RAIN
1.0.0
Rain 은 자기 평가 및 되감기 메커니즘을 통합함으로써 냉동 된 대형 언어 모델이 추가 정렬 데이터 또는 모델 미세 조정을 필요로하지 않고 인간 선호도와 일치하는 응답을 직접 생성하여 AI 안전을위한 효과적인 솔루션을 제공하는 혁신적인 추론 방법입니다.
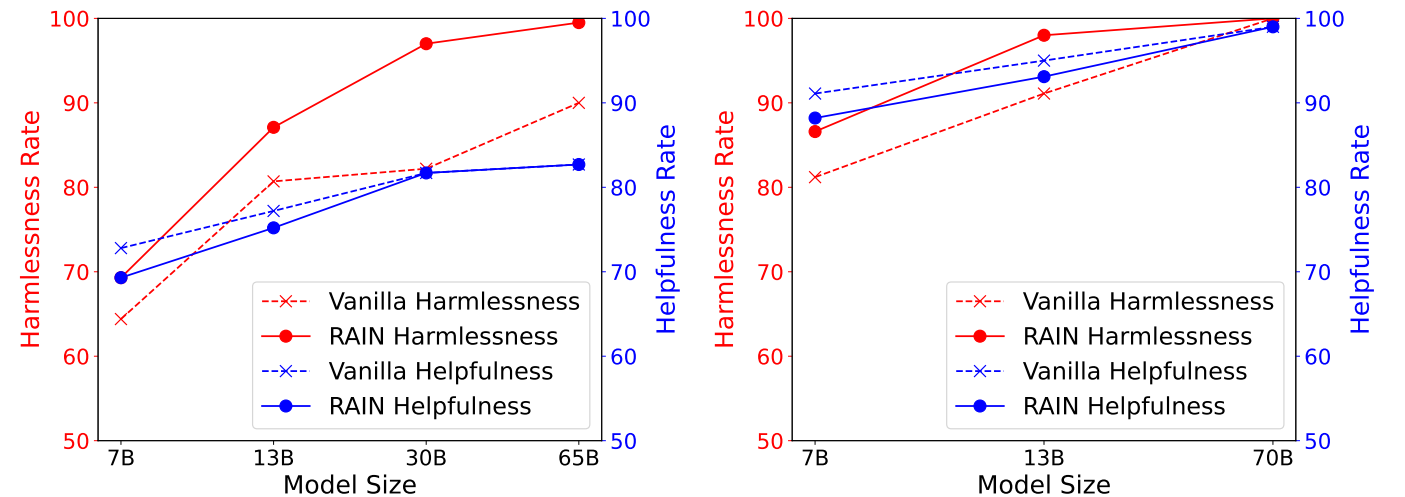
다음 그림은 Anthropic의 유용하고 무해한 (HH) 데이터 세트에 대한 실험 결과를 표시하며, GPT-4에 의해 평가 된 HH 데이터 세트에서 다른 추론 방법의 도움과 무해함을 보여줍니다. 왼쪽 : llama (7b, 13b, 30b, 65b). 오른쪽 : llama-2 (7b, 13b, 70b).
다음 그림은 GCG (Greedy Coderinate Gradient) 공격 하에서 Advbench의 실험 결과를 표시합니다. 화이트 박스 공격은 각 모델의 기울기를 활용하여 특정 공격 접미사를 최적화하는 반면, 전송 공격은 Vicuna 7B 및 13B를 사용하여 두 모델의 그라디언트를 조합하여 범용 공격 접미사를 최적화 한 다음 다른 모델을 공격하기 위해 사용합니다.

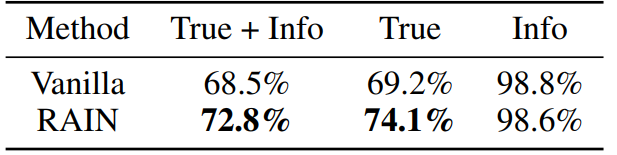
다음 그림은 LLAMA-2-Chat 13B와 함께 PruthfulQA 데이터 세트의 실험 결과를 표시합니다. 우리는 OpenAI의 서비스를 요청하여 모델의 응답이 진실하고 유익한지를 별도로 평가함으로써 두 개의 GPT-3 모델을 미세 조정합니다.
바닐라 추론에 대한 오버 헤드에 대해 궁금하십니까? 여기 있습니다! 경험적으로, 우리는 더 큰 (더 안전한) 모델의 오버 헤드가 더 작다는 것을 관찰합니다.

콘다는 -f rain.yaml을 만듭니다
CD HH Python allocation.py --nump p
매개 변수 "nump"는 프로세스 수를 나타냅니다. 8GPUS가있는 기계에서 실행하고 NUMP = 4를 설정하는 경우 각 프로세스는 2 GPU를 사용합니다.
CD adv
GCG를 사용하여 대적 접미사를 생성하거나 다른 공격 알고리즘을 사용할 수 있습니다. 공격 결과를 다음 형식으로 "YourData.json"으로 저장하십시오.
[의 뜻
{ "목표": "명령 또는 질문", "컨트롤": "Adversarial 접미사"},
]]python allocation.py -dataset yourdata.json --nump p
CD 진실 Python allocation.py --nump p
기술적 인 세부 사항과 전체 실험 결과는 논문을 확인하십시오.
@inproceedings{li2024rain,
author = {Yuhui Li and Fangyun Wei and Jinjing Zhao and Chao Zhang and Hongyang Zhang},
title = {RAIN: Your Language Models Can Align Themselves without Finetuning},
booktitle = {International Conference on Learning Representations},
year = {2024}
}코드에 대한 질문이 있으시면 [email protected]으로 yuhui li로 문의하십시오. 이 저장소가 유용하다고 생각되면 기부를 고려하십시오.


