LLaMA Omni
1.0.0
저자 : Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui MA, Shaolei Zhang, Yang Feng*
llama-omni는 llama-3.1-8b-instruct에 구축 된 언어 모델입니다. 연설 지침을 기반으로 텍스트 및 음성 응답을 동시에 생성하는 저도 및 고품질 음성 상호 작용을 지원하며 동시에 텍스트 및 음성 응답을 생성합니다.
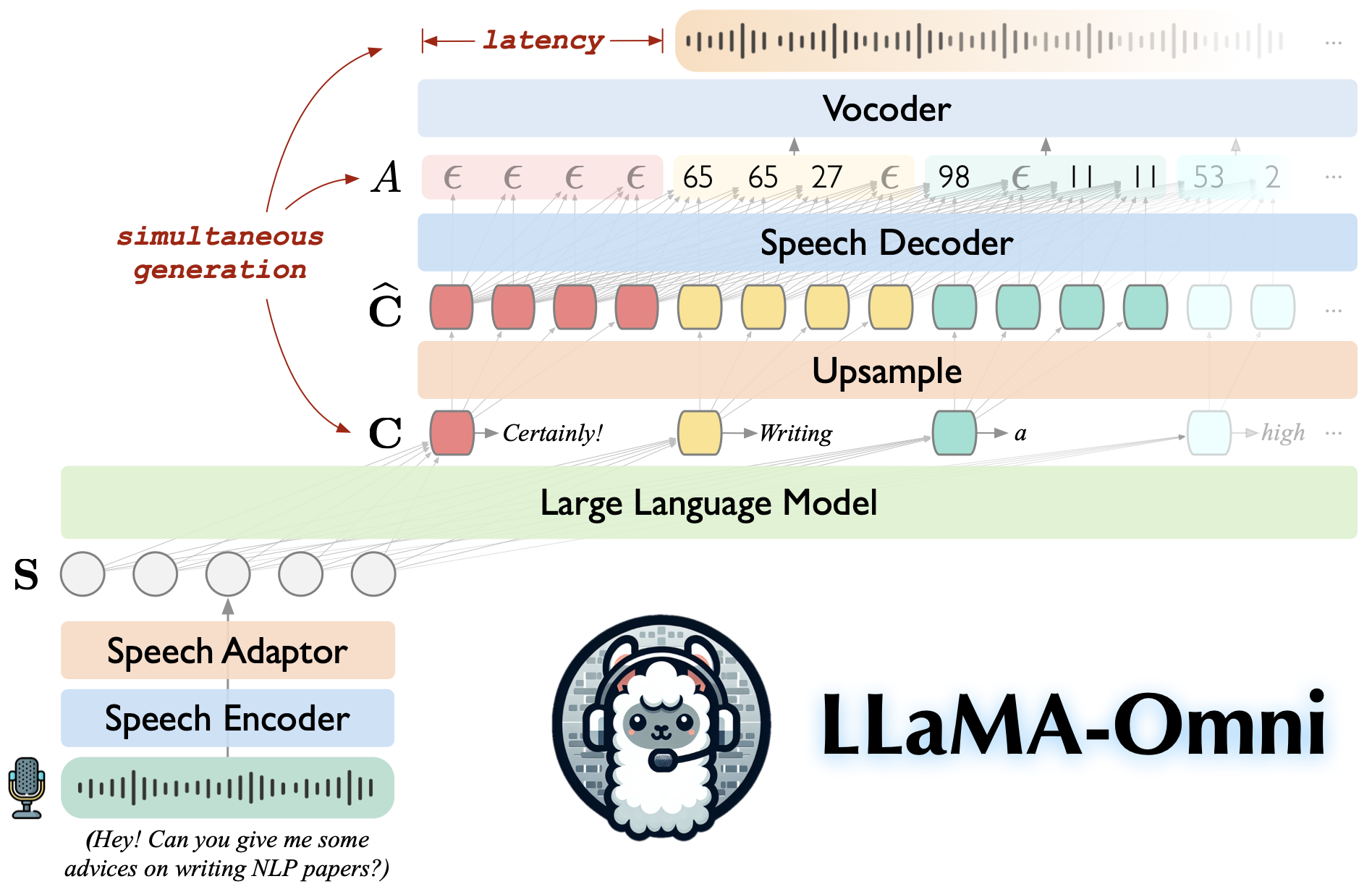
Llama-3.1-8B 비율을 기반으로하여 고품질 응답을 보장합니다.
226ms의 낮은 대기 시간과의 저도의 음성 상호 작용.
텍스트와 음성 응답의 동시 생성.
♻️은 단지 4 GPU를 사용하여 3 일 이내에 훈련되었습니다.
이 저장소를 복제하십시오.
git 클론 https://github.com/ictnlp/llama-omnicd llama-omni
패키지를 설치하십시오.
콘다 생성 -n llama -omni python = 3.10 콘다는 llama-omni를 활성화합니다 PIP 설치 PIP == 24.0 PIP 설치 -E.
fairseq 설치하십시오.
git 클론 https://github.com/pytorch/fairseqcd fairseq PIP 설치 -E. -건물 이산
flash-attention 설치하십시오.
PIP Flash-Attn-건축물 이산을 설치하십시오
Llama-3.1-8B-Omni 모델을? Huggingface에서 다운로드하십시오.
Whisper-large-v3 모델을 다운로드하십시오.
수입 속삭임 model = whisper.load_model ( "large-v3", download_root = "model/speech_encoder/")
단위 기반 Hifi-Gan 보코더를 다운로드하십시오.
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -p vocoder/ wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -p vocoder/
컨트롤러를 시작하십시오.
Python -m omni_speech.serve.controller -host 0.0.0.0 -port 10000
Gradio 웹 서버를 시작하십시오.
Python -m omni_speech.serve.gradio_web_server---controller http : // localhost : 10000-port 8000- 모드 델리스트-모드 Reload --vocoder vocoder/g_00500000 -vocoder-cfg vocoder/config.json
모델 작업자를 시작하십시오.
Python -m omni_speech.serve.model_worker -host 0.0.0.0 ---- 컨트롤러 http : // localhost : 10000 -port 40000-워크 http : // localhost : 40000 -Model-path llama-3.1-8b-omni -모델-이름 llama-3.1-8b-omni -s2s
http : // localhost : 8000/를 방문하고 llama-3.1-8b-omni와 상호 작용하십시오!
참고 : Gradio에서 스트리밍 오디오 재생의 불안정성으로 인해 자동 재생을 활성화하지 않고 스트리밍 오디오 합성 만 구현했습니다. 좋은 해결책이 있다면 PR을 제출하십시오. 감사해요!
로컬로 추론을 실행하려면 omni_speech/infer/examples 디렉토리의 형식에 따라 음성 명령 파일을 구성한 다음 다음 스크립트를 참조하십시오.
bash omni_speech/full/run.sh omni_speech/lell/examples
우리의 코드는 Apache-2.0 라이센스에 따라 릴리스됩니다. 우리의 모델은 학업 연구 목적으로 만 사용되며 상업적 목적으로 사용되지 않을 수 있습니다.
다음 조건이 충족되면이 모델을 학업 환경에서 자유롭게 사용, 수정 및 배포 할 수 있습니다.
비상업적 사용 :이 모델은 상업적 목적으로 사용되지 않을 수 있습니다.
인용 : 연구 에서이 모델을 사용하는 경우 원래 작업을 인용하십시오.
상업적 사용 문의 또는 상업용 라이센스를 얻으려면 [email protected] 으로 문의하십시오.
llava : 우리가 구축 한 코드베이스.
SLAM-LLM : 우리는 음성 인코더 및 음성 어댑터에 대한 코드를 빌립니다.
궁금한 점이 있으면 문제를 제출하거나 [email protected] 에 문의하십시오.
우리의 작업이 귀하에게 유용하다면 다음과 같이 인용하십시오.
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

