multi model server
v1.1.11 - Extra error logging and new timeout config
| 우분투/파이썬 -2.7 | 우분투/파이썬 -3.6 |
|---|---|
MMS (Multi Model Server)는 ML/DL 프레임 워크를 사용하여 훈련 된 딥 러닝 모델을 제공하기위한 유연하고 사용하기 쉬운 도구입니다.
MMS 서버 CLI 또는 사전 구성된 Docker 이미지를 사용하여 모델 추론 요청을 처리하기 위해 HTTP 엔드 포인트를 설정하는 서비스를 시작하십시오.
서빙 및 포장에 대한 빠른 개요와 예제는 다음과 같습니다. 자세한 문서 및 예제는 DOCS 폴더에 제공됩니다.
우리와 함께하십시오 슬랙 채널 개발 팀과 연락을 취하고 질문을하고 요리가 무엇인지 알아보십시오!
슬랙 채널 개발 팀과 연락을 취하고 질문을하고 요리가 무엇인지 알아보십시오!
이 문서를 더 진행하기 전에 다음과 같은 전제 조건이 있는지 확인하십시오.
Ubuntu, Centos 또는 MacOS. Windows 지원은 실험적입니다. 다음 지침은 Linux 및 MacOS에만 초점을 맞출 것입니다.
Python- 다중 모델 서버를 사용하려면 Python이 작업자를 실행해야합니다.
PIP -PIP는 파이썬 패키지 관리 시스템입니다.
Java 8- 멀티 모델 서버는 Java 8을 시작해야합니다. Java 8을 설치하기위한 다음 옵션이 있습니다.
우분투를 위해 :
sudo apt-get install openjdk-8-jre-headlessCentos :
sudo yum install java-1.8.0-openjdkMacOS의 경우 :
brew tap homebrew/cask-versions
brew update
brew cask install adoptopenjdk81 단계 : 가상 환경 설정
가상 환경에서 다중 모델 서버를 설치하고 실행하는 것이 좋습니다. 가상 환경에서 모든 파이썬 종속성을 실행하고 설치하는 것이 좋습니다. 이는 종속성을 격리하고 종속성 관리를 용이하게합니다.
한 가지 옵션은 VirtualEnV를 사용하는 것입니다. 이것은 가상 파이썬 환경을 만드는 데 사용됩니다. 다음과 같이 Python 2.7 용 VirtualEnV를 설치하고 활성화 할 수 있습니다.
pip install virtualenv그런 다음 가상 환경을 만듭니다.
# Assuming we want to run python2.7 in /usr/local/bin/python2.7
virtualenv -p /usr/local/bin/python2.7 /tmp/pyenv2
# Enter this virtual environment as follows
source /tmp/pyenv2/bin/activate자세한 내용은 VirtualEnV 문서를 참조하십시오.
2 단계 : MXNET MMS를 설치하면 기본적으로 MXNET 엔진을 설치하지 않습니다. 가상 환경에 아직 설치되지 않은 경우 MXNET PIP 패키지 중 하나를 설치해야합니다.
CPU 추론의 경우 mxnet-mkl 이 권장됩니다. 다음과 같이 설치하십시오.
# Recommended for running Multi Model Server on CPU hosts
pip install mxnet-mkl GPU 추론의 경우 mxnet-cu92mkl 이 권장됩니다. 다음과 같이 설치하십시오.
# Recommended for running Multi Model Server on GPU hosts
pip install mxnet-cu92mkl3 단계 : 다음과 같이 MMS를 설치 또는 업그레이드합니다.
# Install latest released version of multi-model-server
pip install multi-model-server 이전 버전의 multi-model-server 에서 업그레이드하려면 마이그레이션 참조 문서를 참조하십시오.
참고 :
model-archiver 버전이 설치됩니다. 자세한 옵션 및 세부 사항은 Model-Archiver를 참조하십시오. 설치되면 MMS 모델 서버를 매우 빠르게 실행할 수 있습니다. 사용 가능한 모든 CLI 옵션을 보려면 --help 사용해보십시오.
multi-model-server --help이 빠른 시작을 위해 대부분의 기능을 건너 뛰지만 준비가되면 전체 서버 문서를 살펴보십시오.
객체 분류 모델을 제공하기위한 쉬운 예는 다음과 같습니다.
multi-model-server --start --models squeezenet=https://s3.amazonaws.com/model-server/model_archive_1.0/squeezenet_v1.1.mar위의 명령이 실행되면 호스트에서 MMS를 실행하여 추론 요청을 듣습니다. MMS 시작 중 모델을 지정하는 경우 - 백엔드 작업자가 사용 가능한 VCPU (CPU 인스턴스에서 실행되는 경우) 또는 사용 가능한 GPU 수 (GPU 인스턴스에서 실행되는 경우)로 자동 스케일링됩니다. ). 많은 컴퓨팅 리소스 (VCPU 또는 GPU)가있는 강력한 호스트의 경우이 시작 및 자동화 프로세스는 상당한 시간이 걸릴 수 있습니다. MMS 시작 시간을 최소화하려면 시작 시간 동안 모델 등록 및 스케일링을 피하고 해당 관리 API 호출을 사용하여 나중에 이동할 수 있습니다 (이를 통해 더 미세한 곡물 제어가 할당 된 리소스의 양에 대한 미세한 곡물 제어가 가능합니다. 모든 특정 모델).
테스트하려면 실행중인 MMS 옆에 새 터미널 창을 열 수 있습니다. 그런 다음 curl 사용하여 새끼 고양이의 귀여운 사진 중 하나를 다운로드 할 수 있으며 Curl의 -o 깃발은 kitten.jpg 를 이름으로 지정할 수 있습니다. 그런 다음 새끼 고양이의 이미지와 함께 MMS 예측 엔드 포인트에 POST curl 것입니다.

아래의 예에서는 이러한 단계에 대한 지름길을 제공합니다.
curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg
curl -X POST http://127.0.0.1:8080/predictions/squeezenet -T kitten.jpg예측 엔드 포인트는 JSON에서 예측 응답을 반환합니다. 다음 결과와 비슷합니다.
[
{
"probability" : 0.8582232594490051 ,
"class" : " n02124075 Egyptian cat "
},
{
"probability" : 0.09159987419843674 ,
"class" : " n02123045 tabby, tabby cat "
},
{
"probability" : 0.0374876894056797 ,
"class" : " n02123159 tiger cat "
},
{
"probability" : 0.006165083032101393 ,
"class" : " n02128385 leopard, Panthera pardus "
},
{
"probability" : 0.0031716004014015198 ,
"class" : " n02127052 lynx, catamount "
}
] 이 결과는 예측 엔드 포인트에 대한 curl 호출에 대한 응답과 MMS를 실행하는 터미널 창의 서버 로그에 응답 할 것입니다. 또한 메트릭으로 로컬로 기록되고 있습니다.
다른 모델은 모델 동물원에서 다운로드 할 수 있으므로 그 중 일부를 사용해보십시오.
이제 MMS로 딥 러닝 모델을 제공하는 것이 얼마나 쉬운 지 보았습니다! 더 알고 싶습니까?
현재 실행중인 모델 서버 인스턴스를 중지하려면 다음 명령을 실행하십시오.
$ multi-model-server --stop출력이 멀티 모델 서버가 중지되었음을 지정하는 것을 볼 수 있습니다.
MMS를 사용하면 모든 모델 아티팩트를 단일 모델 아카이브로 포장 할 수 있습니다. 이를 통해 모델을 쉽게 공유하고 배포 할 수 있습니다. 모델을 포장하려면 모델 아카이버 문서를 확인하십시오
전체 문서 색인을 위해 Docs ReadMe로 찾아보십시오. 여기에는 더 많은 예제, API 서비스를 사용자 정의하는 방법, API 엔드 포인트 세부 사항 등이 포함됩니다.
다음은 MMS로 구동되는 딥 러닝 애플리케이션의 몇 가지 예입니다.
제품 검토 분류 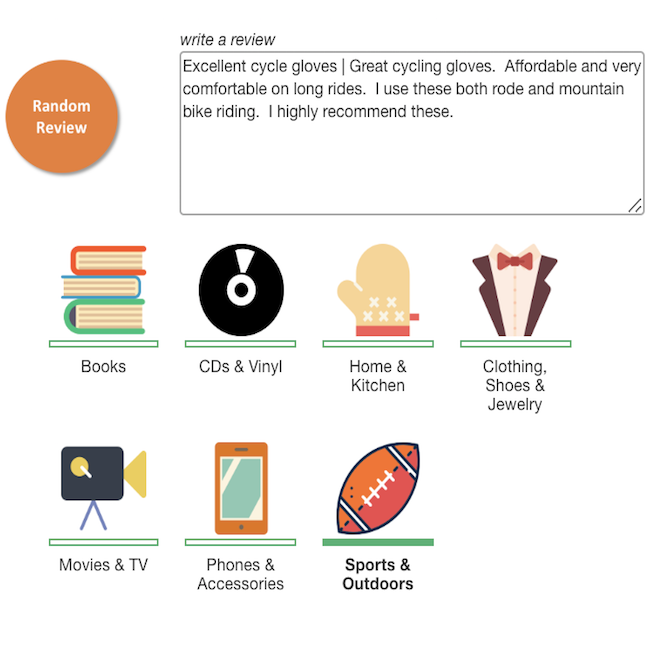 | 시각적 검색 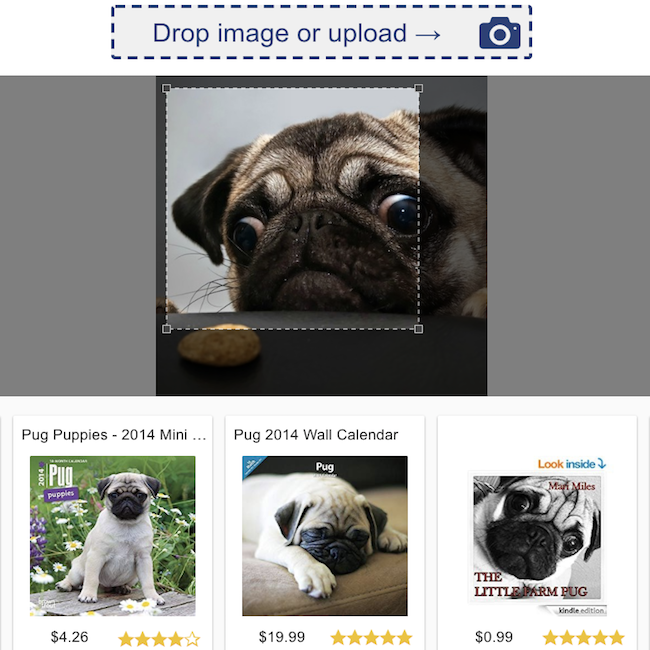 |
얼굴 감정 인식  | 신경 스타일 전달  |
우리는 모든 기여를 환영합니다!
버그를 제출하거나 기능을 요청하려면 Github 문제를 제출하십시오. 풀 요청을 환영합니다.


