bwa mem2
v2.2.1
우리는 디스크의 인덱스 크기가 한 가지 유형의 FM-Index (2bit.64 및 8bit.32 대신 2bit.64) 및 8x 압축으로 이동하여 디스크의 인덱스 크기가 8 배, 메모리에 4 번 떨어 졌다는 것을 기꺼이 발표하게되어 기쁩니다. 접미사 배열의. 예를 들어, 인간 게놈의 경우 디스크의 인덱스 크기는 ~ 80GB에서 ~ 10GB로 하락하고 메모리 풋 프린트는 ~ 40GB에서 ~ 10GB로 떨어집니다. 감소로 인해 인덱스 IO 시간이 상당히 감소하고 읽기 매핑에 대한 성능 영향이 거의 없습니다. 이러한 색인 구조의 이러한 변경으로 인해 (Commit #4B59796, 2020 년 10 월 10 일) 인덱스를 재건해야합니다.
Commit A591E22의 출력 SAM 파일에 MC 플래그가 추가되었습니다. 출력은 원래 BWA-MEM 버전 0.7.17과 일치해야합니다.
Commit e0AC59E에 따라 GIT 하위 모듈 SAFESTRINGLIB가 있습니다. 이를 얻으려면 -클로닝 또는 "Git Submodule Init"및 "Git Submodule Update"를 이미 복제 한 저장소에서 "Git Submodule Init"및 "Git Submodule Update"에 사용하십시오 (자세한 내용은 아래 참조).
# 사전 컴파일 된 바이너리 (권장) curl -l https://github.com/bwa-mem2/bwa-mem2/releases/download/vwa-22.1/bwa-mem2-2.2.1_x64-linux.tar.bz2 | 타르 jxf- BWA-MEM2-2.2.1_X64-LINUX/BWA-MEM2 INDEX REF.FA BWA-MEM2-2.2.1_X64-LINUX/BWA-MEM2 MEM REF.FA Read1.fq read1.fq read2.fq> out.sam# 소스에서 컴파일 (일반 사용자에게는 권장되지 않음)# 소스 측정 클론을 얻으십시오-수용 https : // github.com/bwa-mem2/bwa-mem2cd bwa-mem2# 오르지 클론 https://github.com/bwa-mem2/bwa-mem2cd bwa-mem2 git 서브 모듈 init git 하위 모듈 업데이트# 컴파일 및 런 메이크 ./BWA-MEM2
BWA-MEM2 도구는 BWA의 BWA-MEM 알고리즘의 다음 버전입니다. BWA와 동일한 정렬을 생성하며 사용 사례, 데이터 세트 및 실행중인 머신에 따라 ~ 1.3-3.1 배 더 빠릅니다.
원래 BWA는 Heng Li (@lh3)에 의해 개발되었습니다. BWA-MEM2의 성능 향상은 주로 Vasimuddin MD (@yuk12)와 Parally Computing Lab, Intel의 Sanchit Misra (@sanchit-misra)에 의해 수행되었습니다. BWA-MEM2는 MIT 라이센스에 따라 배포됩니다.
일반 사용자의 경우 릴리스 페이지에서 선행 바이너리를 사용하는 것이 좋습니다. 이 바이너리는 인텔 컴파일러로 컴파일되었으며 GCC 컴파일 바이너리보다 더 빠르게 작동합니다. 사전 컴파일 된 바이너리는 또한 간접적으로 CPU 파견을 지원합니다. bwa-mem2 바이너리는 러닝 머신에서 사용 가능한 SIMD 명령 세트를 기반으로 가장 효율적인 구현을 자동으로 선택할 수 있습니다. 다음 명령 줄을 사용하여 CentoS7 기계에서 사전 컴파일 된 이진을 생성했습니다.
CXX = ICPC Multi를 만듭니다
사용법은 원래 BWA MEM 도구와 정확히 동일합니다. 다음은 간단한 시놉시스입니다. 사용 가능한 명령에 대해 ./bwa-mem2를 실행하십시오.
# 참조 시퀀스 인덱싱 (28N GB 메모리가 필요합니다. <in.fasta>는 서열 파일을 참조하는 경로이며 <prefix>는 결과 색인을 저장하는 파일 이름의 접두사입니다. 기본값은 in.fasta. # 매핑 # run "./bwa-mem2 mem"모든 옵션을 얻으려면 ./bwa-mem2 mem -t <num_threads> <prefix> <reads.fq/fa >> outam.sam 여기서 <접두사>는 접두사가 제공되지 않은 경우 인덱스 또는 참조 FASTA 파일의 경로를 만들 때 지정된 접두사입니다.
데이터 세트 :
참조 게놈 : Human_g1k_v37.fasta
| 별명 | 데이터 세트 소스 | 읽기 수 | 길이를 읽습니다 |
|---|---|---|---|
| D1 | Broad Institute | 2 x 2.5m bp | 151bp |
| D2 | SRA : SRR7733443 | 2 x 2.5m bp | 151bp |
| D3 | SRA : SRR9932168 | 2 x 2.5m bp | 151bp |
| D4 | SRA : SRX6999918 | 2 x 2.5m bp | 151bp |
기계 세부 사항 :
프로세서 : 인텔 (R) Xeon (R) 8280 CPU @ 2.70GHz
OS : Centos Linux 릴리스 7.6.1810
메모리 : 100GB
우리는 성능 결과를 수집하기 위해 아래 단계를 따랐습니다.
A. 데이터 다운로드 단계 :
https://trace.ncbi.nlm.nih.gov/traces/sra/sra.cgi?view=software#header-global에서 sra 툴킷을 다운로드하십시오
Tar XFZV Sratoolkit.2.10.5-centos_linux64.tar.gz
d2 : sratoolkit.2.10.5-centos_linux64/bin/fastq-dump--split-files srr7733443
D3 다운로드 : sratoolkit.2.10.5-centos_linux64/bin/fastq-dump--split-files srr9932168
d4 : sratoolkit.2.10.5-centos_linux64/bin/fastq-dump--split-files srx6999918
B. 정렬 단계 :
git 클론 https://github.com/bwa-mem2/bwa-mem2.git
CD BWA-MEM2
make CXX=icpc (Intel C/C ++ 컴파일러 사용)
또는 make (GCC 컴파일러 사용)
./bwa-mem2 index <ref.fa>
./bwa-mem2 mem [-t <#threads>] <ref.fa> <in_1.fastq> [<in_2.fastq>]> <output.sam>
예를 들어, 이중 소켓 (각각 56 개의 스레드)과 Double Numa Compute 노드에서 다음 명령 줄을 사용하여 D2를 Human_G1K_V37.Fasta 참조 게놈에 정렬했습니다.
numactl -m 0 -C 0-27,56-83 ./bwa-mem2 index human_g1k_v37.fasta numactl -m 0 -C 0-27,56-83 ./bwa-mem2 mem -t 56 human_g1k_v37.fasta SRR7733443_1.fastq SRR7733443_2.fastq > d2_align.sam
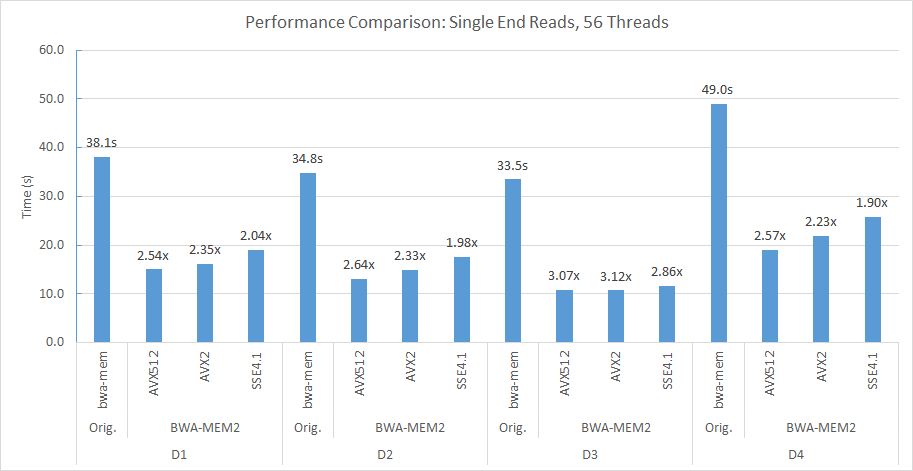
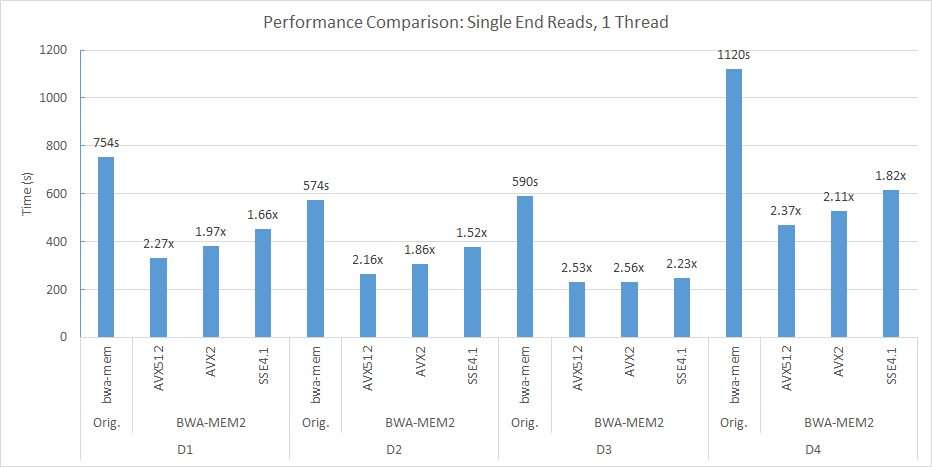
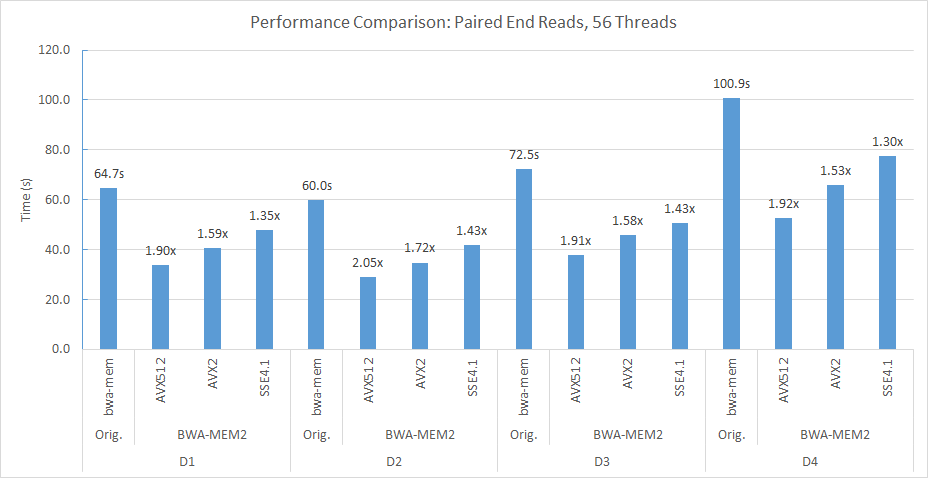

BWA-MEM2-LISA는 BWA-MEM2의 가속화 된 버전으로, 우리는 시드 단계에 학습 된 인덱스를 적용합니다. BWA-MEM2-LISA 브랜치에는 구현의 소스 코드가 포함되어 있습니다. 다음은 BWA-MEM2-LISA의 기능입니다.
BWA-MEM2와 동일한 출력.
인덱스 생성을위한 모든 명령 선과 읽기 매핑은 BWA-MEM2와 정확히 동일합니다.
BWA-MEM2-LISA는 BWA-MEM2에 비해 파종 단계 (BWA-MEM2의 주요 병목 현상 중 하나)를 최대 4.5 배까지 가속합니다.
BWA-MEM2-LISA 지수의 메모리 풋 프린트는 인간 게놈의 경우 ~ 120GB입니다.
이 코드는 BWA-mem2-lisa 분기 : https://github.com/bwa-mem2/bwa-mem2/tree/bwa-mem2-lisa에 있습니다
BWA-MEM2 리포지토리의 ERT 브랜치에는 BWA-MEM2의 Enuerated Radix 트리 기반 가속도의 코드베이스가 포함되어 있습니다. ERT 코드는 BWA-MEM2 상단에 구축되었습니다 ( @arun-sub의 노력 덕분). 다음은 ERT 기반 BWA-MEM2 도구의 하이라이트입니다.
BWA-MEM과 동일한 출력 (2)
이 도구에는 ERT 솔루션 (인덱스 생성 및 매핑 용)을 사용할 수있는 두 가지 추가 플래그가 있으며, 그렇지 않으면 바닐라 BWA-MEM2 모드에서 실행됩니다.
1 개의 추가 플래그를 사용하여 ERT 인덱스 (BWA-MEM2 인덱스와 다름)와 해당 ERT 지수를 사용하기위한 1 개의 추가 플래그 (ERT Branch의 README 참조).
ERT 솔루션은 바닐라 BWA -MEM2와 비교하여 10% -30% 더 빠릅니다 (기계 구성에서 테스트) -사용자는 옵션 -K 1000000 을 사용하여 속도 업을 확인하는 것이 좋습니다.
ERT 지수의 메모리 풋 프린트는 ~ 60GB입니다.
코드는 ERT Branch : https://github.com/bwa-mem2/bwa-mem2/tree/ert에 있습니다
Vasimuddin MD, Sanchit Misra, Heng Li, Srinivas Aluru. 멀티 코어 시스템을위한 BWA-MEM의 효율적인 아키텍처 인식 가속도. IEEE 병렬 및 분산 처리 심포지엄 (IPDPS), 2019. 10.1109/IPDPS.2019.00041


