streaming
v0.9.1
클라우드 스토리지의 대형 데이터 세트에 대한 교육을 최대한 빠르고 저렴하며 확장하기 위해 StreamingDataset을 구축했습니다.
이 제품은 대규모 모델을위한 다중 노드, 분산 교육을 위해 특별히 설계되었습니다. 정확성 보장, 성능 및 사용 편의성을 조정합니다. 이제 교육 데이터 위치와 무관하게 어디서나 효율적으로 훈련 할 수 있습니다. 필요할 때 필요한 데이터에서만 스트리밍하십시오. StreamingDataset을 구축 한 이유에 대한 자세한 내용은 공지 블로그를 읽으십시오.
StreamingDataset은 이미지, 텍스트, 비디오 및 멀티 모달 데이터를 포함한 모든 데이터 유형과 호환됩니다.
주요 클라우드 스토리지 제공 업체 (AWS, OCI, GCS, Azure, Databricks 및 Cloudflare R2, Coreweave, Backblaze B2 등과 같은 S3 호환 객체 저장소)를 지원하고 Pytorch Iterabledataset 클래스를위한 드롭 인 교체로 설계되었습니다. , StreamingDataset은 기존 교육 워크 플로에 완벽하게 통합됩니다.

스트리밍은 pip 사용하여 설치할 수 있습니다.
PIP를 설치하여 Mosaicml-streaming을 설치하십시오
원시 데이터 세트를 지원되는 스트리밍 형식 중 하나로 변환하십시오.
Python 객체를 인코딩하고 디코딩 할 수있는 MDS (Mosaic Data Shard) 형식
CSV / TSV
Jsonl
import numpy as import image image image image image import mdswriter# 로컬 또는 원격 디렉토리 압축 된 출력 filesdata_dir = 'Path-to-Dataset'# 사전 매핑 입력 필드를 데이터 typescolumns = { 'image': 'jpeg'로 저장합니다. , 'class': 'int'}# shard compression, anycompression = 'zstd'# mdswriterwith mdswriter (out = data_dir, columns, columns, compression = compression)를 사용하여 샘플을 파편으로 저장 : out (10000). ) : 샘플 = { 'image': image.fromArray (np.random.randint (0, 256, (32, 32, 3), np.uint8)), 'class': np.random.randint (10),
} out.write (샘플)스트리밍 데이터 세트를 선택한 클라우드 스토리지 (AWS, OCI 또는 GCP)에 업로드하십시오. 다음은 AWS CLI를 사용하여 디렉토리를 S3 버킷에 업로드하는 한 예입니다.
$ aws s3 cp-재주문 경로-다타 세트 s3 : // dataset
torch.utils.data import dataLoaderFrom import 스트리밍 스트리밍 Dataset# 원격 경로 전체 데이터 세트가 지속적으로 저장되는 원격 경로 = 's3 : // my-bucket/path-to-dataset'# local working dir dataSet가 작동하는 동안 DataSet이 캐시되는 곳에서 DIR /path-to-dataset '# 스트리밍 DataSetDataset 작성 = streamingDataset (local = local, remote = remote = 셔플 = true)# 샘플# 1337 ... 샘플 = dataset [1337] img = 샘플 ['이미지를 보자. '] cls = 샘플 ['class ']# pytorch dataloaderDataloader = dataloader (dataSet) 생성
시작 안내서, 예제, API 참조 및 기타 유용한 정보는 문서에서 찾을 수 있습니다.
모델을 훈련하기위한 엔드 투 엔드 튜토리얼이 있습니다.
Cifar-10
Facesynthetics
syntheticnlp
또한 streaming 디렉토리에서 찾을 수있는 다음 인기있는 데이터 세트에 대한 스타터 코드도 있습니다.
| 데이터 세트 | 일 | 읽다 | 쓰다 |
|---|---|---|---|
| laion-400m | 텍스트와 이미지 | 읽다 | 쓰다 |
| Webvid | 텍스트와 비디오 | 읽다 | 쓰다 |
| C4 | 텍스트 | 읽다 | 쓰다 |
| Enwiki | 텍스트 | 읽다 | 쓰다 |
| 말뚝 | 텍스트 | 읽다 | 쓰다 |
| ADE20K | 이미지 분할 | 읽다 | 쓰다 |
| cifar10 | 이미지 분류 | 읽다 | 쓰다 |
| 머리 | 이미지 분류 | 읽다 | 쓰다 |
| imagenet | 이미지 분류 | 읽다 | 쓰다 |
이 데이터 세트에 대한 교육을 시작하려면 :
convert 디렉토리의 해당 스크립트를 사용하여 원시 데이터를 .MDS 형식으로 변환합니다.
예를 들어:
$ python -m streaming.multimodal.convert.webvid -in <csv file> -out <mds output directory>
모델 교육을 시작하려면 데이터 세트 클래스를 가져옵니다.
streaming.multimodal import StreamingInsideWebVidDataset = StreamingInsideWebVid (local = local, remote = remote, shuffle = true)
Stream 으로 데이터 세트 혼합물을 쉽게 실험하십시오. 데이터 세트 샘플링은 상대 (비례) 또는 절대 (반복 또는 샘플 용어)로 제어 할 수 있습니다. 스트리밍 중에 다른 데이터 세트가 스트리밍, 셔플 및 혼합 된 정시에 원활하게 혼합됩니다.
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
솔루션의 고유 한 기능 : 샘플은 GPU, 노드 또는 CPU 작업자의 수에 관계없이 동일한 순서입니다. 이것은 더 쉽게 할 수있게합니다.
훈련 실행 및 손실 스파이크를 재생산하고 디버그합니다
64 gpus로 훈련 된 체크 포인트를로드하고 재현성으로 8 GPU에 디버그
아래 그림을 참조하십시오 - 1, 8, 16, 32 또는 64 GPU의 모델 교육 정확히 동일한 손실 곡선을 생성합니다 (플로팅 포인트 수학의 한계까지).
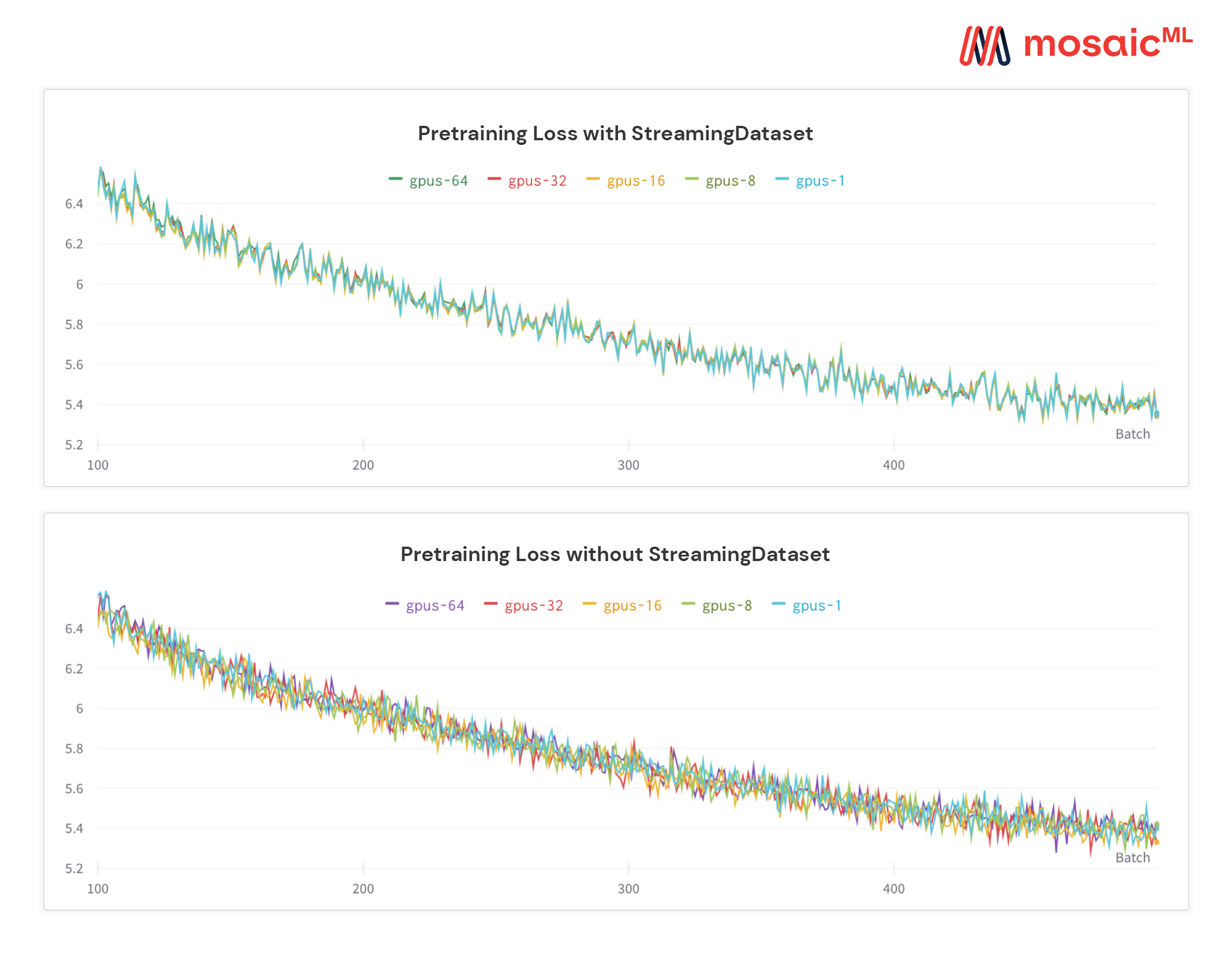
하드웨어 고장 또는 손실 스파이크 후 Dataloader가 회전하는 동안 작업이 재개 될 때까지 비용이 많이 들고 성가신 일 수 있습니다. 우리의 결정 론적 샘플 주문 덕분에 StreamingDataset을 사용하면 긴 훈련 실행 중에 몇 시간이 아닌 몇 초 안에 훈련을 재개 할 수 있습니다.
재개 대기 시간을 최소화하면 기존 솔루션에 비해 수천 달러의 추출 비용과 유휴 GPU 계산 시간을 절약 할 수 있습니다.
당사의 MDS 형식은 뼈에 외부 작업을 줄여서 Dataloader에 의해 병목 현상이있는 워크로드의 대안에 비해 매우 낮은 샘플 대기 시간과 더 높은 처리량을 초래합니다.
| 도구 | 처리량 |
|---|---|
| StreamingDataset | ~ 19000 IMG/SEC |
| ImageFolder | ~ 18000 IMG/SEC |
| WebDataset | ~ 16000 IMG/SEC |
표시된 결과는 ImageNet + RESNET-50 교육에서 나오며 첫 번째 시대 후 데이터가 캐시 된 후 5 회 이상 반복됩니다.
StreamingDataset을 사용함으로써 모델 수렴은 셔플 링 알고리즘 덕분에 로컬 디스크를 사용하는 것만 큼 좋습니다.
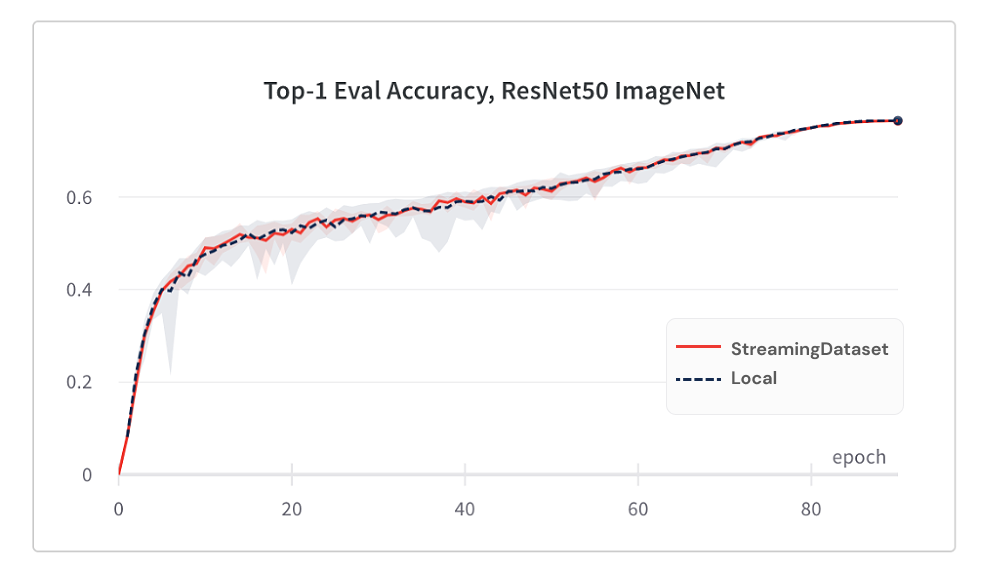
다음은 5 번 이상 반복되는 ImageNet + RESNET-50 교육의 결과입니다.
| 도구 | 상단 1 정확도 |
|---|---|
| StreamingDataset | 76.51% +/- 0.09 |
| ImageFolder | 76.57% +/- 0.10 |
| WebDataset | 76.23% +/- 0.17 |
StreamingDataset은 노드에 할당 된 모든 샘플을 가로 질러 셔플을하는 반면, 대체 솔루션은 작은 풀 (단일 프로세스 내)에서 샘플 만 셔플합니다. 더 넓은 수영장을 가로 지르는 셔플은 인접한 샘플을 더 많이 확산시킵니다. 또한 셔플 링 알고리즘은 삭제 된 샘플을 최소화합니다. 우리는이 두 셔플 링 기능이 모델 수렴에 유리한 것을 발견했습니다.
필요할 때 필요한 데이터에 액세스하십시오.
샘플이 아직 다운로드되지 않더라도 dataset[i] 에 액세스하여 샘플 i 얻을 수 있습니다. 다운로드는 즉시 시작되며 결과는 완료되면 반환됩니다. 샘플이 순차적으로 번호가 매겨져 있고 어떤 순서로든 액세스 할 수있는 맵 스타일의 Pytorch 데이터 세트와 유사하게 반환됩니다.
DataSet = StreamingDataset (...) 샘플 = DataSet [19543]
StreamingDataset은 여러 샘플에 대해 행복하게 반복합니다. 데이터 세트가 구운 수의 장치에서 분할되도록 샘플을 영원히 삭제할 필요는 없습니다. 대신, 각각의 다른 샘플을 반복하여 (삭제되지 않음) 각 장치가 동일한 카운트를 처리하도록합니다.
DataSet = StreamingDataset (...) DL = Dataloader (DataSet, Num_Workers = ...)
디스크 사용량을 지정된 한계로 유지하기 위해 최소 최소한 최근에 사용 된 파편을 동적으로 삭제하십시오. 이것은 streamingdataset 인수 cache_limit 설정하여 활성화됩니다. 자세한 내용은 셔플 링 가이드를 참조하십시오.
dataset = StreamingDataset( cache_limit='100gb', ... )
다음은 StreamingDataset을 사용한 몇 가지 프로젝트와 실험입니다. 추가 할 것이 있습니까? [email protected]으로 이메일을 보내거나 커뮤니티 슬랙에 가입하십시오.
Biomedlm : Mosaicml 및 Stanford CRFM에 의한 생체 의학을위한 도메인 특정 대형 언어 모델
모자이크 확산 모델 : 스크래치 비용으로부터 안정적인 확산 훈련 <$ 160k
모자이크 LLMS : <$ 500K의 GPT-3 품질
모자이크 RESNET : 모자이크 RESNET 및 작곡가와 함께 빠른 컴퓨터 비전 훈련
Mosaic deeplabv3 : 5 배 더 빠른 이미지 세분화 훈련이 Mosaicml 레시피
… 앞으로 더! 계속 지켜봐!
우리는 모든 기여, 풀 요청 또는 문제를 환영합니다.
기여를 시작하려면 기여 페이지를 참조하십시오.
추신 : 우리는 고용하고 있습니다!
이 프로젝트가 마음에 들면 스타를주고 다른 프로젝트를 확인하십시오.
Composer- 확장 가능하고 효율적인 신경망 훈련을 쉽게하는 현대식 Pytorch 도서관
MosaICML 예제 - ML 모델을 신속하고 높은 정확도로 훈련하기위한 참조 예 - GPT / 대형 언어 모델, 안정적인 확산, Bert, Resnet -50 및 Deeplabv3의 스타터 코드를 특징으로합니다.
Mosaicml Cloud- LLM, 확산 모델 및 기타 대형 모델의 교육 비용을 최소화하기 위해 구축 된 교육 플랫폼-다중 클라우드 오케스트레이션, 손쉬운 멀티 노드 스케일링 및 교육 시간 속도를 높이기위한 언더 최적화를 특징으로합니다.
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

