
그래프에 대한 크로스 도메인 크로스 작업 파운데이션 모델 인 GFT의 공식 구현. 로고는 dall · e 3에 의해 생성됩니다.
Zehong Wang, Zheyuan Zhang, Nitesh v Chawla, Chuxu Zhang 및 Yanfang Ye에 의해 저술되었습니다.
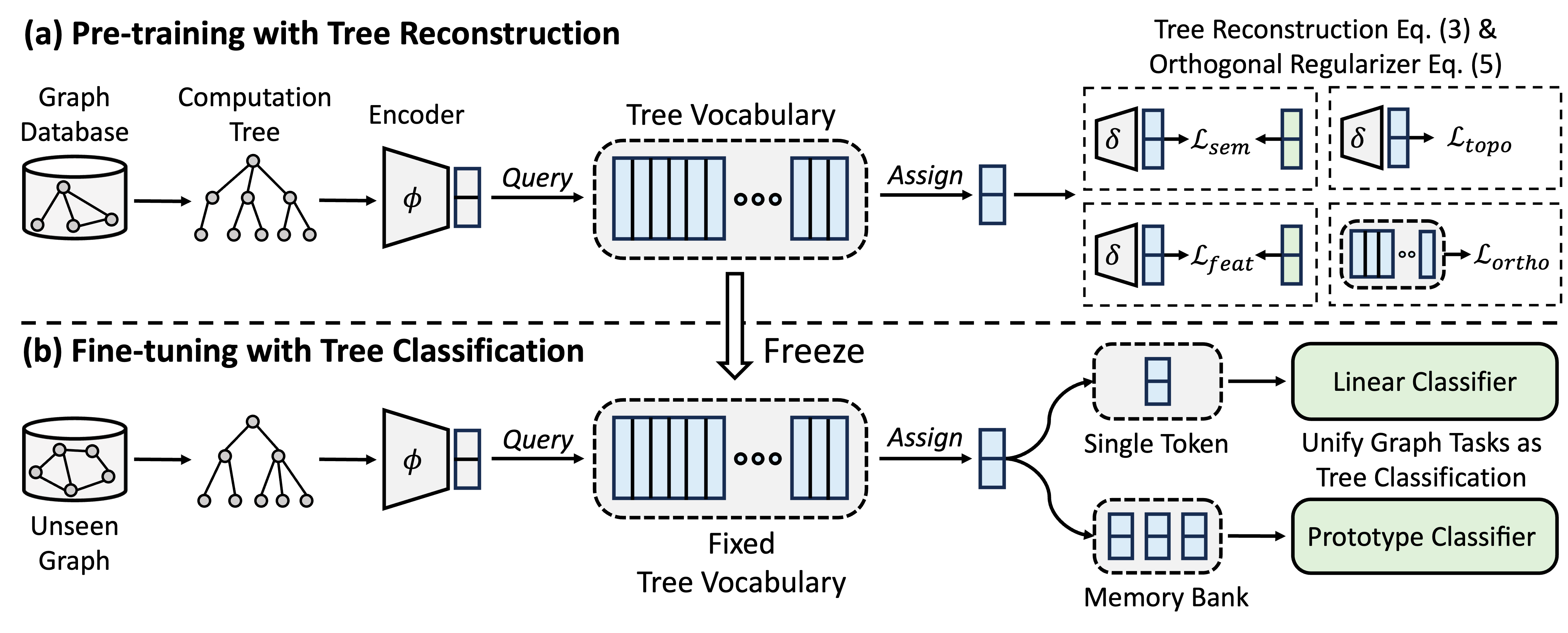
GFT는 크로스 도메인 및 크로스 작업 그래프 파운데이션 모델로, 전송 가능한 트리 어휘를 얻기 위해 계산 트리를 전송 가능한 패턴으로 취급합니다. 또한 GFT는 그래프 관련 작업을 정렬하여 단일 그래프 모델 (예 : GNN)이 노드 레벨, 에지 수준 및 그래프 레벨 작업을 수행 할 수 있도록 통합 된 프레임 워크를 제공합니다.
사전 훈련 중에 모델은 트리 재건 작업을 통해 그래프 데이터베이스에서 트리 어휘로 일반 지식을 인코딩합니다. 미세 조정에서, 배운 트리 어휘는 트리 분류 작업으로 그래프 관련 작업을 통합하여 획득 한 일반 지식을 특정 작업에 적응시키는 데 적용됩니다.
Conda를 사용하여 환경을 설치할 수 있습니다. 다음 스크립트를 실행하십시오. 우리는 단일 A40 48G GPU에서 모든 실험을 실행하지만 24g 메모리가있는 GPU는 미니 배치로 모든 데이터 세트를 처리하기에 충분합니다.
conda env create -f environment.yml
conda activate GFT
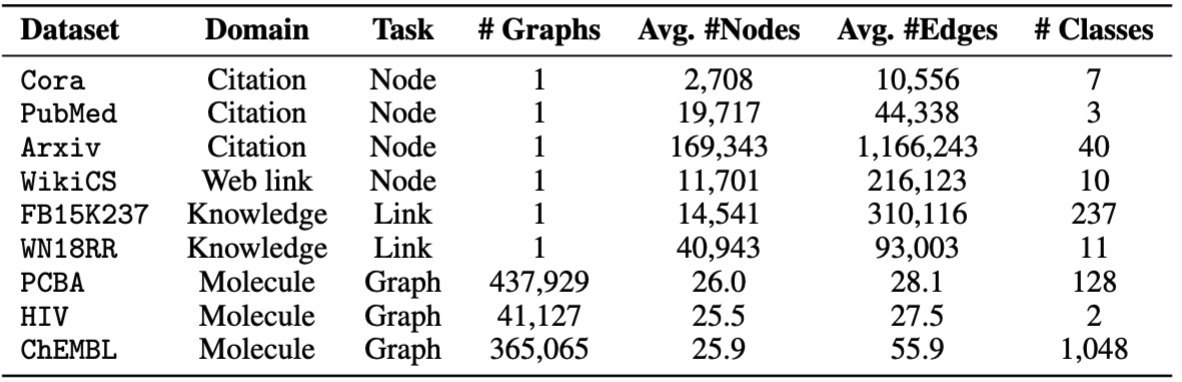
OFA에서 제공 한 데이터 세트를 사용합니다. pretrain.py 를 실행하여 데이터 세트를 자동으로 다운로드 할 수 있으며,이 데이터 세트는 기본적으로 /data 폴더로 다운로드됩니다. 파이프 라인은 텍스트 설명을 텍스트 임베딩으로 변환하여 데이터 세트를 자동으로 전처리합니다.
또는 /data 폴더에서 전처리 된 데이터 세트를 다운로드하고 압축을 풀 수 있습니다.
GFT 코드는 폴더 /GFT 로 표시됩니다. 구조는 다음과 같습니다.
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
광범위한 그래프에서 프리 트레인을 위해 pretrain.py 실행하고 기본적인 결합 또는 소수의 학습을 통해 특정 다운 스트림 작업에 적응하기 위해 finetune.py 실행할 수 있습니다.
결과를 재현하기 위해, 우리는 config/pretrain.yaml 및 config/finetune.yaml 에서 각각 유지되는 전 사전 조정 및 양조에 대한 상세한 하이퍼 파라미터를 제공합니다. 기본 하이퍼 파라미터를 활용하기 위해 Pretrain과 Finetune 모두에 대한 명령 --use_params 제공합니다.
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
Finetuning을 위해 cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv 및 chempcba 포함한 8 개의 데이터 세트를 제공합니다.
또는 스크립트를 실행하여 실험을 재현 할 수 있습니다.
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
참고 : 사전 예방 모델은 기본적으로 ckpts/pretrain_model/ 에 저장됩니다.
# The basic command for pretraining GFT
python GFT/pretrain.py
pretrain.py 실행하면 사전 여지가있는 데이터 세트와 하이퍼 패러 메이트를 사용자 정의 할 수 있습니다.
--pretrain_dataset (또는 --pt_data )을 사용하여 중고 프리 트레인 데이터 세트와 해당 가중치를 설정할 수 있습니다. 사전 정의 된 데이터 구성은 다음 구조와 함께 config/pt_data.yaml 에 있습니다.
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
위의 경우, all 는 설정의 이름이며, 즉 모든 데이터 세트가 사전 조정에 사용됩니다. 각 데이터 세트마다 키 값 쌍이 있으며, 여기서 키는 데이터 세트 이름이고 값은 샘플링 중량입니다. 예를 들어, cora: 5 cora 데이터 세트가 단일 에포크에서 5 회 샘플링된다는 것을 의미합니다. 프리 트레인 GFT를 위해 자신의 데이터 세트 조합을 설계 할 수 있습니다.
인코더, 벡터 양자화, 모델 훈련의 하이퍼-파라미터를 변경하여 사전 여지 위상을 사용자 정의 할 수 있습니다.
--pretrain_dataset : 사전 계통 데이터 세트를 나타냅니다. 위와 동일합니다.--use_params : 사전 정의 된 하이퍼 파라미터를 사용하십시오.--seed : 사전 여지에 사용되는 씨앗.--hidden_dim : GNN의 숨겨진 층의 치수.--num_layers : GNN 층.--activation : 활성화 기능.--backbone : 백본 Gnn.--normalize : 정규화 층.--dropout : GNN 층의 드롭 아웃.--code_dim : 어휘에서 각 코드의 차원.--codebook_size : 어휘의 코드 수.--codebook_head : 코드북 헤드 수. 숫자가 1보다 크면 여러 어휘를 공동으로 사용하게됩니다.--codebook_decay : 코드의 붕괴 속도.--commit_weight : 약정 용어의 무게.--pretrain_epochs : 에포크의 수.--pretrain_lr : 학습 속도.--pretrain_weight_decay : L2 정규화의 무게.--pretrain_batch_size : 배치 크기.--feat_p : 기능 손상 속도.--edge_p : 가장자리/구조 손상 속도.--topo_recon_ratio : 가장자리의 비율을 재구성해야합니다.--feat_lambda : 기능 손실의 무게.--topo_lambda : 토폴로지 손실의 무게.--topo_sem_lambda : 재구성 가장자리에서 토폴로지 손실의 가중치.--sem_lambda : 시맨틱 손실의 무게.--sem_encoder_decay : 시맨틱 인코더의 모멘텀 업데이트 속도. # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
다운 스트림 데이터 세트를 표시하도록 --dataset 설정하고 --use_params 표시 할 수 있습니다. 당신이 표시 할 수있는 다른 과하계는 다음과 같이 표시됩니다.
사전 정의 된 분할 1 개가있는 그래프의 경우 --repeat 설정하여 여러 실험을 수행 할 수 있습니다.
--hidden_dim : GNN의 숨겨진 층의 치수.--num_layers : GNN 층.--activation : 활성화 기능.--backbone : 백본 Gnn.--normalize : 정규화 층.--dropout : GNN 층의 드롭 아웃.--code_dim : 어휘에서 각 코드의 차원.--codebook_size : 어휘의 코드 수.--codebook_head : 코드북 헤드 수. 숫자가 1보다 크면 여러 어휘를 공동으로 사용하게됩니다.--codebook_decay : 코드의 붕괴 속도.--commit_weight : 약정 용어의 무게.--finetune_epochs : 에포크 수.--finetune_lr : 학습 속도.--early_stop : 최대 초기 정지 에포크.--batch_size : 0으로 설정된 경우 전체 그래프 교육을 수행하십시오. --lambda_proto : Finetuning에서 프로토 타입 분류기의 가중치.
--lambda_act : 양조에서 선형 분류기의 가중치.
--trade_off : 프로토 타입 클래를 사용하거나 선형 분류기 사용 간의 트레이드 오프.
각각 선형 분류기 또는 프로토 타입 분류기를 사용하지 않기 위해 --no_lin_clf 또는 --no_proto_clf 추가 할 수 있습니다. 이 두 용어는 하나 이상의 분류기를 사용해야하므로 충돌입니다.
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
다운 스트림 데이터 세트를 표시하도록 --dataset 설정하고 --use_params 표시 할 수 있습니다. 당신이 표시 할 수있는 다른 과하계는 다음과 같이 표시됩니다.
소수의 학습을 위해 전용 된 하이퍼 파라미터는 다음과 같습니다
--n_train : 모델을 미세 조정하기위한 수업 당 교육 인스턴스 수. 작은 n_train 바람직한 성능을 달성합니다 --n_task : 샘플링 된 작업 수.--n_way : 방법의 수.--n_query : 쿼리 세트의 크기.--n_shot : 방법 당 지원 세트의 크기.--hidden_dim : GNN의 숨겨진 층의 치수.--num_layers : GNN 층.--activation : 활성화 기능.--backbone : 백본 Gnn.--normalize : 정규화 층.--dropout : GNN 층의 드롭 아웃.--code_dim : 어휘에서 각 코드의 차원.--codebook_size : 어휘의 코드 수.--codebook_head : 코드북 헤드 수. 숫자가 1보다 크면 여러 어휘를 공동으로 사용하게됩니다.--codebook_decay : 코드의 붕괴 속도.--commit_weight : 약정 용어의 무게.--finetune_epochs : 에포크 수.--finetune_lr : 학습 속도.--early_stop : 최대 초기 정지 에포크.--batch_size : 0으로 설정된 경우 전체 그래프 교육을 수행하십시오. --lambda_proto : Finetuning에서 프로토 타입 분류기의 가중치.
--lambda_act : 양조에서 선형 분류기의 가중치.
--trade_off : 프로토 타입 클래를 사용하거나 선형 분류기 사용 간의 트레이드 오프.
각각 선형 분류기 또는 프로토 타입 분류기를 사용하지 않기 위해 --no_lin_clf 또는 --no_proto_clf 추가 할 수 있습니다. 이 두 용어는 하나 이상의 분류기를 사용해야하므로 충돌입니다.
실험 결과는 전 사전 조정 중 무작위 초기화로 인해 달라질 수 있습니다. 우리는 임의의 초기화의 잠재적 영향을 보여주기 위해 사전 조정에서 다른 임의의 씨앗 (즉, 1-5)을 사용하여 실험 결과를 제공합니다.
| 코라 | PubMed | 위키 -CS | arxiv | wn18rr | FB15K237 | HIV | PCBA | 평균 | |
|---|---|---|---|---|---|---|---|---|---|
| 종자 = 1 | 78.58 ± 0.90 | 77.55 ± 1.54 | 79.38 ± 0.57 | 72.24 ± 0.16 | 91.56 ± 0.33 | 89.67 ± 0.35 | 72.69 ± 1.93 | 78.24 ± 0.23 | 79.99 |
| 종자 = 2 | 78.27 ± 1.26 | 76.41 ± 1.36 | 79.36 ± 0.62 | 72.13 ± 0.24 | 91.72 ± 0.19 | 89.66 ± 0.31 | 71.62 ± 2.45 | 78.20 ± 0.33 | 79.67 |
| 종자 = 3 | 78.16 ± 1.62 | 76.28 ± 1.37 | 79.32 ± 0.65 | 72.13 ± 0.30 | 91.57 ± 0.44 | 89.78 ± 0.23 | 71.58 ± 2.28 | 78.12 ± 0.37 | 79.62 |
| 종자 = 4 | 78.42 ± 1.37 | 75.76 ± 1.58 | 79.44 ± 0.62 | 72.36 ± 0.34 | 91.70 ± 0.24 | 89.73 ± 0.21 | 72.57 ± 2.46 | 78.34 ± 0.27 | 79.79 |
| 종자 = 5 | 78.56 ± 1.62 | 76.49 ± 2.00 | 79.27 ± 0.55 | 72.18 ± 0.26 | 91.47 ± 0.39 | 89.80 ± 0.19 | 72.27 ± 0.93 | 78.31 ± 0.34 | 79.79 |
| 보고 된 | 78.62 ± 1.21 | 77.19 ± 1.99 | 79.39 ± 0.42 | 71.93 ± 0.12 | 91.91 ± 0.34 | 89.72 ± 0.20 | 72.67 ± 1.38 | 77.90 ± 0.64 | 79.92 |
재현성을 더 잘 보장하기 위해이 링크에서 Seed = 1 의 검문소를 제공합니다. 우리는 최고의 평균 성능으로 인해 이것을 선택합니다. ckpts/pretrain_model/ Path에서 다운로드 된 파일을 압축하고 finetune.py 사용하여 제공된 체크 포인트를 섬세하게 활용할 때 --pt_seed 1 설정할 수 있습니다.
궁금한 점이 있으면 [email protected] 에 문의하거나 문제를여십시오.
리포가 연구에 유용하다는 것을 알게되면 원본 용지를 올바르게 인용하십시오.
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}이 저장소는 OFA, Pyg, OGB 및 VQ의 코드베이스를 기반으로합니다. 공유해 주셔서 감사합니다!


