ChatIE
1.0.0
종이의 공식 저장소 "Chatgpt와 채팅을 통한 제로 샷 정보 추출". 활성 업데이트를 위해 스타, 시청 및 포크를 제발하십시오!
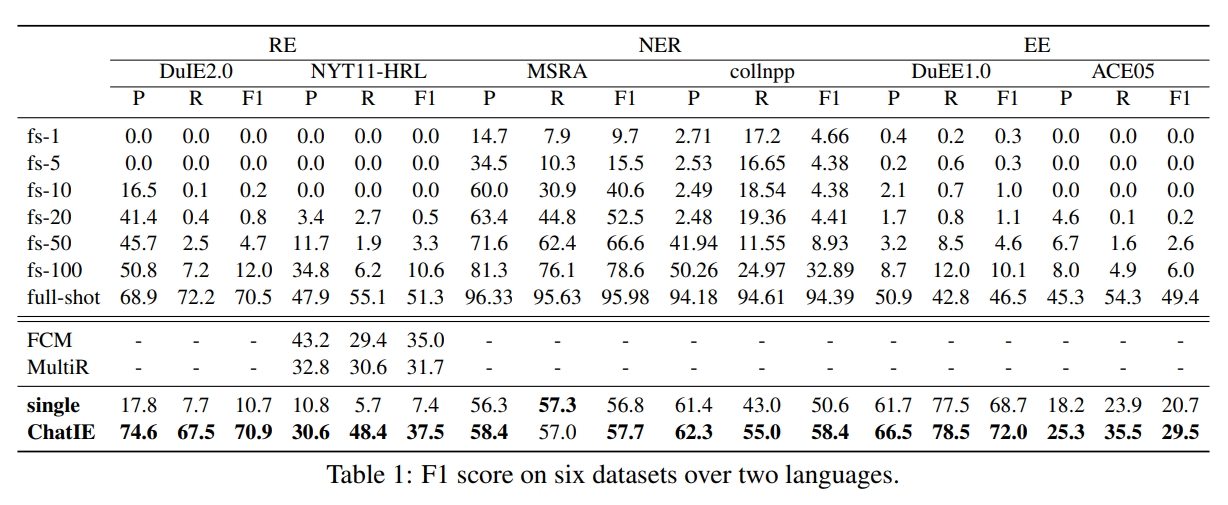
Zero-Shot Information Extraction (IE)은 예고되지 않은 텍스트에서 IE 시스템을 구축하는 것을 목표로합니다. 인간의 개입이 거의 없기 때문에 어려운 일입니다. 도전 적이지만 가치가있는 Zero-Shot IE는 데이터 라벨링이 취하는 시간과 노력을 줄입니다. 대형 언어 모델 (예 : GPT3, ChatGPT)에 대한 최근의 노력은 제로 샷 설정에서 유망한 성능을 보여 주므로 프롬프트 기반 방법을 탐색하도록 영감을줍니다. 이 작업에서는 LLM을 직접 프롬프트하여 강력한 IE 모델을 구성 할 수 있는지 묻습니다. 구체적으로, 우리는 Zero-Shot IE 작업을 2 단계 프레임 워크 (Chatie)와 함께 다중 회전 질문 응답 문제로 변환합니다. Chatgpt의 힘으로, 우리는 EntityRelation Triple Extract, Entity Recognition 및 이벤트 추출의 세 가지 IE 작업에 대한 프레임 워크를 광범위하게 평가합니다. 두 언어에 걸친 6 개의 데이터 세트에 대한 경험적 결과는 Chatie가 인상적인 성능을 달성하고 여러 데이터 세트 (예 : NYT11-HRL)에서 일부 풀 샷 모델을 능가하는 것으로 나타났습니다. 우리는 우리의 작업이 자원이 제한된 IE 모델을 구축하는 데 빛을 비출 수 있다고 생각합니다.
零样本信息抽取위한 (정보 추출, 즉) 旨在从无标注文本中建立 IE 系统 系统, 因为很少涉及人为干预, 该问题非常具有挑战性。但零样本 : 不再需要标注数据时耗费的时间和人力 不再需要标注数据时耗费的时间和人力,, 因此十分重要。近来的大规模语言模型 例如 (因此十分重要。近来的大规模语言模型 gpt-3, 채팅 gpt) 在零样本设置下取得了很好的表现 在零样本设置下取得了很好的表现, 这启发我们探索基于提示的方法来解决零样本 ee 任务。我们提出一个问题 : 不经过训练来实现零样本信息抽取是否可行?我们将零样本 不经过训练来实现零样本信息抽取是否可行?我们将零样本 不经过训练来实现零样本信息抽取是否可行?我们将零样本 ee 任务转变为一个两阶段框架的多轮问答问题 (채팅 IE), 并在三个 IE 任务中广泛评估了该框架 : 实体关系三元组抽取、命名实体识别和事件抽取。在两个语言的 6 ,, 채팅 즉, 取得了非常好的效果 甚至在几个数据集上 甚至在几个数据集上 甚至在几个数据集上 甚至在几个数据集上 (nyt11-hrl) 上超过了全监督模型的表现。我们的工作能够为有限资源下 上超过了全监督模型的表现。我们的工作能够为有限资源下 ee 系统的建立奠定基础。
업데이트 : 공식 API를 사용하면 도구가 더 빨라집니다 !!! 키가 한계를 초과하면 알려주십시오.
통지 : 응답 속도는 공식 OpenAI ChatGpt API에 따라 다릅니다. (때로는 공무원이 너무 붐비고 속도가 느려지거나 Chatgpt가 과부하가 걸립니다.) 또한, 기본 계정이 여러 사람이 동시에 사용하는 경우 계정이있을 수 있으므로 자신의 OpenAI 키를 사용하는 것이 좋습니다. 과부하.
통지 : 공식 API는 국내에서 사용할 수 없으므로 RevCHATGPT 및 V1 버전에서 API를 사용합니다. 그러나 너무 느리기 때문에 공부에 도구를 오프라인으로 사용하는 것이 좋습니다. 앞으로 API를 더 업데이트 할 것입니다 ( TODO ).
우리는 또한 GPT3.5를 기반으로 IE 도구를 제공합니다. GPT4IE에서 볼 수 있습니다.
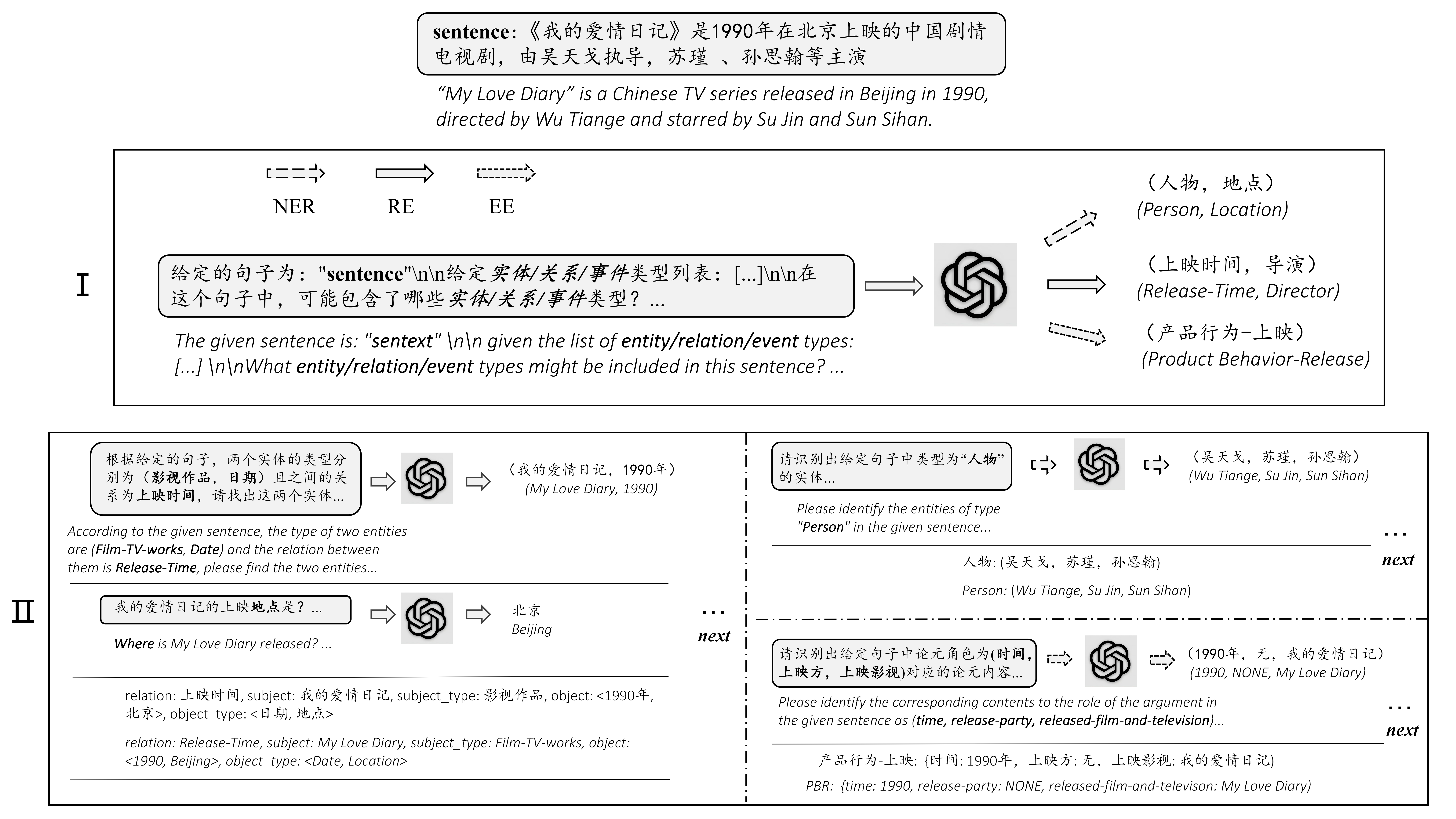
Chatie (Chatgpt와 채팅을 통한 제로 샷 정보 추출)는 오픈 소스 및 강력한 IE 도구 데모입니다. Chatgpt 및 Prompting에 의해 향상된이 회사는 원시 문장 에서 구조화 된 정보를 자동으로 추출하고 입력 문장에 대한 귀중한 심층 분석을 만드는 것을 목표로합니다. 귀중한 구조화 된 정보를 활용하면 기업이 정리하고 비즈니스를 개선하는 결정을 내릴 수 있습니다. 
우리는 다음 기능을 지원합니다.
| 일 | 이름 | lauguages |
|---|---|---|
| 답장 | 엔티티 관련 관절 추출 | 중국어, 영어 |
| 네르 | 지명 된 엔티티 recoginzation | 중국어, 영어 |
| EE | 이벤트 추출 | 중국어, 영어 |
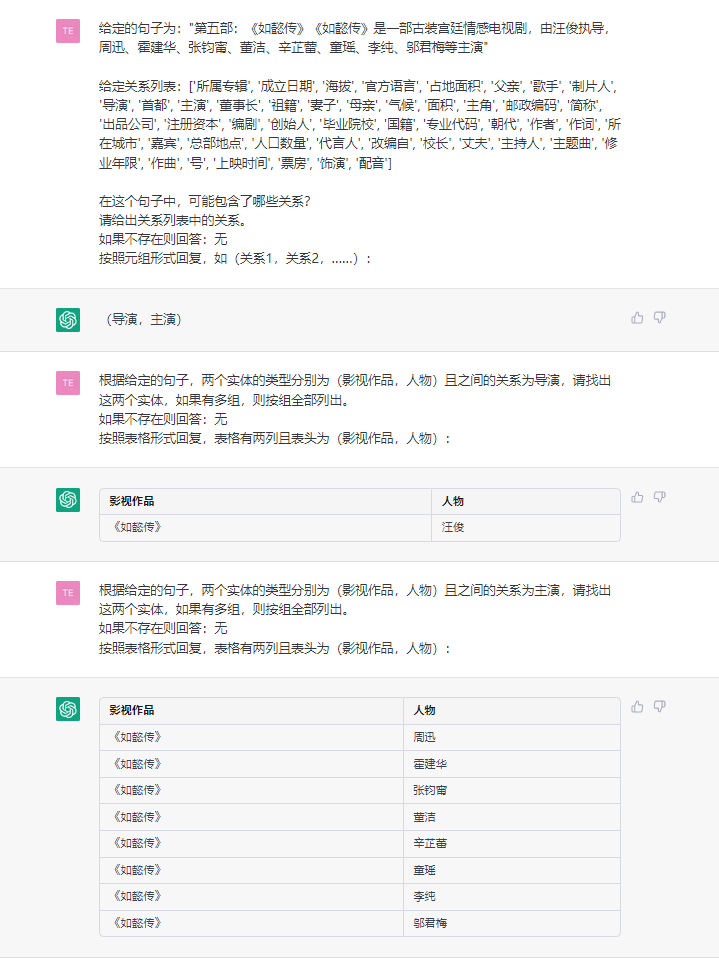
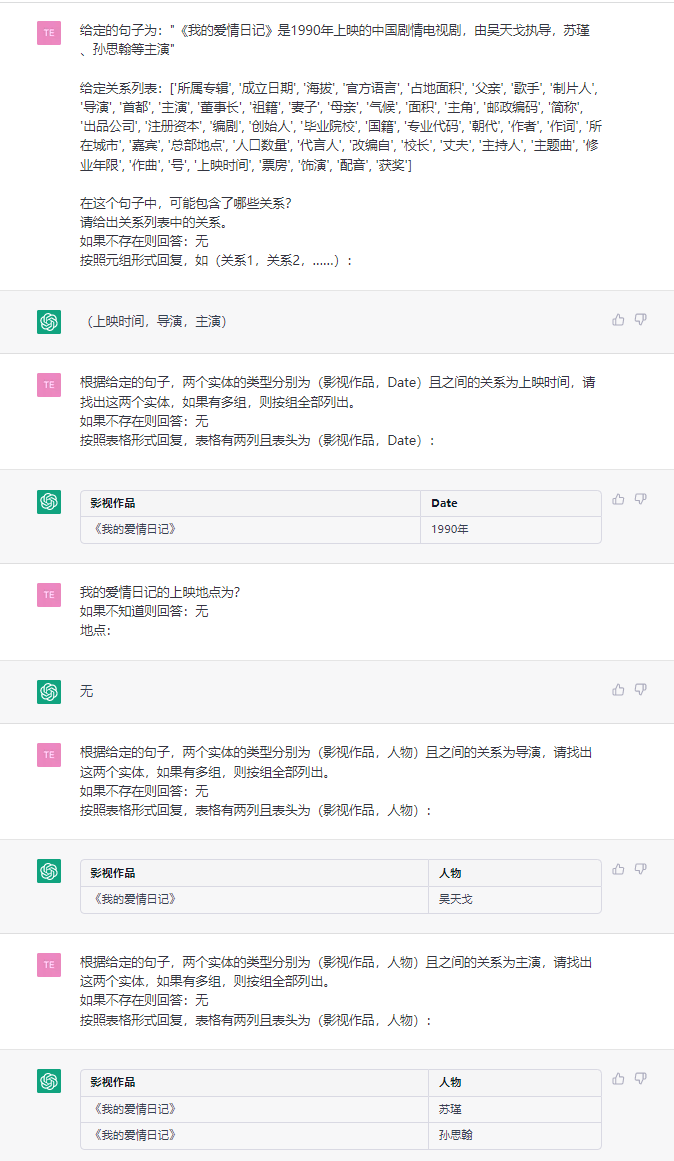
이 과제는 (중국, 자본, 베이징) , (《如懿传》, 主演, 周迅) 와 같은 일반 텍스트에서 트리플을 추출하는 것을 목표로합니다.
추신 : * 선택 사항을 표시하면 기본값을 설정합니다. 그러나 더 나은 추출을 위해서는 응용 프로그램 시나리오에 따라 세 가지 목록을 지정해야합니다.
문장 : 4 명의 다른 Google 경영진 인 George Reyes 최고 재무 책임자; Shona Brown의 비즈니스 운영 담당 수석 부사장; 데이비드 드럼 몬드 (David Drummond) 최고 법률 책임자; 그리고 제품 관리 담당 수석 부사장 인 Jonathan Rosenberg는 각각 $ 250,000의 급여를 받았습니다.
RTL : 기본값, "기본 유형"파일을 참조하십시오.
ouptut : 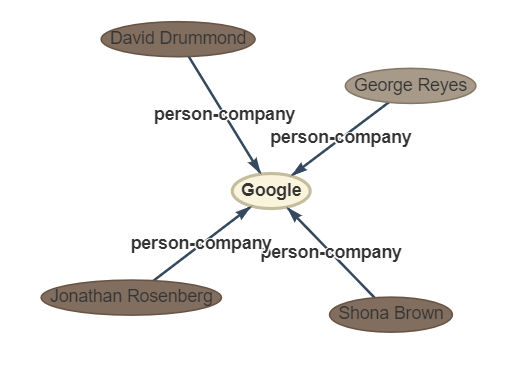
문장 : : : 《如懿传》《如懿传》是一部古装宫廷情感电视剧 : 由汪俊执导, 由汪俊执导, 周迅、霍建华、张钧甯、董洁、辛芷蕾、童瑶、李纯、邬君梅等主演。
RTL : 기본값, "기본 유형"파일을 참조하십시오.
ouptut : 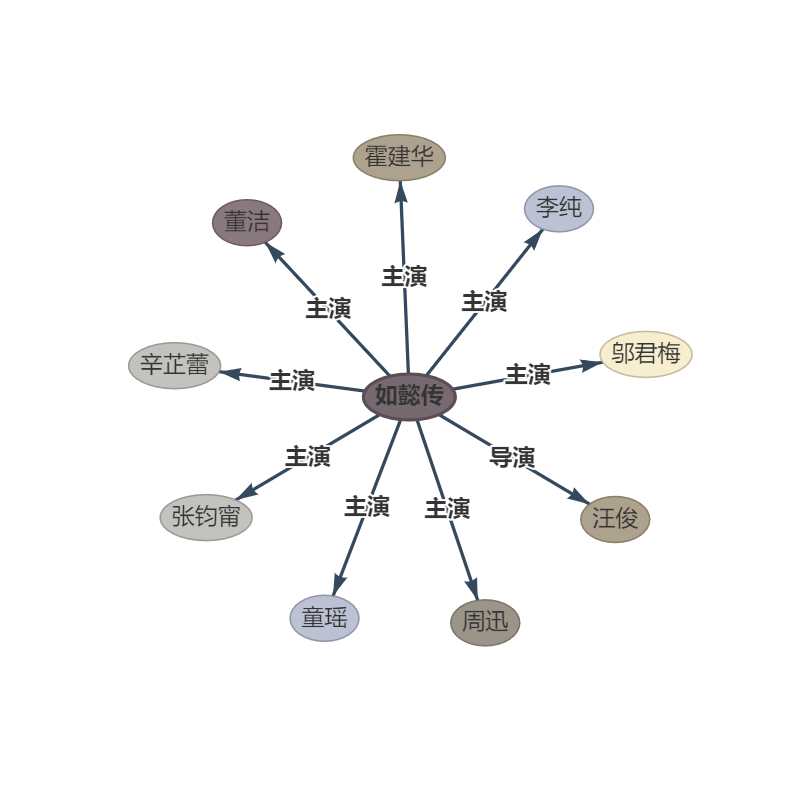
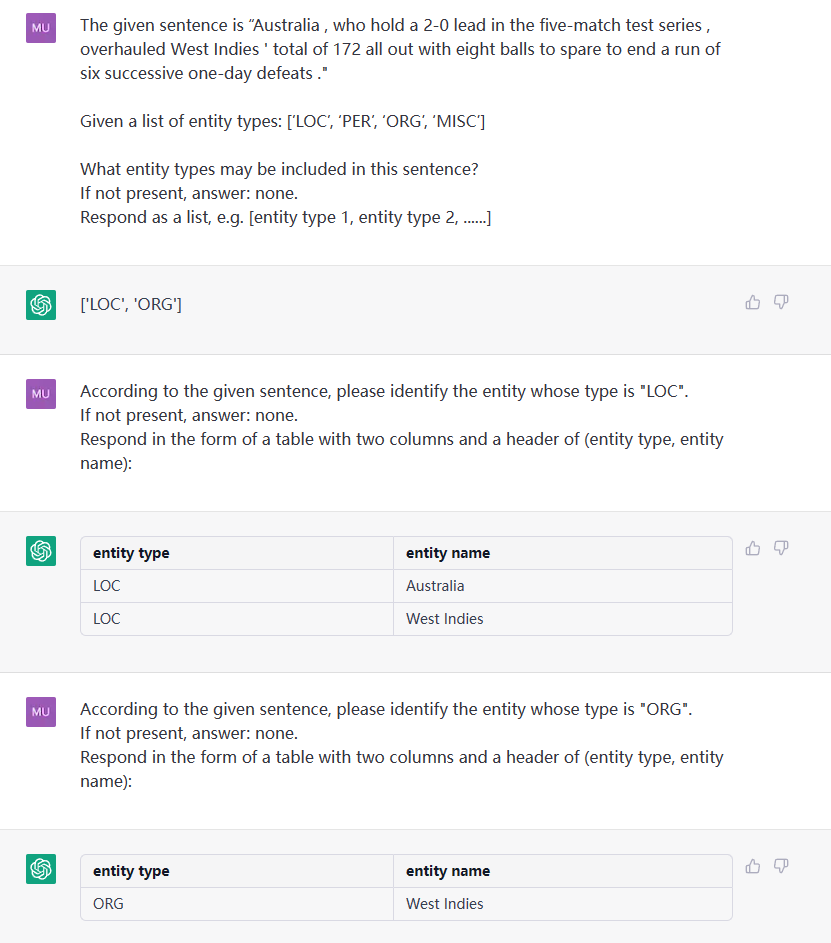
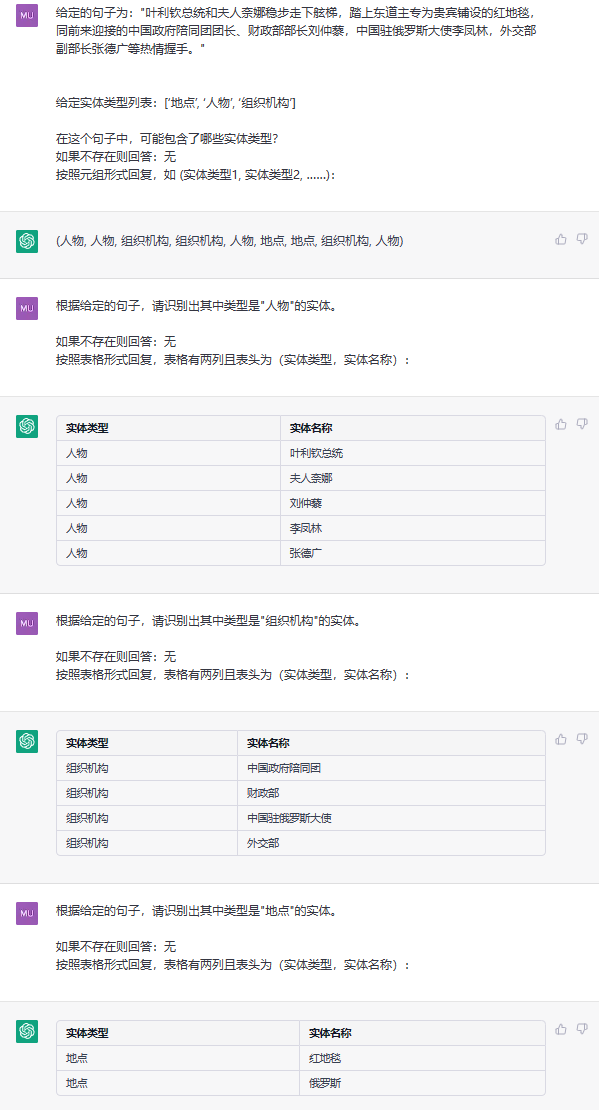
이 작업은 (Loc, Beijing) , (人物, 周恩来) 와 같은 일반 텍스트에서 실체를 추출하는 것을 목표로합니다.
문장 : James는 중국의 수도 인 베이징에서 Google에서 근무했습니다. ETL : [ 'loc', 'misc', 'org', 'per']]]
ouptut : 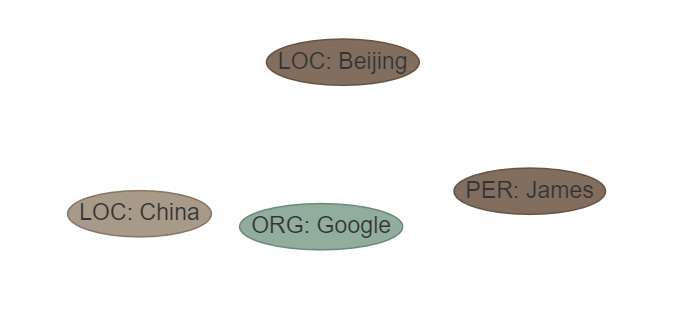
문장 :产党创立于中华民国大陆时期 ff 님, 由陈独秀和李大钊领导组织。
ETL : [ '' ','地点 ','人物 ']]]
ouptut : 
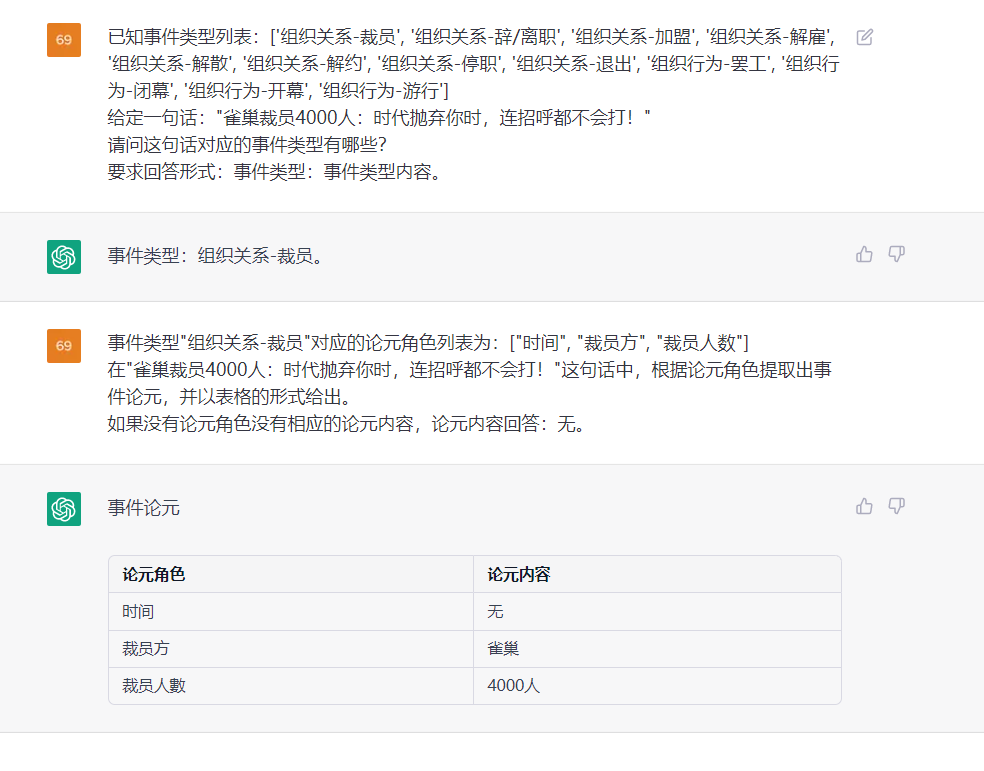
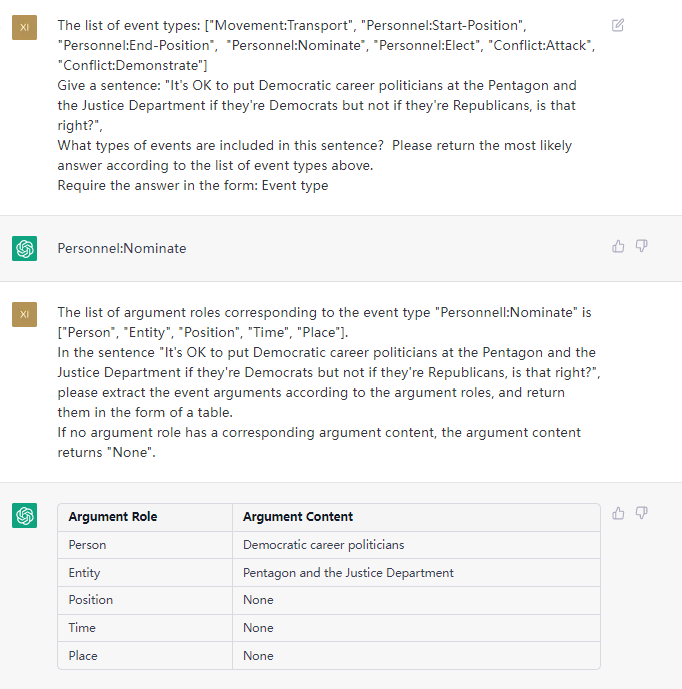
이 과제는 {생명-이발물 : {person : bob, time : toide : place}} , {竞赛行为-晋级 : {时间 : 无, 晋级方 : 西北狼, 晋级와 같은 일반 텍스트에서 이벤트를 추출하는 것을 목표로합니다.赛事 :}}} .
문장 : 어제 밥과 그의 아내는 광저우에서 이혼했습니다.
ETL : 기본값, "기본 유형"파일을 참조하십시오.
ouptut : 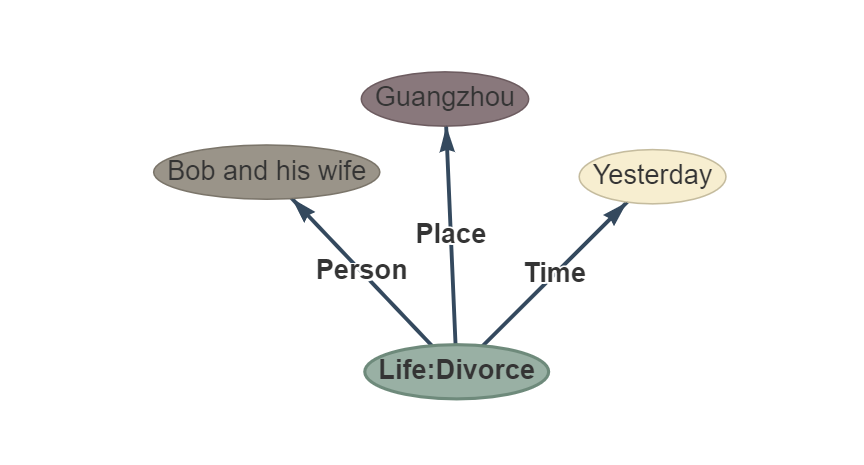
문장 : 2 2022 年卡塔尔世界杯决赛中 年卡塔尔世界杯决赛中, 阿根廷以点球大战险胜法国。
ETL : 기본값, "기본 유형"파일을 참조하십시오.
ouptut : 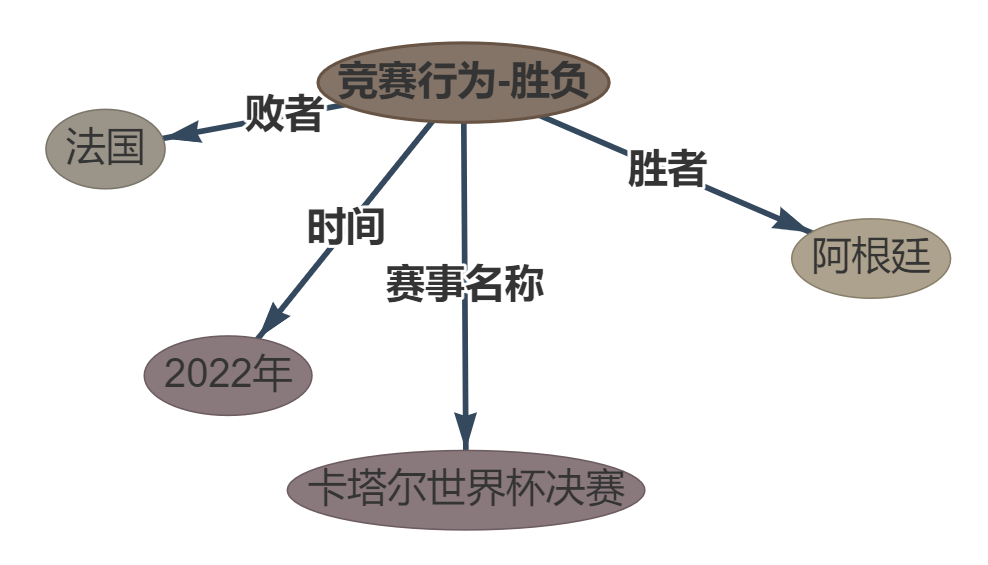
반응+플라스크
front-end 및 실행 npm install 로 필요한 종속성을 다운로드하십시오.npm run start 실행하십시오. Chatie는 새로운 브라우저 탭에서 열려야합니다.back-end 및 실행 python run.py
우리는 프로젝트를 개선하고 최고의 경험을 제공하기 위해 노력하고 있습니다. 이를 달성하기 위해 프로젝트와 상호 작용하는 방법을 이해하고 개선을위한 영역을 식별하는 데 도움이되는 데이터를 수집합니다. 당사는 귀하의 데이터의 개인 정보 및 보안을 소중히 여기며 프로젝트 개선을위한 목적으로 만 데이터를 보장합니다.
이 논문의 체크 아웃 Arxiv : 2302.10205
@article{wei2023zero,
title={Zero-Shot Information Extraction via Chatting with ChatGPT},
author={Wei, Xiang and Cui, Xingyu and Cheng, Ning and Wang, Xiaobin and Zhang, Xin and Huang, Shen and Xie, Pengjun and Xu, Jinan and Chen, Yufeng and Zhang, Meishan and others},
journal={arXiv preprint arXiv:2302.10205},
year={2023}
}


