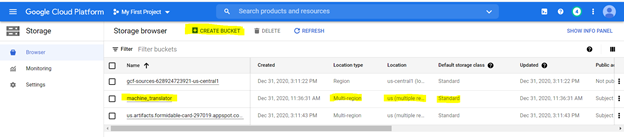
스토리지 버킷에 파일을 업로드합니다. 다음 사양으로 강조 표시된 다음 옵션을 사용하여 버킷을 작성하려면
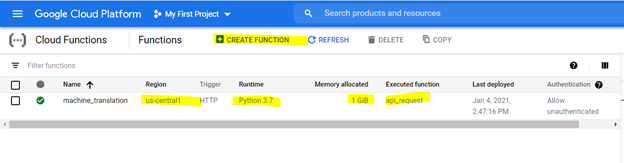
클라우드 기능을 만들려면 GCP 플랫폼에서 IT를 찾아보고 아래로 강조 표시된 옵션을 사용하여 기능을 만듭니다.
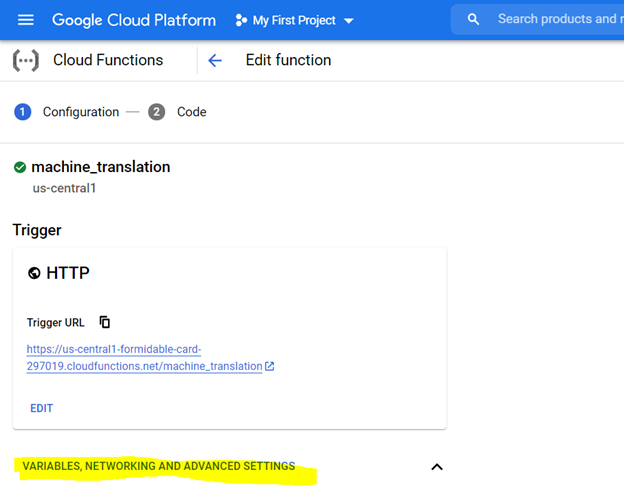
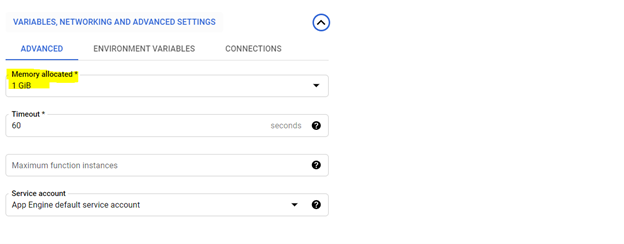
*1 개의 gib 메모리 할당이 권장됩니다. 설정되면 '다음'을 클릭하고 클라우드 기능 콘솔에 코드를 배포하십시오.
코드를 배포하려면 먼저 아래 강조 표시된 설정으로 콘솔을 구성하고 요구 사항 파일을 사용하여 환경을 준비하십시오 (이는 아래에 설명 된대로 PIP install {Library}와 동일).
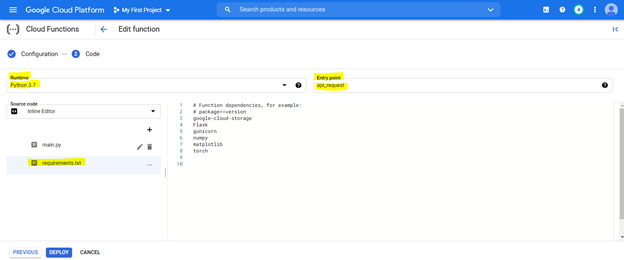
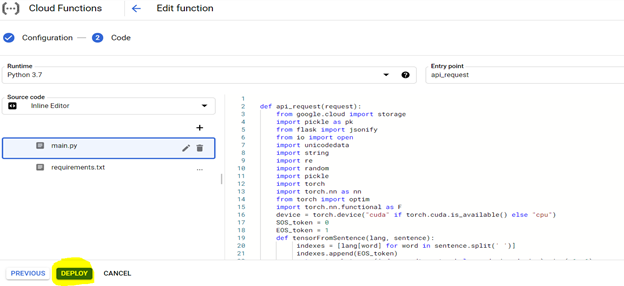

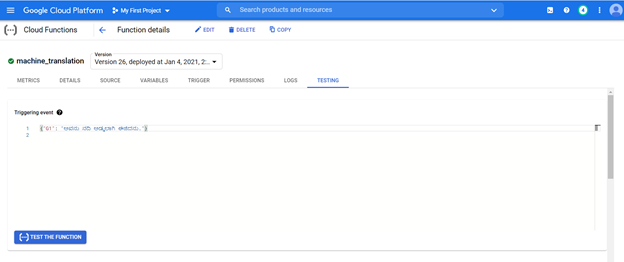

배포 된 모델은 모든 시스템의 URL에서 액세스하여 Kannada 문장을 영어로 변환 할 수 있습니다.


