vision_transformer
1.0.0
이 저장소에서 우리는 논문에서 모델을 공개합니다
모델은 ImageNet 및 Imagenet-21K 데이터 세트에서 미리 훈련되었습니다. 우리는 Jax/Flax에서 릴리스 된 모델을 미세 조정하기위한 코드를 제공합니다.
이 코드베이스의 모델은 원래 https://github.com/google-research/big_vision/에서 훈련을 받았으며, 여기서 더 많은 고급 코드 (예 : 멀티 호스트 교육) 및 원래 교육 스크립트 (EG 구성)를 찾을 수 있습니다. /vit_i21k.py Vit 또는 configs/transfer.py를 미리 훈련하기위한 모델 전송).
목차 :
아래에서 Colabs는 GPU 및 TPU (8 코어, 데이터 병렬 처리)와 함께 실행됩니다.
첫 번째 Colab은 JAX Code of Vision Transformers 및 MLP 믹서를 보여줍니다. 이 Colab을 사용하면 Colab UI의 저장소에서 파일을 직접 편집 할 수 있으며 코드를 단계별로 안내하는 Colab 셀에 주석을 달고 데이터와 상호 작용할 수 있습니다.
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
두 번째 Colab을 사용하면 세 번째 논문 "Vit? ... ..."의 데이터를 생성하는 데 사용 된> 50k 비전 변압기 및 하이브리드 체크 포인트를 탐색 할 수 있습니다. COLAB에는 검문소를 탐색하고 선택하는 코드가 포함되어 있으며,이 Repo의 JAX 코드를 사용하여 추론하고 이러한 체크 포인트를 직접로드 할 수있는 인기있는 timm PYTORCH 라이브러리를 사용합니다. 소수의 모델은 TF-Hub : Sayakpaul/Collections/Vision_transformer (Sayak Paul의 외부 기여)에서 직접 제공됩니다.
두 번째 Colab을 사용하면 개별 JPEG 파일의 예제 (선택적으로 Google Drive에서 직접 읽음)와 함께 TFDS 데이터 세트 및 자체 데이터 세트의 검문소를 미세 조정할 수 있습니다.
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax_augreg.ipynb
참고 : 현재 (6/20/21) Google Colab은 단일 GPU (NVIDIA TESLA T4) 만 지원하고 TPU (현재 TPUV2-8)는 Colab VM에 간접적으로 첨부되어 느린 네트워크를 통해 통신합니다. 나쁜 훈련 속도. 사소한 양의 데이터가 미세 조정할 수있는 경우 일반적으로 전용 머신을 설정하려고합니다. 자세한 내용은 클라우드에서 실행을 참조하십시오.
컴퓨터에 Python>=3.10 설치되어 있는지 확인하십시오.
실행을 통해 JAX 및 Python Dependencies를 설치하십시오.
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
최신 버전의 JAX의 경우 여기에 연결된 해당 저장소에 제공된 지침을 따르십시오. CPU, GPU 및 TPU의 설치 지침은 약간 다릅니다.
flaxformer를 설치하고 여기에 연결된 해당 저장소에 제공된 지침을 따르십시오.
자세한 내용은 아래 클라우드에서 실행되는 섹션을 참조하십시오.
관심있는 데이터 세트에서 다운로드 된 모델의 미세 조정을 실행할 수 있습니다. 모든 모델은 동일한 명령 줄 인터페이스를 공유합니다.
예를 들어 CIFAR10에서 VIT-B/16 (Imagenet21K에서 미리 훈련)을 미세 조정하기 위해 ( b16,cifar10 구성의 인수로 지정하는 방법 및 코드에 GCS 버킷에서 모델에 직접 액세스하도록 지시하는 방법 먼저 로컬 디렉토리로 다운로드하는 대신) :
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'CIFAR10에서 Mixer-B/16 (imagenet21k에서 미리 훈련)을 미세 조정하기 위해 :
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' "vit를 훈련시키는 방법? ..."종이에 configs/augreg.py config로 미세 조정할 수있는> 50k 체크 포인트가 추가되었습니다. 모델 이름 ( configs/model.py 의 config.name 값) 만 지정하면 업스트림 유효성 검사 정확도 ( "권장"체크 포인트, 용지 4.5 절 참조)별로 최고의 I21K 체크 포인트가 선택됩니다. 어떤 모델을 사용하고 싶은지 마음을 구성하려면 논문의 그림 3을 살펴보십시오. 다른 체크 포인트 (Colab vit_jax_augreg.ipynb 참조)를 선택한 다음 filename 또는 adapt_filename 열에서 값을 지정할 수도 있습니다.이 값은 gs://vit_models/augreg 디렉토리에서 .npz 없는 파일 이름에 해당합니다.
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 현재 코드는 CIFAR-10 및 CIFAR-100 데이터 세트를 자동으로 다운로드합니다. 텐서 플로 데이터 세트 라이브러리를 사용하여 다른 공개 또는 사용자 정의 데이터 세트를 쉽게 통합 할 수 있습니다. 또한 추가 된 데이터 세트에 대한 일부 매개 변수를 지정하려면 vit_jax/input_pipeline.py 업데이트해야합니다.
당사 코드는 미세 조정에 사용 가능한 모든 GPU/TPU를 사용합니다.
사용 가능한 모든 플래그의 자세한 목록을 보려면 python3 -m vit_jax.train --help 실행하십시오.
메모리에 대한 메모 :
--config.accum_steps=8 의 값을 늘릴 수 있습니다. 또는 또는 --config.batch=512 를 줄일 수도 있습니다 (그리고 그에 따라 --config.base_lr 줄일 수 있습니다).--config.shuffle_buffer=50000 줄일 수 있습니다. Alexey Dosovitskiy*, Lucas Beyer*, Alexander Kolesnikov*, Dirk Weissenborn*, Xiaohua Zhai*, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, JakoS Uszkoreit 및 Neil Houlsby*†.
(*) 동등한 기술 기여, (†) 동등한 조언.
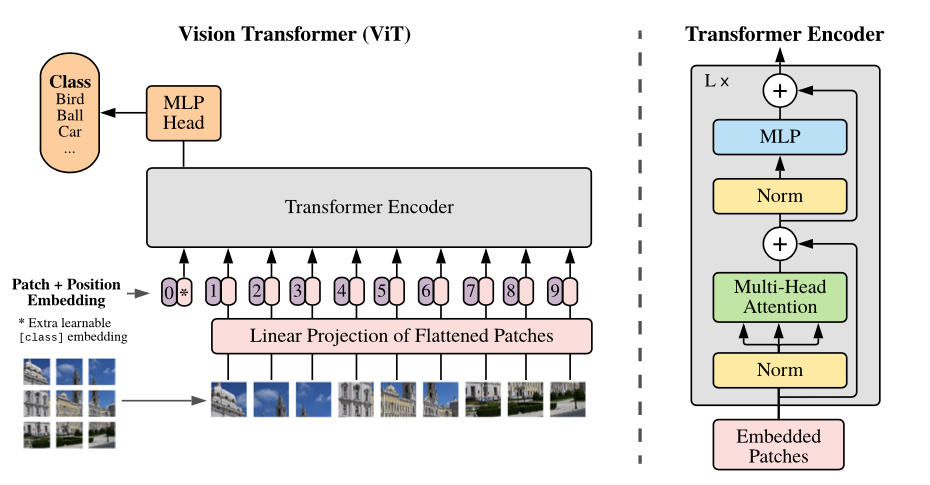
모델 개요 : 이미지를 고정 크기 패치로 나누고 각각 각각을 선형으로 포함하고 위치 임베딩을 추가하고 결과의 벡터 시퀀스를 표준 변압기 인코더에 공급합니다. 분류를 수행하기 위해 학습 가능한 "분류 토큰"을 시퀀스에 추가하는 표준 접근법을 사용합니다.
우리는 다양한 GCS 버킷에서 다양한 VIT 모델을 제공합니다. 모델은 예를 들어 다음과 같이 다운로드 할 수 있습니다.
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
모델 파일 이름 ( .npz 확장자없이)은 config.model_name in vit_jax/configs/models.py 에 해당합니다.
gs://vit_models/imagenet21k imagenet-21k에서 미리 훈련 된 모델.gs://vit_models/imagenet21k+imagenet2012 imagenet-21k에서 미리 훈련되고 imagenet에서 미세 조정 된 모델.gs://vit_models/augreg imagenet-21k에서 미리 훈련 된 모델, 다양한 양의 Augreg. 개선 된 성능.gs://vit_models/sam Sam과 Imagenet에서 미리 훈련 된 모델.gs://vit_models/gsam GSAM과 함께 Imagenet에서 미리 훈련 된 모델.최고의 사전 훈련 메트릭을 갖는 AugReg와 함께 교육을받은 다음 체크 포인트를 사용하는 것이 좋습니다.
| 모델 | 미리 훈련 된 체크 포인트 | 크기 | 미세 조정 된 체크 포인트 | 해결 | IMG/SEC | Imagenet 정확도 |
|---|---|---|---|---|---|---|
| L/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85.59% |
| B/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85.49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83.73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85.99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 MIB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83.85% |
| ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78.22% |
| B/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83.59% |
| s/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79.58% |
| r+ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 MIB | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75.40% |
원래 Vit Paper (https://arxiv.org/abs/2010.11929)의 결과는 gs://vit_models/imagenet21k 의 모델을 사용하여 복제되었습니다.
| 모델 | 데이터 세트 | 드롭 아웃 = 0.0 | 드롭 아웃 = 0.1 |
|---|---|---|---|
| R50+VIT-B_16 | cifar10 | 98.72%, 3.9h (A100), tb.dev | 98.94%, 10.1h (v100), tb.dev |
| R50+VIT-B_16 | cifar100 | 90.88%, 4.1h (A100), tb.dev | 92.30%, 10.1h (v100), tb.dev |
| R50+VIT-B_16 | imagenet2012 | 83.72%, 9.9H (A100), TB.DEV | 85.08%, 24.2h (v100), tb.dev |
| VIT-B_16 | cifar10 | 99.02%, 2.2H (a100), tb.dev | 98.76%, 7.8h (v100), tb.dev |
| VIT-B_16 | cifar100 | 92.06%, 2.2H (a100), tb.dev | 91.92%, 7.8h (v100), tb.dev |
| VIT-B_16 | imagenet2012 | 84.53%, 6.5H (A100), tb.dev | 84.12%, 19.3h (v100), tb.dev |
| VIT-B_32 | cifar10 | 98.88%, 0.8H (a100), tb.dev | 98.75%, 1.8h (v100), tb.dev |
| VIT-B_32 | cifar100 | 92.31%, 0.8H (A100), tb.dev | 92.05%, 1.8H (v100), tb.dev |
| VIT-B_32 | imagenet2012 | 81.66%, 3.3H (A100), tb.dev | 81.31%, 4.9h (v100), tb.dev |
| vit-l_16 | cifar10 | 99.13%, 6.9H (A100), TB.DEV | 99.14%, 24.7h (v100), tb.dev |
| vit-l_16 | cifar100 | 92.91%, 7.1H (A100), TB.DEV | 93.22%, 24.4h (v100), tb.dev |
| vit-l_16 | imagenet2012 | 84.47%, 16.8H (A100), TB.DEV | 85.05%, 59.7H (v100), tb.dev |
| vit-l_32 | cifar10 | 99.06%, 1.9H (A100), TB.DEV | 99.09%, 6.1h (v100), tb.dev |
| vit-l_32 | cifar100 | 93.29%, 1.9H (A100), tb.dev | 93.34%, 6.2H (v100), tb.dev |
| vit-l_32 | imagenet2012 | 81.89%, 7.5H (A100), tb.dev | 81.13%, 15.0h (v100), tb.dev |
또한 더 짧은 교육 일정으로 고품질 결과를 달성 할 수 있으며 코드 사용자가 과반수를 사용하여 정확성과 계산 예산을 상충하는 데 도움이 될 수 있음을 강조하고 싶습니다. CIFAR-10/100 데이터 세트의 일부 예는 아래 표에 나와 있습니다.
| 상류 | 모델 | 데이터 세트 | Total_steps / warmup_steps | 정확성 | 벽 클록 시간 | 링크 |
|---|---|---|---|---|---|---|
| imagenet21k | VIT-B_16 | cifar10 | 500 / 50 | 98.59% | 17m | Tensorboard.dev |
| imagenet21k | VIT-B_16 | cifar10 | 1000 / 100 | 98.86% | 39m | Tensorboard.dev |
| imagenet21k | VIT-B_16 | cifar100 | 500 / 50 | 89.17% | 17m | Tensorboard.dev |
| imagenet21k | VIT-B_16 | cifar100 | 1000 / 100 | 91.15% | 39m | Tensorboard.dev |
Ilya Tolstikhin*, Neil Houlsby*, Alexander Kolesnikov*, Lucas Beyer*, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy.
(*) 동등한 기여.
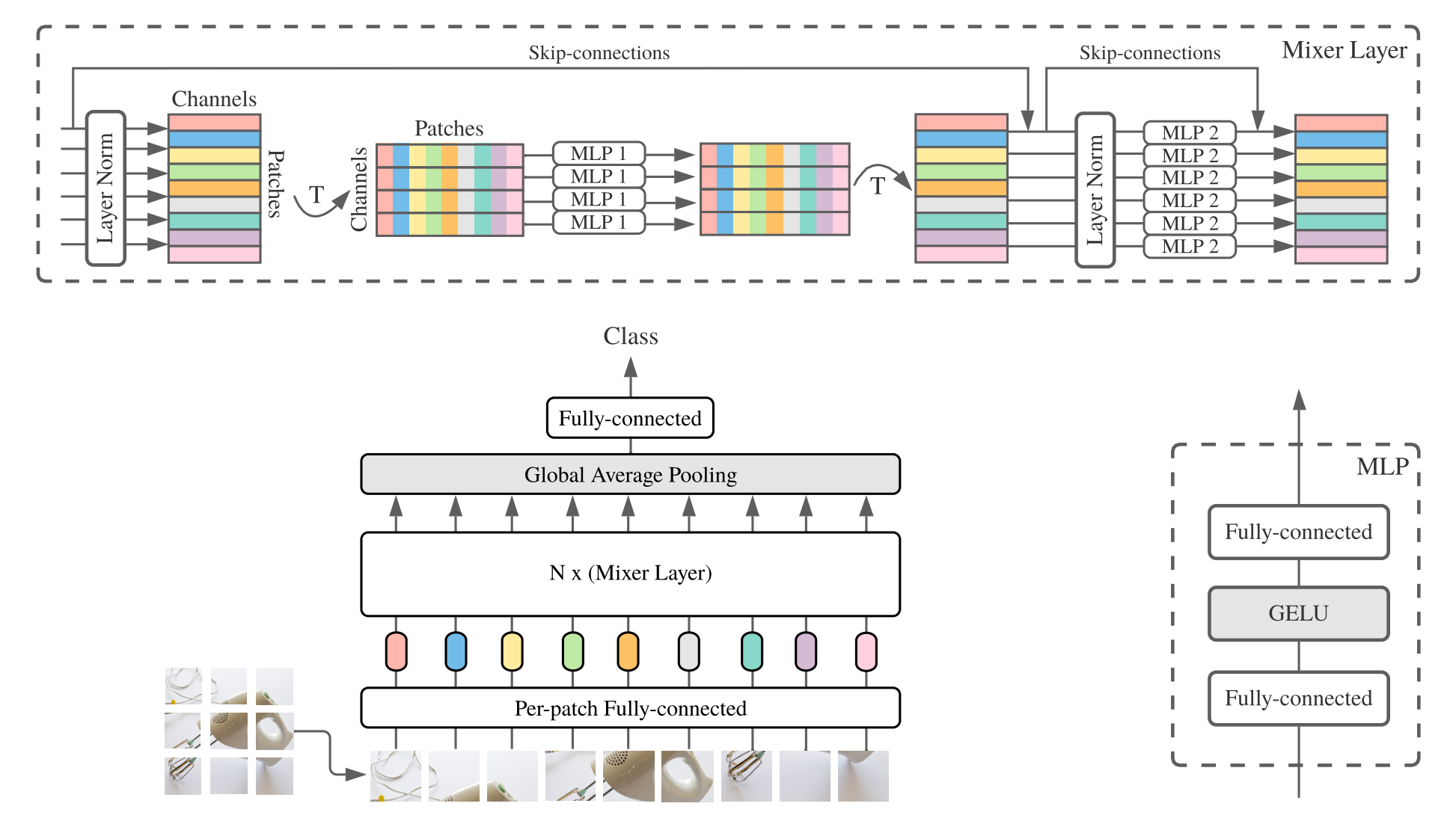
MLP 혼합기 (짧은 믹서 )는 패치 당 선형 임베딩, 믹서 층 및 분류기 헤드로 구성됩니다. 믹서 층은 하나의 토큰 혼합 MLP 및 하나의 채널 혼합 MLP를 포함하며, 각각 2 개의 완전 연결된 층과 Gelu 비선형 성으로 구성됩니다. 다른 구성 요소로는 Skip-Connections, Dropout 및 Linear Classifier 헤드가 있습니다.
설치하려면 위와 동일한 단계를 따르십시오.
우리는 ImageNet 및 ImageNet-21K 데이터 세트에서 미리 훈련 된 Mixer-B/16 및 Mixer-L/16 모델을 제공합니다. 세부 사항은 믹서 용지의 표 3에서 찾을 수 있습니다. 모든 모델은 다음에서 찾을 수 있습니다.
https://console.cloud.google.com/storage/mixer_models/
이 모델은 TF-Hub : Sayakpaul/Collections/MLP-Mixer (Sayak Paul의 외부 기여)에서 직접 사용할 수 있습니다.
이 저장소의 기본 적응 매개 변수가있는 4 개의 V100 GPU와 함께 Google Cloud Machy의 미세 조정 코드를 실행했습니다. 결과는 다음과 같습니다.
| 상류 | 모델 | 데이터 세트 | 정확성 | wall_clock_time | 링크 |
|---|---|---|---|---|---|
| imagenet | 믹서 -B/16 | cifar10 | 96.72% | 3.0h | Tensorboard.dev |
| imagenet | 믹서 -L/16 | cifar10 | 96.59% | 3.0h | Tensorboard.dev |
| imagenet-21k | 믹서 -B/16 | cifar10 | 96.82% | 9.6H | Tensorboard.dev |
| imagenet-21k | 믹서 -L/16 | cifar10 | 98.34% | 10.0H | Tensorboard.dev |
자세한 내용은 Google AI 블로그 게시물 Lit : 이미지 모델에 언어 이해 추가 또는 CVPR 용지를 읽거나 "Lit : 잠긴-이미지 텍스트 튜닝이있는 Zero-Shot 전송"(https://arxiv.org/abs/2111.07991을 읽으십시오. ).
우리는 ImageNet Zeroshot 정확도가 72.1%, ImageNet Zeroshot 정확도가 75.7%인 L/16-large 모델을 갖춘 변압기 B/16 기본 모델을 게시했습니다. 이 모델에 대한 자세한 내용은 조명 모델 카드를 참조하십시오.
대화식 사용을 위해 작은 텍스트 인코더가있는 브라우저 내 데모를 제공합니다 (가장 작은 모델은 최신 휴대 전화에서 실행해야합니다).
https://google-research.github.io/vision_transformer/lit/
그리고 마지막으로 이미지와 텍스트 인코더와 함께 JAX 모델을 사용하는 colab :
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
위의 모델 중 어느 것도 다중 언어 입력을 지원하지는 않지만 우리는 그러한 모델을 게시하기 위해 노력하고 있으며이 저장소를 사용할 수있게되면 업데이트 할 것입니다.
이 저장소에는 조명 모델에 대한 평가 코드 만 포함되어 있습니다. big_vision 저장소에서 교육 코드를 찾을 수 있습니다.
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
model_cards/lit.md 에서 예상되는 Zeroshot 결과 (제로 ot 평가는 Colab의 단순화 된 평가와 약간 다릅니다) :
| 모델 | B16B_2 | L16L |
|---|---|---|
| imagenet Zero-샷 | 73.9% | 75.7% |
| Imagenet V2 Zero-Shot | 65.1% | 66.6% |
| CIFAR100 제로 샷 | 79.0% | 80.5% |
| PETS37 제로 샷 | 83.3% | 83.3% |
| resisc45 Zero-샷 | 25.3% | 25.6% |
| MS-Coco 캡션 이미지-텍스트 검색 | 51.6% | 48.5% |
| MS-Coco 캡션 텍스트-이미지 검색 | 31.8% | 31.1% |
위의 Colabs는 시작하는 데 매우 유용하지만 일반적으로 더 강력한 가속기로 더 큰 기계를 훈련하고 싶을 것입니다.
다음 명령을 사용하여 Google Cloud에서 GPUS로 VM을 설정할 수 있습니다.
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAME또는 다음 유사한 명령을 사용하여 TPU가 첨부 된 클라우드 VM을 설정할 수 있습니다 (아래의 TPU 자습서에서 복사 한 명령).
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME 그런 다음 평소와 같이 저장소 및 설치 종속성 (TPU 지원 기능을 갖춘 jaxlib 포함)을 가져옵니다.
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateGPU가 첨부 된 VM에 연결된 경우 다음 명령으로 JAX 및 기타 종속성을 설치하십시오.
pip install -r vit_jax/requirements.txtTPU가 첨부 된 VM에 연결된 경우 다음 명령으로 JAX 및 기타 종속성을 설치하십시오.
pip install -r vit_jax/requirements-tpu.txtflaxformer를 설치하고 여기에 연결된 해당 저장소에 제공된 지침을 따르십시오.
GPU와 TPU 모두 JAX가 첨부 된 가속기에 연결할 수 있는지 확인하십시오.
python -c ' import jax; print(jax.devices()) '마지막으로 모델을 미세 조정하는 섹션에 언급 된 명령 중 하나를 실행합니다.
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
역 순서대로 :
2022-08-18 : 이미지 측 (LIT_B16B : 768)의 선형 헤드없이 60K 단계 (LIT_B16B : 30K)로 훈련 된 LIT-B16B_2 모델이 추가되었으며 성능이 향상됩니다.
2022-06-09 : 강력한 데이터 확대없이 Imagenet에서 GSAM을 사용하여 처음부터 훈련 된 VIT 및 믹서 모델을 추가했습니다. 결과 VITS는 ADAMW Optimizer 또는 Original SAM 알고리즘을 사용하여 훈련 된 유사한 크기 또는 강력한 데이터 증강을 능가하는 비슷한 크기의 VITS보다 성능이 뛰어납니다.
2022-04-14 : 조명 모델에 대한 모델과 Colab을 추가했습니다.
2021-07-29 : VIT-B/8 Augreg 모델 추가 (3 개의 상류 체크 포인트 및 해상도의 적응 = 224).
2021-07-02 : "시력 변압기가 Resnet을 능가 할 때"용지를 추가했습니다
2021-07-02 : SAM (Sharpness-Aware Minimization) 최적화 VIT 및 MLP 믹서 체크 포인트를 추가했습니다.
2021-06-20 : "VIT를 훈련시키는 방법? ..."종이와 새로운 콜랩을 추가하여 논문에 언급 된> 50K 사전 훈련 및 미세 조정 체크 포인트를 탐색했습니다.
2021-06-18 :이 저장소는 아마 리넨 API 및 ml_collections.ConfigDict 을 사용하도록 다시 작성되었습니다.
2021-05-19 : "VIT를 훈련시키는 방법? ..."용지를 발표하면 다양한 데이터 확대 및 모델 정규화로 ImageNet 및 ImageNet-21K에서 미리 훈련 된 50K 이상의 VIT 및 하이브리드 모델을 추가했습니다. , imagenet, pets37, kitti-distance, cifar-100 및 resisc45에서 미세 조정. 이 모델의 보물을 탐색하려면 vit_jax_augreg.ipynb 를 확인하십시오! 예를 들어, 해당 Colab을 사용하여 논문의 표 3의 i21k_300 열에서 권장되는 사전 훈련 및 미세 조정 체크 포인트의 파일 이름을 가져올 수 있습니다.
2020-12-01 : R50+VIT-B/16 하이브리드 모델 (RESNET-50 백본 위에 VIT-B/16)을 추가했습니다. Imagenet21K에 사전이 발생하면이 모델은 계산 양조 비용의 절반 미만으로 L/16 모델의 거의 성능을 달성합니다. "R50"은 B/16 변형에 대해 다소 수정되었습니다. 원래 RESNET-50에는 [3,4,6,3] 블록이 있으며 각각 이미지의 해상도를 2 배로 줄입니다. RESNET 줄기와 함께 32 배의 감소가 발생하므로 (1,1) 패치 크기가 더 이상 실현 될 수 없습니다. 이러한 이유로 우리는 대신 R50+B/16 변형에 [3,4,9] 블록을 사용합니다.
2020-11-09 : VIT-L/16 모델을 추가했습니다.
2020-10-29 : ImageNet-21K에 사전에 사전 BIT-B/16 및 VIT-L/16 모델이 추가 된 다음 224x224 해상도 (기본 384x384 대신)에서 Imagenet에서 미세 조정되었습니다. 이 모델에는 이름에 접미사 "-224"가 있습니다. 그들은 각각 81.2%와 82.7% 상위 1 상 정확도를 달성 할 것으로 예상된다.
Andreas Steiner가 준비한 오픈 소스 릴리스.
참고 :이 저장소는 Google-Research/Big_transfer에서 포크 및 수정되었습니다.
이것은 공식적인 Google 제품이 아닙니다.


