GroundingDINO
Grounding DINO SwinB

Idea-CVR, Idea-Research
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang ? .
[ Paper ] [ Demo ] [ BibTex ]
Dino 접지를위한 Pytorch 구현 및 사전 치료 모델. 자세한 내용은 오픈 세트 객체 감지를위한 접지 사전 훈련과 함께 종이 접지 Dino : Dino와 결혼하십시오 .
2023/07/18 : 우리는 세그먼트를 활성화하고 원하는 세분화에서 무엇이든 인식하기 위해 보편적 인 이미지 세분화 모델 인 Semantic-Sam을 출시합니다. 코드 와 체크 포인트를 사용할 수 있습니다!2023/06/17 : 우리는 Coco Zero-Shot 성능에 대한 접지 디노를 평가하는 예를 제공합니다.2023/04/15 : 오픈 세트 인정에 관심이있는 사람들을위한 야생 판독 값의 CV를 참조하십시오!2023/04/08 : 우리는 더 통제 가능한 이미지 편집을 위해 접지 디노와 접지 디노를 결합하기위한 데모를 릴리스합니다.2023/04/08 : 이미지 편집을위한 안정적인 확산과 접지 디노를 결합하기 위해 데모를 릴리스합니다.2023/04/06 : 우리는 Grounded-segment-antho라는 이름의 세그먼트-모든 것을 Groundingdino에서 세분화하는 것을 목표로하는 Groundingdino와 결혼하여 새로운 데모를 구축합니다.2023/03/28 : 디노 접지 및 기본 객체 감지 프롬프트 엔지니어링에 관한 YouTube 비디오. [Skalskip]2023/03/28 : 포옹 페이스 스페이스에 데모를 추가하십시오!2023/03/27 : CPU 전용 모드를 지원합니다. 이제 모델은 GPU없이 기계에서 실행할 수 있습니다.2023/03/25 : Dino를 접지하기위한 데모는 Colab에서 제공됩니다. [Skalskip]2023/03/22 : 코드가 지금 사용할 수 있습니다! 지상 디노와 유리와 결혼
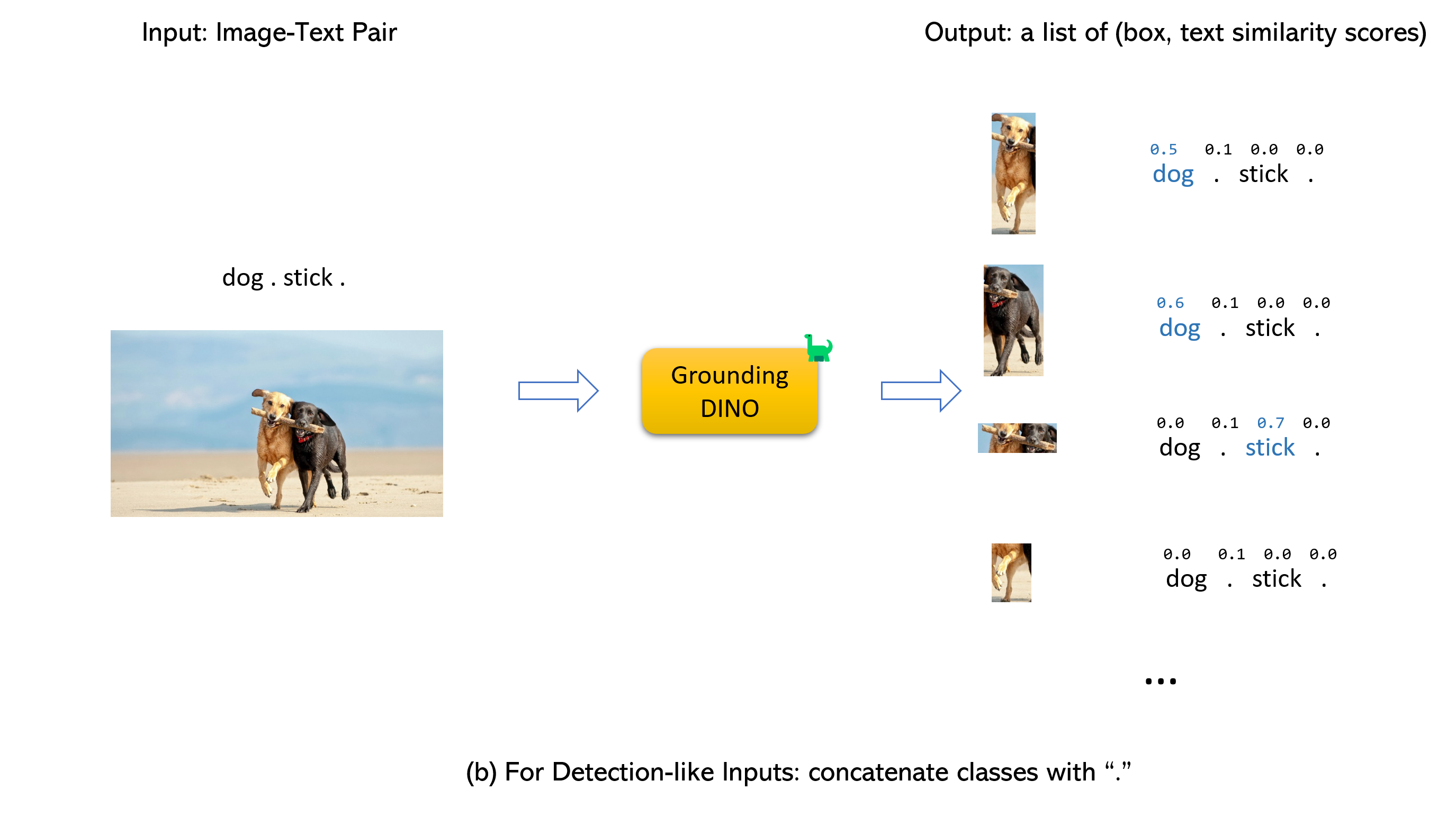
지상 디노와 유리와 결혼 (image, text) 쌍을 입력으로 받아들입니다.900 (기본적으로) 객체 상자를 출력합니다. 각 상자에는 모든 입력 단어에서 유사성 점수가 있습니다. (아래 그림과 같이.)box_threshold 보다 높은 상자를 기본적으로 선택합니다.text_threshold 보다 유사성이 높은 단어를 추출합니다.two dogs with a stick. dogs 같은 특정 문구의 대상을 얻으려면. , 최종 출력으로 dogs 가장 높은 텍스트 유사성을 가진 상자를 선택할 수 있습니다.. 디노 접지. 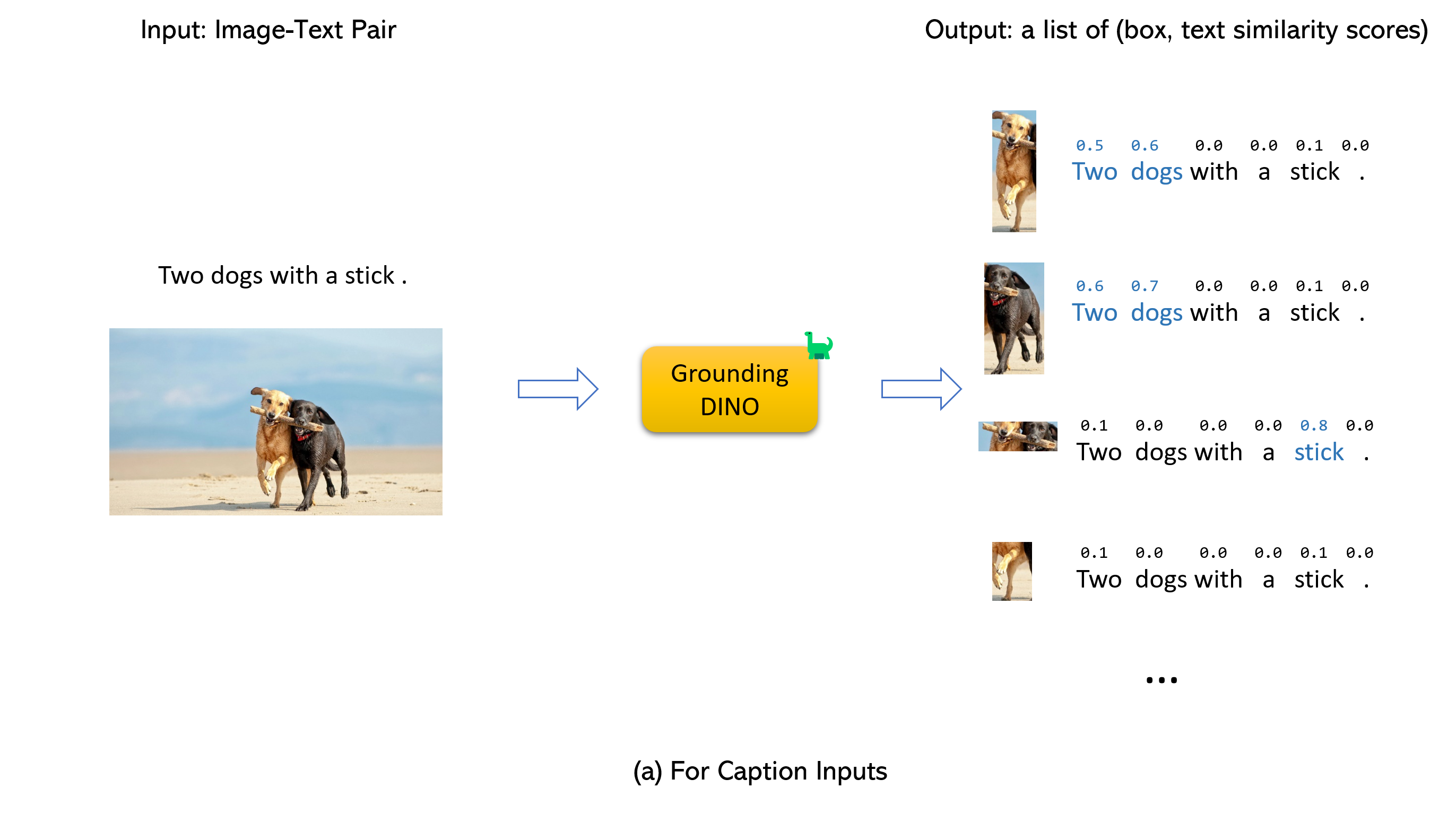
메모:
CUDA_HOME 설정되어 있는지 확인하십시오. CUDA를 사용할 수없는 경우 CPU 전용 모드에서 컴파일됩니다.설치 단계를 엄격하게 다음과 같이하십시오. 그렇지 않으면 프로그램이 생성 할 수 있습니다.
NameError: name ' _C ' is not defined이런 일이 발생하면 GIT를 Reclone으로지면 디노를 다시 설치하고 모든 설치 단계를 다시 수행하십시오.
echo $CUDA_HOME아무것도 인쇄하지 않으면 경로를 설정하지 않았 음을 의미합니다.
환경 변수가 현재 쉘에서 설정되도록 이것을 실행하십시오.
export CUDA_HOME=/path/to/cuda-11.3CUDA 버전은 CUDA 런타임과 일치해야합니다. 동시에 여러 CUDA가 존재할 수 있기 때문입니다.
Cuda_home을 영구적으로 설정하려면 다음을 사용하여 저장하십시오.
echo ' export CUDA_HOME=/path/to/cuda ' >> ~ /.bashrc그런 다음 bashrc 파일을 소스하고 cuda_home을 확인하십시오.
source ~ /.bashrc
echo $CUDA_HOME이 예에서/path/to/cuda-11.3은 CUDA 툴킷이 설치된 경로로 교체해야합니다. 터미널에서 어떤 NVCC를 입력하여이를 찾을 수 있습니다.
예를 들어, 출력이/usr/local/cuda/bin/nvcc 인 경우 :
export CUDA_HOME=/usr/local/cuda설치:
1. Github의 GatterningDino 저장소를 클론.
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO/pip install -e .mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..GPU ID를 확인하십시오 (GPU를 사용하는 경우에만)
nvidia-smi {GPU ID} , image_you_want_to_detect.jpg 를 바꾸고 다음 명령의 "dir you want to save the output" 대체하십시오.
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
-i image_you_want_to_detect.jpg
-o " dir you want to save the output "
-t " chair "
[--cpu-only] # open it for cpu mode감지 할 문구를 지정하려면 여기 데모가 있습니다.
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p ./groundingdino_swint_ogc.pth
-i .asset/cat_dog.jpeg
-o logs/1111
-t " There is a cat and a dog in the image . "
--token_spans " [[[9, 10], [11, 14]], [[19, 20], [21, 24]]] "
[--cpu-only] # open it for cpu mode Token_spans는 문구의 시작 및 끝 위치를 지정합니다. 예를 들어, 첫 번째 문구는 [[9, 10], [11, 14]] 입니다. "There is a cat and a dog in the image ."[9:10] = 'a' , "There is a cat and a dog in the image ."[11:14] = 'cat' . 따라서 그것은 a cat 문구를 말합니다. 마찬가지로, [[19, 20], [21, 24]] 는 a dog 문구를 말합니다.
자세한 내용은 demo/inference_on_a_image.py 참조하십시오.
파이썬으로 실행 :
from groundingdino . util . inference import load_model , load_image , predict , annotate
import cv2
model = load_model ( "groundingdino/config/GroundingDINO_SwinT_OGC.py" , "weights/groundingdino_swint_ogc.pth" )
IMAGE_PATH = "weights/dog-3.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source , image = load_image ( IMAGE_PATH )
boxes , logits , phrases = predict (
model = model ,
image = image ,
caption = TEXT_PROMPT ,
box_threshold = BOX_TRESHOLD ,
text_threshold = TEXT_TRESHOLD
)
annotated_frame = annotate ( image_source = image_source , boxes = boxes , logits = logits , phrases = phrases )
cv2 . imwrite ( "annotated_image.jpg" , annotated_frame )웹 UI
우리는 또한 Grounding Dino를 Gradio Web UI와 통합하기위한 데모 코드를 제공합니다. 자세한 내용은 파일 demo/gradio_app.py 참조하십시오.
노트북
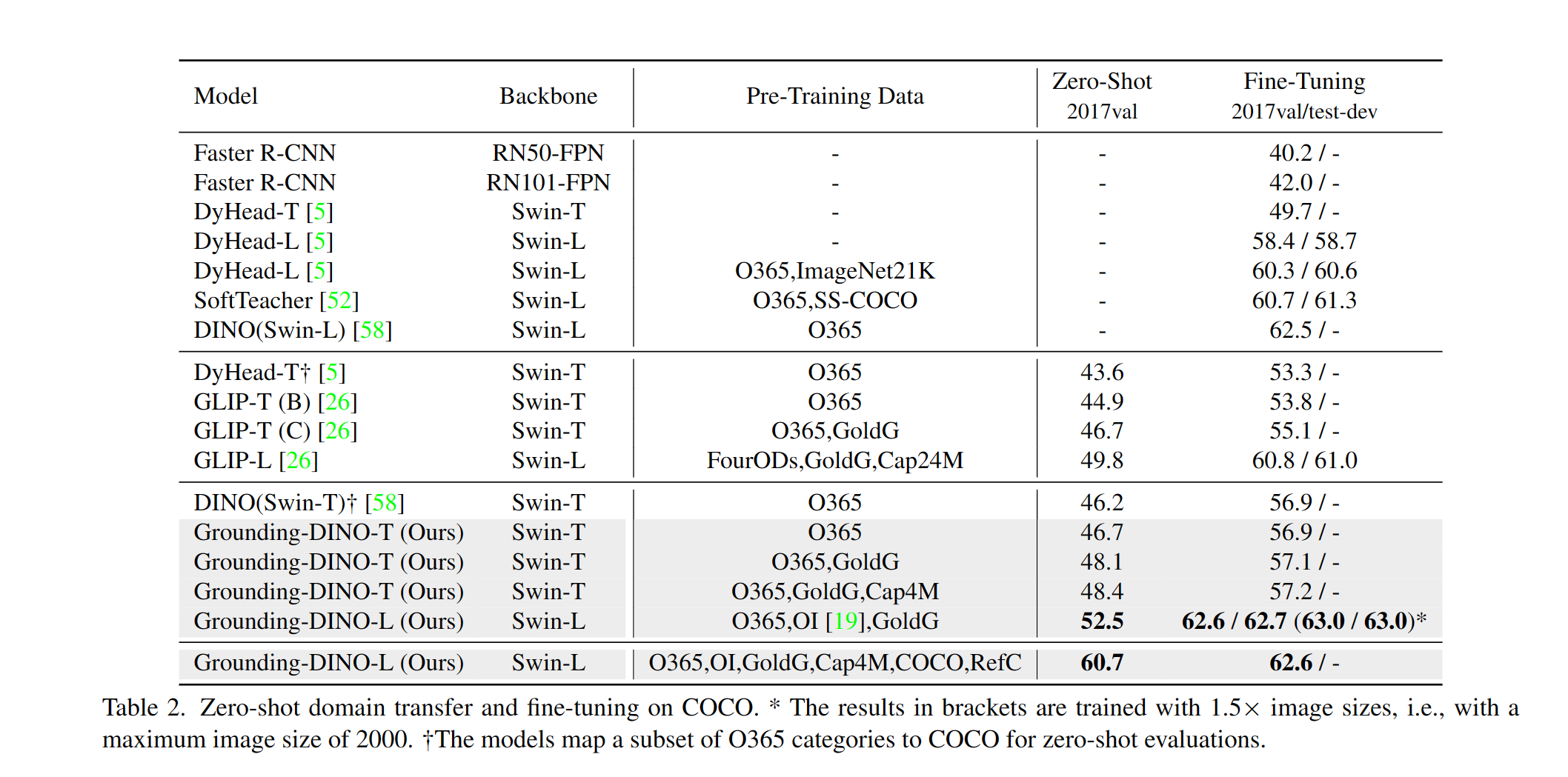
우리는 코코의 접지 디노 제로 샷 성능을 평가하는 예를 제공합니다. 결과는 48.5 여야합니다.
CUDA_VISIBLE_DEVICES=0
python demo/test_ap_on_coco.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
--anno_path /path/to/annoataions/ie/instances_val2017.json
--image_dir /path/to/imagedir/ie/val2017| 이름 | 등뼈 | 데이터 | 코코의 상자 AP | 검문소 | 구성 | |
|---|---|---|---|---|---|---|
| 1 | Groundingdino-t | SWIN-T | O365, Goldg, CAP4M | 48.4 (제로 샷) / 57.2 (미세 조정) | github 링크 | HF 링크 | 링크 |
| 2 | Groundingdino-B | SWIN-B | Coco, O365, Goldg, Cap4M, OpenImage, Odinw-35, Refcoco | 56.7 | github 링크 | HF 링크 | 링크 |

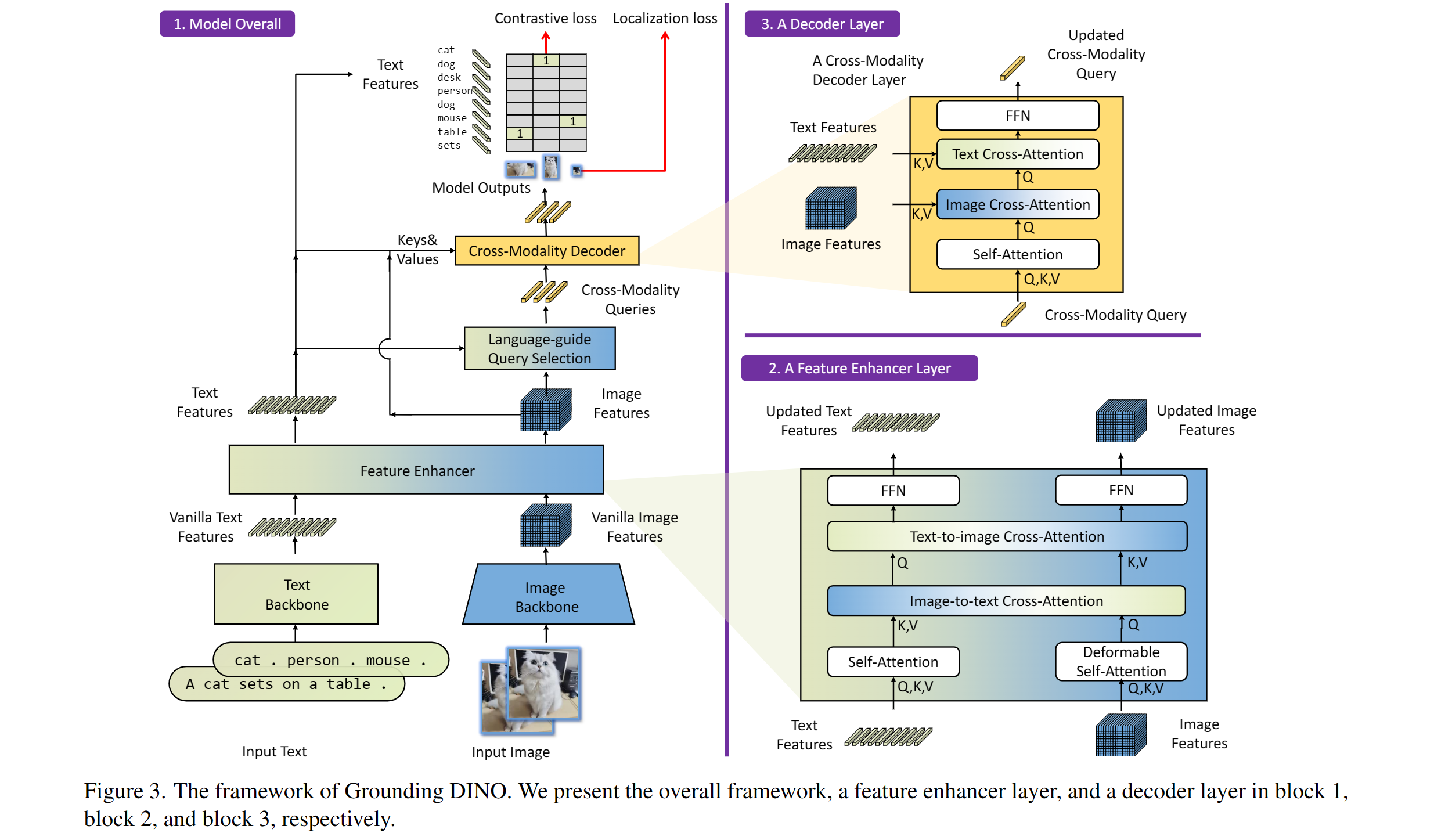
포함 : 텍스트 백본, 이미지 백본, 기능 강화기, 언어 가이드 쿼리 선택 및 교차 모임 디코더.
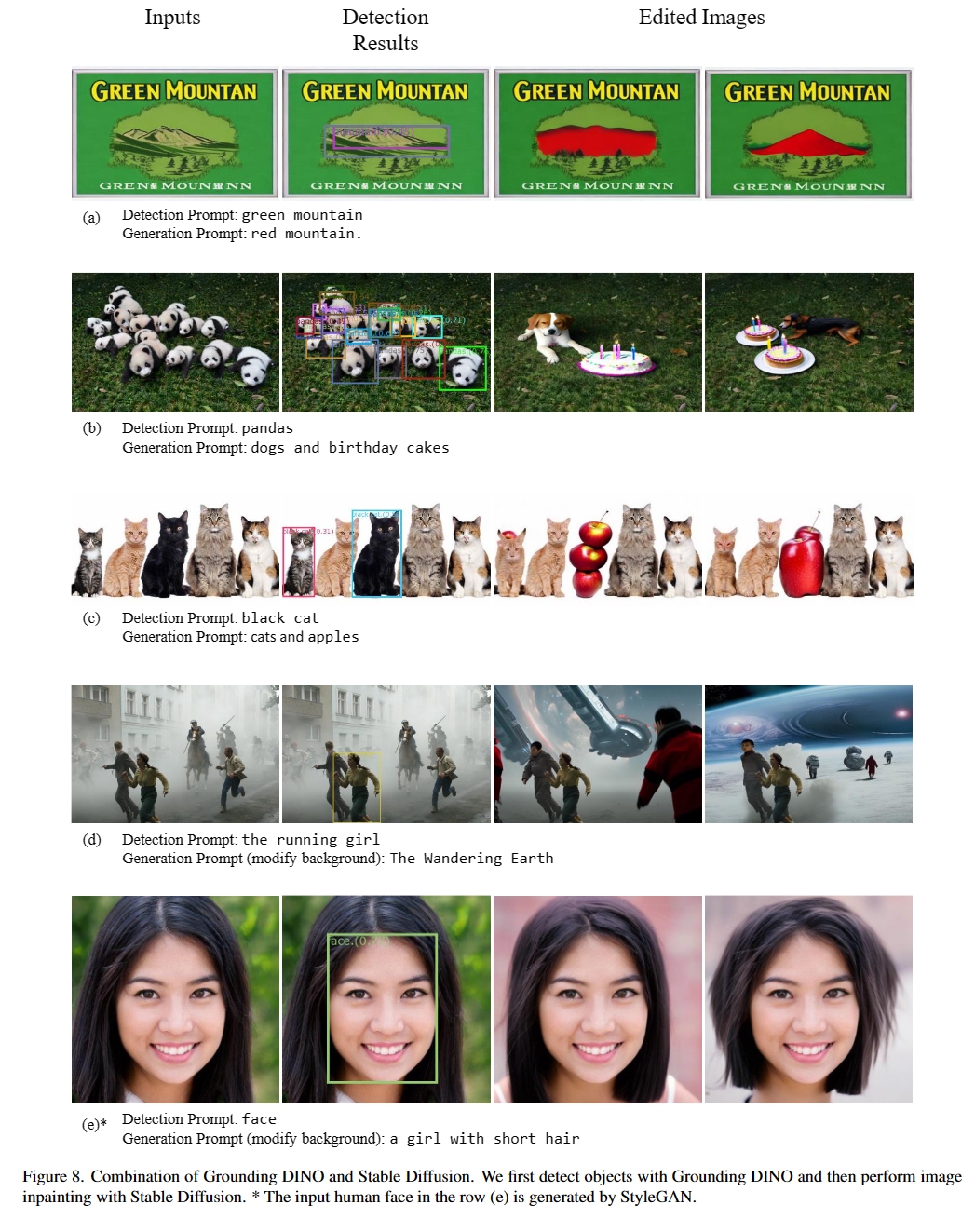
우리의 모델은 Dino 및 Glip과 관련이 있습니다. 그들의 위대한 일에 감사드립니다!
또한 DETR, 변형 가능한 DETR, SMCA, 조건부 DETR, Anchor DETR, Dynamic DETR, DAB-DETR, DN-DET 등을 포함한 훌륭한 이전 작업에 감사드립니다. Awesome Detection Transformer에서 더 많은 관련 작업을 사용할 수 있습니다. 새로운 도구 상자 Detrex도 사용할 수 있습니다.
멋진 모델에 대한 안정적인 확산과 유리에 감사드립니다.
우리의 연구가 귀하의 연구에 도움이되면 다음 Bibtex 항목을 인용하는 것을 고려하십시오.
@article { liu2023grounding ,
title = { Grounding dino: Marrying dino with grounded pre-training for open-set object detection } ,
author = { Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others } ,
journal = { arXiv preprint arXiv:2303.05499 } ,
year = { 2023 }
}

