VitalSource Grabber
1.0.0
VitalSource는 교과서의 온라인 상점입니다. 불행히도 구매 한 콘텐츠에 대한 액세스는 매우 제한적입니다. 책 (PDF 없음)을 읽으려면 VitalSource의 앱을 사용해야하며 인쇄는 한 번에 2 페이지로 제한됩니다. 이 2 페이지는 전자 메일 주소로 워터 마크를 받고 이미지로 제공되므로 검색 할 수 없습니다. 엄청난. VitalSource 책의 다운로드를 유망한 다른 저장소가 여러 개 있지만 그중 어느 것도 저를 위해 일하지 않았으므로 내 자신의 글을 썼습니다.
pip3 install requests )brew install imagemagick )앞에서 언급했듯이 VitalSource를 사용하면 한 번에 최대 2 페이지를 인쇄 할 수 있습니다. 각 책은 다른 형식 (A5/A4/Custom)으로 설정 될 수 있지만 인쇄 된 레이아웃은 항상 A4 크기로 설정 될 수 있기 때문에 이것은 중요한 세부 사항입니다. 따라서 두 개의 A5 크기의 텍스트 페이지가 두 개의 A4 인쇄 페이지를 완전히 채우지 않습니다.
VitalSource에 페이지를 하나씩 인쇄하도록 요청하면 모든 페이지의 내용이 동일하게 배포됩니다. 우리가 2 페이지 씩 인쇄하기로 선택하고 원래 책이 A4 형식보다 작다면, 짝수 페이지는 일반적으로 거의 비어 있습니다. 이 차이를 더 잘 설명하려면 다음 이미지를 참조하십시오. 
페이지를 다운로드하려면 원하는 변형에 따라 download_single.py 또는 download_double.py 스크립트를 사용하려고합니다. 두 변형 모두에서 처음 10 페이지를 다운로드하고 결과를 기반으로 결정하는 것이 좋습니다 (각 책마다 다릅니다).
스크립트를 실행하기 전에 9-11 행의 일부 매개 변수를 수정하려고합니다 : IBAN , VitalSourceAPIKey 및 VitalSourceAccessToken . Iban은 매우 자명하지만 다른 두 매개 변수는 귀하의 작업이 필요합니다. 권장 디버그 프록시 중 하나를 사용하여 Bookshelf App의 네트워크 트래픽을 캡처하고 두 헤더 속성을 추출해야합니다. 프록시가 제자리에 있으면 Bookshelf 앱에서 책을 열고 모든 페이지를 인쇄하십시오. 그런 다음 프록시 로그에서 https://print.vitalsource.com/ domain의 트래픽을 확인하고 요청 헤더를 확인하십시오. 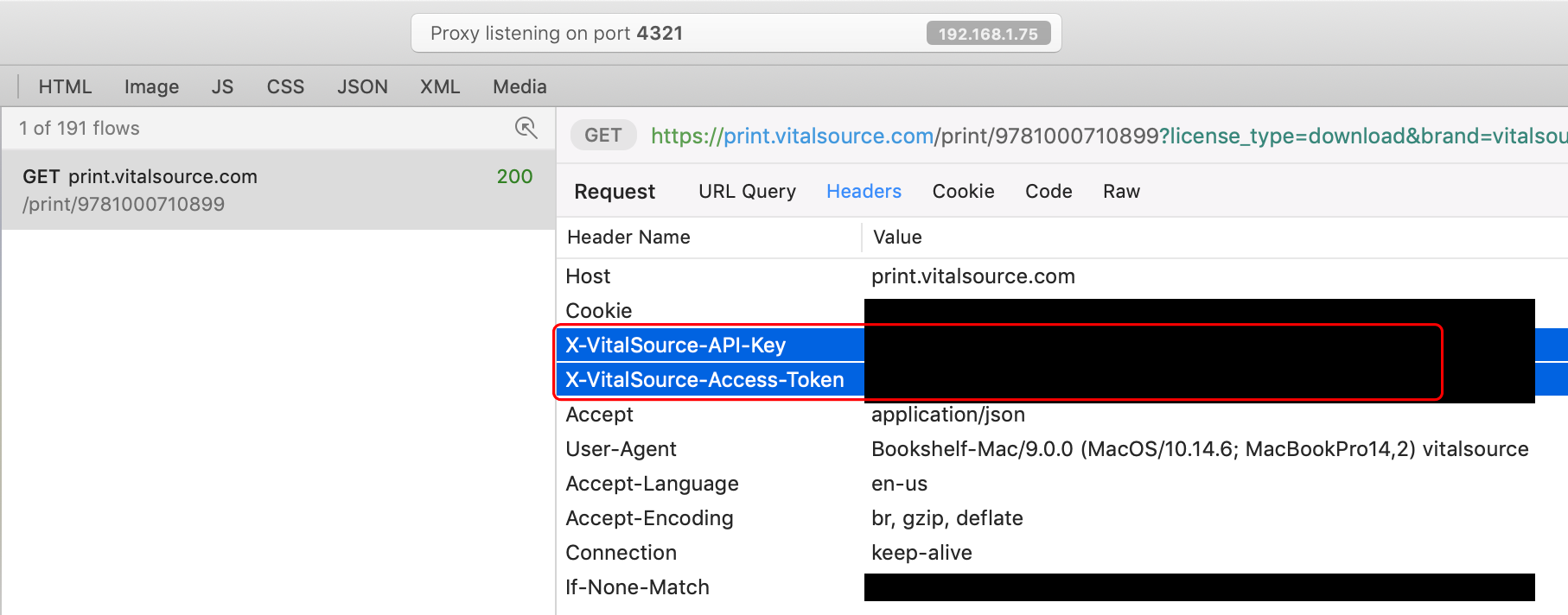
3 개의 매개 변수를 업데이트하면 스크립트를 실행하십시오. 천천히 (다운로드 경고를 피하기 위해 다운로드가 조절됩니다) 요청 된 페이지를 다운로드의 새 폴더로 다운로드하십시오.
Script process.sh 다운로드 된 페이지의 정리를 처리합니다. 먼저 워터 마크를 제거한 다음 각 페이지의 하단에 페이지 번호를 추가합니다. 
다운로드 된 책의 Iban을 유일한 매개 변수로 실행하면 좋을 것입니다. 이와 같이 ./process.sh 9781000710899
이것은 쉬운 일입니다 - 모든 이미지를 선택하고 마우스 오른쪽 버튼을 클릭하고 빠른 작업을 선택하십시오> PDF 작성 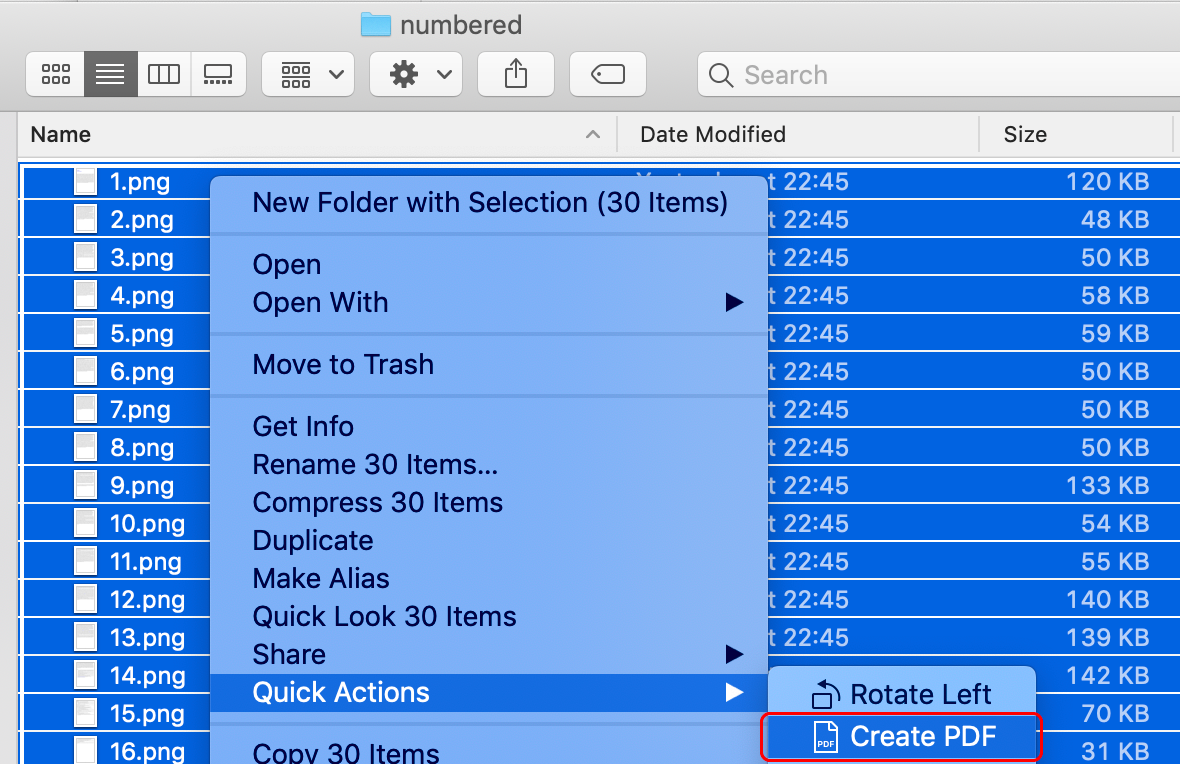
최종 PDF를 검색 할 수 있으려면 OCR (Optical Character Inception)을 실행해야합니다. 이를 수행 할 수있는 많은 상용 도구가 있습니다. 예를 들어 Adobe Acrobat.


