rlcard
RLCard 1.0.7
中文文档
RLCard는 카드 게임에서 강화 학습 (RL)을위한 툴킷입니다. 다양한 강화 학습 및 검색 알고리즘을 구현하기위한 사용하기 쉬운 인터페이스를 갖춘 여러 카드 환경을 지원합니다. RLCard의 목표는 강화 학습과 불완전한 정보 게임을 연결하는 것입니다. RLCard는 Rice 및 Texas A & M University의 Data Lab 및 Community Contributors에서 개발했습니다.
지역 사회:
소식:
다음 게임은 주로 커뮤니티 기고자들이 개발하고 유지 관리합니다. 감사합니다!
모든 기고자들에게 감사합니다!




























이 repo가 유용하다고 생각하면 다음을 인용 할 수 있습니다.
Zha, Daochen 등 "RLCARD : 카드 게임에서 강화 학습을위한 플랫폼." ijcai. 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} Python 3.6+ 와 PIP가 설치되어 있는지 확인하십시오. rlcard 의 안정적인 버전을 pip 로 설치하는 것이 좋습니다.
pip3 install rlcard
기본 설치에는 카드 환경 만 포함됩니다. 교육 알고리즘의 Pytorch 구현을 사용하려면 실행하십시오
pip3 install rlcard[torch]
중국에 있고 위의 명령이 너무 느리면 Tsinghua University에서 제공하는 거울을 사용할 수 있습니다.
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
또는 최신 버전을 복제 할 수 있습니다 (중국에 있고 Github가 느리면 Gitee에서 거울을 사용할 수 있습니다).
git clone https://github.com/datamllab/rlcard.git
또는 더 빨리 하나의 지점 만 복제하십시오.
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
그런 다음 설치하십시오
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
또한 콘다 설치 방법을 제공합니다.
conda install -c toubun rlcard
Conda 설치는 카드 환경 만 제공하며 요구 사항에 따라 Pytorch를 수동으로 설치해야합니다.
짧은 예는 다음과 같습니다.
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()RLCard는 다양한 알고리즘에 유연하게 연결될 수 있습니다. 다음 예제를 참조하십시오.
examples/human/leduc_holdem_human.py 실행하여 미리 훈련 된 leduc hold'em 모델과 함께 재생하십시오. Leduc Hold'em은 Texas Hold'em의 단순화 된 버전입니다. 규칙은 여기에서 찾을 수 있습니다.
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
또한 손쉬운 디버깅을위한 GUI도 제공합니다. 여기를 확인하십시오. 일부 데모 :
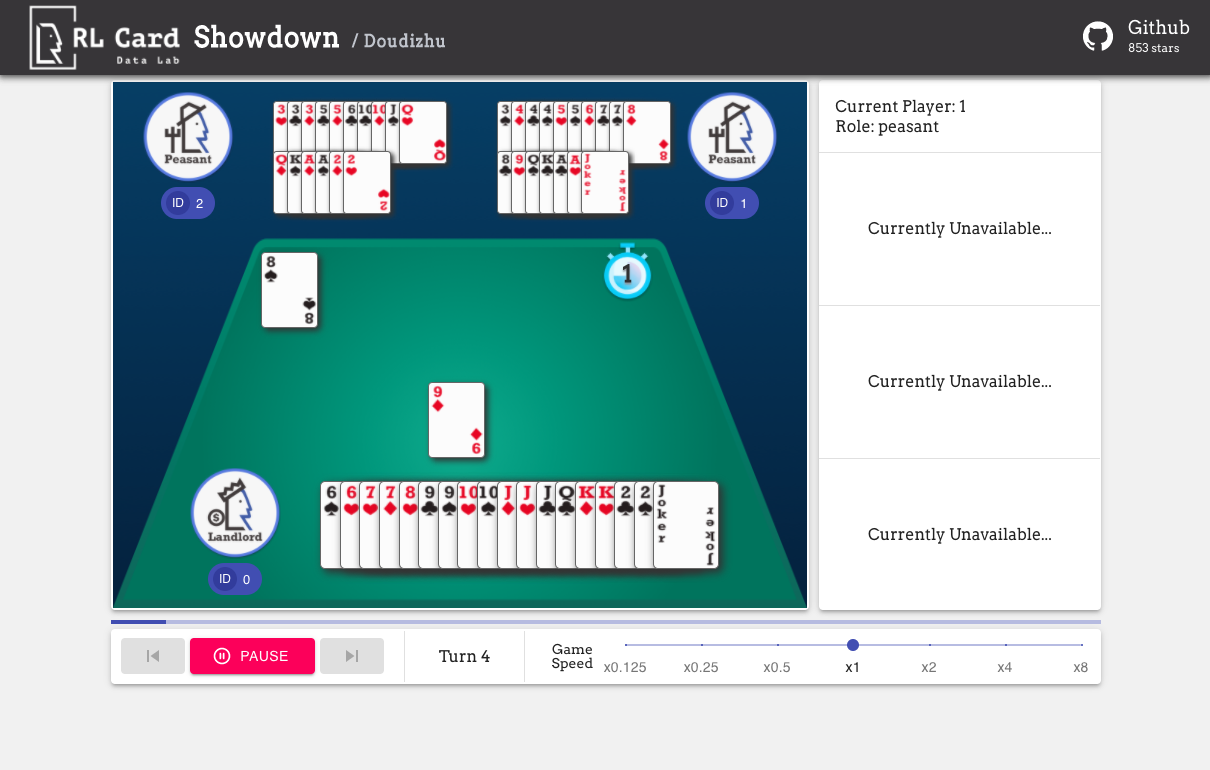
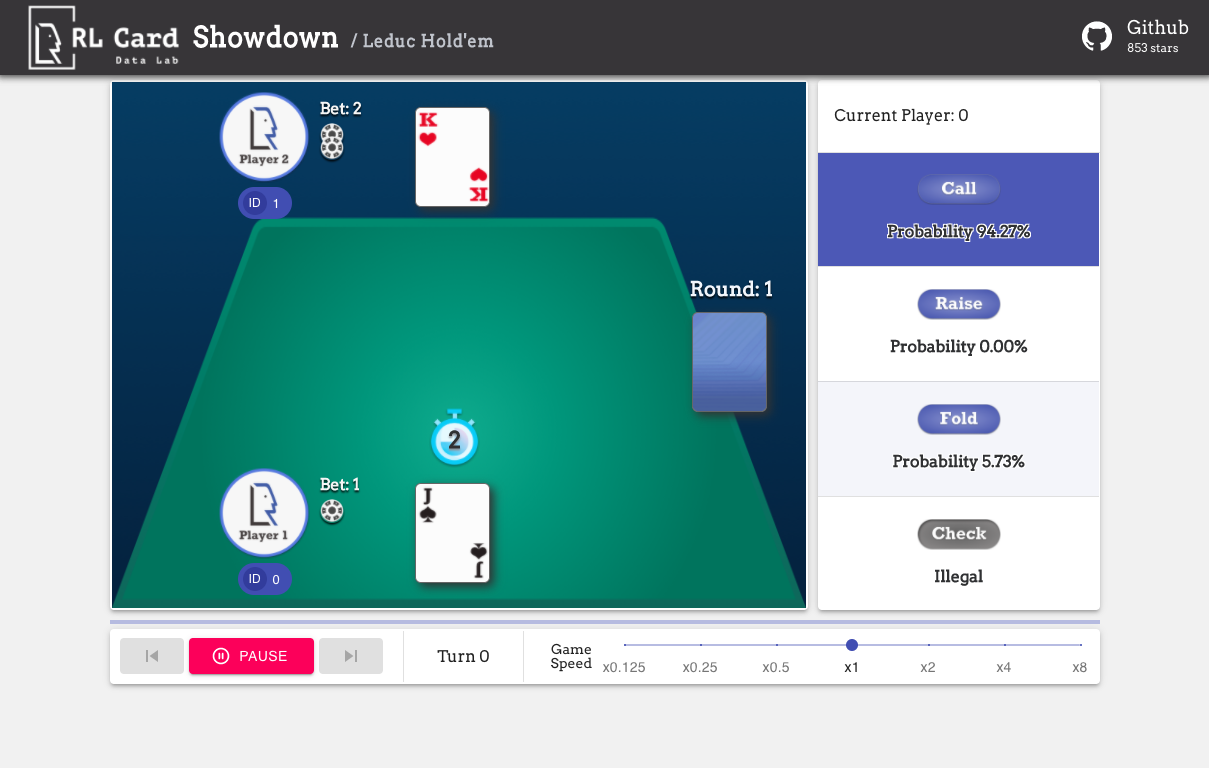
우리는 여러 측면에서 게임에 대한 복잡성 추정을 제공합니다. 인포셋 번호 : 정보 세트 수; Infoset 크기 : 단일 정보 세트의 평균 상태 수; 액션 크기 : 액션 공간의 크기. 이름 : rlcard.make 에 전달 해야하는 이름은 게임 환경을 만들기 위해 메이크입니다. 우리는 또한 문서에 대한 링크와 임의 예제를 제공합니다.
| 게임 | 인포셋 번호 | 인포셋 크기 | 액션 크기 | 이름 | 용법 |
|---|---|---|---|---|---|
| 블랙 잭 (Wiki, Baike) | 10^3 | 10^1 | 10^0 | 곤봉 | 문서, 예 |
| Leduc Hold'em (종이) | 10^2 | 10^2 | 10^0 | Leduc-Holdem | 문서, 예 |
| Limit Texas Hold'em (Wiki, Baike) | 10^14 | 10^3 | 10^0 | 한계 홀드 | 문서, 예 |
| Dou Dizhu (Wiki, Baike) | 10^53 ~ 10^83 | 10^23 | 10^4 | Doudizhu | 문서, 예 |
| Mahjong (Wiki, Baike) | 10^121 | 10^48 | 10^2 | 마작 | 문서, 예 |
| 무리 텍사스 홀드 홀 (Wiki, Baike) | 10^162 | 10^3 | 10^4 | 비정규 홀드 | 문서, 예 |
| UNO (Wiki, Baike) | 10^163 | 10^10 | 10^1 | 우노 | 문서, 예 |
| 진 러미 (Wiki, Baike) | 10^52 | - | - | 진-럼미 | 문서, 예 |
| 다리 (Wiki, Baike) | - | - | 다리 | 문서, 예 |
| 연산 | 예 | 참조 |
|---|---|---|
| Deep Monte-Carlo (DMC) | 예제/run_dmc.py | [종이] |
| 딥 Q- 러닝 (DQN) | 예제/run_rl.py | [종이] |
| 신경 가상 자체 플레이 (NFSP) | 예제/run_rl.py | [종이] |
| 반 상당 후회 최소화 (CFR) | 예제/run_cfr.py | [종이] |
우리는 기준선 역할을하는 모델 동물원을 제공합니다.
| 모델 | 설명 |
|---|---|
| Leduc-Holdem-Cfr | Leduc Hold'em에서 미리 훈련 된 CFR (기회 샘플링) 모델 |
| Leduc-Holdem-Rule-V1 | Leduc Hold'em의 규칙 기반 모델, v1 |
| Leduc-Holdem-Rule-V2 | Leduc Hold'em, v2에 대한 규칙 기반 모델 |
| UNO-RULE-V1 | UNO의 규칙 기반 모델, v1 |
| 한계 홀드-룰 -V1 | Limit Texas Hold'em, v1에 대한 규칙 기반 모델 |
| Doudizhu-Rule-V1 | Dou Dizhu의 규칙 기반 모델, v1 |
| 진-럼미오버-룰 | 진 러미 초보자 규칙 모델 |
다음 인터페이스를 사용하여 환경을 만들 수 있습니다. 선택적으로 사전으로 일부 구성을 지정할 수 있습니다.
env_id 는 환경의 문자열입니다. config 일부 환경 구성을 지정하는 사전입니다.seed : 기본값 None . 결과를 재현하기위한 환경 로컬 임의의 시드를 설정하십시오.allow_step_back : default False . step_back 함수가 트리에서 뒤로 이동하도록 허용하는 경우 True .game_ 로 시작합니다. 현재 Blackjack에서 game_num_players 만 지원합니다.EnvironEmnt가 만들어지면 게임 정보에 액세스 할 수 있습니다.
상태는 파이썬 사전입니다. 관찰 state['obs'] , 법적 조치 state['legal_actions'] , 원시 관찰 state['raw_obs'] 및 원시 법적 조치 state['raw_legal_actions'] 로 구성됩니다.
다음 인터페이스는 기본 사용을 제공합니다. 사용하기 쉽지만 에이전트에 대한 가정이 있습니다. 에이전트는 에이전트 템플릿을 따라야합니다.
agents Agent 객체의 목록입니다. 목록의 길이는 게임의 플레이어 수와 같아야합니다.set_agents 호출 된 후에 사용할 수 있습니다. is_training 이 True 이면 에이전트에서 step 함수를 사용하여 게임을합니다. is_training 이 False 경우 eval_step 대신 호출됩니다.고급 사용을 위해 다음 인터페이스를 사용하면 게임 트리에서 유연한 작업이 가능합니다. 이 인터페이스는 에이전트에 대해 가정하지 않습니다.
action 원시 행동 또는 정수 일 수 있습니다. 동작이 원시 조치 (문자열) 인 경우 raw_action True 이어야합니다.allow_step_back 이 True 인 경우에만 사용할 수 있습니다. 한 걸음 뒤로갑니다. 이것은 CFR (기회 샘플링)과 같은 게임 트리에서 작동하는 알고리즘에 사용할 수 있습니다.True 반환합니다. OthereWise, False 를 반환합니다.player_id 에 해당하는 상태를 반환합니다.기본 모듈의 목적은 다음과 같이 나열되어 있습니다.
자세한 내용은 일반적인 소개에 대해서는 문서를 참조하십시오. API 문서는 당사 웹 사이트에서 제공됩니다.
이 프로젝트에 대한 기여는 대단히 감사합니다! 피드백/버그에 대한 문제를 만드십시오. 코드를 기여하려면 기고 가이드를 참조하십시오. 궁금한 점이 있으시면 [email protected]로 daochen zha에 문의하십시오.
우리는 관대 한 지원과 커뮤니티 기고자들의 모든 기여에 대해 JJ World Network Technology Co., Ltd에게 감사의 말씀을 전합니다.


