Noise Reduction
1.0.0

프로젝트에 대해
기술 스택
파일 구조
시작하기
결과와 데모
미래의 일
기고자
감사와 자원
특허
제거 해야하는 노이즈를 제거해야했으며 신호를 비난하면서 제거되는 비 환경 노이즈처럼 자연스럽게 유도됩니다. 이 문서를 참조하여 AI 노이즈 감소에 대한이 블로그도 참조하십시오.
오디오 관리를위한 Librosa 라이브러리가 사용됩니다.
오디오 신호의 경우 Scipy를 사용했습니다
MATPLOTLIB 데이터를 조작하고 신호를 시각화하는 데 사용되었습니다.
나머지는 수학 연산의 경우 멍청하고 웨이브 파일에서 작동하기위한 웨이브입니다.
Noise Reduction ├───docs ## Documents and Images │ └───Input Audio file ├─── Project Details │ | │ ├─── │ │ ├───Research papers │ │ ├───Linear Algebra │ │ ├───Neural networks & Deep Learning │ │ ├───Project Documentation │ │ ├───AI Noise Reduction Blog │ │ ├───AI Noise Reduction Report │ │ └───Code Implementation │ │ ├───AI Noise Reduction.py │ │ ├───audio.wav │ │ ├───Resources
Windows에서 테스트되었습니다
git 클론 https://github.com/dhriti03/noise-plection.gitcd 소음-감소
노트북에 특정 라이브러리를 설치하십시오
파이프 설치 웨이브 PIP 설치 Librosa PIP 설치 Scipy.io PIP 설치 MATPLOTLIB.PYPLOT
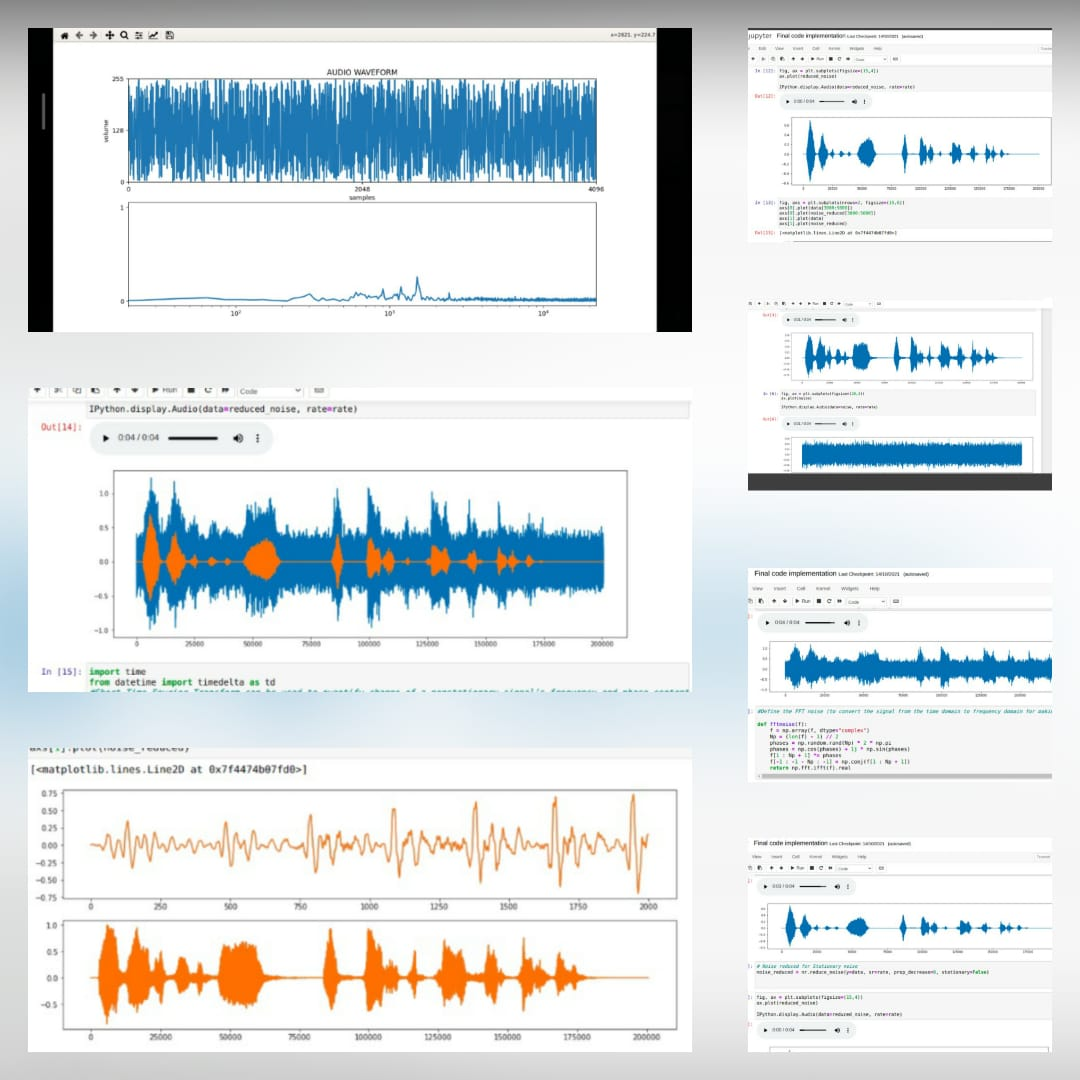
*이것은 원래 오디오 파일입니다 * 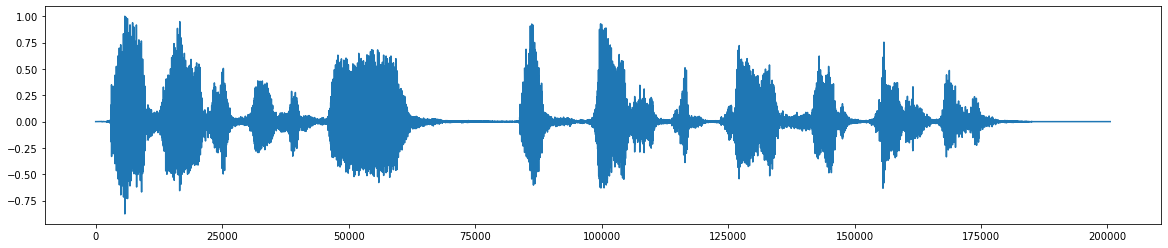 *소음 추가 후 *
*소음 추가 후 * 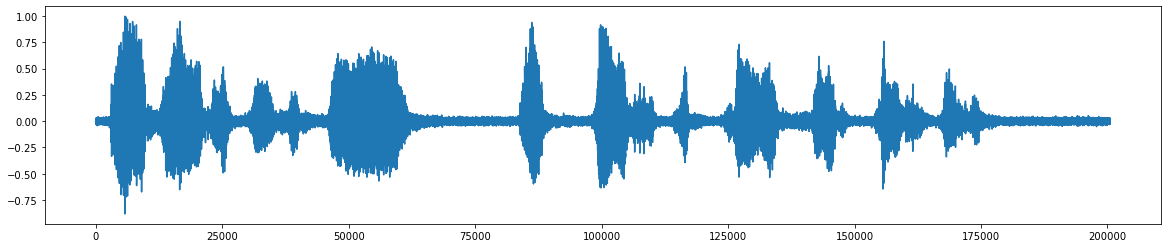 *노이즈 제거 후 최종 오디오 신호 *
*노이즈 제거 후 최종 오디오 신호 *  *프로젝트의 유량 차트 *
*프로젝트의 유량 차트 * 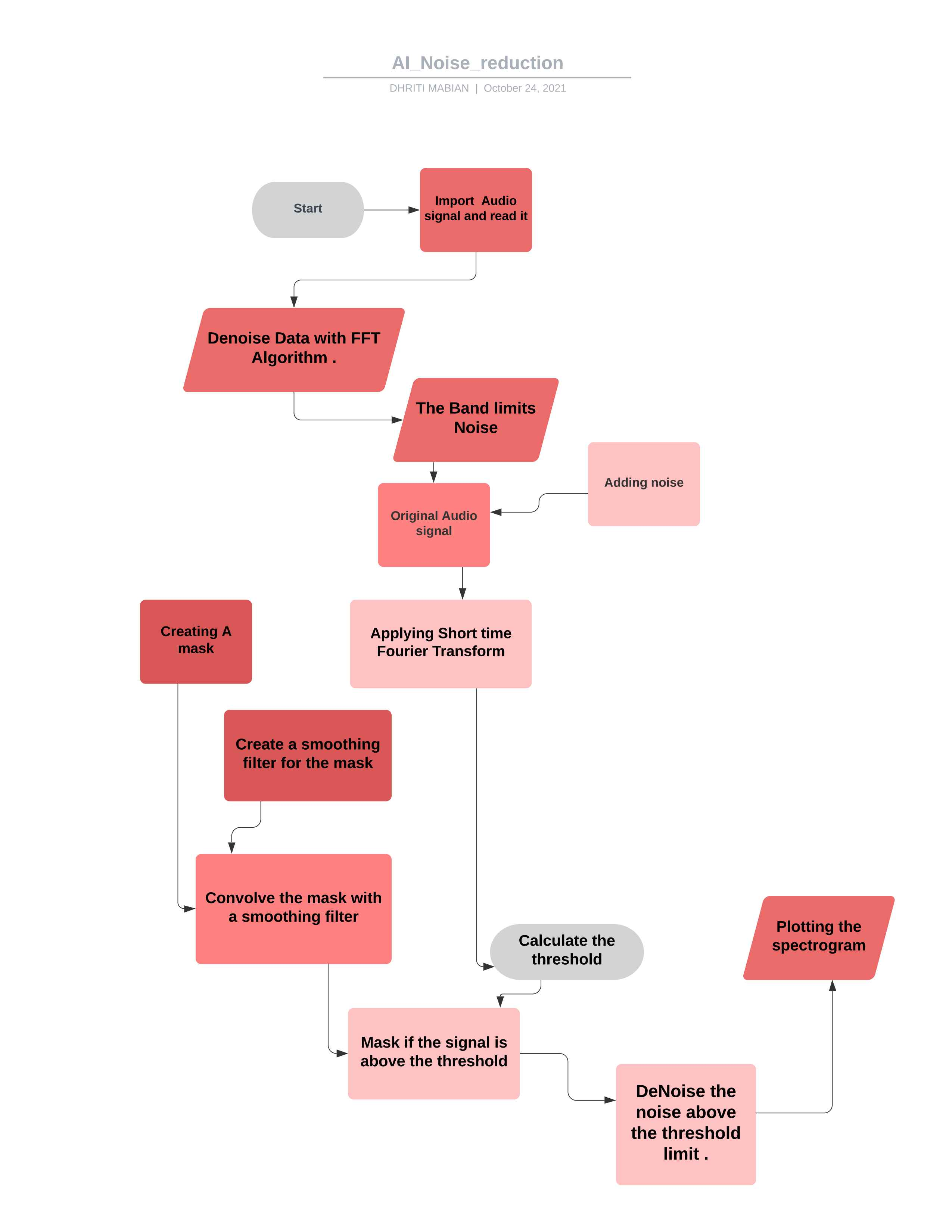
요구 사항에 따라 코드를 조작 할 때 대부분의 오디오 부호를 제어하는 데 코드를 사용할 수 있습니다. ##이론
FFT는 노이즈 오디오 클립을 통해 계산됩니다
통계는 노이즈의 FFT (주파수)에 대해 계산됩니다.
임계 값은 노이즈 통계에 따라 계산됩니다 (및 알고리즘의 원하는 감도)
마스크는 신호 FFT를 임계 값과 비교하여 결정됩니다.
마스크는 주파수와 시간에 대한 필터로 매끄 럽습니다.
마스크는 신호의 FFT에 적용되며 반전됩니다.
scipy.io에서 Ippython import wavfileimport scipy.signalimport numpy npimport matplotlib.pyplot pltimport librosaimport wave%matplotlib inline
여기서 우리는 대화식 및 탐색 적 컴퓨팅을위한 포괄적 인 환경을 만들기 위해 사용되는 ipython lib와 같은 라이브러리를 가져오고 있습니다.
Scipy.io 에서 라이브러리는 광범위한 Python 명령을 사용하여 데이터를 조작하고 데이터를 시각화하는 데 사용됩니다.
Numpy에는 다차원 배열 및 매트릭스 데이터 구조가 포함되어 있습니다. 삼각형, 통계 및 대수 루틴과 같은 배열에서 다수의 수학 연산을 수행하는 데 활용 될 수 있으므로 매우 유용한 라이브러리입니다.
matplotlib.pyplot 라이브러리는 다양한 시각화를 통해 막대한 양의 데이터를 이해하는 데 도움이됩니다.
Librosa는 음악 생성 (LSTM 사용), 자동 음성 인식과 같은 오디오 데이터를 사용할 때 사용됩니다. 음악 정보 검색 시스템을 만드는 데 필요한 빌딩 블록을 제공합니다.
%matplotlib 인라인 인라인 플로팅을 활성화하려면 플롯/그래프가 플로팅 명령이 작성된 셀 바로 아래에 표시됩니다. Jupyter 노트북과 같은 프론트 엔드의 백엔드와 상호 작용을 제공합니다.
wav_loc = r '/home/noise_reduction/downloads/wave/file.wav'rate, data = wavfile.read (wav_loc, mmap = false)
여기서 WAW 파일 경로 위치를 취한 다음 Scipy.io 라이브러리에서 나온 Wawfile 모듈이있는 WAW 파일을 읽습니다. 매개 변수 (filename- 문자열 또는 입력 wav 파일 인 파일 핸들 열린 파일 핸들.
def fftnoise (f) : f = np.array (f, dtype = "complex") np = (len (f) -1) // 2phaes = np.random.rand (np) * 2 * np.paithases = np .COS (위상) + 1J * NP.SIN (위상) F [1 : NP + 1] * = PHASESF [-1 : -1- NP : -1] = NP.conj (F [1 : NP + 1] ) np.fft.ifft (f) .real을 반환합니다
여기서 우리는 먼저 FFT 노이즈 함수를 짧게 정의합니다. FFT (Fast Fourier Transform)는 시퀀스의 DFT (Decrete Fourier Transform) 또는 그 역 (IDFT)을 계산하는 알고리즘입니다. 푸리에 분석은 원래 도메인 (종종 시간 또는 공간)에서 신호를 주파수 영역의 표현으로 변환하고 그 반대도 마찬가지입니다. DFT는 일련의 값을 상이한 주파수의 구성 요소로 분해함으로써 얻어진다.
빠른 푸리에 변환을 사용하고 데이터 유형 복합체의 함수를 정의하고 최종적으로 기능의 실제 부분을 계산합니다. 이에서는 최소 주파수와 최대 주파수 사이의 범위 범위가 1으로 설정되고 원치 않는 욕실은 무시됩니다.
파일 위치 제공
WAV 파일을 읽습니다
-32767 ~ +32767은 적절한 오디오 (대칭 적)이며 32768은 오디오가 그 시점에서 클리핑되었음을 의미합니다.
Wav-file은 16 비트 정수이고, 범위는 [-32768, 32767]이므로 32768 (2^15)으로 나누어진다.
def band_limited_noise (min_freq, max_freq, 샘플 = 1024, samplerate = 1) : freqs = np.abs (np.fft.fftfreq (샘플, 1 / samplerate)) f = np.zeros (샘플) f [np.lodical_and (freqs) > = min_freq, freqs <= max_freq)] = 1 return fftnoise (f)
푸리에 변환이 유한 주파수 또는 파장으로 제한되는 함수 또는 시계열.
최소 및 최대 한계를 사용하여 표준 FREQ로 FREQ를 정의합니다.
NOISE_LEN = 2 # SECONDSNOISE = BAND_LIMITED_NOISE (min_freq = 4000, max_freq = 12000, 샘플 = len (data), samplerate = rate)*10noise_clip = 노이즈 [: rate*noise_len] audio_clip_band_limited = 데이터+노이즈
대역 제한 화이트 노이즈 블록은 장치가 Hz 인 양면 스펙트럼을 지정합니다.
최대 12000과 4000의 최소 Freq가 노이즈와 제공된 데이터를 비교하는 경우.
여기서 우리는 속도와 노이즈 신호의 렌을 가짐으로써 노이즈 신호를 클립하고 있습니다.
따라서 노이즈와 주어진 데이터를 추가합니다
사실상 노이즈 추가는 훈련 데이터 세트의 크기를 확장합니다.
랜덤 노이즈는 입력 변수에 추가되어 모델에 노출 될 때마다 다르게 다릅니다.
입력 샘플에 노이즈를 추가하는 것은 간단한 형태의 데이터 증강입니다.
노이즈를 추가하면 네트워크가 항상 변경되기 때문에 훈련 샘플을 외울 수 없다는 것을 의미합니다.
더 작은 네트워크 가중치와 일반화 오류가 낮은 더 강력한 네트워크를 만듭니다.
DATETIME IMPORTIM에서 Timedelta를 TD로 가져 오기 시간
가져 오기 시간 이 모듈은 다양한 시간 관련 기능을 제공합니다. 관련 기능은 DateTime 및 Calendar 모듈도 참조하십시오. 클래스 datetime.timedelta
두 날짜, 시간 또는 데이터 타임 인스턴스의 마이크로 초 분해능의 차이를 표현하는 지속 시간.
def _stft (y, n_fft, hop_length, win_length) : return librosa.stft (y = y, n_fft = n_fft, hop_length = hop_length, win_length = win_length)
짧은 시간 푸리에 변환을 사용하여 시간이 지남에 따라 비 정지 신호의 빈도 및 위상 함량의 변화를 정량화 할 수 있습니다.
홉 길이는 연속 프레임 사이의 샘플 수를 참조해야합니다. 신호 분석의 경우 홉 길이가 프레임 크기보다 작아 프레임이 겹치도록합니다.
매개 변수 ynp.ndarray [shape = (n,)], 실제 값 입력 신호
n_fftint> 0 [스칼라]
0으로 패딩 한 후 창문 신호의 길이. STFT 행렬 D의 행 수는 (1 + N_FFT/2)입니다 . 기본값 인 N_FFT = 2048 샘플은 22050 Hz의 샘플 속도에서 93 밀리 초의 물리적 지속 시간에 해당합니다. 즉, Librosa의 기본 샘플 속도입니다. 이 값은 음악 신호에 적합합니다. 그러나 음성 처리에서 권장 값은 512로, 22050Hz의 샘플 속도로 23 밀리 초에 해당합니다. 어쨌든 FFT (Fast Fourier Transform) 알고리즘의 속도를 최적화하기 위해 N_FFT를 2의 전력으로 설정하는 것이 좋습니다.
Hop_Lengthint> 0 [스칼라]
인접한 STFT 열 사이의 오디오 샘플 수.
작은 값은 STFT의 주파수 분해능에 영향을 미치지 않으면 서 D의 열 수를 증가시킵니다.
지정되지 않은 경우 기본값은 Win_Length // 4로 나타납니다 (아래 참조).
win_lengthint <= n_fft [스칼라]
오디오의 각 프레임은 길이 Win_length의 창으로 창으로 창으로 표시되며 N_FFT 와 일치하도록 0으로 패딩합니다.
작은 값은 주파수 분해능을 희생시키면서 STFT의 시간적 해상도를 향상시킵니다 (즉, 주파수 분해능을 희생시키면서 (즉, 주파수가 밀접하게 간격을 두는 순수한 톤을 구별하는 능력). 이 효과는 시간 주파수 현지화 트레이드 오프로 알려져 있으며 입력 신호 y의 특성에 따라 조정해야합니다.
지정되지 않은 경우, 기본값은 win_length = n_fft 입니다.
return librosa.istft (y, hop_length, win_length)
역시 단기 푸리에 변환 (ISTFT).
일반적으로 창 함수, 홉 길이 및 기타 매개 변수는 STFT와 동일해야하며, 이는 수정되지 않은 STFT_MATRIX로부터 신호를 완벽하게 재구성하게한다.
def _amp_to_db (x) : return librosa.core.amplitude_to_db (x, ref = 1.0, amin = 1e-20, top_db = 80.0)
1. 진폭 스펙트로 그램을 DB 스케일 스펙트로 그램으로 전환합니다. 이는 Power_To_DB (S ** 2)와 동일하지만 편의를 위해 제공됩니다.
return librosa.core.db_to_amplitude (x, ref = 1.0)
DB 스케일 스펙트로 그램을 진폭 스펙트로 그램으로 변환하십시오.
이것은 효과적으로 admplitude_to_db를 반전합니다.
db_to_amplitude (s_db) ~ = 10.0 (0.5* (s_db + log10 (ref)/10)) **
def plot_spectrogram (신호, 제목) : fig, ax = plt.subplots (figsize = (20, 4)) cax = ax.matshow (신호, origin = "lower", agage = "auto", cmap = plt.cm. 지진, vmin = -1 * np.max (np.abs (신호)), vmax = np.max (np.abs (신호)),
)입력으로 신호를 사용하여 스펙 토 그램을 플로팅합니다.
Axes 클래스에는 Axis, Tick, Line2d, Text, Polygon 등의 대부분의 그림 요소가 포함되어 있으며 좌표계를 설정합니다.
이 기능을 통해 액세스 할 수있는 Matplotlib의 여러 컬러 맵을 제공합니다.
그림 Colorbar (CAX) AX.SET_TITLE (제목)
무슨 일이 일어나고 있는지 확인하는 가장 좋은 방법은 컬러 바 (산점도를 작성한 후 plt.colorbar ())를 추가하는 것입니다. 0에서 10000 사이의 아웃 값은 모두 막대의 가장 낮은 부분보다 낮으며, 여기서 물건은 매우 녹색입니다.
일반적으로 VMIN 미만의 값은 가장 낮은 색상으로 채색되며 Vmax 위의 값은 가장 높은 색상을 얻습니다.
VMIN보다 VMAX를 더 작게 설정하면 내부적으로 교체됩니다. 그러나 Matplotlib의 정확한 버전과 정확한 기능에 따라 Matplotlib는 오류 경고를 줄 수 있습니다. 따라서 VMIN을 Vmax보다 항상 낮게 설정하는 것이 가장 좋습니다.
def plot_statistics_and__filter (평균 _freq_noise, std_freq_noise, noise_thresh, smoothing_filter) : fig, ax = plt.subplots (ncols = 2, figsize = (20, 4)) plt_std, = ax [0] .plot (std_freq_noise, label = "std. 소음 ")
plt_std, = ax [0] .plot (Noise_thresh, label = "노이즈 임계 값 (주파수)") ax [0] .set_title ( "마스크의 임계 값")
AX [0] .Legend () CAX = AX [1] .MATSHOW (Smoothing_Filter, Origin = "Lower") 그림 ColorBar (CAX) AX [1] .SET_TITLE ( "스무딩 마스크 필터")소음 감소의 기본 통계.
신호 대 잡음비 (SNR 또는 S/N)는 원하는 신호의 수준을 배경 노이즈 수준과 비교하는 과학 및 공학에 사용되는 측정 값입니다.
SNR은 종종 데시벨로 표현 된 신호 전력 대 노이즈 전력의 비율로 정의됩니다.
1 : 1보다 높은 비율 (0dB보다 큽니다)은 노이즈보다 신호가 더 많음을 나타냅니다.
노이즈 마스킹을위한 임계 홀드 주파수 설정.
마스킹 임계 값은 다른 사운드의 존재로 인해 하나의 소리가 들리지 않는 프로세스를 말합니다.
따라서 마스킹 임계 값은 "마스커"라는 다른 노이즈가있는 경우 소리를들을 때 필요한 사운드의 사운드 압력 레벨입니다.
따라서 임계 값을 추가했습니다.
다양한 저 패스 필터로 소음 신호를 흐리게합니다
이미지에 맞춤 제작 필터를 적용 (2D 컨볼 루션)
def removenoise ( # # to to the positial slope parttion parttion a everate slope parttion (rise)의 신호 (전압)는 가능한 한 많은 노이즈를 제거하려고 시도합니다. audio_clip, #이 클립은 우리가 각각 수행 할 수있는 매개 변수입니다. 작업 노이즈 _clip, n grad_freq = 2, # mask.n_grad_time = 4, # 마스크와 함께 부드럽게 할 시간 채널 수는 몇 개의 주파수 채널 수를 smits.n_fft = 2048, # stft columns.win_length = win_length = 2048, # 각 오디오 프레임은`window ()`에 의해 창에 의해 window가 있습니다. window는`win_length '가``n_fft`..hop_length = 512, # 숫자 오디오와 일치합니다. n_std_thresh = 1.5, # # SignalProp_DecRease = 1.0으로 간주 될 노이즈의 평균 DB (각 주파수 레벨에서)보다 더 큰 표준 편차가 몇 개 더 커지는 수 , # 플래그는 당신이 알고리즘의 단계를 플로팅하기 위해 presentablevisual = false, #whether로 보이는 정규 표현식을 쓸 수 있습니다.
def Removenoise ( 삼각형 파의 포지티브 슬로프 부분 (상승)의 신호 (전압)가 가능한 한 많은 노이즈를 제거하려고 시도합니다.
Audio_Clip,
이 클립은 우리가 각각의 작업을 수행 할 수있는 매개 변수입니다.
Noise_Clip, n_grad_freq = 2 마스크와 함께 부드럽게 할 주파수 채널 수.
n_grad_time = 4, 마스크와 함께 부드러운 시간 채널 수.
n_fft = 2048
STFT 열 사이의 프레임의 숫자 오디오.
win_length = 2048, 각 오디오 프레임은 window() 로 창으로 표시됩니다. 창의 길이는 win_length 가 있고 n_fft 와 일치하도록 0으로 패딩합니다.
Hop_Length = 512, Stft 열 사이의 프레임의 숫자 오디오.
n_std_thresh = 1.5 신호로 간주 될 노이즈 (각 주파수 레벨)의 평균 DB보다 더 큰 표준 편차 수
prop_decrease = 1.0, 노이즈를 어느 정도까지 줄여야하는지 (1 = 모두, 0 = none)
verbose = false,
Flag는 알고리즘의 단계를 플로팅하기 위해 표시 가능한 visual = false, # # #false로 보이는 정규 표현식을 쓸 수 있습니다.
Noise_stft = _stft (Noise_Clip, N_FFT, HOP_LENGTH, WIN_LENGTH) NOISE_STFT_DB = _AMP_TO_DB (NP.ABS (Noise_Stft))
소음에 대한 stft
DB로 변환
Mean_freq_noise = np.mean (Noise_stft_db, Axis = 1) std_freq_noise = np.std (Noise_stft_db, Axis = 1) Noise_thresh = mean_freq_noise + std_freq_noise * n_std_thresh
노이즈에 대한 통계를 계산합니다
여기서 우리는 테시 노이즈를 위해 평균과 표준 노이즈와 N_STD 노이즈를 추가합니다.
sig_stft = _stft (audio_clip, n_fft, hop_length, win_length) sig_stft_db = _amp_to_db (np.abs (sig_stft))
신호 위의 stft
mask_gain_db = np.min (_amp_to_db (np.abs (sig_stft)))))
DB를 마스크 할 값을 계산하십시오
smoothing_filter = np.outer (np.concatenate (
[np.linspace (0, 1, n_grad_freq + 1, endpoint = false), np.linspace (1, 0, n_grad_freq + 2),
]]
) [1 : -1], np.concatenate (
[np.linspace (0, 1, n_grad_time + 1, endpoint = false), np.linspace (1, 0, n_grad_time + 2),
]]
) [1 : -1],
) smoothing_filter = smoothing_filter / np.sum (smoothing_filter)시간과 주파수로 마스크를위한 스무딩 필터 생성
db_thresh = np.repeat (np.reshape (Noise_thresh, [1, len (mean_freq_noise)]), np.shape (sig_stft_db) [1], axis = 0,
).티각 주파수/시간 빈에 대한 임계 값을 계산하십시오
sig_mask = sig_stft_db <db_thresh
신호에 대한 마스크
sig_mask = scipy.signal.fftconvolve (sig_mask, smoothing_filter, mode = "same") sig_mask = sig_mask * prop_decrease
스무딩 필터로 마스크 컨볼 루션
# mask the signalsig_stft_db_masked = (sig_stft_db * (1 - sig_mask)+ np.ones(np.shape(mask_gain_dB)) * mask_gain_dB * sig_mask) # mask realsig_imag_masked = np.imag(sig_stft) * (1 - sig_mask)sig_stft_amp = (_db_to_amp (sig_stft_db_masked) * np.sign (sig_stft)) + (1j * sig_imag_masked)
신호를 가리십시오
# SignalRecovered_Signal = _istft (SIG_STFT_AMP, HOP_LENGTH, WIN_LENGTH) 복구 된 regreged_spec = _amp_to_db (_p.abs (_stft (recoded_signal, n_fft, hop_length, win_length))
)신호를 복구하십시오
따라서 신호가 임계 값 이상인 경우 마스크를 적용하십시오.
스무딩 필터로 마스크를 복독하십시오
이미 다운로드 된 WAV 파일에 노이즈 감소 알고리즘을 적용합니다.
오디오 신호의 라이브 녹음에 FFT를 적용합니다.
노이즈 취소를위한 AI의 더 깊은 구현.
다양한 형식의 오디오 파일에 노이즈 감소 알고리즘을 적용합니다.
마이크와 ESP32가있는 라이브 오디오 신호는 추가 계산 및 신호 처리를 위해 WAV 파일을 얻게됩니다.
Dhriti Mabian
Priyal Awankar
*SRA VJTI_EKLAVYA 2021
Shreyas Atre
가혹한 샤
대담
노이즈 취소 방법
마틴 하인즈 (Martin Heinz)에서 보일러 플레이트를 가져 갔다
팀 사인 버그
특허


