Huawei UK University Challenge Competition 2021
1.0.0

팀 발표자 : Kahraman Kostas
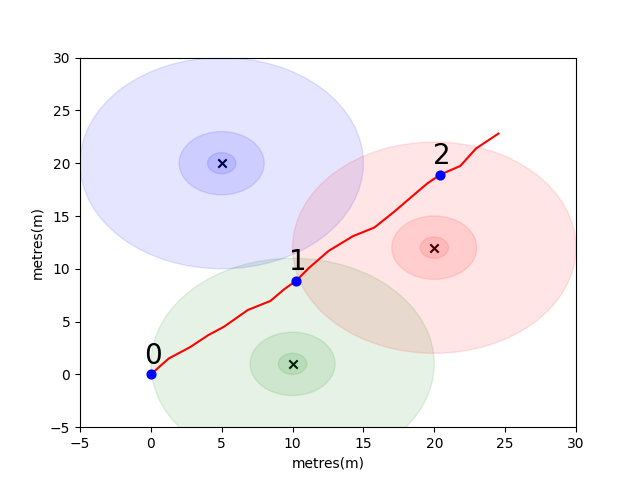
시작하기 위해 우리는 몇 가지 주요 실내 포지셔닝 개념을 소개하기 위해 간단한 문제를 해결했습니다. 다음 환경을 고려하십시오. 사용자는 3 개의 Wi -Fi 이미 터가있을 때 열린 공간으로 여행하고 있습니다 (이 사용자가 만든 데이터를 궤적이라고합니다). 각 이미 터에는 고유 한 MAC 주소가 있습니다. 사용자는 주기적으로 WiFi 환경을 스캔하고 각 감지 된 MAC (DB)의 RSSI를 기록하는 스마트 폰이 장착되어 있습니다.
이 모델의 경우 각 이미 터에 대한 표준 로그 손실 자유 공간 전파 모델을 사용했습니다. 이것은 여유 공간에서 잘 작동하지만 벽 및 기타 장애물이있는 실제 실내 환경에서는 더 복잡한 방식으로 신호를 튀길 수있는 간단한 모델입니다. 일반적으로 우리는 방출 안테나의 고정 에너지가 파도가 전파 될 때 증가하는 영역에 퍼져 있기 때문에 거리에서 RSSI의 가파른 하락을 볼 것으로 예상됩니다. 아래의 다이어그램에서 각 원은 10dB의 낙하를 나타냅니다.
사용자는 지점 (0,0)에서 북동쪽을 걷고 전화는 환경을 세 번 스캔합니다. 각 스캔에서 기록 된 데이터는 다음과 같습니다.
scan 0 -> {'green': -60, 'blue': -66, 'red': -67}
scan 1 -> {'green': -58, 'blue': -61, 'red': -60}
scan 2 -> {'green': -66, 'blue': -62, 'red': -59}
WiFi 환경의 복잡하고 로컬로 독특한 특성은 실내 위치 시스템에 매우 유용합니다. 예를 들어 아래 이미지 scan 1 에서는 3 개의 이미지의 중심에서 데이터를 측정 하며이 환경에는 유사한 RSSI 값을 등록 할 수있는 판독 값을 취할 수있는 다른 장소가 없습니다. 독립적 인 궤적의 스캔 또는 "지문"세트가 주어지면, 우리는 실제 공간에 얼마나 가까이 있는지를 나타내는 WiFi 공간에서 얼마나 유사한 지 계산하는 데 관심이 있습니다.
첫 번째 과제는 위에서 도입 한 샘플 궤적의 각 스캔간에 유클리드 거리 와 맨해튼 거리 지표를 계산하는 기능을 작성하는 것입니다. 단일 궤적의 데이터를 사용하면 유사성 메트릭의 품질을 테스트하는 좋은 방법은 보행자 Dead Reckoning이 사용하는 전화의 IMU (Intertial Measurement Unit)의 데이터를 사용하여 실제 거리의 상당히 정확한 추정치를 얻을 수 있습니다. (pdr) 모듈.
def euclidean ( fp1 , fp2 ):
raise NotImplementedError
def manhattan ( fp1 , fp2 ):
raise NotImplementedError # solution of the above functions
from scipy . spatial import distance
def euclidean ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . euclidean ( fp1 , fp2 )
def manhattan ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . cityblock ( fp1 , fp2 ) import json
import numpy as np
import matplotlib . pyplot as plt
from metrics import eval_dist_metric
with open ( "intro_trajectory_1.json" ) as f :
traj = json . load ( f )
## Pre-calculate the pair indexes we are interested in
keys = []
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
# only calculate the upper triangle
if fp1 [ 'step_index' ] > fp2 [ 'step_index' ]:
keys . append (( fp1 [ 'step_index' ], fp2 [ 'step_index' ]))
## Get the distances from PDR
true_d = {}
for step1 in traj [ 'steps' ]:
for step2 in traj [ 'steps' ]:
key = ( step1 [ 'step_index' ], step2 [ 'step_index' ])
if key in keys :
true_d [ key ] = abs ( step1 [ 'di' ] - step2 [ 'di' ])
euc_d = {}
man_d = {}
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
key = ( fp1 [ 'step_index' ], fp2 [ 'step_index' ])
if key in keys :
euc_d [ key ] = euclidean ( fp1 [ 'profile' ], fp2 [ 'profile' ])
man_d [ key ] = manhattan ( fp1 [ 'profile' ], fp2 [ 'profile' ])
print ( "Euclidean Average Error" )
print ( f' { eval_dist_metric ( euc_d , true_d ):.2f } ' )
print ( "Manhattan Average Error" )
print ( f' { eval_dist_metric ( man_d , true_d ):.2f } ' ) Euclidean Average Error
9.29
Manhattan Average Error
4.90
기능을 올바르게 구현하면 유클리드 메트릭의 평균 오류는 9.29 이고 맨해튼은 4.90 에 불과하다는 것을 알았을 것입니다. 따라서이 데이터의 경우 맨해튼 거리는 실제 거리에 대한 더 나은 추정치입니다.
이것은 물론 매우 단순한 모델입니다. 실제로, RSSI 값과 이러한 방식으로 여유 공간 거리 사이에는 직접적인 관계가 없습니다. 일반적으로 거리에 대한 자체 추정치를 만들 때 숫자 점수에 물리적 거리 추정치에 맞게 궤적 내에서 알려진 PDR 거리를 사용합니다.
주요 도전을 위해 Wi-Fi 지문 만 기반으로 두 스캔 사이의 실제 거리를 추정하기 위해 자신의 메트릭을 개발하기를 바랍니다. 2021 년 초에 단일 쇼핑몰에서 수집 한 실제 크라우드 소싱 데이터를 제공 할 것입니다. 데이터에는 114661 개의 지문 스캔과 스캔 사이의 879824 거리가 포함됩니다. 우리가 고려해야 할 추가 정보가 주어지면 거리는 실제 거리에 대한 최상의 추정치가 될 것입니다.
우리는 지문 쌍의 테스트 세트를 제공 할 것이며 얼마나 멀리 떨어져 있는지 알려주는 함수를 작성해야합니다.
이 기능은 우리가 위에서 도입 한 메트릭 중 하나의 변형만큼 간단하거나 다른 상황에서 다른 MAC 주소 (또는 Mac 주소 조합)를 가중치하는 전체 머신 러닝 솔루션만큼 복잡 할 수 있습니다.
고려해야 할 몇 가지 최종 포인트 :
데이터는 귀하를 위해 세 가지 파일로 조립됩니다.
task1_fingerprints.json 문제에 대한 모든 지문 정보가 포함되어 있습니다. 즉, 각 항목은 쇼핑몰 영역에서 Wi -Fi 이미 터의 실제 스캔을 나타냅니다. 동일한 MAC 주소가 많은 지문에 존재한다는 것을 알게 될 것입니다.
task1_train.csv 에는 알고리즘을 설계/훈련하는 데 도움이되는 유효한 교육 쌍이 포함되어 있습니다. 각 id1-id2 쌍에는 라벨이 붙은지면 진실 거리 (미터)가 있으며 각 ID는 task1_fingerprints.json 의 지문에 해당합니다.
task1_test.csv 는 task1_train.csv 와 동일한 형식이지만 변위가 포함되어 있지 않습니다. 이것들은 우리가 당신이 원시 지문 정보를 사용하는 것을 예측하기를 원하는 것입니다.
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
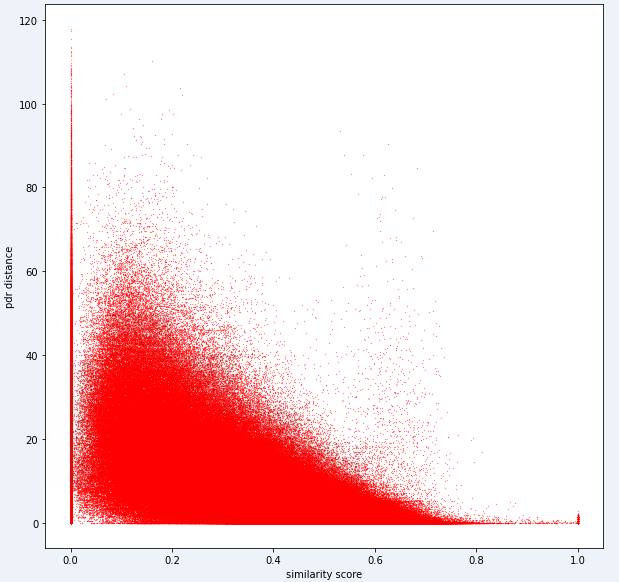
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]])궁극적으로 이상적인 모델은 치수가 높은 지문 공간 (1 지문이 많은 측정을 포함 할 수 있음)과 1 차원 거리 공간 사이의 정확한 매핑을 찾을 수 있어야합니다. 메트릭이 명백한 추세를 나타냅니다. 높은 유사성은 저 거리와 관련이 있어야합니다.
아래는이 작업에 내부적으로 사용하는 하나의 거리 메트릭입니다. 이 메트릭의 경우에도 상당한 양의 노이즈가 있음을 알 수 있습니다.
이러한 수준의 소음으로 인해 작업 1의 점수 지표는 리콜보다 정밀하게 바이어스됩니다.
제출물은 test1_test.csv 파일의 정확한 ID를 사용해야하며 지문 쌍의 추정 거리 (미터)로 세 번째 (현재 비어있는) 변위 열을 채워야합니다.
def my_distance_function ( fp1 , fp2 ):
raise NotImplementedError output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
fp1 = fps [ id1 ]
fp2 = fps [ id2 ]
distance_estimate = my_distance_function ( fp1 , fp2 )
output_data . append ([ id1 , id2 , distance_estimate ])
with open ( "MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )첫 번째 작업의 단계는 다음과 같이 요약 될 수 있습니다.
이 단계는 아래 이미지에 설명되어 있습니다.

Python 3.6.5를 사용하여 응용 프로그램 파일을 만들었습니다. 경쟁 시작시 주어진 예제 파일에 포함되지 않은 몇 가지 추가 모듈이 포함되었습니다. 이 모듈은 다음과 같이 나열 될 수 있습니다.
| 몰 룰레스 | 일 |
|---|---|
| 텐서 플로 | 딥 러닝 |
| 팬더 | 데이터 분석 |
| Scipy | 거리 컴퓨팅 |
우리는이 모듈을 첫 번째 단계로 설치하는 것으로 시작했습니다.
## 1.1 Installing modules
!p ip install tensorflow == 2.6 . 2
!p ip install scipy
!p ip install pandas 이 단계에서는 반복 가능한 결과를 얻기 위해 사용될 관련 랜덤 시드를 수정했습니다. 이런 식으로, 우리는 모든 달리기에서 동일한 결과를 얻는 결정 론적 경로를 제공했습니다. 그러나 우리의 관찰에 따르면, 다른 컴퓨터로 얻은 결과는 약간 다를 수 있습니다 (± 1%)
## 1.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )
import tensorflow as tf
tf . random . set_seed ( seed_value )
import tensorflow as tf
session_conf = tf . compat . v1 . ConfigProto ( intra_op_parallelism_threads = 1 , inter_op_parallelism_threads = 1 )
sess = tf . compat . v1 . Session ( graph = tf . compat . v1 . get_default_graph (), config = session_conf ) 이 섹션에서는 사용할 데이터를로드합니다. 우리는 주어진 샘플 파일에서 코드와 설명을 가져 왔습니다 ( Task1-IPS-Challenge-2021.ipynb ).
task1_fingerprints.json 문제에 대한 모든 지문 정보가 포함되어 있습니다. 즉, 각 항목은 쇼핑몰 영역에서 Wi -Fi 이미 터의 실제 스캔을 나타냅니다. 동일한 MAC 주소가 많은 지문에 존재한다는 것을 알게 될 것입니다.
task1_train.csv 에는 알고리즘을 설계/훈련하는 데 도움이되는 유효한 교육 쌍이 포함되어 있습니다. 각 id1-id2 쌍에는 라벨이 붙은지면 진실 거리 (미터)가 있으며 각 ID는 task1_fingerprints.json 의 지문에 해당합니다.
task1_test.csv 는 task1_train.csv 와 동일한 형식이지만 변위가 포함되어 있지 않습니다.
## 1.3 Loading the data
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]]) 879824it [05:16, 2778.31it/s]
5160445it [01:00, 85269.27it/s]
이 단계에서는 두 기능을 사용하여 기능 추출을 수행합니다. feature_extraction_file 함수는 JSON 파일에서 지문 (쌍)의 관련 값을 가져 와서 feature_extraction 함수로 보내 계산을 수행합니다.
feature_extraction 함수에서,이 두 지문이 크기와 포함 된 장치의 측면에서 서로 다르면 두 지문에 포함 된 모든 장치는 함께 모여 반복하지 않고 공통 시퀀스를 형성합니다. 각 배열에서, 우리는이 두 배열을 비 응답 장치에 값 0을 할당하여 동일한 장치를 동일하게 만듭니다 (포함 된 장치 측면에서). 이 과정은 다음 이미지의 예제로 설명됩니다.
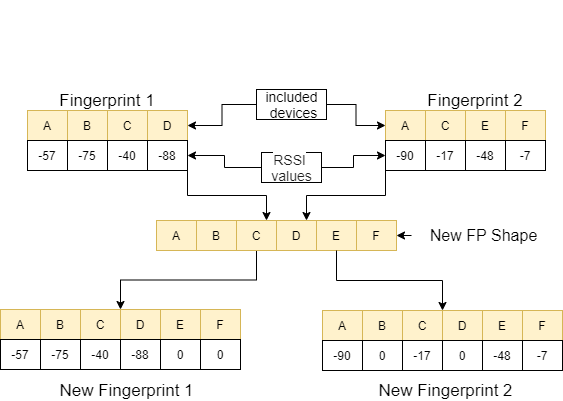
이 두 지문 사이의 거리는 유사하게 만들어진 11 가지 다른 방법을 사용하여 계산됩니다 [1]. 이러한 방법은 다음과 같습니다.
그런 다음이 값은 feature_extraction_file 함수로 지시 되며이 함수 내에서 CSV 파일로 저장됩니다. 다시 말해, 다양한 크기의 지문은이 프로세스의 결과로 11 가지 기능 CSV 파일로 바뀝니다. 사용될 모델은 새로 생성 된 기능으로 교육 및 테스트됩니다.
## 1.4 Feature Extraction
def feature_extraction_file ( data , name , flag ):
features = [[ "braycurtis" ,
"canberra" ,
"chebyshev" ,
"cityblock" ,
"correlation" ,
"cosine" ,
"euclidean" ,
"jensenshannon" ,
"minkowski" ,
"sqeuclidean" ,
"wminkowski" , "real" ]]
for i in tqdm (( data ), position = 0 , leave = True ):
fp1 = fps [ i [ 0 ]]
fp2 = fps [ i [ 1 ]]
feature = feature_extraction ( fp1 , fp2 )
if flag :
feature . append ( i [ 2 ])
else : feature . append ( 0 )
features . append ( feature )
with open ( name , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( features )
#print(features) ## 1.4 Feature Extraction
def feature_extraction ( fp1 , fp2 ):
mac = set ( list ( fp1 . keys ()) + list ( fp2 . keys ()))
mac = { i : 0 for i in mac }
f1 = mac . copy ()
f2 = mac . copy ()
for key in fp1 :
f1 [ key ] = fp1 [ key ]
for key in fp2 :
f2 [ key ] = fp2 [ key ]
f1 = list ( f1 . values ())
f2 = list ( f2 . values ())
braycurtis = scipy . spatial . distance . braycurtis ( f1 , f2 )
canberra = scipy . spatial . distance . canberra ( f1 , f2 )
chebyshev = scipy . spatial . distance . chebyshev ( f1 , f2 )
cityblock = scipy . spatial . distance . cityblock ( f1 , f2 )
correlation = scipy . spatial . distance . correlation ( f1 , f2 )
cosine = scipy . spatial . distance . cosine ( f1 , f2 )
euclidean = scipy . spatial . distance . euclidean ( f1 , f2 )
jensenshannon = scipy . spatial . distance . jensenshannon ( f1 , f2 )
minkowski = scipy . spatial . distance . minkowski ( f1 , f2 )
sqeuclidean = scipy . spatial . distance . sqeuclidean ( f1 , f2 )
wminkowski = scipy . spatial . distance . wminkowski ( f1 , f2 , 1 , np . ones ( len ( f1 )))
output_data = [ braycurtis ,
canberra ,
chebyshev ,
cityblock ,
correlation ,
cosine ,
euclidean ,
jensenshannon ,
minkowski ,
sqeuclidean ,
wminkowski ]
output_data = [ 0 if x != x else x for x in output_data ]
return output_data 이 작업에는 쇼핑몰에 Wi -Fi Emitters 주변의 RRSI 신호가있는 지문 스캔이 있습니다. 첫 번째 Challange는 회귀 작업 인 두 지문 스캔 사이의 거리를 추정하기를 원합니다. 우리는 생물학적 신경 네트워크에서 영감을 얻은 Ann (인공 신경망)을 사용했습니다. Ann은 3 개의 층으로 구성됩니다. 입력 레이어, 숨겨진 레이어 (하나 이상) 및 출력 레이어. ANN은 교육 데이터 (기능 포함)를 포함하는 입력 계층으로 시작하여 데이터를 첫 번째 숨겨진 계층으로 전달하는 첫 번째 숨겨진 계층의 가중치로 데이터를 전달합니다. 숨겨진 층에는 입력에 대한 가중치 계산 반복이 있으며 활성화 함수를 적용합니다 [2]. 우리의 문제가 회귀이기 때문에, 우리의 마지막 층은 단일 출력 뉴런입니다. 출력은 지문 스캔 쌍 사이의 거리를 예측하는 것입니다. 우리의 첫 번째 숨겨진 층에는 64가 있고 두 번째는 128 개의 뉴런이 있습니다. 이 모델의 모든 아키텍처는 다음과 같이 공유됩니다. 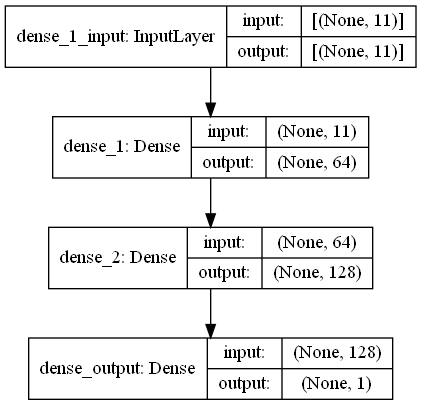
우리는 두 가지 함수를 사용하여 딥 러닝을 수행합니다. create_model 함수는 교육 데이터를 형성하여 모델을 훈련시키고 모델의 구조를 결정합니다. model_features 함수는 지정된 구조를 가진 모델을 생성합니다. 생성 된 모델은 create_model 함수에 의해 교육을받은 후 사용되도록 저장됩니다.
## 1.5 Model
import scipy . spatial
import pandas as pd
import numpy as np
import matplotlib . pyplot as plt
from tensorflow import keras
from tensorflow . keras . models import Sequential
from tensorflow . keras . layers import Dense
#from keras.utils.vis_utils import plot_model
% matplotlib inline
def model_features ( i , ii ):
model = Sequential ()
model . add ( Dense ( i , input_shape = ( 11 , ), activation = 'relu' , name = 'dense_1' ))
model . add ( Dense ( ii , activation = 'relu' , name = 'dense_2' ))
model . add ( Dense ( 1 , activation = 'linear' , name = 'dense_output' ))
model . compile ( optimizer = 'adam' , loss = 'mse' , metrics = [ 'mae' ])
model . summary ()
#plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)
#print(model.get_config())
return model
def create_model ( name ):
df = pd . read_csv ( name )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X )
y_train = np . array ( df [ df . columns [ - 1 ]])
model = model_features ( 64 , 128 )
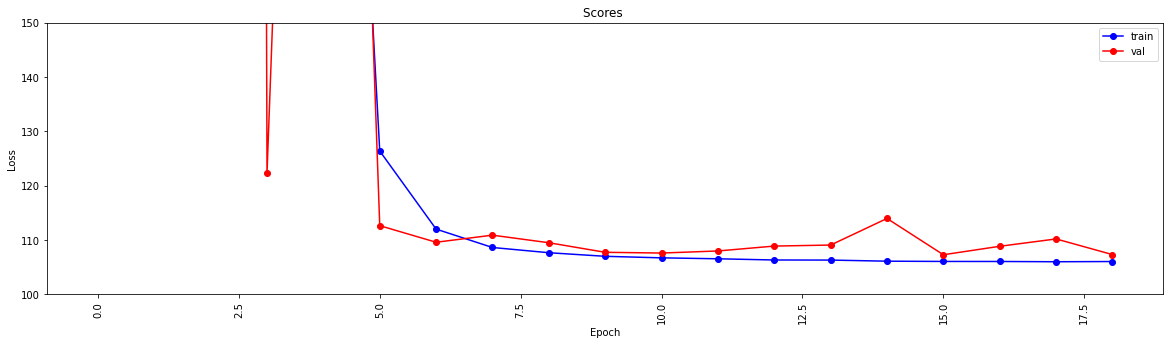
history = model . fit ( X_train , y_train , epochs = 19 , validation_split = 0.5 ) #,batch_size=1)
loss = history . history [ 'loss' ]
val_loss = history . history [ 'val_loss' ]
my_xticks = list ( range ( len ( loss )))
plt . figure ( figsize = ( 20 , 5 ))
plt . plot ( my_xticks , loss , linestyle = '-' , marker = 'o' , color = 'b' , label = "train" )
plt . plot ( my_xticks , val_loss , linestyle = '-' , marker = 'o' , color = 'r' , label = "val" )
plt . title ( "Scores " )
plt . legend ( numpoints = 1 )
plt . ylabel ( "Loss" )
plt . xlabel ( "Epoch" )
plt . xticks ( rotation = 90 )
plt . ylim ([ 100 , 150 ])
plt . show ()
madelname = "./THEMODEL"
model . save ( madelname )
print ( "Model Created!" )
이 기능은 교육 및 테스트 데이터가 기능 추출을 거쳤는지 확인합니다. 그렇지 않은 경우 해당 기능을 호출하여 이러한 파일과 모델을 생성합니다. 모델 및 모든 기능 추출을 처리 한 후 테스트 데이터를 형식화하여 최종 결과를 생성합니다.
## 1.6 Checking the inputs
from numpy import inf
from numpy import nan
def create_new_files ( train , test ):
model_path = "./THEMODEL/"
my_train_file = 'new_train_features.csv'
my_test_file = 'new_test_features.csv'
if os . path . isfile ( my_train_file ) :
pass
else :
print ( "Please wait! Training data feature extraction is in progress... n it will take about 10 minutes" )
feature_extraction_file ( train , my_train_file , 1 )
print ( "TThe training feature extraction completed!!!" )
if os . path . isfile ( my_test_file ) :
pass
else :
print ( "Please wait! Testing data feature extraction is in progress... n it will take about 100-120 minutes" )
feature_extraction_file ( test , my_test_file , 0 )
print ( "The testing feature extraction completed!!!" )
if os . path . isdir ( model_path ):
pass
else :
print ( "Please wait! Creating the deep learning model... n it will take about 10 minutes" )
create_model ( my_train_file )
print ( "The model file created!!! n n n " )
model = keras . models . load_model ( model_path )
df = pd . read_csv ( my_test_file )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X_train = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X_train )
y_train = np . array ( df [ df . columns [ - 1 ]])
predicted = model . predict ( X_train )
print ( "Please wait! Creating resuşts... " )
return predicted 이 단계에는 추출 및 모델 생성 프로세스가 특징이며 모든 프로세스가 시작될 수 있습니다. 따라서 test1_test.csv 파일의 IDS를 사용 하여이 지문 쌍의 추정 거리로 세 번째 (변위) 열을 채우고이 파일을 디렉토리에 이름 TASK1-MySubmission.csv 로 저장합니다.
## 1.7 Submission
distance_estimate = create_new_files ( train_data , test_ids )
count = 0
output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
output_data . append ([ id1 , id2 , distance_estimate [ count ][ 0 ]])
count += 1
print ( "Process finished. Preparing result file ..." )
with open ( "TASK1-MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )
print ( "The results are ready. n See MySubmission.csv" ) Please wait! Creating the deep learning model...
it will take about 10 minutes
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 64) 768
_________________________________________________________________
dense_2 (Dense) (None, 128) 8320
_________________________________________________________________
dense_output (Dense) (None, 1) 129
=================================================================
Total params: 9,217
Trainable params: 9,217
Non-trainable params: 0
_________________________________________________________________
Epoch 1/19
13748/13748 [==============================] - 30s 2ms/step - loss: 2007233.6250 - mae: 161.3013 - val_loss: 218.8822 - val_mae: 11.5630
Epoch 2/19
13748/13748 [==============================] - 27s 2ms/step - loss: 24832.6309 - mae: 53.9385 - val_loss: 123437.0859 - val_mae: 307.2885
Epoch 3/19
13748/13748 [==============================] - 26s 2ms/step - loss: 4028.0859 - mae: 29.9960 - val_loss: 3329.2024 - val_mae: 49.9126
Epoch 4/19
13748/13748 [==============================] - 27s 2ms/step - loss: 904.7919 - mae: 17.6284 - val_loss: 122.3358 - val_mae: 6.8169
Epoch 5/19
13748/13748 [==============================] - 25s 2ms/step - loss: 315.7050 - mae: 11.9098 - val_loss: 404.0973 - val_mae: 15.2033
Epoch 6/19
13748/13748 [==============================] - 26s 2ms/step - loss: 126.3843 - mae: 7.8173 - val_loss: 112.6499 - val_mae: 7.6804
Epoch 7/19
13748/13748 [==============================] - 27s 2ms/step - loss: 112.0149 - mae: 7.4220 - val_loss: 109.5987 - val_mae: 7.1964
Epoch 8/19
13748/13748 [==============================] - 26s 2ms/step - loss: 108.6342 - mae: 7.3271 - val_loss: 110.9016 - val_mae: 7.6862
Epoch 9/19
13748/13748 [==============================] - 26s 2ms/step - loss: 107.6721 - mae: 7.2827 - val_loss: 109.5083 - val_mae: 7.5235
Epoch 10/19
13748/13748 [==============================] - 27s 2ms/step - loss: 107.0110 - mae: 7.2290 - val_loss: 107.7498 - val_mae: 7.1105
Epoch 11/19
13748/13748 [==============================] - 29s 2ms/step - loss: 106.7296 - mae: 7.2158 - val_loss: 107.6115 - val_mae: 7.1178
Epoch 12/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.5561 - mae: 7.2039 - val_loss: 107.9937 - val_mae: 6.9932
Epoch 13/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.3344 - mae: 7.1905 - val_loss: 108.8941 - val_mae: 7.4530
Epoch 14/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.3188 - mae: 7.1927 - val_loss: 109.0832 - val_mae: 7.5309
Epoch 15/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.1150 - mae: 7.1829 - val_loss: 113.9741 - val_mae: 7.9496
Epoch 16/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.0676 - mae: 7.1788 - val_loss: 107.2984 - val_mae: 7.2192
Epoch 17/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0614 - mae: 7.1733 - val_loss: 108.8553 - val_mae: 7.4640
Epoch 18/19
13748/13748 [==============================] - 28s 2ms/step - loss: 106.0113 - mae: 7.1790 - val_loss: 110.2068 - val_mae: 7.6562
Epoch 19/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0519 - mae: 7.1791 - val_loss: 107.3276 - val_mae: 7.0981
INFO:tensorflow:Assets written to: ./THEMODELassets
Model Created!
The model file created!!!
Please wait! Creating resuşts...
100%|████████████████████████████████████████████████████████████████████| 5160445/5160445 [00:08<00:00, 610910.29it/s]
Process finished. Preparing result file ...
The results are ready.
See MySubmission.csv
우리는 이제 Wi -Fi 거리를 평가하기위한 메트릭이 있다는 점을 감안할 때 다음과 같은 작업은 쇼핑몰 (첫 번째 챌린지에 사용 된 다른 쇼핑몰부터 첫 번째 도전에 사용 된 쇼핑몰)을 분리하는 것입니다. 그러나 그래프 클러스터링 접근법을 강력하게 제안합니다.
데이터의 각 Wi -Fi 지문을 그래프의 노드로 고려하고 두 개의 지문을 유사하게 평가하여 그래프의 다른 지문으로 모서리를 형성 할 수 있습니다. 우리는 지문과 유사하지 않은 것 사이의 낮은 무게 (또는 가장자리가 없음) 사이에 높은 유사성을 가진 가장자리에 높은 무게를 할당 할 수 있습니다. 이론적으로, 완벽하게 정확한 유사성 메트릭은 약 4 미터 이상의 모든 가장자리를 배제 할 수 있기 때문에 사소하게 바닥을 분리 할 것입니다 (대략 건물의 1 층 높이). 실제로 우리는 바닥 사이에 잘못된 가장자리를 만들 것이며 어떻게 든이 가장자리를 깨뜨려야 할 것입니다.
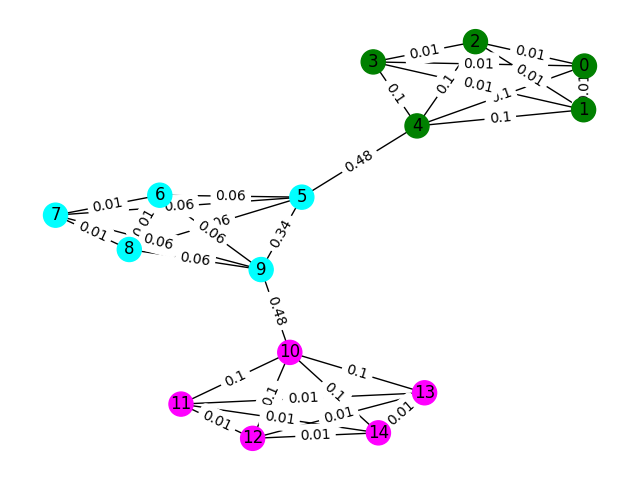
간단한 예로 시작하겠습니다. 노드 색상이 지문의 실제 바닥 분류를 나타내는 아래의 그래프를 고려하고 가장자리는 이러한 노드가 같은 바닥에 존재한다고 생각한다는 것을 반영합니다. 이 연습을 위해 우리는 "사이의 점수"로 각 모서리를 미리 표시했습니다. 그래프의 두 노드 사이에서 가장 짧은 경로를 가져 와서이 가장자리가 몇 번이나 걸어가는 지표입니다. 일반적으로 이것은 높은 연결성을 나타내고 제거의 후보가 될 수있는 가장자리를 나타냅니다.
이 예에서는 Edge-Betweenness Score를 사용하여 그래프 커뮤니티를 감지하십시오. 각 하위 목록에 커뮤니티의 노드 ID가 포함 된 목록 목록을 반환하십시오. 이것은 단지 문제에 대한 이해를 돕고 실제 솔루션을 포함하지는 않습니다.
def detect_communities ( Graph ):
## This function should return a list of lists containing
## the node ids of the communities that you have detected.
eb_score = nx . edge_betweenness_centrality ( G )
raise NotImplementedError import networkx as nx
from metrics import check_result
G = nx . read_adjlist ( "graph.adjlist" )
communities = detect_communities ( G )
if check_result ( communities ):
print ( "Correct!" )
else :
print ( "Try again" ) 이 문제에 대한 샘플 교육 데이터는 106981 지문 ( task2_train_fingerprints.json )과 그 사이의 일부 가장자리 세트입니다. 우리는 세 가지 다른 에지 유형을 나타내는 파일을 제공했으며, 모두 다르게 처리해야합니다.
task2_train_steps.csv 궤적 내에서 후속 단계를 연결하는 가장자리를 나타냅니다. 이 가장자리는 같은 바닥에서 두 개의 지문이 기록되었다는 확실성을 나타 내기 때문에 매우 신뢰해야합니다.
task2_train_elevations.csv 단계의 반대를 나타냅니다. 이 고도는 지문이 거의 다른 바닥에서 나온다는 것을 나타냅니다. 따라서 지문 인 경우이를 외삽 할 수 있습니다
task2_train_estimated_wifi_distances.csv 는 자체 거리 메트릭을 사용하여 계산 한 사전 계산 거리입니다. 이 메트릭은 불완전하며, 따라서 우리는 이러한 가장자리의 많은 부분이 잘못 될 것이라는 것을 알고 있습니다 (즉, 2 층을 함께 연결할 것입니다). We suggest that initially you use the edges in this file to construct your initial graph and compute some solution. However, if you get a high score on task1 then you might consider computing your own wifi distances to build a graph.
그래프는 궤적 수준 또는 지문 수준의 두 가지 수준 중 하나 일 수 있으므로 사용하려는 표현을 선택할 수 있지만 궁극적으로 궤적 클러스터를 알고 싶습니다. 궤적 수준은 모든 노드를 궤적으로, 궤적의 지문이 높은 시뮬레이션이있는 경우 노드 사이의 가장자리가 발생합니다. 지문 수준은 각 지문을 노드로 사용합니다. task2_train_lookup.json 을 사용하여 지문의 궤적 ID를 조회하여 표현간에 변환 할 수 있습니다.
솔루션을 디버깅하고 훈련시키는 데 도움이되도록 task2_train_GT.json 의 일부 궤적에 대한 근거 진실을 제공했습니다. 이 파일에서 키는 궤적 ID ( task2_train_lookup.json 과 동일)이며 값은 건물의 실제 바닥 ID입니다.
테스트 세트는 훈련 세트와 정확히 동일한 형식입니다 (별도의 건물의 경우 우리는 그것을 쉽게 만들지 않을 것입니다;)) 그러나 우리는 동등한 지상 진실 파일을 포함하지 않았습니다. 이를 통해 솔루션을 평가할 수 있습니다.
고려해야 할 사항
이 섹션에서는 파일을 열고 두 가지 유형의 그래프를 구성하는 몇 가지 예제 코드를 제공합니다.
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/train"
with open ( os . path . join ( path_to_data , "task2_train_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_train_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_train_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_train_lookup.json" )
gt_path = os . path . join ( path_to_data , "task2_train_GT.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f )
with open ( gt_path ) as f :
gt = json . load ( f )
이것은 그래프의 각 노드가 지문 인 지문 수준 그래프를 구성하는 한 가지 방법입니다. 우리는 WiFi 및 PDR 모서리의 추정/실제 거리에 해당하는 가장자리 가중치를 추가했습니다. 우리는 또한이 관계를 나타 내기 위해 고도 가장자리를 추가했습니다. 솔루션을 개발할 때 이러한 가장자리 (또는 궤적 사이에 유효한 고도 가장자리) 가 없음 을 명시 적으로 시행 할 수 있습니다.
G = nx . Graph ()
for id1 , id2 , dist in tqdm ( steps ):
G . add_edge ( id1 , id2 , ty = "s" , weight = dist )
for id1 , id2 , dist in tqdm ( wifi ):
G . add_edge ( id1 , id2 , ty = "w" , weight = dist )
for id1 , id2 in tqdm ( elevs ):
G . add_edge ( id1 , id2 , ty = "e" )궤적 그래프는 궤적 사이의 많은 Wi -Fi 연결을 나타내는 방법을 생각 해야하는 것만 큼 간단하지 않습니다. 아래의 예제 그래프에서 우리는 평균 거리를 무게로 취하지 만 이것이 정말로 가장 좋은 표현입니까?
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])제출물은 같은 층에 있다고 생각되는 궤적이 쉼표로 분리 된 동일한 행에 색인을 갖는 CSV 파일이어야합니다. 각 새 클러스터는 새 행에 입력됩니다.
예를 들어, 아래 임의의 항목을 참조하십시오.
import random
random_data = []
n_clusters = random . randint ( 50 , 100 )
for i in range ( 0 , n_clusters ):
random_data . append ([])
for traj in set ( fp_lookup . values ()):
cluster = random . randint ( 0 , n_clusters - 1 )
random_data [ cluster ]. append ( traj )
with open ( "MyRandomSubmission.csv" , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( random_data )작업 2의 단계는 다음과 같이 요약 할 수 있습니다.
Node2vec 사용하여 벡터화됩니다.TASK2-Mysubmission.csv )은 ID의 궤적에 따라 준비됩니다.이 단계는 아래 이미지에 설명되어 있습니다.

Python 3.6.5를 사용하여 응용 프로그램 파일을 만들었습니다. 경쟁 시작시 주어진 예제 파일에 포함되지 않은 몇 가지 추가 모듈이 포함되었습니다. 이 모듈은 다음과 같이 나열 될 수 있습니다.
| 몰 룰레스 | 일 |
|---|---|
| Scikit-Learn | 머신 러닝 및 데이터 준비 |
| node2vec | 네트워크를위한 확장 가능한 기능 학습 |
| Numpy | 수학적 작업 |
우리는이 모듈을 첫 번째 단계로 설치하는 것으로 시작했습니다.
## 2.1 Installing modules
!p ip install node2vec
!p ip install scikit - learn
!p ip install numpy 이 단계에서는 반복 가능한 결과를 얻기 위해 사용될 관련 랜덤 시드를 수정했습니다. 이런 식으로, 우리는 모든 달리기에서 동일한 결과를 얻는 결정 론적 경로를 제공했습니다. 그러나 우리의 관찰에 따르면, 다른 컴퓨터에서 얻은 결과는 약간 다를 수 있습니다 (± 1%)
## 2.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )이 섹션에서는 테스트 데이터에 주어진 파일이로드됩니다.
wifi 변수는 task2_test_estimated_wifi_distances.csv 에서 ID와 가중치를 취합니다.steps 변수는 파일 task2_test_steps.csv 에서 ID와 가중치를 취합니다.elevs 변수는 파일 task2_test_elevations.csv 에서 ID를 가져옵니다.fp_lookup 변수 task2_test_lookup.json 파일에서 ID 및 궤적을 가져옵니다. 우리는이 프로세스에서 얻은 결과가 큰 차이를 만들지 않았기 때문에 WIFI에서 우리가 얻은 모델로 WiFi에서 주어진 추정 거리를 다시 계산하는 방법을 선호하지 않았습니다. 그렇기 때문에 궁극적 인 작업에서 task2_test_fingerprints.json 파일을 사용하지 않았습니다.
## 2.3 Loading the data
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/test"
with open ( os . path . join ( path_to_data , "task2_test_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_test_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_test_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_test_lookup.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f ) 3773297it [00:19, 191689.25it/s]
2767it [00:00, 52461.27it/s]
139537it [00:00, 180082.01it/s]
궤적 그래프를 만들 때 평균 거리를 가중치로 취합니다. 이 프로세스에 대해 Task 2 ( Task2-IPS-Challenge-2021.ipynb )에 대한 예제를 사용했습니다. 결과 그래프 ( B )를 디렉토리의 인접력 목록 ( my.adjlist )으로 저장했습니다.
## 2.3 Generating the Trajectory graph.
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])
nx . write_adjlist ( B , "my.adjlist" ) 100%|████████████████████████████████████████████████████████████████████| 3773297/3773297 [00:27<00:00, 135453.95it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████| 2767/2767 [00:00<?, ?it/s]
인접성 목록을 기계 학습 알고리즘에 입력하기 전에 노드를 벡터로 변환합니다. 우리의 작업에서 우리는 2016 년 Grover & Leskovec가 제안한 그래프 임베딩 알고리즘 방법론으로 Node2Vec을 사용했습니다 [3]. Node2Vec은 네트워크의 노드에 대한 기능 학습을위한 반 감독 알고리즘입니다. Node2Vec은 분포 구조 개념에 동기를 부여한 NLP 접근법 인 Skip-Gram 기술을 기반으로 작성됩니다. 아이디어에 동기를 부여합니다. 비슷한 맥락에서 사용 된 다른 단어가 아마도 비슷한 의미를 가지고 있으며 그들 사이에 명백한 관계가 있습니다. Skip-Gram Technique는 중심 단어 (입력)를 사용하여 이웃 (출력)을 예측하는 동안 주어진 창 크기 (중앙 이후의 항목 순서)를 기반으로 주변 환경의 확률을 계산합니다. 즉, N-Grams. NLP 접근법과 달리 Node2Vec 시스템에는 선형 구조가있는 단어가 아니라 그래픽 구조가 분산 된 노드 및 모서리가 공급됩니다. 이 다차원 구조는 임베딩을 복잡하고 계산적으로 비싸게 만들지 만 Node2VEC는 SGD (schancatic Gradient Descent) 최적화와 함께 음의 샘플링을 사용하여이를 처리합니다. 이 외에도, 랜덤 워크 접근법은 비선형 구조에서 소스 노드의 인접 노드를 감지하는 데 사용됩니다.
우리의 연구에서, 우리는 먼저 2 개의 노드 (가중치)의 주어진 거리에서 Node2VEC로 모델링하여 저 차원 공간에서 노드 관계의 벡터 표현을 수행했습니다. 그런 다음 노드 벡터가있는 Node2Vec (그래프 임베드)의 출력을 사용하여 전통적인 k- 평균 클러스터링 알고리즘을 공급했습니다.
NOD2VEC에서 사용하는 매개 변수는 다음과 같이 나열 될 수 있습니다.
| 초 파라미터 | 값 |
|---|---|
| 치수 | 32 |
| walk_length | 15 |
| num_walks | 100 |
| 노동자 | 1 |
| 씨앗 | 0 |
| 창문 | 10 |
| min_count | 1 |
| batch_words | 4 |
Node2Vec 모델은 인접성 목록을 입력으로 가져와 32 크기의 벡터를 출력합니다. 이 부분에서는 Node.py 파일이 Jupyter Notebook 에서 생성되어 실행됩니다. Jupyter 노트북 셀이 아닌 외부에서 실행하는 것이 바람직한 두 가지 이유가 있습니다.
Node2vec 은 계산적으로 비싼 방법이며 Jupyter 노트북 내부에서 실행되면 RAM 오버플로 오류가 가능합니다. Node2vec 모델을 생성하고 실행하면이 오류가 피할 수 있습니다. 아래 셀은 node.py라는 파일을 만듭니다. 이 파일은 Node2Vec 모델을 만듭니다. This model takes the the adjacency list ( my.adjlist ) as input and creates a 32-dimensional vector file as output ( vectors.emb ).
중요한! 아래 코드는 Linux 배포판 (Google Colab 및 Ubuntu에서 테스트)에서 실행해야합니다.
# 2.4 Converting nodes to vectors
# A folder named tmp is created. This folder is essential for the node2vec model to use less RAM.
try :
if not os . path . exists ( "tmp" ):
os . makedirs ( "tmp" )
except OSError :
print ( "The folder could not be created! n Please manually create the " tmp " folder in the directory" )
node = """
# importing related modules
from node2vec import Node2Vec
import networkx as nx
#importing adjacency list file as B
B = nx.read_adjlist("my.adjlist")
seed_value=0
# Specifying the input and hyperparameters of the node2vec model
node2vec = Node2Vec(B, dimensions=32, walk_length=15, num_walks=100, workers=1,seed=seed_value,temp_folder = './tmp')
#Assigning/specifying random seeds
import os
os.environ['PYTHONHASHSEED']=str(seed_value)
import random
random.seed(seed_value)
import numpy as np
np.random.seed(seed_value)
# creation of the model
model = node2vec.fit(window=10, min_count=1, batch_words=4,seed=seed_value)
# saving the output vector
model.wv.save_word2vec_format("vectors.emb")
# save the model
model.save("vectorMODEL")
"""
f = open ( "node.py" , "w" )
f . write ( node )
f . close ()
! PYTHONHASHSEED = 0 python3 node . py 벡터 파일이 생성 된 후이 파일 ( vectors.emb )을 읽습니다. 이 파일은 33 개의 열로 구성됩니다. 첫 번째 열은 노드 번호 (IDS)이며 벡터 값은 남아 있습니다. 첫 번째 열로 전체 파일을 정렬하면 노드를 원래 순서로 반환합니다. 그런 다음이 ID 열을 삭제하고 더 이상 사용할 수 없습니다. 그래서 우리는 데이터의 최종 모양을 제공합니다. 당사의 데이터는 기계 학습 애플리케이션에 사용할 준비가되었습니다.
# 2.4 Reshaping data
vec = np . loadtxt ( "vectors.emb" , skiprows = 1 )
print ( "shape of vector file: " , vec . shape )
print ( vec )
vec = vec [ vec [:, 0 ]. argsort ()];
vec = vec [ 0 : vec . shape [ 0 ], 1 : vec . shape [ 1 ]] shape of vector file: (11162, 33)
[[ 9.1200000e+03 3.9031842e-01 -4.7147268e-01 ... -5.7490986e-02
1.3059708e-01 -5.4280665e-02]
[ 6.5320000e+03 -3.5591956e-02 -9.8558587e-01 ... -2.7217887e-02
5.6435770e-01 -5.7787680e-01]
[ 5.6580000e+03 3.5879680e-01 -4.7564098e-01 ... -9.7607370e-02
1.5506668e-01 1.1333219e-01]
...
[ 2.7950000e+03 1.1724627e-02 1.0272172e-02 ... -4.5596390e-04
-1.1507459e-02 -7.6738600e-04]
[ 4.3380000e+03 1.2865483e-02 1.2103912e-02 ... 1.6619096e-03
1.3672550e-02 1.4605848e-02]
[ 1.1770000e+03 -1.3707868e-03 1.5238028e-02 ... -5.9994194e-04
-1.2986251e-02 1.3706315e-03]]
Task-2는 클러스터링 문제입니다. 이 문제를 해결할 때 결정해야한다는 전제는 우리가 얼마나 많은 클러스터를 나누어야하는지입니다. 이를 위해 다른 클러스터 번호를 시도하고 얻은 점수를 비교했습니다. 아래 그래프는 클러스터 수와 얻은 점수의 비교를 보여줍니다. 이 그래프에서 볼 수 있듯이, 클러스터의 수는 5와 21 사이에 지속적으로 증가했으며, 일부 예외 변동은 21 개 후에 안정화되었습니다. 이러한 이유로, 우리는 연구에서 21에서 23 사이의 클러스터 수에 중점을 두었습니다.
# 2.5 Determine the number of clusters
import numpy as np
import matplotlib . pyplot as plt
import seaborn as sns
import matplotlib
% matplotlib inline
sns . set_style ( "whitegrid" )
agglom = [ 24.69 , 28.14 , 28.14 , 28.14 , 30 , 33.33 , 40.88 , 38.70 , 40 , 40 , 40 , 29.12 , 45.85 , 45.85 , 48.00 , 50.17 , 57.83 , 57.83 , 57.83 ]
plt . figure ( figsize = ( 10 , 5 ))
plt . plot ( range ( 5 , 24 ), agglom )
matplotlib . pyplot . xticks ( range ( 5 , 24 ))
plt . title ( 'Number of clusters and performance relationship' )
plt . xlabel ( 'Number of clusters' )
plt . ylabel ( 'Score' )
plt . show ()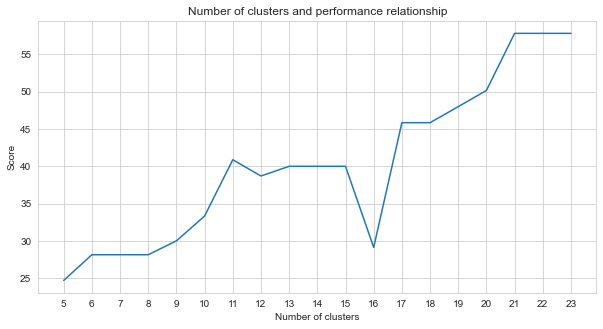
우리가 시도한 감독되지 않은 기계 학습 방법 중 (예 : K- 평균, 응집 클러스터링, 친화력 전파, 평균 이동, 스펙트럼 클러스터링, DBSCAN, 광학, 자작 나무, 미니 배치 K- 평균), 우리는 K- 평균을 사용하여 최고의 결과를 달성했습니다. 23 개의 클러스터가 있습니다.
K-Means는 클러스터링 알고리즘은 기본적이고 전통적인 감독 기계 학습 기술 중 하나입니다. 클러스터는 특정 유사성을 공유하는 포인트 (데이터의 노드)를 함께 그룹화하는 것입니다. K- 평균은 데이터가 나누어야하는 그룹의 수를 나타내는 대상 수의 중심 수가 필요합니다. 알고리즘은 무작위로 할당 된 중심 그룹으로 시작한 다음 반복을 계속하여 최상의 위치를 찾습니다. 이 알고리즘은 포인트 구성원의 정사각형을 클러스터 내로 사용하여 지점/노드를 지정된 중심에 할당합니다. 이는 계속 업데이트하고 재배치됩니다 [4]. 이 예에서 중심 수는 바닥 수를 반영합니다. 이것은 바닥의 순서에 대한 정보를 제공하지 않는다는 점에 유의해야합니다.
아래에서 K- 평균 응용 프로그램은 23 개의 클러스터에 대해 작성되었습니다.
# 2.5 Best result
from sklearn import cluster
import time
ML_results = []
k_clusters = 23
algorithms = {}
algorithms [ 'KMeans' ] = cluster . KMeans ( n_clusters = k_clusters , random_state = 10 )
second = time . time ()
for model in algorithms . values ():
model . fit ( vec )
ML_results = list ( model . labels_ )
print ( model , time . time () - second ) KMeans(n_clusters=23, random_state=10) 1.082334280014038
기계 학습 알고리즘의 출력은 지문이 속한 클러스터를 결정합니다. 그러나 우리에게 필요한 것은 궤적을 클러스터링하는 것입니다. 따라서 이러한 지문은 fp_lookup 변수를 사용하여 궤적 상대로 변환됩니다. 이 출력은 TASK2-Mysubmission.csv 파일로 처리됩니다.
## 2.6 Submission
result = {}
for ii , i in enumerate ( set ( fp_lookup . values ())):
result [ i ] = ML_results [ ii ]
ters = {}
for i in result :
if result [ i ] not in ters :
ters [ result [ i ]] = []
ters [ result [ i ]]. append ( i )
else :
ters [ result [ i ]]. append ( i )
final_results = []
for i in ters :
final_results . append ( ters [ i ])
name = "TASK2-Mysubmission.csv"
with open ( name , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( final_results )
print ( name , "file is ready!" ) TASK2-Mysubmission.csv file is ready!
[1] P. Virtanen 및 Scipy 1.0 기고자. Scipy 1.0 : Python의 과학 컴퓨팅을위한 기본 알고리즘. 자연 방법, 17 : 261-272, 2020.
[2] A. Geron, Scikit-Learn, Keras 및 Tensorflow와의 실습 기계 학습 : 지능형 시스템을 구축하기위한 개념, 도구 및 기술. O'Reilly Media, 2019
[3] A. Grover, J. Leskovec. ACM SIGKDD 지식 발견 및 데이터 마이닝에 관한 국제 회의 (KDD), 2016.
[4] Jin X., Han J. (2011) K-Means 클러스터링. 에서 : Sammut C., Webb GI (eds) 기계 학습 백과 사전. Springer, Boston, MA. https://doi.org/10.1007/978-0-387-30164-8_425


