Awesome Code LLM
1.0.0
이것은 NLP 및 소프트웨어 엔지니어링의 관점을 통일하는 TMLR 설문 조사를위한 리포입니다. 코드의 언어 모델에 대한 설문 조사 - 코드에 대한 LLM 연구에 대한 포괄적 인 검토. 각 카테고리의 작업은 시간순으로 주문됩니다. 머신 러닝에 대한 기본 이해가 있지만 NLP에 익숙하지 않은 경우 섹션 9에서 권장 판독 값 목록도 제공합니다.
[2024/11/28] 특집 논문 :
Nanyang Technological University의 의사 피드백으로 추론을위한 선호도 최적화.
Scribeagent : Scribe의 프로덕션 규모 워크 플로 데이터를 사용하는 전문 웹 에이전트를 향해.
계획 중심 프로그래밍 : 멜버른 대학교의 대형 언어 모델 프로그래밍 워크 플로우.
Sun Yat-Sen University의 Rust를 대상으로하는 저장소 수준 코드 번역 벤치 마크.
사전 경험 활용 : 중국 과학 기술 대학의 텍스트 간 SQL을위한 확장 가능한 보조 지식 기반.
Codexembed : Salesforce AI Research의 다중 태스크 코드 검색을위한 일반인 임베딩 모델 패밀리.
Prosec : Purdue University의 사전 보안 정렬을 가진 강화 코드 LLM.
[2024/10/22] 우리는 2024 년 9 월과 10 월부터 Wechat 기사에서 70 개의 논문을 편집했습니다.
[2024/09/06] 우리의 설문 조사는 TMLR (Machine Learning Research) 거래에 의한 출판을 위해 승인되었습니다.
[2024/09/14] 우리는 2024 년 8 월부터 57 개의 논문 (ACL 2024에 발표 된 48 개 포함)을 하나의 WeChat 기사에서 편집했다.
이 저장소에서 누락 된 용지를 발견하거나 카테고리에 잘못 배치되었거나 저널/컨퍼런스 정보에 대한 참조가없는 경우 주저하지 말고 문제를 만들지 마십시오. 이 repo가 도움이되면 설문 조사를 인용하십시오.
@article{zhang2024unifying,
title={Unifying the Perspectives of {NLP} and Software Engineering: A Survey on Language Models for Code},
author={Ziyin Zhang and Chaoyu Chen and Bingchang Liu and Cong Liao and Zi Gong and Hang Yu and Jianguo Li and Rui Wang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=hkNnGqZnpa},
note={}
}
설문 조사
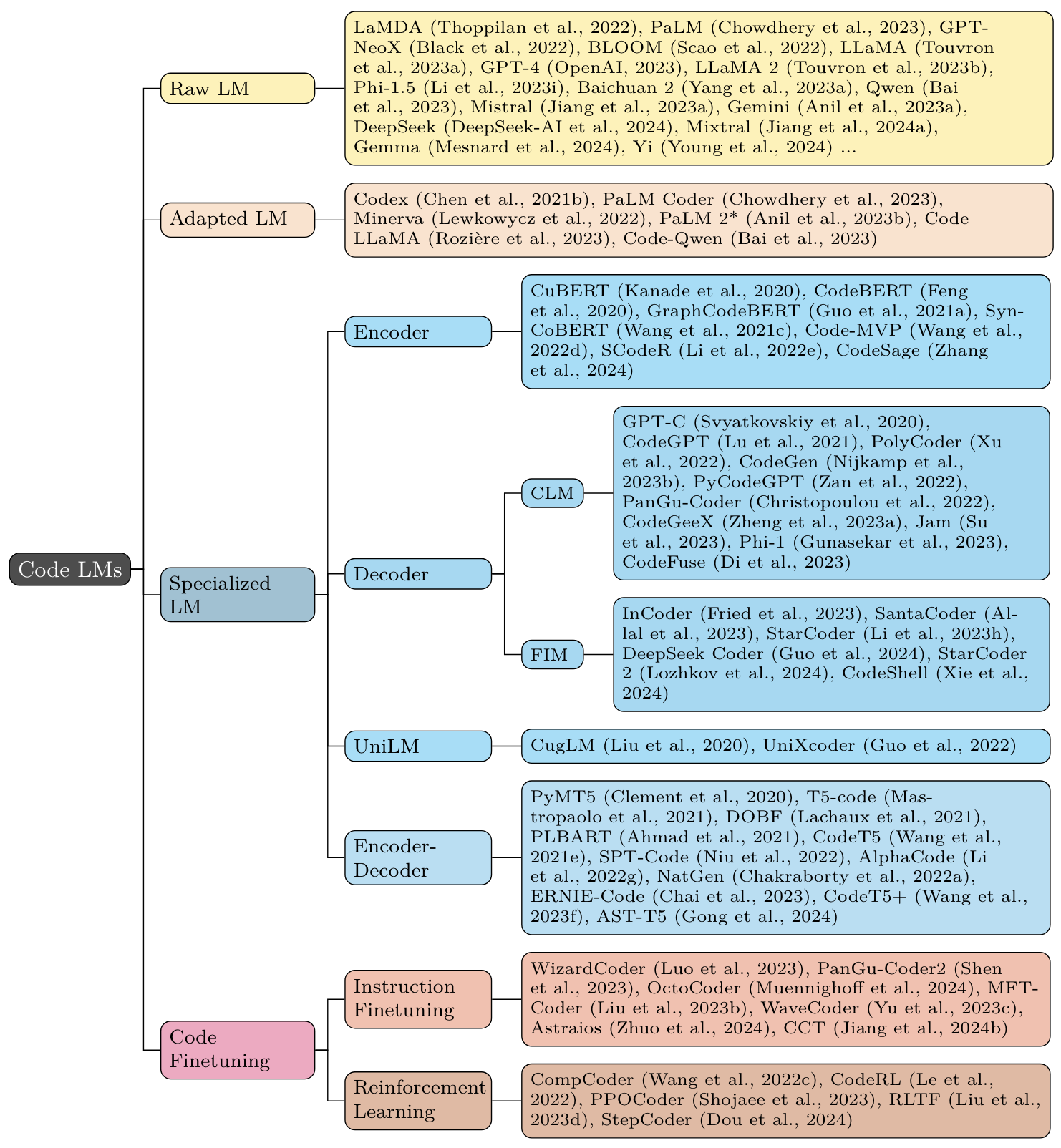
모델
2.1 기본 LLMS 및 사전 조정 전략
2.2 기존 LLM 코드에 적합합니다
2.3 코드에 대한 일반적인 사전 조정
2.4 (명령어) 코드에 미세 조정
2.5 코드에 대한 강화 학습
코딩이 추론을 충족 할 때
3.1 추론 코딩
3.2 코드 시뮬레이션
3.3 코드 에이전트
3.4 대화식 코딩
3.5 프론트 엔드 내비게이션
저수고, 저수준 및 도메인 별 언어에 대한 코드 LLM
다운 스트림 작업을위한 방법/모델
프로그램 작성
테스트 및 배포
DevOps
요구 사항
AI 생성 코드 분석
인간 -LLM 상호 작용
데이터 세트
8.1 사전 여지
8.2 벤치 마크
권장 판독 값
소환
스타 역사
우리와 함께하십시오
우리는 유사한 주제에 대한 최근 몇 가지 설문 조사를 나열합니다. 코드의 언어 모델에 관한 것이지만 1-2 NLP 측에 중점을 둡니다. 3-6 SE 측에 중점을 둡니다. 7-11은 우리 이후에 풀려납니다.
"대형 언어 모델이 NL2 코드를 충족합니다 : 설문 조사"[2022-12] [ACL 2023] [논문]
"신경 코드 인텔리전스에 대한 사전 미리 언어 모델에 대한 설문 조사"[2022-12] [논문]
"소스 코드의 미리 훈련 된 모델의 경험적 비교"[2023-02] [ICSE 2023] [논문]
"소프트웨어 공학을위한 대형 언어 모델 : 체계적인 문헌 검토"[2023-08] [논문]
"소프트웨어 엔지니어링 작업에서 큰 언어 모델에 대한 이해를 향해"[2023-08] [논문]
"코드 인텔리전스를위한 언어 모델의 함정 : 분류 및 설문 조사"[2023-10] [논문]
"소프트웨어 엔지니어링을위한 대형 언어 모델에 대한 설문 조사"[2023-12] [논문]
"코드 인텔리전스를위한 딥 러닝 : 설문 조사, 벤치 마크 및 툴킷"[2023-12] [논문]
"신경 코드 인텔리전스 설문 조사 : 패러다임, 발전 및 그 이상"[2024-03] [논문]
"업무 사람들이 프롬프트 : 소프트웨어 검증 및 위조 접근법에서 LLM 다운 스트림 작업의 분류"[2024-04] [논문]
"자동 프로그래밍 : 대형 언어 모델 및 그 너머"[2024-05] [논문]
"소프트웨어 엔지니어링 및 기초 모델 : 재단 모델 배심원을 사용한 업계 블로그의 통찰력"[2024-10] [논문]
"딥 러닝 기반 소프트웨어 엔지니어링 : 진보, 도전 및 기회"[2024-10] [논문]
이 LLM은 코드를 위해 특별히 훈련되지 않았지만 다양한 코딩 기능을 보여주었습니다.
Lamda : "Lamda : 대화 응용 프로그램을위한 언어 모델"[2022-01] [논문]
Palm : "Palm : 경로로 언어 모델링 스케일링"[2022-04] [JMLR] [논문]
GPT-NEOX : "GPT-NEOX-20B : 오픈 소스 자동 회귀 언어 모델"[2022-04] [ACL 2022 LLM 생성의 도전 및 관점에 대한 워크숍] [논문] [repo]
블룸 : "블룸 : 176B 패러 미터 오픈 액세스 다국어 언어 모델"[2022-11] [논문] [모델]
라마 : "라마 : 개방적이고 효율적인 기초 언어 모델"[2023-02] [논문]
GPT-4 : "GPT-4 기술 보고서"[2023-03] [논문]
라마 2 : "라마 2 : 오픈 파운데이션 및 미세 조정 된 채팅 모델"[2023-07] [종이] [repo]
PHI-1.5 : "교과서는 전부입니다 II : PHI-1.5 기술 보고서"[2023-09] [논문] [모델]
Baichuan 2 : "Baichuan 2 : 대규모 언어 모델 오픈"[2023-09] [논문] [Repo]
Qwen : "Qwen Technical Report"[2023-09] [논문] [Repo]
MISTRAL : "Mistral 7B"[2023-10] [논문] [repo]
Gemini : "Gemini : 유능한 멀티 모달 모델의 가족"[2023-12] [논문]
PHI-2 : "PHI-2 : 작은 언어 모델의 놀라운 힘"[2023-12] [블로그]
Yayi2 : "Yayi 2 : 다국어 오픈 소스 대형 언어 모델"[2023-12] [논문] [Repo]
Deepseek : "Deepseek LLM : 장기주의로 오픈 소스 언어 모델 스케일링"[2024-01] [논문] [Repo]
Mixtral : "전문가의 Mixtral"[2024-01] [논문] [블로그]
Deepseekmoe : "Deepseekmoe : Experts 혼합 언어 모델의 궁극적 인 전문가 전문 분야를 향해"[2024-01] [Paper] [Repo]
오리온 : "오리온 -14B : 오픈 소스 다국어 대형 언어 모델"[2024-01] [종이] [repo]
Olmo : "Olmo : 언어 모델의 과학을 가속화"[2024-02] [논문] [Repo]
Gemma : "Gemma : Gemini 연구 및 기술을 기반으로 한 개방형 모델"[2024-02] [Paper] [Blog]
클로드 3 : "클로드 3 모델 패밀리 : Opus, Sonnet, Haiku"[2024-03] [논문] [블로그]
YI : "YI : 01.ai의 개방형 기초 모델"[2024-03] [종이] [Repo]
Poro : "Poro 34B와 다국어의 축복"[2024-04] [논문] [모델]
Jetmoe : "Jetmoe : 0.1M 달러로 LLAMA2 성능에 도달"[2024-04] [Paper] [Repo]
Llama 3 : "Llama 3 모델의 무리"[2024-04] [Blog] [Repo] [종이]
Reka Core : "Reka Core, Flash 및 Edge : 일련의 강력한 멀티 모달 언어 모델"[2024-04] [논문]
PHI-3 : "PHI-3 기술 보고서 : 휴대 전화에서 로컬로 유능한 언어 모델"[2024-04] [논문]
OpenELM : "OpenElm : 오픈 소스 교육 및 추론 프레임 워크를 갖춘 효율적인 언어 모델 패밀리"[2024-04] [논문] [Repo]
Tele-FLM : "Tele-FLM 기술 보고서"[2024-04] [논문] [모델]
Deepseek-V2 : "Deepseek-V2 : 강력하고 경제적이며 효율적인 경험적 혼합 언어 모델"[2024-05] [Paper] [Repo]
Gecko : "Gecko : 영어, 코드 및 한국을위한 생성 언어 모델"[2024-05] [논문] [모델]
Map-Neo : "Map-Neo : 유능하고 투명한 이중 언어 대형 언어 모델 시리즈"[2024-05] [논문] [Repo]
Skywork-Moe : "Skywork-Moe : Experts 혼합 언어 모델을위한 훈련 기술에 대한 깊은 다이빙"[2024-06] [논문]
Xmodel-LM : "Xmodel-LM 기술 보고서"[2024-06] [논문]
GEB : "GEB-1.3B : 열린 경량 대형 언어 모델"[2024-06] [논문]
HARE : "Hare : Human Priors, 소규모 언어 모델 효율의 열쇠"[2024-06] [논문]
DCLM : "DataComp-LM : 언어 모델에 대한 차세대 교육 세트를 찾아서"[2024-06] [논문]
Nemotron-4 : "Nemotron-4 340B 기술 보고서"[2024-06] [논문]
Chatglm : "Chatglm : GLM-130B에서 GLM-4까지의 대형 언어 모델 패밀리"[2024-06] [논문]
Yulan : "Yulan : 오픈 소스 대형 언어 모델"[2024-06] [논문]
Gemma 2 : "Gemma 2 : 실용적인 크기의 오픈어 모델 향상"[2024-06] [논문]
H2O-Danube3 : "H2O-Danube3 기술 보고서"[2024-07] [논문]
QWEN2 : "QWEN2 기술 보고서"[2024-07] [논문]
Allam : "Allam : 아랍어 및 영어를위한 대형 언어 모델"[2024-07] [논문]
SEALLMS 3 : "SEALLMS 3 : 동남아시아 언어를위한 열린 기초 및 채팅 다국어 대형 언어 모델"[2024-07] [논문]
AFM : "Apple Intelligence Foundation 언어 모델"[2024-07] [논문]
"코드 또는 코드를 코드하지 않으면, 사전 훈련에서 코드의 영향 탐색"[2024-08] [논문]
Olmoe : "Olmoe : 열린 혼합 언어 모델"[2024-09] [논문]
"코드 사전 조정은 언어 모델 작업 성능에 어떤 영향을 미칩니 까?" [2024-09] [종이]
Eurollm : "Eurollm : 유럽을위한 다국어 언어 모델"[2024-09] [논문]
"사전 훈련 단계에서 어떤 프로그래밍 언어와 어떤 기능이 다운 스트림 논리 추론 성능에 영향을 미칩니 까?" [2024-10] [종이]
GPT-4O : "GPT-4O 시스템 카드"[2024-10] [논문]
Hunyuan-Large : "Hunyuan-Large : Tencent에 의해 520 억 개의 활성화 된 매개 변수를 가진 오픈 소스 MOE 모델"[2024-11] [논문]
Crystal : "Crystal : 언어 및 코드에 대한 LLM 능력을 조명"[2024-11] [논문]
Xmodel-1.5 : "Xmodel-1.5 : 1B 스케일 다국어 LLM"[2024-11] [용지]
이 모델은 코드 관련 데이터에 대해 추가로 사전에 걸린 일반 목적 LLM입니다.
Codex (GPT-3) : "코드에서 훈련 된 대형 언어 모델 평가"[2021-07] [논문]
Palm Coder (Palm) : "Palm : 경로로 언어 모델링을 스케일링"[2022-04] [JMLR] [논문]
Minerva (Palm) : "언어 모델의 정량적 추론 문제 해결"[2022-06] [논문]
Palm 2 * (Palm 2) : "Palm 2 기술 보고서"[2023-05] [종이]
Code Llama (Llama 2) : "Code Llama : Code for Code Open Foundation 모델"[2023-08] [Paper] [Repo]
여우 원숭이 (llama 2) : "여우 원숭이 : 언어 에이전트에 대한 자연 언어 및 코드 조화"[2023-10] [ICLR 2024 스포트라이트] [논문]
BTX (llama 2) : "Branch-Train-Mix : 전문가 LLM을 혼합 Experts LLM에 혼합"[2024-03] [논문]
Hirope : "Hirope : 계층 적 위치를 사용한 코드 모델의 길이 외삽"[2024-03] [ACL 2024] [논문]
"고도로 전문화 된 언어 모델을 융합하여 동시에 텍스트, 코드 및 수학을 마스터 링"[2024-03] [논문]
CodeGemma : "CodeGemma : 젬마를 기반으로 한 오픈 코드 모델"[2024-04] [논문] [모델]
DeepSeek-Coder-V2 : "DeepSeek-Coder-V2 : 코드 인텔리전스에서 폐쇄 소스 모델의 장벽을 깨기"[2024-06] [논문]
"협업 코드 생성 모델의 약속과 위험 : 효율성과 암기의 균형을 잡는다"[2024-09] [논문]
QWEN2.5-CODER : "QWEN2.5-CODER 기술 보고서"[2024-09] [논문]
Lingma SWE-GPT : "Lingma SWE-GPT : 자동화 된 소프트웨어 개선을위한 개방형 개발 프로세스 중심 언어 모델"[2024-11] [논문]
이 모델은 일반적인 언어 모델링을 위해 기존 목표를 사용하여 처음부터 전기 된 변압기 인코더, 디코더 및 인코더 디코더입니다.
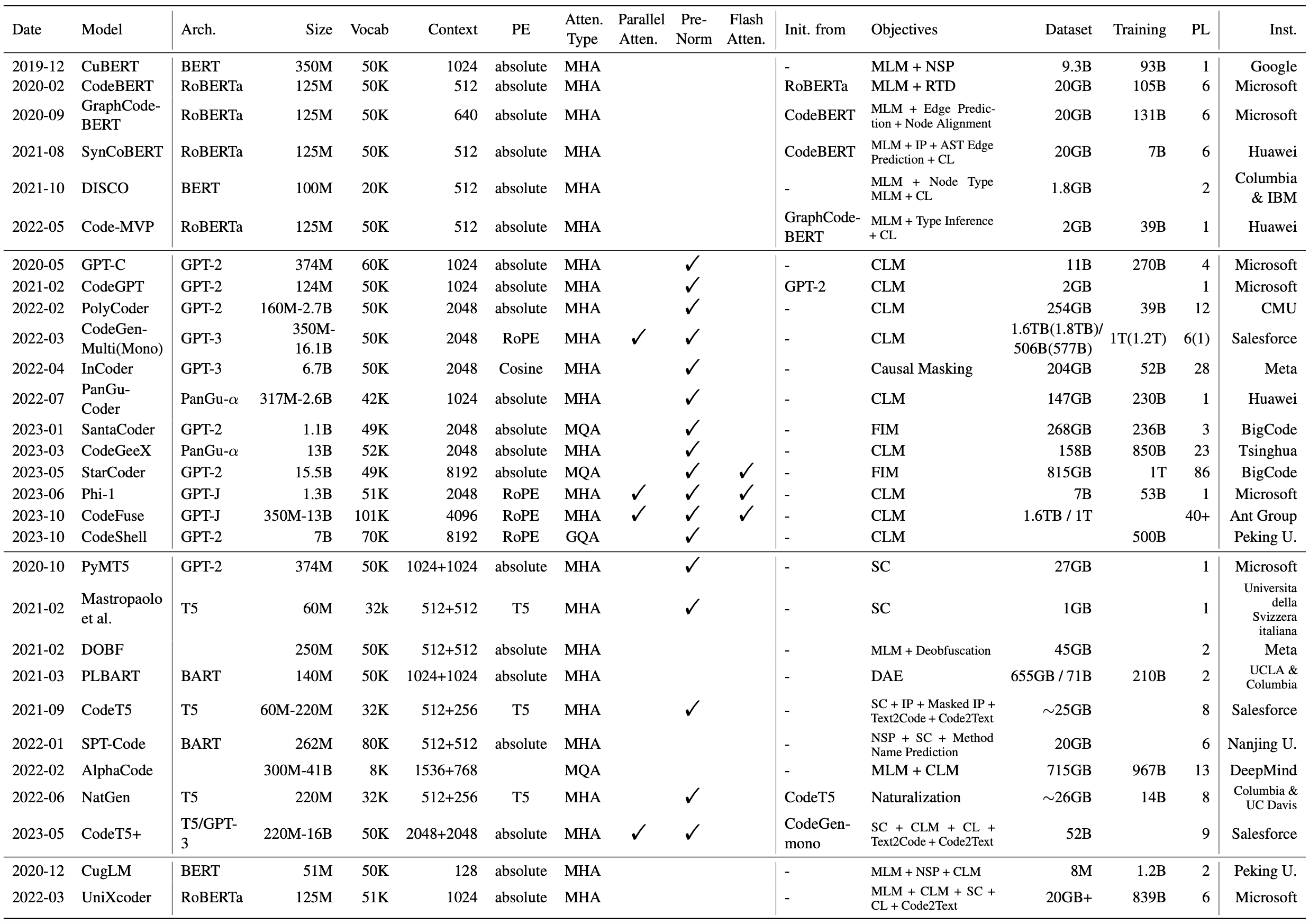
Cubert (MLM + NSP) : "소스 코드의 상황에 맞는 임베딩을 배우고 평가하고 평가"[2019-12] [ICML 2020] [논문] [repo]
Codebert (MLM + RTD) : "Codebert : 프로그래밍 및 자연 언어를위한 미리 훈련 된 모델"[2020-02] [EMNLP 2020 결과] [논문] [Repo]
GraphCodebert (MLM + DFG Edge Prediction + DFG 노드 정렬) : "GraphCodebert : 데이터 흐름이있는 사전 훈련 코드 표현"[2020-09] [ICLR 2021] [PAPER] [Repo]
SyncObert (MLM + 식별자 예측 + AST 에지 예측 + 대비 학습) : "SyncoBert : 코드 표현을위한 구문 유도 다중 모달 대비 사전 훈련"[2021-08] [논문]
디스코 (MLM + 노드 유형 MLM + 대비 학습) : "학습 (DIS)-프로그램 대조에서 소스 코드의 유사성"[2021-10] [ACL 2022] [논문]
Code-MVP (MLM + Type Exection + 대비 학습) : "Code-MVP : 대조적 인 사전 훈련으로 여러 뷰에서 소스 코드를 나타내는 학습"[2022-05] [NAACL 2022 기술 트랙] [논문]
Codesage (MLM + Deobfuscation + 대비 학습) : "규모의 코드 표현 학습"[2024-02] [ICLR 2024] [논문]
Colsbert (MLM) : "코드 이해 모델 뒤에 법률 스케일링"[2024-02] [논문]
GPT-C (CLM) : "Intellicode Compose : Transformer를 사용한 코드 생성"[2020-05] [ESEC/FSE 2020] [논문]
CodeGpt (CLM) : "CodexGlue : 코드 이해 및 생성을위한 기계 학습 벤치 마크 데이터 세트"[2021-02] [Neurips 데이터 세트 및 벤치 마크 2021] [논문] [Repo]
CodeParrot (CLM) [2021-12] [블로그]
Polycoder (CLM) : "코드의 큰 언어 모델에 대한 체계적인 평가"[2022-02] [DL4C@ICLR 2022] [논문] [Repo]
CodeGen (CLM) : "CodeGen : 다중 회전 프로그램 합성이있는 코드를위한 개방형 대형 언어 모델"[2022-03] [ICLR 2023] [논문] [Repo]
인코더 (인과 마스킹) : "인코더 : 코드 충전 및 합성을위한 생성 모델"[2022-04] [ICLR 2023] [논문] [repo]
pycodegpt (clm) : "Cert : 라이브러리 지향 코드 생성을위한 스케치에서 지속적인 사전 훈련"[2022-06] [ijcai-ecai 2022] [paper] [repo]
Pangu-Coder (CLM) : "Pangu-Coder : 기능 수준 언어 모델링을 사용한 프로그램 합성"[2022-07] [논문]
Santacoder (FIM) : "Santacoder : 별에 닿지 마십시오!" [2023-01] [종이] [모델]
CodeGeex (CLM) : "CodeGeex : HumaneVal-X에 다국어 평가를 가진 코드 생성을위한 미리 훈련 된 모델"[2023-03] [논문] [repo]
Starcoder (fim) : "Starcoder : 소스가 당신과 함께 있기를 바랍니다!" [2023-05] [종이] [모델]
PHI-1 (CLM) : "교과서가 필요합니다"[2023-06] [논문] [모델]
Codefuse (CLM) : "CodeFuse-13B : 사전 해당 다국어 코드 대형 언어 모델"[2023-10] [논문] [모델]
DeepSeek Coder (CLM+FIM) : "DeepSeek-Coder : 대형 언어 모델이 프로그래밍을 충족 할 때-코드 인텔리전스의 상승"[2024-01] [논문] [Repo]
StarCoder2 (CLM+FIM) : "StarCoder 2와 Stack v2 : The Next Generation"[2024-02] [Paper] [Repo]
Codeshell (CLM+FIM) : "Codeshell Technical Report"[2024-03] [논문] [Repo]
CodeQwen1.5 [2024-04] [블로그]
화강암 : "화강암 코드 모델 : 코드 인텔리전스를위한 개방형 기초 모델"[2024-05] [Paper] "화강암 코드 모델 스케일링 128K 컨텍스트"[2024-07] [용지]
NT-Java : "좁은 변압기 : 데스크탑 용 스타 코더 기반 Java-LM"[2024-07] [용지]
Arctic-SnowCoder : "Arctic-SnowCoder : 코드 사전 조정에서 고품질 데이터를 탈취하는"[2024-09] [논문]
AixCoder : "AixCoder-7B : 코드 완료를위한 가볍고 효과적인 대형 언어 모델"[2024-10] [논문]
OpenCoder : "OpenCoder : 최상위 코드 대형 언어 모델을위한 오픈 요리 책"[2024-11] [논문]
PYMT5 (SPAN 부패) : "PYMT5 : 변압기가있는 자연 언어 및 파이썬 코드의 다중 모드 번역"[2020-10] [EMNLP 2020] [용지]
Mastropaolo et al. (MLM + Deobfuscation) : "DOBF : 프로그래밍 언어에 대한 Deobfuscation 사전 훈련 목표"[2021-02] [ICSE 2021] [논문] [Repo]
DOBF (SPAN FURUPTION) : "코드 관련 작업을 지원하기 위해 텍스트-텍스트 전송 변압기 사용을 연구"[2021-02] [Neurips 2021] [논문] [Repo]
Plbart (DAE) : "프로그램 이해 및 세대를위한 통합 사전 훈련"[2021-03] [NAACL 2021] [논문] [Repo]
Codet5 (Span Fureption + Identifier 태깅 + 마스크 된 식별자 예측 + Text2Code + Code2Text) : "CodET5 : Code-AWARE CODE 이해 및 생성을위한 통합 된 미리 훈련 된 인코더 디코더 모델"[2021-09] [EMNLP 2021] [용지] [Repo]
SPT 코드 (SPAN 부패 + NSP + 메소드 이름 예측) : "SPT 코드 : 소스 코드 표현 학습을위한 시퀀스-시퀀스 사전 훈련"[2022-01] [ICSE 2022 기술 트랙] [논문]
알파 코드 (MLM + CLM) : "알파 코드를 사용한 경쟁 수준 코드 생성"[2022-02] [Science] [논문] [블로그]
Natgen (코드 귀화) : "Natgen :"자화 "소스 코드를 통한 생성 사전 훈련"[2022-06] [ESEC/FSE 2022] [논문] [Repo]
어니 코드 (스팬 부패 + 피벗 기반 번역 LM) : "어니 코드 : 프로그래밍 언어에 대한 영어 중심의 교차-언어 전 사전 조절을 넘어서
Codet5 + (SPAN 부패 + CLM + 텍스트 코드 대비 학습 + 텍스트 코드 번역) : "Codet5 + : 코드 이해 및 생성을위한 큰 코드 대형 언어 모델"[2023-05] [EMNLP 2023] [논문] [Repo]
AST-T5 (SPAN 부패) : "AST-T5 : 코드 생성 및 이해를위한 구조 인식 사전 조정"[2024-01] [ICML 2024] [논문]
CUGLM (MLM + NSP + CLM) : "코드 완료를위한 다중 작업 학습 기반 사전 훈련 된 언어 모델"[2020-12] [ASE 2020] [논문]
UnixCoder (MLM + NSP + CLM + SPAN 부패 + 대비 학습 + Code2Text) : "UnixCoder : 코드 표현을위한 통합 교차 모달 사전 훈련"[2022-03] [ACL 2022] [논문] [Repo]
이 모델은 코드 LLM의 용량을 향상시키기 위해 미세 조정 기술을 적용합니다.
WizardCoder (Starcoder + Evol-Instruct) : "WizardCoder : 코드 강화 코드의 대형 언어 모델 강화"[2023-06] [ICLR 2024] [논문] [Repo]
Pangu-Coder 2 (StarCoder + Evol-Instruct + RRTF) : "Pangu-Coder2 : 순위 피드백을 갖춘 코드에 대한 대형 언어 모델 향상"[2023-07] [논문]
Octocoder (starcoder) / Octogeex (CodegeEx2) : "Octopack : 명령 튜닝 코드 대형 언어 모델"[2023-08] [ICLR 2024 스포트라이트] [용지] [repo]
"교육 단계에서 코드 데이터가 LLMS 추론을 돕는다"[2023-09] [ICLR 2024 스포트라이트] [논문]
InstructCoder : "InstructCoder : 코드 편집을위한 대형 언어 모델을 튜닝"[논문] [Repo]
MFTCODER : "MFTCODER : 멀티 태스킹 미세 조정으로 코드 LLM을 높이기"[2023-11] [KDD 2024] [용지] [Repo]
"정확한 코드 생성기 훈련을위한 LLM 지원 코드 청소"[2023-11] [ICLR 2024] [논문]
Magicoder : "Magicoder : OSS-Instruct로 코드 생성 권한을 부여"[2023-12] [ICML 2024] [논문]
WaveCoder : "WaveCoder : 명령 튜닝에 의한 코드 대형 언어 모델에 대한 광범위하고 다재다능한 향상"[2023-12] [ACL 2024] [논문]
Astraios : "Astraios : 매개 변수 효율적인 명령 튜닝 코드 대형 언어 모델"[2024-01] [논문]
Dolphcoder : "Dolphcoder : Echo-Rocating 코드 다양하고 다목적 명령 튜닝을 가진 대형 언어 모델"[2024-02] [ACL 2024] [논문]
Safecoder : "보안 코드 생성을위한 명령 튜닝"[2024-02] [ICML 2024] [논문]
"코드가 필요 : 주석 확대로 코드 LLM 향상"[ACL 2024 결과] [논문]
CCT : "코드 대형 언어 모델에 대한 코드 비교 튜닝"[2024-03] [논문]
SAT : "코드 미리 훈련 된 모델을위한 구조 인식 미세 조정"[2024-04] [논문]
Codefort : "Codefort : 코드 생성 모델을위한 강력한 교육"[2024-04] [논문]
XFT : "XFT : 단순히 업 사이클 혼합물을 병합하여 코드 명령 튜닝의 힘 잠금 해제"[2024-04] [ACL 2024] [논문] [Repo]
aiev-instruct : "Autocoder : AIEV-Intruct를 사용하여 코드 대형 언어 모델 향상"[2024-05] [논문]
ALCHEMISTCODER : "ALCHEMISTCODER : 멀티 소스 데이터에 대한 후시 조정에 의한 조화 및 유도 코드 기능"[2024-05] [논문]
"상징적 인 작업에서 코드 생성에 이르기까지 : 다각화는 더 나은 작업 수행자를 산출합니다"[2024-05] [논문]
"대규모 언어 모델 추론에 대한 데이터 지침을 미세 조정하는 데 미치는 영향을 공개"[2024-05] [논문]
Plum : "Plum : 선호도 학습과 테스트 사례가 더 나은 코드 언어 모델을 생성합니다"[2024-06] [논문]
McOder : "McEval : 대규모 다국어 코드 평가"[2024-06] [논문]
"훈련 코드의 대형 언어 모델에서 감독 된 미세 조정 및 강화 학습 간의 상관 관계를 잠금 해제"[2024-06] [논문]
코드 최적화 : "코드-최적화 : 정확성 및 효율성을위한 자체 생성 환경 설정 데이터"[2024-06] [논문]
유니 코더 : "유니 코더 : 범용 코드를 통한 스케일링 코드 대형 언어 모델"[2024-06] [ACL 2024] [논문]
"Brevity는 재치의 영혼입니다 : 코드 생성을위한 긴 파일을 가지 치기"[2024-06] [논문]
"코드가 적고, 더 정렬 : 데이터 가지 치기로 코드 생성을위한 효율적인 LLM 미세 조정"[2024-07] [논문]
버터 세 코더 : "비버 세 코더 : 역시 구조로 명령어 조정 코드 LLM의 힘을 발휘"[2024-07] [논문]
"소규모 코드 언어 모델에 대한 커리큘럼 학습"[2024-07] [논문]
유전 적 강의 : "유전자 명령 : 대형 언어 모델에 대한 코딩 지침의 합성 생성 확장"[2024-07] [논문]
DatASCope : "대형 코드 모델을 미세한 API 유도 데이터 세트 합성"[2024-08] [논문]
** Xcoder ** : "코드 LLM은 어떻게 수행합니까? 고품질 데이터로 코드 명령어 조정 권한 부여"[2024-09] [논문]
Galla : "Galla : Graph는 소스 코드 이해를 향상시키기 위해 대형 언어 모델을 정렬했습니다"[2024-09] [논문]
헥사 코더 : "헥사 코더 : Oracle 유도 합성 훈련 데이터를 통한 보안 코드 생성"[2024-09] [논문]
AMR-EVOL : "AMR-EVOL : 적응 모듈 식 응답 진화는 코드 생성에서 큰 언어 모델에 대한 더 나은 지식 증류를 유도합니다"[2024-10] [논문]
Lintseq : "합성 편집 시퀀스에 대한 언어 모델 교육 코드 합성을 향상시킵니다"[2024-10] [논문]
COBA : "COBA : 대형 언어 모델의 멀티 태스킹 결합을위한 수렴 밸런서"[2024-10] [EMNLP 2024] [논문]
Cursorcore : "Cursorcore : 모든 것을 정렬하여 프로그래밍을 지원합니다"[2024-10] [논문]
selfcodealign : "selfcodealign : 코드 생성을위한 자기 정렬"[2024-10] [논문]
"Codellms의 데이터 합성 기술 마스터 링"[2024-10] [논문]
Codelutra : "Codelutra : 선호도 유도 개선을 통한 LLM 코드 생성 강화"[2024-11] [논문]
DSTC : "DSTC : 코드 LMS 개선을위한 자체 생성 테스트 및 코드만으로 직접 선호도 학습"[2024-11] [논문]
Compcoder : "컴파일러 피드백을 갖춘 컴파일 가능한 신경 코드 생성"[2022-03] [ACL 2022] [논문]
Coderl : "Coderl : 사전에 걸린 모델과 깊은 강화 학습을 통한 코드 생성 마스터 링"[2022-07] [Neurips 2022] [Paper] [Repo]
ppocoder : "심층 강화 학습을 사용한 실행 기반 코드 생성"[2023-01] [TMLR 2023] [용지] [repo]
RLTF : "RLTF : 단위 테스트 피드백으로부터의 강화 학습"[2023-07] [논문] [Repo]
B- 코더 : "B- 코더 : 프로그램 합성을위한 가치 기반 깊은 강화 학습"[2023-10] [ICLR 2024] [논문]
Ircoco : "Ircoco : 코드 완료를위한 즉각적인 보상으로 인한 깊은 강화 학습"[2024-01] [FSE 2024] [논문]
STEPCODER : "StepCoder : 컴파일러 피드백으로부터 강화 학습으로 코드 생성 개선"[2024-02] [ACL 2024] [논문]
RLPF & DPA : "빠른 코드 생성을위한 성능 조정 된 LLM"[2024-04] [논문]
"코드 완료를위한 RLHF의 암기 측정"[2024-06] [논문]
"경량 LLM에서 API-USAGE를 사용하여 코드 생성에 RLAIF 적용"[2024-06] [용지]
rlcoder : "rlcoder : 저장소 수준 코드 완료를위한 강화 학습"[2024-07] [논문]
PF-PPO : "코드 생성을위한 LLM을 미세 조정하기 위해 RLHF의 정책 여과"[2024-09] [논문]
Coffee-gym : "Coffee-gym : 잘못된 코드에 대한 자연어 피드백을 평가하고 개선하기위한 환경"[2024-09] [논문]
RLEF : "RLEF : 강화 학습을 통한 실행 피드백의 접지 코드 LLM"[2024-10] [논문]
CodePMP : "CodePMP : 대형 언어 모델 추론을위한 전 사전 조정"[2024-10] [논문]
CodedPo : "CodedPo : 자체 생성 및 검증 된 소스 코드와 코드 모델을 정렬"[2024-10] [논문]
"코드 생성에 대한 프로세스 감독 유도 정책 최적화"[2024-10] [논문]
"직접 선호도 최적화와 코델름을 정렬"[2024-10] [논문]
FALCON : "FALCON : 피드백 중심의 적응성 장기/단기 메모리 강화 코딩 최적화 시스템"[2024-10] [논문]
PFPO : "의사 피드백으로 추론을위한 선호 최적화"[2024-11] [논문]
PAL : "PAL : 프로그램 보조 언어 모델"[2022-11] [ICML 2023] [논문] [Repo]
냄비 : "생각의 프로그램 : 수치 적 추론 과제에 대한 추론에서 계산을 분리하는 것"[2022-11] [TMLR 2023] [논문] [Repo]
PAD : "PAD : 프로그램 보조 증류는 소규모 모델을 고려한 미세 조정보다 더 잘 추론 할 수 있습니다"[2023-05] [NAACL 2024] [논문]
CSV : "코드 기반 자체 검증으로 GPT-4 코드 통역사를 사용하여 도전적인 수학 단어 문제 해결"[2023-08] [ICLR 2024] [논문]
MathCoder : "MathCoder : 강화 된 수학적 추론을위한 LLM의 원활한 코드 통합"[2023-10] [ICLR 2024] [논문]
COC : "코드 체인 : 언어 모델을 사용하는 코드 에뮬레이터를 사용한 추론"[2023-12] [ICML 2024] [논문]
마리오 : "마리오 : 코드 통역 출력이있는 수학 추론-재현 가능한 파이프 라인"[2024-01] [ACL 2024 결과] [논문]
Regal : "Regal : 일반화 가능한 추상화를 발견하기위한 리팩토링 프로그램"[2024-01] [ICML 2024] [논문]
"실행 가능한 코드 작업은 더 나은 LLM 에이전트를 이끌어냅니다"[2024-02] [ICML 2024] [논문]
Hpropro : "프로그램 기반 프롬프트를 통해 하이브리드 질문에 대한 답변 탐색"[2024-02] [ACL 2024] [논문]
XSTREET : "코드를 통해 LLM에서 더 나은 다국어 구조적 추론을 유도"[2024-03] [ACL 2024] [논문]
FlowMind : "FlowMind : LLMS가있는 자동 워크 플로 생성"[2024-03] [용지]
사고 및 집행 : "컴파일러로서 언어 모델 : 의사 코드 실행 시뮬레이션 언어 모델에서 알고리즘 추론을 향상시킵니다"[2024-04] [논문]
코어 : "Core : 자연 언어 프로그래밍, 의사 코드 프로그래밍 및 AI 에이전트의 흐름 프로그래밍을위한 통역사로서 LLM"[2024-05] [논문]
Mumath-Code : "Mumath-Code : 수학적 추론을위한 다수의 데이터 확대와 도구 사용 대형 언어 모델을 결합"[2024-05] [논문]
Cogex : "프로그램 생성, 에뮬레이션 및 검색을 통한 추론 배우기"[2024-05] [논문]
"LLM의 산술 추론 : Prolog Generation & Pembutation"[2024-05] [논문]
"LLMS는 프로그램과 함께 사유 할 수 있습니까?" [2024-06] [종이]
DOTAMATH : "DOTAMATH : 수학적 추론을위한 코드 지원 및 자기 교정으로 사고의 분해"[2024-07] [논문]
Cibench : "Cibench : 코드 통역 플러그인으로 LLMS 평가"[2024-07] [논문]
Pybench : "Pybench : 다양한 실제 코딩 작업에서 LLM 에이전트 평가"[2024-07] [논문]
Adacoder : "Adacoder : 프로그래밍 방식 시각적 질문에 대한 적응 형 프롬프트 압축"[2024-07] [논문]
피라미드 코더 : "피라미드 코더 : 구성 시각적 질문에 대한 계층 적 코드 생성기"[2024-07] [논문]
CodeGraph : "CodeGraph : 코드로 LLM의 그래프 추론 향상"[2024-08] [논문]
SIAM : "SIAM : 대형 언어 모델의 자체 개선 코드 지원 수학적 추론"[2024-08] [논문]
CodePlan : "CodePlan : Code-Form Planning을 확장하여 대형 Langauge 모델에서 추론 잠재력 잠금 해제"[2024-09] [논문]
냄비 : "사고의 증거 : 신경 상징 프로그램 합성 합성은 강력하고 해석 가능한 추론을 허용한다"[2024-09] [논문]
Metamath : "Metamath : 대형 언어 모델에서 향상된 수학적 추론을위한 자연 언어 및 코드 통합"[2024-09] [논문]
"Babelbench : 멀티 모달 및 다중 보관 된 데이터의 코드 중심 분석을위한 OMNI 벤치 마크"[2024-10] [논문]
Codesteer : "코드 실행과 텍스트 추론 사이의 큰 언어 모델을 조종"[2024-10] [논문]
MathCoder2 : "MathCoder2 : 모델 번역 된 수학적 코드에 대한 지속적인 사전 조정으로 인한 더 나은 수학 추론"[2024-10] [논문]
LLMFP : "엄격한 계획 : LLM 기반 공식화 된 프로그래밍을 통한 일반 목적 제로 샷 계획"[2024-10] [논문]
증명서 : "모든 투표가 중요하지는 않습니다! 검증자가 수학 추론을위한 언어 모델의 자기 일관성을 향상시키는 프로그램"[2024-10] [논문]
증명 : "신뢰하지만 확인 : 야생의 프로그래밍 방식 VLM 평가"[2024-10] [논문]
지오 코더 : "지오 코더 : 시력 모델을 통해 모듈 식 코드를 생성하여 지오메트리 문제 해결"[2024-10] [논문]
ConaseAgain : "이성 : 수학적 추론을 평가하기 위해 추출 가능한 상징적 프로그램 사용"[2024-10] [논문]
GFP : "갭 필링 프롬프트는 코드 보조 수학적 추론을 향상시킨다"[2024-11] [논문]
UTMATH : "UTMATH : 코딩에 대한 생각을 통한 단위 테스트를 통한 수학 평가"[2024-11] [논문]
Cocop : "Cocop : 코드 완료 프롬프트를 통한 LLM으로 텍스트 분류 향상"[2024-11] [논문]
REPL-PLAN : "대형 언어 모델을 사용한 대화식 및 표현 코드 확장 계획"[2024-11] [논문]
"큰 언어 모델의 코드 시뮬레이션 문제"[2024-01] [논문]
"Codemind : 코드 추론을위한 큰 언어 모델에 도전하는 프레임 워크"[2024-02] [논문]
"큰 언어 모델로 자연어 설명 알고리즘 실행 : 조사"[2024-02] [논문]
"언어 모델이 솔버를 척 할 수 있습니까? LLM으로 논리 코드 시뮬레이션"[2024-03] [논문]
"프로그램 실행의 런타임 동작으로 대형 언어 모델 평가"[2024-03] [논문]
"다음 : 코드 실행에 대한 추론에 대한 대형 언어 모델 교육"[2024-04] [ICML 2024] [논문]
"Selfpico : LLMS를 사용한 셀프 가이드 부분 코드 실행"[2024-07] [논문]
"코드 집행자로서의 대형 언어 모델 : 탐색 적 연구"[2024-10] [논문]
"VisualCoder : 세분화 된 멀티 모달 체인의 추론으로 코드 실행에 큰 언어 모델을 안내"[2024-10] [논문]
자체 청소년 : "Chatgpt를 통한 자체 정책 코드 생성"[2023-04] [논문]
ChatDev : "소프트웨어 개발을위한 커뮤니케이션 에이전트"[2023-07] [논문] [Repo]
Metagpt : "Metagpt : Multi-Agent 공동 작업 프레임 워크를위한 메타 프로그래밍"[2023-08] [Paper] [Repo]
Codechain : "Codechain : 대표적 하위 모듈을 갖는 자기 반성 체인을 통해 모듈 식 코드 생성을 향해"[2023-10] [ICLR 2024] [논문]
CodeAgent : "CodeAgent : 실제 리포 레벨 코딩 문제를위한 공구 통합 에이전트 시스템으로 코드 생성 강화"[2024-01] [ACL 2024] [논문]
Conline : "Conline : 온라인 검색 및 정확성 테스트를 통한 복잡한 코드 생성 및 개선"[2024-03] [논문]
LCG : "LLM 기반 코드 생성이 소프트웨어 개발 프로세스를 충족 할 때"[2024-03] [논문]
ReaperAgent : "RepairAgent : 프로그램 수리를위한 자율적 인 LLM 기반 에이전트"[2024-03] [논문]
MAGIS : : : "MAGIS GITHUB 문제 해결을위한 LLM 기반 다중 에이전트 프레임 워크"[2024-03] [논문]
SOA : "자체 조직 에이전트 : 매우 대규모 코드 생성 및 최적화를 향한 LLM 다중 에이전트 프레임 워크"[2024-04] [논문]
Autocoderover : "Autocoderover : 자율 프로그램 개선"[2024-04] [논문]
SWE-Agent : "SWE-Agent : 에이전트 컴퓨터 인터페이스가 자동화 된 소프트웨어 엔지니어링을 활성화"[2024-05] [논문]
MapCoder : "MapCoder : 경쟁 문제 해결을위한 다중 에이전트 코드 생성"[2024-05] [ACL 2024] [논문]
"화재와의 싸움 : 소스 코드 관련 작업에서 Chatgpt를 얼마나 신뢰할 수 있습니까?" [2024-05] [종이]
FUNCODER : "나누기 및 정복은 합의를 충족시킨다 : 코드 생성에서 함수의 힘을 발휘한다"[2024-05] [논문]
CTC : "Multi-Agent Software Development through Cross-Team Collaboration" [2024-06] [paper]
MASAI : "MASAI: Modular Architecture for Software-engineering AI Agents" [2024-06] [paper]
AgileCoder : "AgileCoder: Dynamic Collaborative Agents for Software Development based on Agile Methodology" [2024-06] [paper]
CodeNav : "CodeNav: Beyond tool-use to using real-world codebases with LLM agents" [2024-06] [paper]
INDICT : "INDICT: Code Generation with Internal Dialogues of Critiques for Both Security and Helpfulness" [2024-06] [paper]
AppWorld : "AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents" [2024-07] [paper]
CortexCompile : "CortexCompile: Harnessing Cortical-Inspired Architectures for Enhanced Multi-Agent NLP Code Synthesis" [2024-08] [paper]
Survey : "Large Language Model-Based Agents for Software Engineering: A Survey" [2024-09] [paper]
AutoSafeCoder : "AutoSafeCoder: A Multi-Agent Framework for Securing LLM Code Generation through Static Analysis and Fuzz Testing" [2024-09] [paper]
SuperCoder2.0 : "SuperCoder2.0: Technical Report on Exploring the feasibility of LLMs as Autonomous Programmer" [2024-09] [paper]
Survey : "Agents in Software Engineering: Survey, Landscape, and Vision" [2024-09] [paper]
MOSS : "MOSS: Enabling Code-Driven Evolution and Context Management for AI Agents" [2024-09] [paper]
HyperAgent : "HyperAgent: Generalist Software Engineering Agents to Solve Coding Tasks at Scale" [2024-09] [paper]
"Compositional Hardness of Code in Large Language Models -- A Probabilistic Perspective" [2024-09] [paper]
RGD : "RGD: Multi-LLM Based Agent Debugger via Refinement and Generation Guidance" [2024-10] [paper]
AutoML-Agent : "AutoML-Agent: A Multi-Agent LLM Framework for Full-Pipeline AutoML" [2024-10] [paper]
Seeker : "Seeker: Enhancing Exception Handling in Code with LLM-based Multi-Agent Approach" [2024-10] [paper]
REDO : "REDO: Execution-Free Runtime Error Detection for COding Agents" [2024-10] [paper]
"Evaluating Software Development Agents: Patch Patterns, Code Quality, and Issue Complexity in Real-World GitHub Scenarios" [2024-10] [paper]
EvoMAC : "Self-Evolving Multi-Agent Collaboration Networks for Software Development" [2024-10] [paper]
VisionCoder : "VisionCoder: Empowering Multi-Agent Auto-Programming for Image Processing with Hybrid LLMs" [2024-10] [paper]
AutoKaggle : "AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions" [2024-10] [paper]
Watson : "Watson: A Cognitive Observability Framework for the Reasoning of Foundation Model-Powered Agents" [2024-11] [paper]
CodeTree : "CodeTree: Agent-guided Tree Search for Code Generation with Large Language Models" [2024-11] [paper]
EvoCoder : "LLMs as Continuous Learners: Improving the Reproduction of Defective Code in Software Issues" [2024-11] [paper]
"Interactive Program Synthesis" [2017-03] [paper]
"Question selection for interactive program synthesis" [2020-06] [PLDI 2020] [paper]
"Interactive Code Generation via Test-Driven User-Intent Formalization" [2022-08] [paper]
"Improving Code Generation by Training with Natural Language Feedback" [2023-03] [TMLR] [paper]
"Self-Refine: Iterative Refinement with Self-Feedback" [2023-03] [NeurIPS 2023] [paper]
"Teaching Large Language Models to Self-Debug" [2023-04] [paper]
"Self-Edit: Fault-Aware Code Editor for Code Generation" [2023-05] [ACL 2023] [paper]
"LeTI: Learning to Generate from Textual Interactions" [2023-05] [paper]
"Is Self-Repair a Silver Bullet for Code Generation?" [2023-06] [ICLR 2024] [paper]
"InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback" [2023-06] [NeurIPS 2023] [paper]
"INTERVENOR: Prompting the Coding Ability of Large Language Models with the Interactive Chain of Repair" [2023-11] [ACL 2024 Findings] [paper]
"OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement" [2024-02] [ACL 2024 Findings] [paper]
"Iterative Refinement of Project-Level Code Context for Precise Code Generation with Compiler Feedback" [2024-03] [ACL 2024 Findings] [paper]
"CYCLE: Learning to Self-Refine the Code Generation" [2024-03] [paper]
"LLM-based Test-driven Interactive Code Generation: User Study and Empirical Evaluation" [2024-04] [paper]
"SOAP: Enhancing Efficiency of Generated Code via Self-Optimization" [2024-05] [paper]
"Code Repair with LLMs gives an Exploration-Exploitation Tradeoff" [2024-05] [paper]
"ReflectionCoder: Learning from Reflection Sequence for Enhanced One-off Code Generation" [2024-05] [paper]
"Training LLMs to Better Self-Debug and Explain Code" [2024-05] [paper]
"Requirements are All You Need: From Requirements to Code with LLMs" [2024-06] [paper]
"I Need Help! Evaluating LLM's Ability to Ask for Users' Support: A Case Study on Text-to-SQL Generation" [2024-07] [paper]
"An Empirical Study on Self-correcting Large Language Models for Data Science Code Generation" [2024-08] [paper]
"RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation" [2024-09] [paper]
"From Code to Correctness: Closing the Last Mile of Code Generation with Hierarchical Debugging" [2024-10] [paper] [repo]
"What Makes Large Language Models Reason in (Multi-Turn) Code Generation?" [2024-10] [paper]
"The First Prompt Counts the Most! An Evaluation of Large Language Models on Iterative Example-based Code Generation" [2024-11] [paper]
"Planning-Driven Programming: A Large Language Model Programming Workflow" [2024-11] [paper]
"ConAIR:Consistency-Augmented Iterative Interaction Framework to Enhance the Reliability of Code Generation" [2024-11] [paper]
"MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding" [2021-10] [ACL 2022] [paper]
"WebKE: Knowledge Extraction from Semi-structured Web with Pre-trained Markup Language Model" [2021-10] [CIKM 2021] [paper]
"WebGPT: Browser-assisted question-answering with human feedback" [2021-12] [paper]
"CM3: A Causal Masked Multimodal Model of the Internet" [2022-01] [paper]
"DOM-LM: Learning Generalizable Representations for HTML Documents" [2022-01] [paper]
"WebFormer: The Web-page Transformer for Structure Information Extraction" [2022-02] [WWW 2022] [paper]
"A Dataset for Interactive Vision-Language Navigation with Unknown Command Feasibility" [2022-02] [ECCV 2022] [paper]
"WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents" [2022-07] [NeurIPS 2022] [paper]
"Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding" [2022-10] [ICML 2023] [paper]
"Understanding HTML with Large Language Models" [2022-10] [EMNLP 2023 findings] [paper]
"WebUI: A Dataset for Enhancing Visual UI Understanding with Web Semantics" [2023-01] [CHI 2023] [paper]
"Mind2Web: Towards a Generalist Agent for the Web" [2023-06] [NeurIPS 2023] [paper]
"A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis", [2023-07] [ICLR 2024] [paper]
"WebArena: A Realistic Web Environment for Building Autonomous Agents" [2023-07] [paper]
"CogAgent: A Visual Language Model for GUI Agents" [2023-12] [paper]
"GPT-4V(ision) is a Generalist Web Agent, if Grounded" [2024-01] [paper]
"WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models" [2024-01] [paper]
"WebLINX: Real-World Website Navigation with Multi-Turn Dialogue" [2024-02] [paper]
"OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web" [2024-02] [paper]
"AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent" [2024-04] [paper]
"WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents" [2024-04] [paper]
"AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation" [2024-04] [paper]
"GUICourse: From General Vision Language Models to Versatile GUI Agents" [2024-06] [paper]
"NaviQAte: Functionality-Guided Web Application Navigation" [2024-09] [paper]
"MobileVLM: A Vision-Language Model for Better Intra- and Inter-UI Understanding" [2024-09] [paper]
"Multimodal Auto Validation For Self-Refinement in Web Agents" [2024-10] [paper]
"Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents" [2024-10] [paper]
"Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation" [2024-10] [paper]
"Harnessing Webpage UIs for Text-Rich Visual Understanding" [2024-10] [paper]
"AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents" [2024-10] [paper]
"Beyond Browsing: API-Based Web Agents" [2024-10] [paper]
"Large Language Models Empowered Personalized Web Agents" [2024-10] [paper]
"AdvWeb: Controllable Black-box Attacks on VLM-powered Web Agents" [2024-10] [paper]
"Auto-Intent: Automated Intent Discovery and Self-Exploration for Large Language Model Web Agents" [2024-10] [paper]
"OS-ATLAS: A Foundation Action Model for Generalist GUI Agents" [2024-10] [paper]
"From Context to Action: Analysis of the Impact of State Representation and Context on the Generalization of Multi-Turn Web Navigation Agents" [2024-10] [paper]
"AutoGLM: Autonomous Foundation Agents for GUIs" [2024-10] [paper]
"WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning" [2024-11] [paper]
"The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use" [2024-11] [paper]
"ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data" [2024-11] [paper]
"ShowUI: One Vision-Language-Action Model for GUI Visual Agent" [2024-11] [paper]
[ Ruby ] "On the Transferability of Pre-trained Language Models for Low-Resource Programming Languages" [2022-04] [ICPC 2022] [paper]
[ Verilog ] "Benchmarking Large Language Models for Automated Verilog RTL Code Generation" [2022-12] [DATE 2023] [paper]
[ OCL ] "On Codex Prompt Engineering for OCL Generation: An Empirical Study" [2023-03] [MSR 2023] [paper]
[ Ansible-YAML ] "Automated Code generation for Information Technology Tasks in YAML through Large Language Models" [2023-05] [DAC 2023] [paper]
[ Hansl ] "The potential of LLMs for coding with low-resource and domain-specific programming languages" [2023-07] [paper]
[ Verilog ] "VeriGen: A Large Language Model for Verilog Code Generation" [2023-07] [paper]
[ Verilog ] "RTLLM: An Open-Source Benchmark for Design RTL Generation with Large Language Model" [2023-08] [paper]
[ Racket, OCaml, Lua, R, Julia ] "Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs" [2023-08] [paper]
[ Verilog ] "VerilogEval: Evaluating Large Language Models for Verilog Code Generation" [2023-09] [ICCAD 2023] [paper]
[ Verilog ] "RTLFixer: Automatically Fixing RTL Syntax Errors with Large Language Models" [2023-11] [paper]
[ Verilog ] "Advanced Large Language Model (LLM)-Driven Verilog Development: Enhancing Power, Performance, and Area Optimization in Code Synthesis" [2023-12] [paper]
[ Verilog ] "RTLCoder: Outperforming GPT-3.5 in Design RTL Generation with Our Open-Source Dataset and Lightweight Solution" [2023-12] [paper]
[ Verilog ] "BetterV: Controlled Verilog Generation with Discriminative Guidance" [2024-02] [ICML 2024] [paper]
[ R ] "Empirical Studies of Parameter Efficient Methods for Large Language Models of Code and Knowledge Transfer to R" [2024-03] [paper]
[ Haskell ] "Investigating the Performance of Language Models for Completing Code in Functional Programming Languages: a Haskell Case Study" [2024-03] [paper]
[ Verilog ] "A Multi-Expert Large Language Model Architecture for Verilog Code Generation" [2024-04] [paper]
[ Verilog ] "CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation" [2024-04] [paper]
[ Alloy ] "An Empirical Evaluation of Pre-trained Large Language Models for Repairing Declarative Formal Specifications" [2024-04] [paper]
[ Verilog ] "Evaluating LLMs for Hardware Design and Test" [2024-04] [paper]
[ Kotlin, Swift, and Rust ] "Software Vulnerability Prediction in Low-Resource Languages: An Empirical Study of CodeBERT and ChatGPT" [2024-04] [paper]
[ Verilog ] "MEIC: Re-thinking RTL Debug Automation using LLMs" [2024-05] [paper]
[ Bash ] "Tackling Execution-Based Evaluation for NL2Bash" [2024-05] [paper]
[ Fortran, Julia, Matlab, R, Rust ] "Evaluating AI-generated code for C++, Fortran, Go, Java, Julia, Matlab, Python, R, and Rust" [2024-05] [paper]
[ OpenAPI ] "Optimizing Large Language Models for OpenAPI Code Completion" [2024-05] [paper]
[ Kotlin ] "Kotlin ML Pack: Technical Report" [2024-05] [paper]
[ Verilog ] "VerilogReader: LLM-Aided Hardware Test Generation" [2024-06] [paper]
"Benchmarking Generative Models on Computational Thinking Tests in Elementary Visual Programming" [2024-06] [paper]
[ Logo ] "Program Synthesis Benchmark for Visual Programming in XLogoOnline Environment" [2024-06] [paper]
[ Ansible YAML, Bash ] "DocCGen: Document-based Controlled Code Generation" [2024-06] [paper]
[ Qiskit ] "Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models" [2024-06] [paper]
[ Perl, Golang, Swift ] "DistiLRR: Transferring Code Repair for Low-Resource Programming Languages" [2024-06] [paper]
[ Verilog ] "AssertionBench: A Benchmark to Evaluate Large-Language Models for Assertion Generation" [2024-06] [paper]
"A Comparative Study of DSL Code Generation: Fine-Tuning vs. Optimized Retrieval Augmentation" [2024-07] [paper]
[ Json, XLM, YAML ] "ConCodeEval: Evaluating Large Language Models for Code Constraints in Domain-Specific Languages" [2024-07] [paper]
[ Verilog ] "AutoBench: Automatic Testbench Generation and Evaluation Using LLMs for HDL Design" [2024-07] [paper]
[ Verilog ] "CodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization" [2024-07] [paper]
[ Verilog ] "ITERTL: An Iterative Framework for Fine-tuning LLMs for RTL Code Generation" [2024-07] [paper]
[ Verilog ] "OriGen:Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection" [2024-07] [paper]
[ Verilog ] "Large Language Model for Verilog Generation with Golden Code Feedback" [2024-07] [paper]
[ Verilog ] "AutoVCoder: A Systematic Framework for Automated Verilog Code Generation using LLMs" [2024-07] [paper]
[ RPA ] "Plan with Code: Comparing approaches for robust NL to DSL generation" [2024-08] [paper]
[ Verilog ] "VerilogCoder: Autonomous Verilog Coding Agents with Graph-based Planning and Abstract Syntax Tree (AST)-based Waveform Tracing Tool" [2024-08] [paper]
[ Verilog ] "Revisiting VerilogEval: Newer LLMs, In-Context Learning, and Specification-to-RTL Tasks" [2024-08] [paper]
[ MaxMSP, Web Audio ] "Benchmarking LLM Code Generation for Audio Programming with Visual Dataflow Languages" [2024-09] [paper]
[ Verilog ] "RTLRewriter: Methodologies for Large Models aided RTL Code Optimization" [2024-09] [paper]
[ Verilog ] "CraftRTL: High-quality Synthetic Data Generation for Verilog Code Models with Correct-by-Construction Non-Textual Representations and Targeted Code Repair" [2024-09] [paper]
[ Bash ] "ScriptSmith: A Unified LLM Framework for Enhancing IT Operations via Automated Bash Script Generation, Assessment, and Refinement" [2024-09] [paper]
[ Survey ] "Survey on Code Generation for Low resource and Domain Specific Programming Languages" [2024-10] [paper]
[ R ] "Do Current Language Models Support Code Intelligence for R Programming Language?" [2024-10] [paper]
"Can Large Language Models Generate Geospatial Code?" [2024-10] [paper]
[ PLC ] "Agents4PLC: Automating Closed-loop PLC Code Generation and Verification in Industrial Control Systems using LLM-based Agents" [2024-10] [paper]
[ Lua ] "Evaluating Quantized Large Language Models for Code Generation on Low-Resource Language Benchmarks" [2024-10] [paper]
"Improving Parallel Program Performance Through DSL-Driven Code Generation with LLM Optimizers" [2024-10] [paper]
"GeoCode-GPT: A Large Language Model for Geospatial Code Generation Tasks" [2024-10] [paper]
[ R, D, Racket, Bash ]: "Bridge-Coder: Unlocking LLMs' Potential to Overcome Language Gaps in Low-Resource Code" [2024-10] [paper]
[ SPICE ]: "SPICEPilot: Navigating SPICE Code Generation and Simulation with AI Guidance" [2024-10] [paper]
[ IEC 61131-3 ST ]: "Training LLMs for Generating IEC 61131-3 Structured Text with Online Feedback" [2024-10] [paper]
[ Verilog ] "MetRex: A Benchmark for Verilog Code Metric Reasoning Using LLMs" [2024-11] [paper]
[ Verilog ] "CorrectBench: Automatic Testbench Generation with Functional Self-Correction using LLMs for HDL Design" [2024-11] [paper]
[ MUMPS, ALC ] "Leveraging LLMs for Legacy Code Modernization: Challenges and Opportunities for LLM-Generated Documentation" [2024-11] [paper]
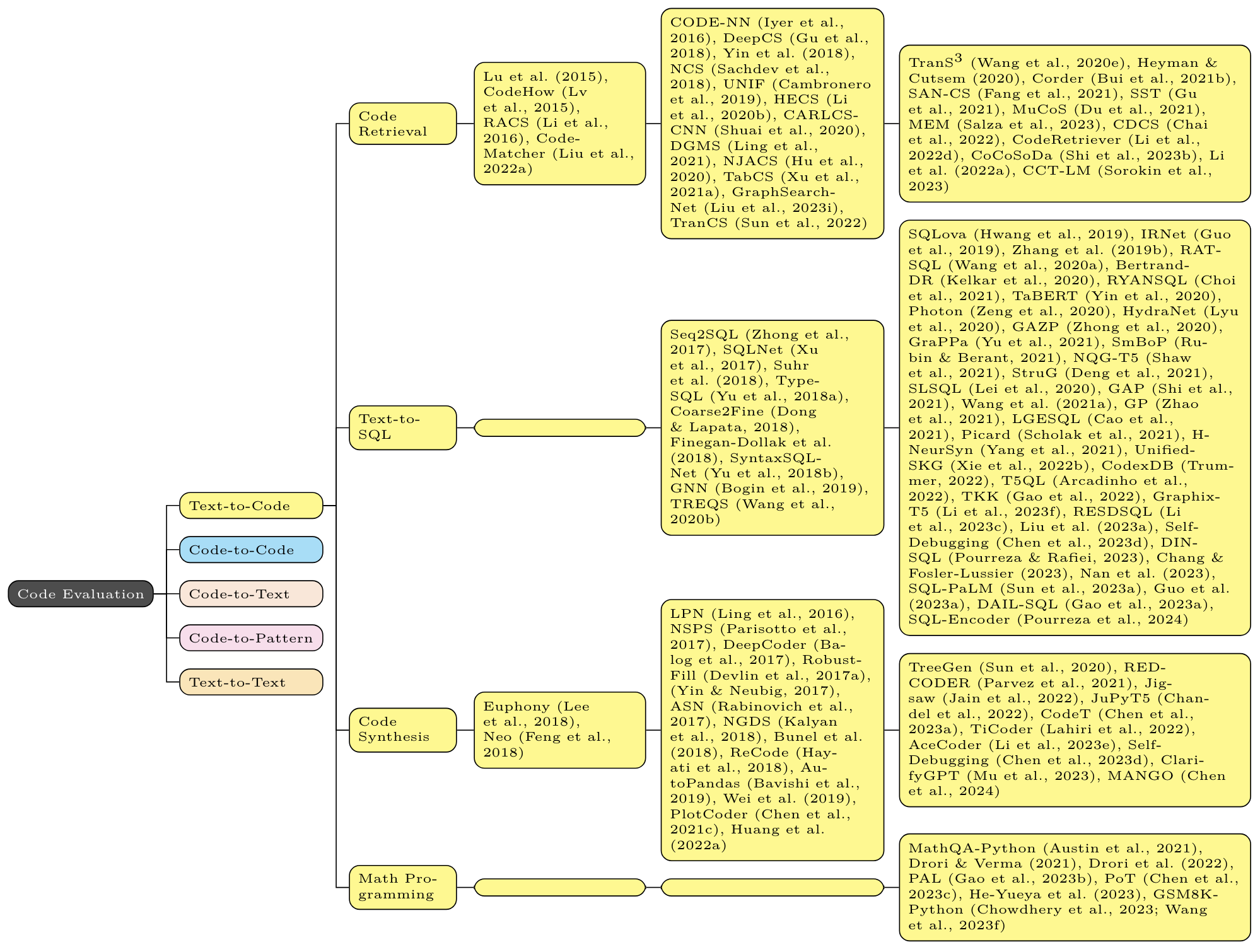
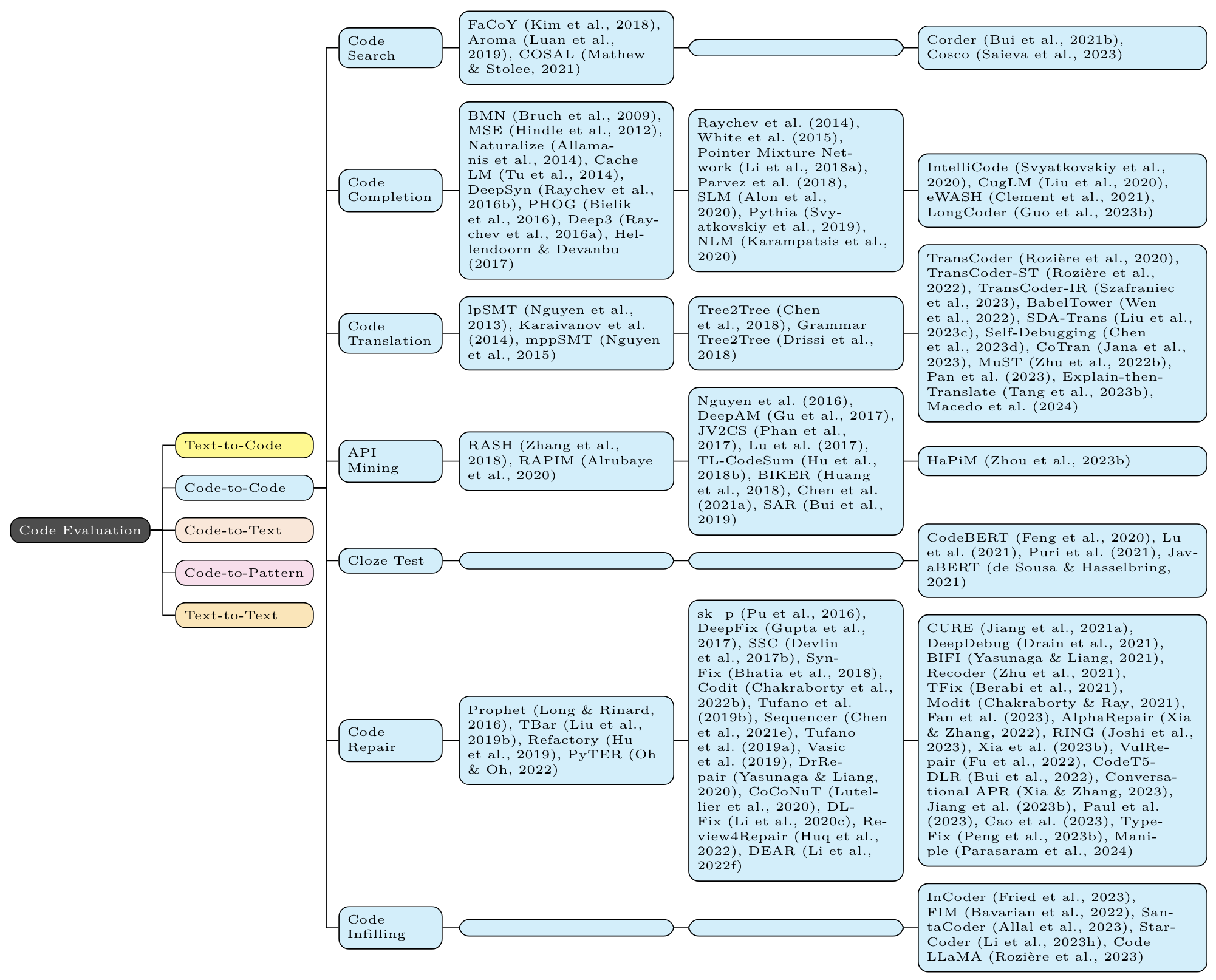
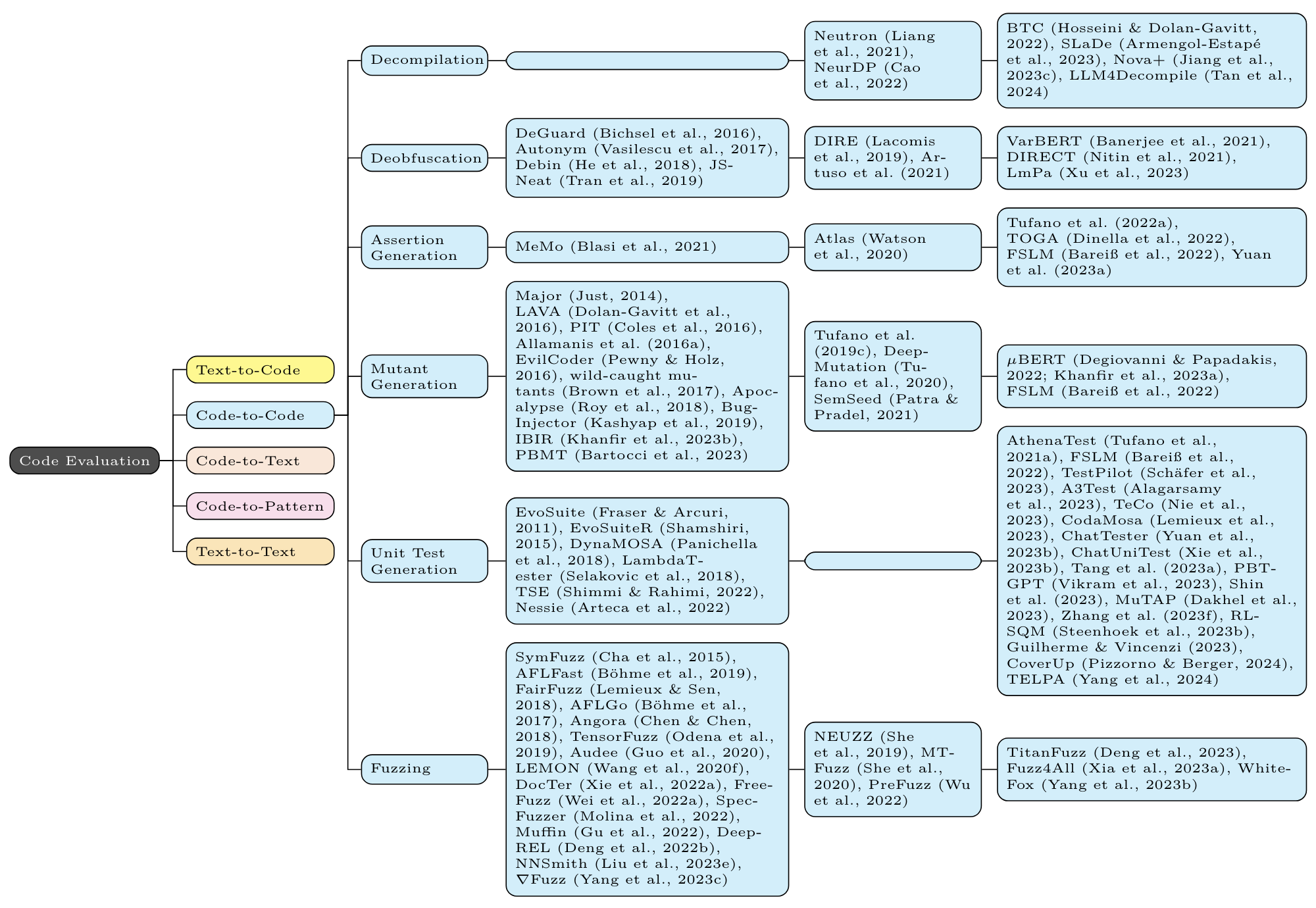
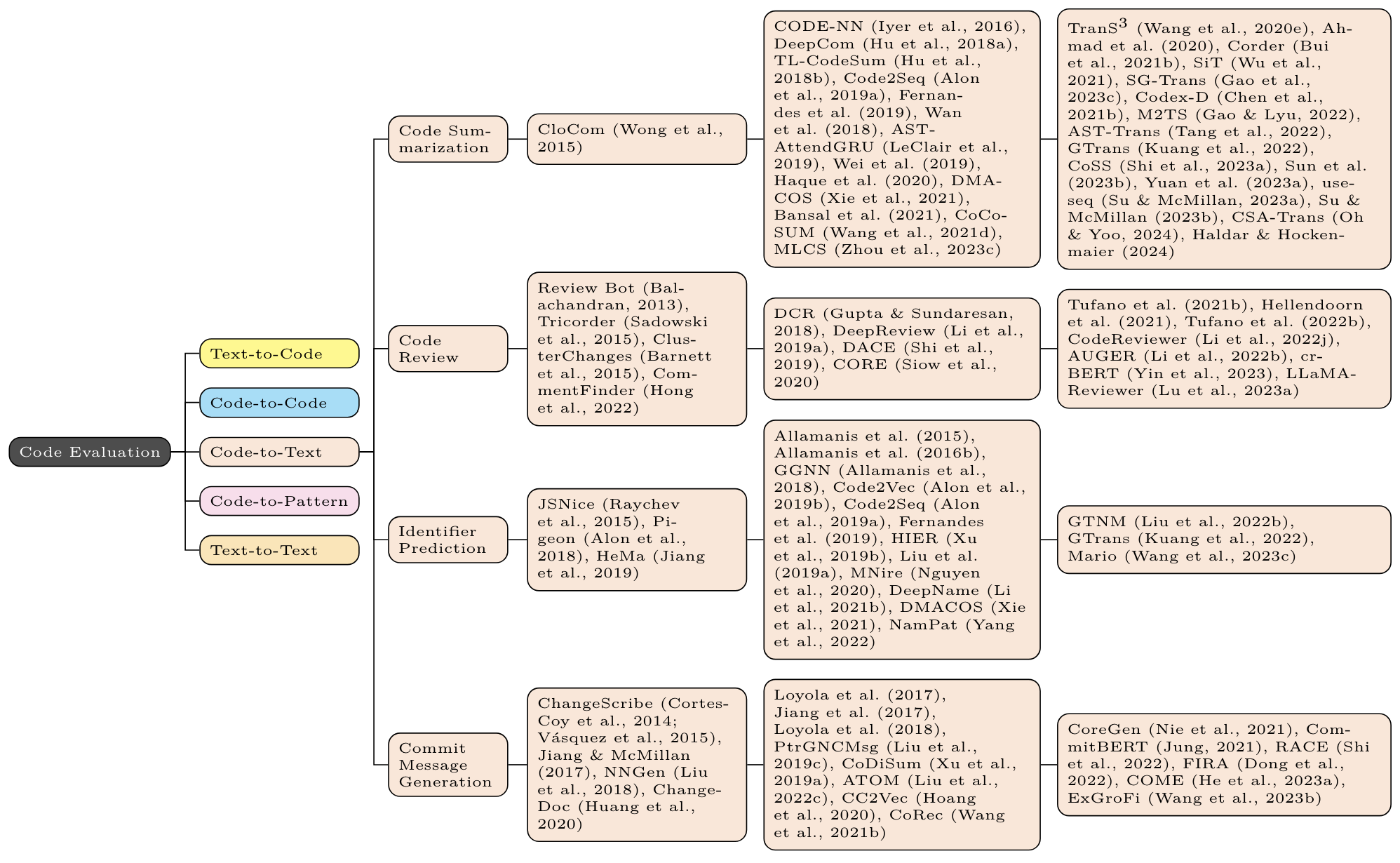
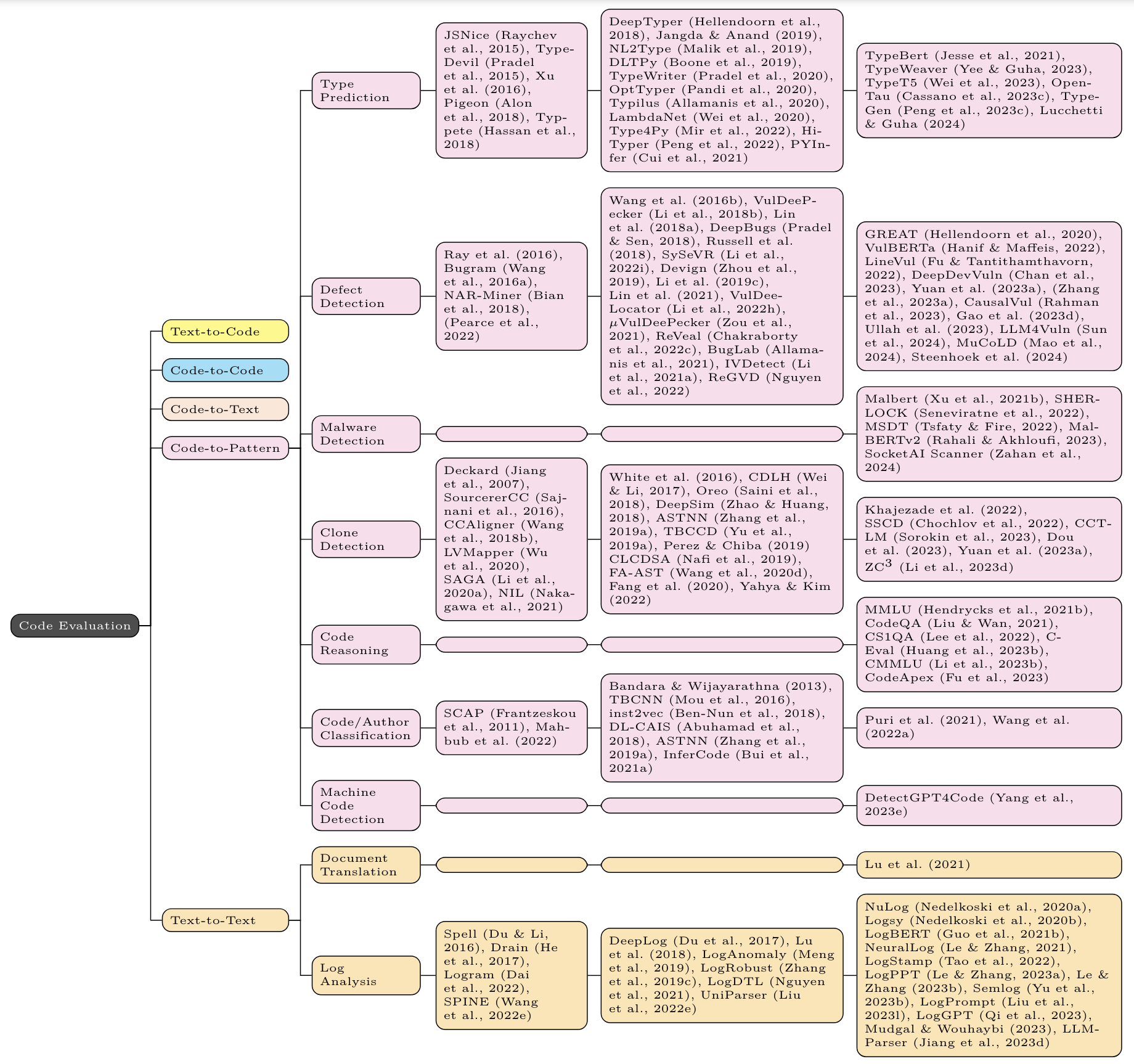
For each task, the first column contains non-neural methods (eg n-gram, TF-IDF, and (occasionally) static program analysis); the second column contains non-Transformer neural methods (eg LSTM, CNN, GNN); the third column contains Transformer based methods (eg BERT, GPT, T5).
"Enhancing Large Language Models in Coding Through Multi-Perspective Self-Consistency" [2023-09] [ACL 2024] [paper]
"Self-Infilling Code Generation" [2023-11] [ICML 2024] [paper]
"JumpCoder: Go Beyond Autoregressive Coder via Online Modification" [2024-01] [ACL 2024] [paper]
"Unsupervised Evaluation of Code LLMs with Round-Trip Correctness" [2024-02] [ICML 2024] [paper]
"The Larger the Better? Improved LLM Code-Generation via Budget Reallocation" [2024-03] [paper]
"Quantifying Contamination in Evaluating Code Generation Capabilities of Language Models" [2024-03] [ACL 2024] [paper]
"Comments as Natural Logic Pivots: Improve Code Generation via Comment Perspective" [2024-04] [ACL 2024 Findings] [paper]
"Distilling Algorithmic Reasoning from LLMs via Explaining Solution Programs" [2024-04] [paper]
"Quality Assessment of Prompts Used in Code Generation" [2024-04] [paper]
"Assessing GPT-4-Vision's Capabilities in UML-Based Code Generation" [2024-04] [paper]
"Large Language Models Synergize with Automated Machine Learning" [2024-05] [paper]
"Model Cascading for Code: Reducing Inference Costs with Model Cascading for LLM Based Code Generation" [2024-05] [paper]
"A Survey on Large Language Models for Code Generation" [2024-06] [paper]
"Is Programming by Example solved by LLMs?" [2024-06] [paper]
"Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review" [2024-06] [paper]
"MPCODER: Multi-user Personalized Code Generator with Explicit and Implicit Style Representation Learning" [2024-06] [ACL 2024] [paper]
"Revisiting the Impact of Pursuing Modularity for Code Generation" [2024-07] [paper]
"Evaluating Long Range Dependency Handling in Code Generation Models using Multi-Step Key Retrieval" [2024-07] [paper]
"When to Stop? Towards Efficient Code Generation in LLMs with Excess Token Prevention" [2024-07] [paper]
"Assessing Programming Task Difficulty for Efficient Evaluation of Large Language Models" [2024-07] [paper]
"ArchCode: Incorporating Software Requirements in Code Generation with Large Language Models" [2024-08] [ACL 2024] [paper]
"Fine-tuning Language Models for Joint Rewriting and Completion of Code with Potential Bugs" [2024-08] [ACL 2024 Findings] [paper]
"Selective Prompt Anchoring for Code Generation" [2024-08] [paper]
"Bridging the Language Gap: Enhancing Multilingual Prompt-Based Code Generation in LLMs via Zero-Shot Cross-Lingual Transfer" [2024-08] [paper]
"Optimizing Large Language Model Hyperparameters for Code Generation" [2024-08] [paper]
"EPiC: Cost-effective Search-based Prompt Engineering of LLMs for Code Generation" [2024-08] [paper]
"CodeRefine: A Pipeline for Enhancing LLM-Generated Code Implementations of Research Papers" [2024-08] [paper]
"No Man is an Island: Towards Fully Automatic Programming by Code Search, Code Generation and Program Repair" [2024-09] [paper]
"Planning In Natural Language Improves LLM Search For Code Generation" [2024-09] [paper]
"Multi-Programming Language Ensemble for Code Generation in Large Language Model" [2024-09] [paper]
"A Pair Programming Framework for Code Generation via Multi-Plan Exploration and Feedback-Driven Refinement" [2024-09] [paper]
"USCD: Improving Code Generation of LLMs by Uncertainty-Aware Selective Contrastive Decoding" [2024-09] [paper]
"Eliciting Instruction-tuned Code Language Models' Capabilities to Utilize Auxiliary Function for Code Generation" [2024-09] [paper]
"Selection of Prompt Engineering Techniques for Code Generation through Predicting Code Complexity" [2024-09] [paper]
"Horizon-Length Prediction: Advancing Fill-in-the-Middle Capabilities for Code Generation with Lookahead Planning" [2024-10] [paper]
"Showing LLM-Generated Code Selectively Based on Confidence of LLMs" [2024-10] [paper]
"AutoFeedback: An LLM-based Framework for Efficient and Accurate API Request Generation" [2024-10] [paper]
"Enhancing LLM Agents for Code Generation with Possibility and Pass-rate Prioritized Experience Replay" [2024-10] [paper]
"From Solitary Directives to Interactive Encouragement! LLM Secure Code Generation by Natural Language Prompting" [2024-10] [paper]
"Self-Explained Keywords Empower Large Language Models for Code Generation" [2024-10] [paper]
"Context-Augmented Code Generation Using Programming Knowledge Graphs" [2024-10] [paper]
"In-Context Code-Text Learning for Bimodal Software Engineering" [2024-10] [paper]
"Combining LLM Code Generation with Formal Specifications and Reactive Program Synthesis" [2024-10] [paper]
"Less is More: DocString Compression in Code Generation" [2024-10] [paper]
"Multi-Programming Language Sandbox for LLMs" [2024-10] [paper]
"Personality-Guided Code Generation Using Large Language Models" [2024-10] [paper]
"Do Advanced Language Models Eliminate the Need for Prompt Engineering in Software Engineering?" [2024-11] [paper]
"Scattered Forest Search: Smarter Code Space Exploration with LLMs" [2024-11] [paper]
"Anchor Attention, Small Cache: Code Generation with Large Language Models" [2024-11] [paper]
"ROCODE: Integrating Backtracking Mechanism and Program Analysis in Large Language Models for Code Generation" [2024-11] [paper]
"SRA-MCTS: Self-driven Reasoning Aurmentation with Monte Carlo Tree Search for Enhanced Code Generation" [2024-11] [paper]
"CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation" [2024-05] [paper]
"Prompt-based Code Completion via Multi-Retrieval Augmented Generation" [2024-05] [paper]
"A Lightweight Framework for Adaptive Retrieval In Code Completion With Critique Model" [2024-06] [papaer]
"Preference-Guided Refactored Tuning for Retrieval Augmented Code Generation" [2024-09] [paper]
"Building A Coding Assistant via the Retrieval-Augmented Language Model" [2024-10] [paper]
"DroidCoder: Enhanced Android Code Completion with Context-Enriched Retrieval-Augmented Generation" [2024-10] [ASE 2024] [paper]
"Assessing the Answerability of Queries in Retrieval-Augmented Code Generation" [2024-11] [paper]
"Fault-Aware Neural Code Rankers" [2022-06] [NeurIPS 2022] [paper]
"Functional Overlap Reranking for Neural Code Generation" [2023-10] [ACL 2024 Findings] [paper]
"Top Pass: Improve Code Generation by Pass@k-Maximized Code Ranking" [2024-08] [paper]
"DOCE: Finding the Sweet Spot for Execution-Based Code Generation" [2024-08] [paper]
"Sifting through the Chaff: On Utilizing Execution Feedback for Ranking the Generated Code Candidates" [2024-08] [paper]
"B4: Towards Optimal Assessment of Plausible Code Solutions with Plausible Tests" [2024-09] [paper]
"Learning Code Preference via Synthetic Evolution" [2024-10] [paper]
"Tree-to-tree Neural Networks for Program Translation" [2018-02] [NeurIPS 2018] [paper]
"Program Language Translation Using a Grammar-Driven Tree-to-Tree Model" [2018-07] [paper]
"Unsupervised Translation of Programming Languages" [2020-06] [NeurIPS 2020] [paper]
"Leveraging Automated Unit Tests for Unsupervised Code Translation" [2021-10] [ICLR 2022] paper]
"Code Translation with Compiler Representations" [2022-06] [ICLR 2023] [paper]
"Multilingual Code Snippets Training for Program Translation" [2022-06] [AAAI 2022] [paper]
"BabelTower: Learning to Auto-parallelized Program Translation" [2022-07] [ICML 2022] [paper]
"Syntax and Domain Aware Model for Unsupervised Program Translation" [2023-02] [ICSE 2023] [paper]
"CoTran: An LLM-based Code Translator using Reinforcement Learning with Feedback from Compiler and Symbolic Execution" [2023-06] [paper]
"Lost in Translation: A Study of Bugs Introduced by Large Language Models while Translating Code" [2023-08] [ICSE 2024] [paper]
"On the Evaluation of Neural Code Translation: Taxonomy and Benchmark", 2023-08, ASE 2023, [paper]
"Program Translation via Code Distillation" [2023-10] [EMNLP 2023] [paper]
"Explain-then-Translate: An Analysis on Improving Program Translation with Self-generated Explanations" [2023-11] [EMNLP 2023 Findings] [paper]
"Exploring the Impact of the Output Format on the Evaluation of Large Language Models for Code Translation" [2024-03] [paper]
"Exploring and Unleashing the Power of Large Language Models in Automated Code Translation" [2024-04] [paper]
"VERT: Verified Equivalent Rust Transpilation with Few-Shot Learning" [2024-04] [paper]
"Towards Translating Real-World Code with LLMs: A Study of Translating to Rust" [2024-05] [paper]
"An interpretable error correction method for enhancing code-to-code translation" [2024-05] [ICLR 2024] [paper]
"LASSI: An LLM-based Automated Self-Correcting Pipeline for Translating Parallel Scientific Codes" [2024-06] [paper]
"Rectifier: Code Translation with Corrector via LLMs" [2024-07] [paper]
"Enhancing Code Translation in Language Models with Few-Shot Learning via Retrieval-Augmented Generation" [2024-07] [paper]
"A Joint Learning Model with Variational Interaction for Multilingual Program Translation" [2024-08] [paper]
"Automatic Library Migration Using Large Language Models: First Results" [2024-08] [paper]
"Context-aware Code Segmentation for C-to-Rust Translation using Large Language Models" [2024-09] [paper]
"TRANSAGENT: An LLM-Based Multi-Agent System for Code Translation" [2024-10] [paper]
"Unraveling the Potential of Large Language Models in Code Translation: How Far Are We?" [2024-10] [paper]
"CodeRosetta: Pushing the Boundaries of Unsupervised Code Translation for Parallel Programming" [2024-10] [paper]
"A test-free semantic mistakes localization framework in Neural Code Translation" [2024-10] [paper]
"Repository-Level Compositional Code Translation and Validation" [2024-10] [paper]
"Leveraging Large Language Models for Code Translation and Software Development in Scientific Computing" [2024-10] [paper]
"InterTrans: Leveraging Transitive Intermediate Translations to Enhance LLM-based Code Translation" [2024-11] [paper]
"Translating C To Rust: Lessons from a User Study" [2024-11] [paper]
"A Transformer-based Approach for Source Code Summarization" [2020-05] [ACL 2020] [paper]
"Code Summarization with Structure-induced Transformer" [2020-12] [ACL 2021 Findings] [paper]
"Code Structure Guided Transformer for Source Code Summarization" [2021-04] [ACM TSEM] [paper]
"M2TS: Multi-Scale Multi-Modal Approach Based on Transformer for Source Code Summarization" [2022-03] [ICPC 2022] [paper]
"AST-trans: code summarization with efficient tree-structured attention" [2022-05] [ICSE 2022] [paper]
"CoSS: Leveraging Statement Semantics for Code Summarization" [2023-03] [IEEE TSE] [paper]
"Automatic Code Summarization via ChatGPT: How Far Are We?" [2023-05] [paper]
"Semantic Similarity Loss for Neural Source Code Summarization" [2023-08] [paper]
"Distilled GPT for Source Code Summarization" [2023-08] [ASE] [paper]
"CSA-Trans: Code Structure Aware Transformer for AST" [2024-04] [paper]
"Analyzing the Performance of Large Language Models on Code Summarization" [2024-04] [paper]
"Enhancing Trust in LLM-Generated Code Summaries with Calibrated Confidence Scores" [2024-04] [paper]
"DocuMint: Docstring Generation for Python using Small Language Models" [2024-05] [paper] [repo]
"Natural Is The Best: Model-Agnostic Code Simplification for Pre-trained Large Language Models" [2024-05] [paper]
"Large Language Models for Code Summarization" [2024-05] [paper]
"Exploring the Efficacy of Large Language Models (GPT-4) in Binary Reverse Engineering" [2024-06] [paper]
"Identifying Inaccurate Descriptions in LLM-generated Code Comments via Test Execution" [2024-06] [paper]
"MALSIGHT: Exploring Malicious Source Code and Benign Pseudocode for Iterative Binary Malware Summarization" [2024-06] [paper]
"ESALE: Enhancing Code-Summary Alignment Learning for Source Code Summarization" [2024-07] [paper]
"Source Code Summarization in the Era of Large Language Models" [2024-07] [paper]
"Natural Language Outlines for Code: Literate Programming in the LLM Era" [2024-08] [paper]
"Context-aware Code Summary Generation" [2024-08] [paper]
"AUTOGENICS: Automated Generation of Context-Aware Inline Comments for Code Snippets on Programming Q&A Sites Using LLM" [2024-08] [paper]
"LLMs as Evaluators: A Novel Approach to Evaluate Bug Report Summarization" [2024-09] [paper]
"Evaluating the Quality of Code Comments Generated by Large Language Models for Novice Programmers" [2024-09] [paper]
"Generating Equivalent Representations of Code By A Self-Reflection Approach" [2024-10] [paper]
"A review of automatic source code summarization" [2024-10] [Empirical Software Engineering] [paper]
"DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons" [2021-05] [paper]
"Break-It-Fix-It: Unsupervised Learning for Program Repair" [2021-06] [ICML 2021] [paper]
"TFix: Learning to Fix Coding Errors with a Text-to-Text Transformer" [2021-07] [ICML 2021] [paper]
"Automated Repair of Programs from Large Language Models" [2022-05] [ICSE 2023] [paper]
"Less Training, More Repairing Please: Revisiting Automated Program Repair via Zero-shot Learning" [2022-07] [ESEC/FSE 2022] [paper]
"Repair Is Nearly Generation: Multilingual Program Repair with LLMs" [2022-08] [AAAI 2023] [paper]
"Practical Program Repair in the Era of Large Pre-trained Language Models" [2022-10] [paper]
"VulRepair: a T5-based automated software vulnerability repair" [2022-11] [ESEC/FSE 2022] [paper]
"Conversational Automated Program Repair" [2023-01] [paper]
"Impact of Code Language Models on Automated Program Repair" [2023-02] [ICSE 2023] [paper]
"InferFix: End-to-End Program Repair with LLMs" [2023-03] [ESEC/FSE 2023] [paper]
"Enhancing Automated Program Repair through Fine-tuning and Prompt Engineering" [2023-04] [paper]
"A study on Prompt Design, Advantages and Limitations of ChatGPT for Deep Learning Program Repair" [2023-04] [paper]
"Domain Knowledge Matters: Improving Prompts with Fix Templates for Repairing Python Type Errors" [2023-06] [ICSE 2024] [paper]
"RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair" [2023-12] [paper]
"The Fact Selection Problem in LLM-Based Program Repair" [2024-04] [paper]
"Aligning LLMs for FL-free Program Repair" [2024-04] [paper]
"A Deep Dive into Large Language Models for Automated Bug Localization and Repair" [2024-04] [paper]
"Multi-Objective Fine-Tuning for Enhanced Program Repair with LLMs" [2024-04] [paper]
"How Far Can We Go with Practical Function-Level Program Repair?" [2024-04] [paper]
"Revisiting Unnaturalness for Automated Program Repair in the Era of Large Language Models" [2024-04] [paper]
"A Unified Debugging Approach via LLM-Based Multi-Agent Synergy" [2024-04] [paper]
"A Systematic Literature Review on Large Language Models for Automated Program Repair" [2024-05] [paper]
"NAVRepair: Node-type Aware C/C++ Code Vulnerability Repair" [2024-05] [paper]
"Automated Program Repair: Emerging trends pose and expose problems for benchmarks" [2024-05] [paper]
"Automated Repair of AI Code with Large Language Models and Formal Verification" [2024-05] [paper]
"A Case Study of LLM for Automated Vulnerability Repair: Assessing Impact of Reasoning and Patch Validation Feedback" [2024-05] [paper]
"CREF: An LLM-based Conversational Software Repair Framework for Programming Tutors" [2024-06] [paper]
"Towards Practical and Useful Automated Program Repair for Debugging" [2024-07] [paper]
"ThinkRepair: Self-Directed Automated Program Repair" [2024-07] [paper]
"MergeRepair: An Exploratory Study on Merging Task-Specific Adapters in Code LLMs for Automated Program Repair" [2024-08] [paper]
"RePair: Automated Program Repair with Process-based Feedback" [2024-08] [ACL 2024 Findings] [paper]
"Enhancing LLM-Based Automated Program Repair with Design Rationales" [2024-08] [paper]
"Automated Software Vulnerability Patching using Large Language Models" [2024-08] [paper]
"Enhancing Source Code Security with LLMs: Demystifying The Challenges and Generating Reliable Repairs" [2024-09] [paper]
"MarsCode Agent: AI-native Automated Bug Fixing" [2024-09] [paper]
"Co-Learning: Code Learning for Multi-Agent Reinforcement Collaborative Framework with Conversational Natural Language Interfaces" [2024-09] [paper]
"Debugging with Open-Source Large Language Models: An Evaluation" [2024-09] [paper]
"VulnLLMEval: A Framework for Evaluating Large Language Models in Software Vulnerability Detection and Patching" [2024-09] [paper]
"ContractTinker: LLM-Empowered Vulnerability Repair for Real-World Smart Contracts" [2024-09] [paper]
"Can GPT-O1 Kill All Bugs? An Evaluation of GPT-Family LLMs on QuixBugs" [2024-09] [paper]
"Exploring and Lifting the Robustness of LLM-powered Automated Program Repair with Metamorphic Testing" [2024-10] [paper]
"LecPrompt: A Prompt-based Approach for Logical Error Correction with CodeBERT" [2024-10] [paper]
"Semantic-guided Search for Efficient Program Repair with Large Language Models" [2024-10] [paper]
"A Comprehensive Survey of AI-Driven Advancements and Techniques in Automated Program Repair and Code Generation" [2024-11] [paper]
"Self-Supervised Contrastive Learning for Code Retrieval and Summarization via Semantic-Preserving Transformations" [2020-09] [SIGIR 2021] [paper]
"REINFOREST: Reinforcing Semantic Code Similarity for Cross-Lingual Code Search Models" [2023-05] [paper]
"Rewriting the Code: A Simple Method for Large Language Model Augmented Code Search" [2024-01] [ACL 2024] [paper]
"Revisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance" [2024-04] [ACL 2024 short] [paper]
"Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension" [2024-04] [paper]
"Refining Joint Text and Source Code Embeddings for Retrieval Task with Parameter-Efficient Fine-Tuning" [2024-05] [paper]
"Typhon: Automatic Recommendation of Relevant Code Cells in Jupyter Notebooks" [2024-05] [paper]
"Toward Exploring the Code Understanding Capabilities of Pre-trained Code Generation Models" [2024-06] [paper]
"Aligning Programming Language and Natural Language: Exploring Design Choices in Multi-Modal Transformer-Based Embedding for Bug Localization" [2024-06] [paper]
"Assessing the Code Clone Detection Capability of Large Language Models" [2024-07] [paper]
"CodeCSE: A Simple Multilingual Model for Code and Comment Sentence Embeddings" [2024-07] [paper]
"Large Language Models for cross-language code clone detection" [2024-08] [paper]
"Coding-PTMs: How to Find Optimal Code Pre-trained Models for Code Embedding in Vulnerability Detection?" [2024-08] [paper]
"You Augment Me: Exploring ChatGPT-based Data Augmentation for Semantic Code Search" [2024-08] [paper]
"Improving Source Code Similarity Detection Through GraphCodeBERT and Integration of Additional Features" [2024-08] [paper]
"LLM Agents Improve Semantic Code Search" [2024-08] [paper]
"zsLLMCode: An Effective Approach for Functional Code Embedding via LLM with Zero-Shot Learning" [2024-09] [paper]
"Exploring Demonstration Retrievers in RAG for Coding Tasks: Yeas and Nays!" [2024-10] [paper]
"Instructive Code Retriever: Learn from Large Language Model's Feedback for Code Intelligence Tasks" [2024-10] [paper]
"Binary Code Similarity Detection via Graph Contrastive Learning on Intermediate Representations" [2024-10] [paper]
"Are Decoder-Only Large Language Models the Silver Bullet for Code Search?" [2024-10] [paper]
"CodeXEmbed: A Generalist Embedding Model Family for Multiligual and Multi-task Code Retrieval" [2024-11] [paper]
"CodeSAM: Source Code Representation Learning by Infusing Self-Attention with Multi-Code-View Graphs" [2024-11] [paper]
"EnStack: An Ensemble Stacking Framework of Large Language Models for Enhanced Vulnerability Detection in Source Code" [2024-11] [paper]
"Isotropy Matters: Soft-ZCA Whitening of Embeddings for Semantic Code Search" [2024-11] [paper]
"An Empirical Study on the Code Refactoring Capability of Large Language Models" [2024-11] [paper]
"Automated Update of Android Deprecated API Usages with Large Language Models" [2024-11] [paper]
"An Empirical Study on the Potential of LLMs in Automated Software Refactoring" [2024-11] [paper]
"CODECLEANER: Elevating Standards with A Robust Data Contamination Mitigation Toolkit" [2024-11] [paper]
"Instruct or Interact? Exploring and Eliciting LLMs' Capability in Code Snippet Adaptation Through Prompt Engineering" [2024-11] [paper]
"Learning type annotation: is big data enough?" [2021-08] [ESEC/FSE 2021] [paper]
"Do Machine Learning Models Produce TypeScript Types That Type Check?" [2023-02] [ECOOP 2023] [paper]
"TypeT5: Seq2seq Type Inference using Static Analysis" [2023-03] [ICLR 2023] [paper]
"Type Prediction With Program Decomposition and Fill-in-the-Type Training" [2023-05] [paper]
"Generative Type Inference for Python" [2023-07] [ASE 2023] [paper]
"Activation Steering for Robust Type Prediction in CodeLLMs" [2024-04] [paper]
"An Empirical Study of Large Language Models for Type and Call Graph Analysis" [2024-10] [paper]
"Repository-Level Prompt Generation for Large Language Models of Code" [2022-06] [ICML 2023] [paper]
"CoCoMIC: Code Completion By Jointly Modeling In-file and Cross-file Context" [2022-12] [paper]
"RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation" [2023-03] [EMNLP 2023] [paper]
"Coeditor: Leveraging Repo-level Diffs for Code Auto-editing" [2023-05] [ICLR 2024 Spotlight] [paper]
"RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems" [2023-06] [ICLR 2024] [paper]
"Guiding Language Models of Code with Global Context using Monitors" [2023-06] [paper]
"RepoFusion: Training Code Models to Understand Your Repository" [2023-06] [paper]
"CodePlan: Repository-level Coding using LLMs and Planning" [2023-09] [paper]
"SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" [2023-10] [ICLR 2024] [paper]
"CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion" [2023-10] [NeurIPS 2023] [paper]
"A^3-CodGen: A Repository-Level Code Generation Framework for Code Reuse with Local-Aware, Global-Aware, and Third-Party-Library-Aware" [2023-12] [paper]
"Teaching Code LLMs to Use Autocompletion Tools in Repository-Level Code Generation" [2024-01] [paper]
"RepoHyper: Better Context Retrieval Is All You Need for Repository-Level Code Completion" [2024-03] [paper]
"Repoformer: Selective Retrieval for Repository-Level Code Completion" [2024-03] [ICML 2024] [paper]
"CodeS: Natural Language to Code Repository via Multi-Layer Sketch" [2024-03] [paper]
"Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository" [2024-04] [paper]
"Contextual API Completion for Unseen Repositories Using LLMs" [2024-05] [paper]
"Dataflow-Guided Retrieval Augmentation for Repository-Level Code Completion" [2024-05][ACL 2024] [paper]
"How to Understand Whole Software Repository?" [2024-06] [paper]
"R2C2-Coder: Enhancing and Benchmarking Real-world Repository-level Code Completion Abilities of Code Large Language Models" [2024-06] [paper]
"CodeR: Issue Resolving with Multi-Agent and Task Graphs" [2024-06] [paper]
"Enhancing Repository-Level Code Generation with Integrated Contextual Information" [2024-06] [paper]
"On The Importance of Reasoning for Context Retrieval in Repository-Level Code Editing" [2024-06] [paper]
"GraphCoder: Enhancing Repository-Level Code Completion via Code Context Graph-based Retrieval and Language Model" [2024-06] [ASE 2024] [paper]
"STALL+: Boosting LLM-based Repository-level Code Completion with Static Analysis" [2024-06] [paper]
"Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs" [2024-06] [paper]
"Agentless: Demystifying LLM-based Software Engineering Agents" [2024-07] [paper]
"RLCoder: Reinforcement Learning for Repository-Level Code Completion" [2024-07] [paper]
"CoEdPilot: Recommending Code Edits with Learned Prior Edit Relevance, Project-wise Awareness, and Interactive Nature" [2024-08] [paper] [repo]
"RAMBO: Enhancing RAG-based Repository-Level Method Body Completion" [2024-09] [paper]
"Exploring the Potential of Conversational Test Suite Based Program Repair on SWE-bench" [2024-10] [paper]
"RepoGraph: Enhancing AI Software Engineering with Repository-level Code Graph" [2024-10] [paper]
"See-Saw Generative Mechanism for Scalable Recursive Code Generation with Generative AI" [2024-11] [paper]
"Seeking the user interface", 2014-09, ASE 2014, [paper]
"pix2code: Generating Code from a Graphical User Interface Screenshot", 2017-05, EICS 2018, [paper]
"Machine Learning-Based Prototyping of Graphical User Interfaces for Mobile Apps", 2018-02, TSE 2020, [paper]
"Automatic HTML Code Generation from Mock-Up Images Using Machine Learning Techniques", 2019-04, EBBT 2019, [paper]
"Sketch2code: Generating a website from a paper mockup", 2019-05, [paper]
"HTLM: Hyper-Text Pre-Training and Prompting of Language Models", 2021-07, ICLR 2022, [paper]
"Learning UI-to-Code Reverse Generator Using Visual Critic Without Rendering", 2023-05, [paper]
"Design2Code: How Far Are We From Automating Front-End Engineering?" [2024-03] [paper]
"Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset" [2024-03] [paper]
"VISION2UI: A Real-World Dataset with Layout for Code Generation from UI Designs" [2024-04] [paper]
"LogoMotion: Visually Grounded Code Generation for Content-Aware Animation" [2024-05] [paper]
"PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM" [2024-06] [paper]
"UICoder: Finetuning Large Language Models to Generate User Interface Code through Automated Feedback" [2024-06] [paper]
"On AI-Inspired UI-Design" [2024-06] [paper]
"Identifying User Goals from UI Trajectories" [2024-06] [paper]
"Automatically Generating UI Code from Screenshot: A Divide-and-Conquer-Based Approach" [2024-06] [paper]
"Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs" [2024-06] [paper]
"Vision-driven Automated Mobile GUI Testing via Multimodal Large Language Model" [2024-07] [paper]
"AUITestAgent: Automatic Requirements Oriented GUI Function Testing" [2024-07] [paper]
"LLM-based Abstraction and Concretization for GUI Test Migration" [2024-09] [paper]
"Enabling Cost-Effective UI Automation Testing with Retrieval-Based LLMs: A Case Study in WeChat" [2024-09] [paper]
"Self-Elicitation of Requirements with Automated GUI Prototyping" [2024-09] [paper]
"Infering Alt-text For UI Icons With Large Language Models During App Development" [2024-09] [paper]
"Leveraging Large Vision Language Model For Better Automatic Web GUI Testing" [2024-10] [paper]
"Sketch2Code: Evaluating Vision-Language Models for Interactive Web Design Prototyping" [2024-10] [paper]
"WAFFLE: Multi-Modal Model for Automated Front-End Development" [2024-10] [paper]
"DesignRepair: Dual-Stream Design Guideline-Aware Frontend Repair with Large Language Models" [2024-11] [paper]
"Interaction2Code: How Far Are We From Automatic Interactive Webpage Generation?" [2024-11] [paper]
"A Multi-Agent Approach for REST API Testing with Semantic Graphs and LLM-Driven Inputs" [2024-11] [paper]
"PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models" [2021-09] [EMNLP 2021] [paper]
"CodexDB: Generating Code for Processing SQL Queries using GPT-3 Codex" [2022-04] [paper]
"T5QL: Taming language models for SQL generation" [2022-09] [paper]
"Towards Generalizable and Robust Text-to-SQL Parsing" [2022-10] [EMNLP 2022 Findings] [paper]
"XRICL: Cross-lingual Retrieval-Augmented In-Context Learning for Cross-lingual Text-to-SQL Semantic Parsing" [2022-10] [EMNLP 2022 Findings] [paper]
"A comprehensive evaluation of ChatGPT's zero-shot Text-to-SQL capability" [2023-03] [paper]
"DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction" [2023-04] [NeurIPS 2023] [paper]
"How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings" [2023-05] [paper]
"Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies" [2023-05] [paper]
"SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL" [2023-05] [paper]
"Retrieval-augmented GPT-3.5-based Text-to-SQL Framework with Sample-aware Prompting and Dynamic Revision Chain" [2023-07] [ICONIP 2023] [paper]
"Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation" [2023-08] [paper]
"MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL" [2023-12] [paper]
"Investigating the Impact of Data Contamination of Large Language Models in Text-to-SQL Translation" [2024-02] [ACL 2024 Findings] [paper]
"Decomposition for Enhancing Attention: Improving LLM-based Text-to-SQL through Workflow Paradigm" [2024-02] [ACL 2024 Findings] [paper]
"Knowledge-to-SQL: Enhancing SQL Generation with Data Expert LLM" [2024-02] [ACL 2024 Findings] [paper]
"Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark" [2024-02] [ACL 2024 short] [paper]
"SQL-Encoder: Improving NL2SQL In-Context Learning Through a Context-Aware Encoder" [2024-03] [paper]
"LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency" [2024-04] [paper]
"Dubo-SQL: Diverse Retrieval-Augmented Generation and Fine Tuning for Text-to-SQL" [2024-04] [paper]
"EPI-SQL: Enhancing Text-to-SQL Translation with Error-Prevention Instructions" [2024-04] [paper]
"ProbGate at EHRSQL 2024: Enhancing SQL Query Generation Accuracy through Probabilistic Threshold Filtering and Error Handling" [2024-04] [paper]
"CoE-SQL: In-Context Learning for Multi-Turn Text-to-SQL with Chain-of-Editions" [2024-05] [paper]
"Open-SQL Framework: Enhancing Text-to-SQL on Open-source Large Language Models" [2024-05] [paper]
"MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation" [2024-05] [paper]
"PromptMind Team at EHRSQL-2024: Improving Reliability of SQL Generation using Ensemble LLMs" [2024-05] [paper]
"LG AI Research & KAIST at EHRSQL 2024: Self-Training Large Language Models with Pseudo-Labeled Unanswerable Questions for a Reliable Text-to-SQL System on EHRs" [2024-05] [paper]
"Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation" [2024-05] [ACL 2024 Findings] [paper]
"CHESS: Contextual Harnessing for Efficient SQL Synthesis" [2024-05] [paper]
"DeTriever: Decoder-representation-based Retriever for Improving NL2SQL In-Context Learning" [2024-06] [paper]
"Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL" [2024-06] [paper]
"RH-SQL: Refined Schema and Hardness Prompt for Text-to-SQL" [2024-06] [paper]
"QDA-SQL: Questions Enhanced Dialogue Augmentation for Multi-Turn Text-to-SQL" [2024-06] [paper]
"End-to-end Text-to-SQL Generation within an Analytics Insight Engine" [2024-06] [paper]
"MAGIC: Generating Self-Correction Guideline for In-Context Text-to-SQL" [2024-06] [paper]
"SQLFixAgent: Towards Semantic-Accurate SQL Generation via Multi-Agent Collaboration" [2024-06] [paper]
"Unmasking Database Vulnerabilities: Zero-Knowledge Schema Inference Attacks in Text-to-SQL Systems" [2024-06] [paper]
"Lucy: Think and Reason to Solve Text-to-SQL" [2024-07] [paper]
"ESM+: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models" [2024-07] [paper]
"RB-SQL: A Retrieval-based LLM Framework for Text-to-SQL" [2024-07] [paper]
"AI-Assisted SQL Authoring at Industry Scale" [2024-07] [paper]
"SQLfuse: Enhancing Text-to-SQL Performance through Comprehensive LLM Synergy" [2024-07] [paper]
"A Survey on Employing Large Language Models for Text-to-SQL Tasks" [2024-07] [paper]
"Towards Automated Data Sciences with Natural Language and SageCopilot: Practices and Lessons Learned" [2024-07] [paper]
"Evaluating LLMs for Text-to-SQL Generation With Complex SQL Workload" [2024-07] [paper]
"Synthesizing Text-to-SQL Data from Weak and Strong LLMs" [2024-08] [ACL 2024] [paper]
"Improving Relational Database Interactions with Large Language Models: Column Descriptions and Their Impact on Text-to-SQL Performance" [2024-08] [paper]
"The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models" [2024-08] [paper]
"MAG-SQL: Multi-Agent Generative Approach with Soft Schema Linking and Iterative Sub-SQL Refinement for Text-to-SQL" [2024-08] [paper]
"Enhancing Text-to-SQL Parsing through Question Rewriting and Execution-Guided Refinement" [2024-08] [ACL 2024 Findings] [paper]
"DAC: Decomposed Automation Correction for Text-to-SQL" [2024-08] [paper]
"Interactive-T2S: Multi-Turn Interactions for Text-to-SQL with Large Language Models" [2024-08] [paper]
"SQL-GEN: Bridging the Dialect Gap for Text-to-SQL Via Synthetic Data And Model Merging" [2024-08] [paper]
"Enhancing SQL Query Generation with Neurosymbolic Reasoning" [2024-08] [paper]
"Text2SQL is Not Enough: Unifying AI and Databases with TAG" [2024-08] [paper]
"Tool-Assisted Agent on SQL Inspection and Refinement in Real-World Scenarios" [2024-08] [paper]
"SelECT-SQL: Self-correcting ensemble Chain-of-Thought for Text-to-SQL" [2024-09] [paper]
"You Only Read Once (YORO): Learning to Internalize Database Knowledge for Text-to-SQL" [2024-09] [paper]
"PTD-SQL: Partitioning and Targeted Drilling with LLMs in Text-to-SQL" [2024-09] [paper]
"Enhancing Text-to-SQL Capabilities of Large Language Models via Domain Database Knowledge Injection" [2024-09] [paper]
"DataGpt-SQL-7B: An Open-Source Language Model for Text-to-SQL" [2024-09] [paper]
"E-SQL: Direct Schema Linking via Question Enrichment in Text-to-SQL" [2024-09] [paper]
"FLEX: Expert-level False-Less EXecution Metric for Reliable Text-to-SQL Benchmark" [2024-09] [paper]
"Enhancing LLM Fine-tuning for Text-to-SQLs by SQL Quality Measurement" [2024-10] [paper]
"From Natural Language to SQL: Review of LLM-based Text-to-SQL Systems" [2024-10] [paper]
"CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL" [2024-10] [paper]
"Context-Aware SQL Error Correction Using Few-Shot Learning -- A Novel Approach Based on NLQ, Error, and SQL Similarity" [2024-10] [paper]
"Learning from Imperfect Data: Towards Efficient Knowledge Distillation of Autoregressive Language Models for Text-to-SQL" [2024-10] [paper]
"LR-SQL: A Supervised Fine-Tuning Method for Text2SQL Tasks under Low-Resource Scenarios" [2024-10] [paper]
"MSc-SQL: Multi-Sample Critiquing Small Language Models For Text-To-SQL Translation" [2024-10] [paper]
"Learning Metadata-Agnostic Representations for Text-to-SQL In-Context Example Selection" [2024-10] [paper]
"An Actor-Critic Approach to Boosting Text-to-SQL Large Language Model" [2024-10] [paper]
"RSL-SQL: Robust Schema Linking in Text-to-SQL Generation" [2024-10] [paper]
"KeyInst: Keyword Instruction for Improving SQL Formulation in Text-to-SQL" [2024-10] [paper]
"Grounding Natural Language to SQL Translation with Data-Based Self-Explanations" [2024-11] [paper]
"PDC & DM-SFT: A Road for LLM SQL Bug-Fix Enhancing" [2024-11] [paper]
"XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL" [2024-11] [paper]
"Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL" [2024-11] [paper]
"Text-to-SQL Calibration: No Need to Ask -- Just Rescale Model Probabilities" [2024-11] [paper]
"Baldur: Whole-Proof Generation and Repair with Large Language Models" [2023-03] [FSE 2023] [paper]
"An In-Context Learning Agent for Formal Theorem-Proving" [2023-10] [paper]
"Towards AI-Assisted Synthesis of Verified Dafny Methods" [2024-02] [FSE 2024] [paper]
"Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming" [2024-05] [paper]
"Laurel: Generating Dafny Assertions Using Large Language Models" [2024-05] [paper]
"AutoVerus: Automated Proof Generation for Rust Code" [2024-09] [paper]
"Proof Automation with Large Language Models" [2024-09] [paper]
"Automated Proof Generation for Rust Code via Self-Evolution" [2024-10] [paper]
"CoqPilot, a plugin for LLM-based generation of proofs" [2024-10] [paper]
"dafny-annotator: AI-Assisted Verification of Dafny Programs" [2024-11] [paper]
"Unit Test Case Generation with Transformers and Focal Context" [2020-09] [AST@ICSE 2022] [paper]
"An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation" [2023-02] [IEEE TSE] [paper]
"A3Test: Assertion-Augmented Automated Test Case Generation" [2023-02] [paper]
"Learning Deep Semantics for Test Completion" [2023-02] [ICSE 2023] [paper]
"Using Large Language Models to Generate JUnit Tests: An Empirical Study" [2023-04] [EASE 2024] [paper]
"CodaMosa: Escaping Coverage Plateaus in Test Generation with Pre-Trained Large Language Models" [2023-05] [ICSE 2023] [paper]
"No More Manual Tests? Evaluating and Improving ChatGPT for Unit Test Generation" [2023-05] [paper]
"ChatUniTest: a ChatGPT-based automated unit test generation tool" [2023-05] [paper]
"ChatGPT vs SBST: A Comparative Assessment of Unit Test Suite Generation" [2023-07] [paper]
"Can Large Language Models Write Good Property-Based Tests?" [2023-07] [paper]
"Domain Adaptation for Deep Unit Test Case Generation" [2023-08] [paper]
"Effective Test Generation Using Pre-trained Large Language Models and Mutation Testing" [2023-08] [paper]
"How well does LLM generate security tests?" [2023-10] [paper]
"Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation" [2023-10] [paper]
"An initial investigation of ChatGPT unit test generation capability" [2023-10] [SAST 2023] [paper]
"CoverUp: Coverage-Guided LLM-Based Test Generation" [2024-03] [paper]
"Enhancing LLM-based Test Generation for Hard-to-Cover Branches via Program Analysis" [2024-04] [paper]
"Large Language Models for Mobile GUI Text Input Generation: An Empirical Study" [2024-04] [paper]
"Test Code Generation for Telecom Software Systems using Two-Stage Generative Model" [2024-04] [paper]
"LLM-Powered Test Case Generation for Detecting Tricky Bugs" [2024-04] [paper]
"Generating Test Scenarios from NL Requirements using Retrieval-Augmented LLMs: An Industrial Study" [2024-04] [paper]
"Large Language Models as Test Case Generators: Performance Evaluation and Enhancement" [2024-04] [paper]
"Leveraging Large Language Models for Automated Web-Form-Test Generation: An Empirical Study" [2024-05] [paper]
"DLLens: Testing Deep Learning Libraries via LLM-aided Synthesis" [2024-06] [paper]
"Exploring Fuzzing as Data Augmentation for Neural Test Generation" [2024-06] [paper]
"Mokav: Execution-driven Differential Testing with LLMs" [2024-06] [paper]
"Code Agents are State of the Art Software Testers" [2024-06] [paper]
"CasModaTest: A Cascaded and Model-agnostic Self-directed Framework for Unit Test Generation" [2024-06] [paper]
"An Empirical Study of Unit Test Generation with Large Language Models" [2024-06] [paper]
"Large-scale, Independent and Comprehensive study of the power of LLMs for test case generation" [2024-06] [paper]
"Augmenting LLMs to Repair Obsolete Test Cases with Static Collector and Neural Reranker" [2024-07] [paper]
"Harnessing the Power of LLMs: Automating Unit Test Generation for High-Performance Computing" [2024-07] [paper]
"An LLM-based Readability Measurement for Unit Tests' Context-aware Inputs" [2024-07] [paper]
"A System for Automated Unit Test Generation Using Large Language Models and Assessment of Generated Test Suites" [2024-08] [paper]
"Leveraging Large Language Models for Enhancing the Understandability of Generated Unit Tests" [2024-08] [paper]
"Multi-language Unit Test Generation using LLMs" [2024-09] [paper]
"Exploring the Integration of Large Language Models in Industrial Test Maintenance Processes" [2024-09] [paper]
"Python Symbolic Execution with LLM-powered Code Generation" [2024-09] [paper]
"Rethinking the Influence of Source Code on Test Case Generation" [2024-09] [paper]
"On the Effectiveness of LLMs for Manual Test Verifications" [2024-09] [paper]
"Retrieval-Augmented Test Generation: How Far Are We?" [2024-09] [paper]
"Context-Enhanced LLM-Based Framework for Automatic Test Refactoring" [2024-09] [paper]
"TestBench: Evaluating Class-Level Test Case Generation Capability of Large Language Models" [2024-09] [paper]
"Advancing Bug Detection in Fastjson2 with Large Language Models Driven Unit Test Generation" [2024-10] [paper]
"Test smells in LLM-Generated Unit Tests" [2024-10] [paper]
"LLM-based Unit Test Generation via Property Retrieval" [2024-10] [paper]
"Disrupting Test Development with AI Assistants" [2024-11] [paper]
"Parameter-Efficient Fine-Tuning of Large Language Models for Unit Test Generation: An Empirical Study" [2024-11] [paper]
"VALTEST: Automated Validation of Language Model Generated Test Cases" [2024-11] [paper]
"REACCEPT: Automated Co-evolution of Production and Test Code Based on Dynamic Validation and Large Language Models" [2024-11] [paper]
"Generating Accurate Assert Statements for Unit Test Cases using Pretrained Transformers" [2020-09] [paper]
"TOGA: A Neural Method for Test Oracle Generation" [2021-09] [ICSE 2022] [paper]
"TOGLL: Correct and Strong Test Oracle Generation with LLMs" [2024-05] [paper]
"Test Oracle Automation in the era of LLMs" [2024-05] [paper]
"Beyond Code Generation: Assessing Code LLM Maturity with Postconditions" [2024-07] [paper]
"Chat-like Asserts Prediction with the Support of Large Language Model" [2024-07] [paper]
"Do LLMs generate test oracles that capture the actual or the expected program behaviour?" [2024-10] [paper]
"Generating executable oracles to check conformance of client code to requirements of JDK Javadocs using LLMs" [2024-11] [paper]
"Automatically Write Code Checker: An LLM-based Approach with Logic-guided API Retrieval and Case by Case Iteration" [2024-11] [paper]
"ASSERTIFY: Utilizing Large Language Models to Generate Assertions for Production Code" [2024-11] [paper]
"μBERT: Mutation Testing using Pre-Trained Language Models" [2022-03] [paper]
"Efficient Mutation Testing via Pre-Trained Language Models" [2023-01] [paper]
"LLMorpheus: Mutation Testing using Large Language Models" [2024-04] [paper]
"An Exploratory Study on Using Large Language Models for Mutation Testing" [2024-06] [paper]
"Fine-Tuning LLMs for Code Mutation: A New Era of Cyber Threats" [2024-10] [paper]
"Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models" [2022-12] [paper]
"Fuzz4All: Universal Fuzzing with Large Language Models" [2023-08] [paper]
"WhiteFox: White-Box Compiler Fuzzing Empowered by Large Language Models" [2023-10] [paper]
"LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing" [2024-06] [paper]
"FuzzCoder: Byte-level Fuzzing Test via Large Language Model" [2024-09] [paper]
"ISC4DGF: Enhancing Directed Grey-box Fuzzing with LLM-Driven Initial Seed Corpus Generation" [2024-09] [paper]
"Large Language Models Based JSON Parser Fuzzing for Bug Discovery and Behavioral Analysis" [2024-10] [paper]
"Fixing Security Vulnerabilities with AI in OSS-Fuzz" [2024-11] [paper]
"A Code Knowledge Graph-Enhanced System for LLM-Based Fuzz Driver Generation" [2024-11] [paper]
"VulDeePecker: A Deep Learning-Based System for Vulnerability Detection" [2018-01] [NDSS 2018] [paper]
"DeepBugs: A Learning Approach to Name-based Bug Detection" [2018-04] [Proc. ACM Program. Lang.] [paper]
"Automated Vulnerability Detection in Source Code Using Deep Representation Learning" [2018-07] [ICMLA 2018] [paper]
"SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities" [2018-07] [IEEE TDSC] [paper]
"Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks" [2019-09] [NeurIPS 2019] [paper]
"Improving bug detection via context-based code representation learning and attention-based neural networks" [2019-10] [Proc. ACM Program. Lang.] [paper]
"Global Relational Models of Source Code" [2019-12] [ICLR 2020] [paper]
"VulDeeLocator: A Deep Learning-based Fine-grained Vulnerability Detector" [2020-01] [IEEE TDSC] [paper]
"Deep Learning based Vulnerability Detection: Are We There Yet?" [2020-09] [IEEE TSE] [paper]
"Security Vulnerability Detection Using Deep Learning Natural Language Processing" [2021-05] [INFOCOM Workshops 2021] [paper]
"Self-Supervised Bug Detection and Repair" [2021-05] [NeurIPS 2021] [paper]
"Vulnerability Detection with Fine-grained Interpretations" [2021-06] [ESEC/SIGSOFT FSE 2021] [paper]
"ReGVD: Revisiting Graph Neural Networks for Vulnerability Detection" [2021-10] [ICSE Companion 2022] [paper]
"VUDENC: Vulnerability Detection with Deep Learning on a Natural Codebase for Python" [2022-01] [Inf. Softw. Technol] [paper]
"Transformer-Based Language Models for Software Vulnerability Detection" [222-04] [ACSAC 2022] [paper]
"LineVul: A Transformer-based Line-Level Vulnerability Prediction" [2022-05] [MSR 2022] [paper]
"VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection" [2022-05] [IJCNN 2022] [paper]
"Open Science in Software Engineering: A Study on Deep Learning-Based Vulnerability Detection" [2022-09] [IEEE TSE] [paper]
"An Empirical Study of Deep Learning Models for Vulnerability Detection" [2022-12] [ICSE 2023] [paper]
"CSGVD: A deep learning approach combining sequence and graph embedding for source code vulnerability detection" [2023-01] [J. 시스템 Softw.] [paper]
"Benchmarking Software Vulnerability Detection Techniques: A Survey" [2023-03] [paper]
"Transformer-based Vulnerability Detection in Code at EditTime: Zero-shot, Few-shot, or Fine-tuning?" [2023-05] [paper]
"A Survey on Automated Software Vulnerability Detection Using Machine Learning and Deep Learning" [2023-06] [paper]
"Limits of Machine Learning for Automatic Vulnerability Detection" [2023-06] [paper]
"Evaluating Instruction-Tuned Large Language Models on Code Comprehension and Generation" [2023-08] [paper]
"Prompt-Enhanced Software Vulnerability Detection Using ChatGPT" [2023-08] [paper]
"Towards Causal Deep Learning for Vulnerability Detection" [2023-10] [paper]
"Understanding the Effectiveness of Large Language Models in Detecting Security Vulnerabilities" [2023-11] [paper]
"How Far Have We Gone in Vulnerability Detection Using Large Language Models" [2023-11] [paper]
"Can Large Language Models Identify And Reason About Security Vulnerabilities? Not Yet" [2023-12] [paper]
"LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs' Vulnerability Reasoning" [2024-01] [paper]
"Security Code Review by LLMs: A Deep Dive into Responses" [2024-01] [paper]
"Chain-of-Thought Prompting of Large Language Models for Discovering and Fixing Software Vulnerabilities" [2024-02] [paper]
"Multi-role Consensus through LLMs Discussions for Vulnerability Detection" [2024-03] [paper]
"A Comprehensive Study of the Capabilities of Large Language Models for Vulnerability Detection" [2024-03] [paper]
"Vulnerability Detection with Code Language Models: How Far Are We?" [2024-03] [paper]
"Multitask-based Evaluation of Open-Source LLM on Software Vulnerability" [2024-04] [paper]
"Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap" [2024-04] [paper]
"Pros and Cons! Evaluating ChatGPT on Software Vulnerability" [2024-04] [paper]
"VulEval: Towards Repository-Level Evaluation of Software Vulnerability Detection" [2024-04] [paper]
"DLAP: A Deep Learning Augmented Large Language Model Prompting Framework for Software Vulnerability Detection" [2024-05] [paper]
"Bridging the Gap: A Study of AI-based Vulnerability Management between Industry and Academia" [2024-05] [paper]
"Bridge and Hint: Extending Pre-trained Language Models for Long-Range Code" [2024-05] [paper]
"Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study" [2024-05] [paper]
"LLM-Assisted Static Analysis for Detecting Security Vulnerabilities" [2024-05] [paper]
"Generalization-Enhanced Code Vulnerability Detection via Multi-Task Instruction Fine-Tuning" [2024-06] [ACL 2024 Findings] [paper]
"Security Vulnerability Detection with Multitask Self-Instructed Fine-Tuning of Large Language Models" [2024-06] [paper]
"M2CVD: Multi-Model Collaboration for Code Vulnerability Detection" [2024-06] [paper]
"Towards Effectively Detecting and Explaining Vulnerabilities Using Large Language Models" [2024-06] [paper]
"Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG" [2024-06] [paper]
"Bug In the Code Stack: Can LLMs Find Bugs in Large Python Code Stacks" [2024-06] [paper]
"Supporting Cross-language Cross-project Bug Localization Using Pre-trained Language Models" [2024-07] [paper]
"ALPINE: An adaptive language-agnostic pruning method for language models for code" [2024-07] [paper]
"SCoPE: Evaluating LLMs for Software Vulnerability Detection" [2024-07] [paper]
"Comparison of Static Application Security Testing Tools and Large Language Models for Repo-level Vulnerability Detection" [2024-07] [paper]
"Code Structure-Aware through Line-level Semantic Learning for Code Vulnerability Detection" [2024-07] [paper]
"A Study of Using Multimodal LLMs for Non-Crash Functional Bug Detection in Android Apps" [2024-07] [paper]
"EaTVul: ChatGPT-based Evasion Attack Against Software Vulnerability Detection" [2024-07] [paper]
"Evaluating Large Language Models in Detecting Test Smells" [2024-07] [paper]
"Automated Software Vulnerability Static Code Analysis Using Generative Pre-Trained Transformer Models" [2024-07] [paper]
"A Qualitative Study on Using ChatGPT for Software Security: Perception vs. Practicality" [2024-08] [paper]
"Large Language Models for Secure Code Assessment: A Multi-Language Empirical Study" [2024-08] [paper]
"VulCatch: Enhancing Binary Vulnerability Detection through CodeT5 Decompilation and KAN Advanced Feature Extraction" [2024-08] [paper]
"Impact of Large Language Models of Code on Fault Localization" [2024-08] [paper]
"Better Debugging: Combining Static Analysis and LLMs for Explainable Crashing Fault Localization" [2024-08] [paper]
"Beyond ChatGPT: Enhancing Software Quality Assurance Tasks with Diverse LLMs and Validation Techniques" [2024-09] [paper]
"CLNX: Bridging Code and Natural Language for C/C++ Vulnerability-Contributing Commits Identification" [2024-09] [paper]
"Code Vulnerability Detection: A Comparative Analysis of Emerging Large Language Models" [2024-09] [paper]
"Program Slicing in the Era of Large Language Models" [2024-09] [paper]
"Generating API Parameter Security Rules with LLM for API Misuse Detection" [2024-09] [paper]
"Enhancing Fault Localization Through Ordered Code Analysis with LLM Agents and Self-Reflection" [2024-09] [paper]
"Comparing Unidirectional, Bidirectional, and Word2vec Models for Discovering Vulnerabilities in Compiled Lifted Code" [2024-09] [paper]
"Enhancing Pre-Trained Language Models for Vulnerability Detection via Semantic-Preserving Data Augmentation" [2024-10] [paper]
"StagedVulBERT: Multi-Granular Vulnerability Detection with a Novel Pre-trained Code Model" [2024-10] [paper]
"Understanding the AI-powered Binary Code Similarity Detection" [2024-10] [paper]
"RealVul: Can We Detect Vulnerabilities in Web Applications with LLM?" [2024-10] [paper]
"Just-In-Time Software Defect Prediction via Bi-modal Change Representation Learning" [2024-10] [paper]
"DFEPT: Data Flow Embedding for Enhancing Pre-Trained Model Based Vulnerability Detection" [2024-10] [paper]
"Utilizing Precise and Complete Code Context to Guide LLM in Automatic False Positive Mitigation" [2024-11] [paper]
"Smart-LLaMA: Two-Stage Post-Training of Large Language Models for Smart Contract Vulnerability Detection and Explanation" [2024-11] [paper]
"FlexFL: Flexible and Effective Fault Localization with Open-Source Large Language Models" [2024-11] [paper]
"Breaking the Cycle of Recurring Failures: Applying Generative AI to Root Cause Analysis in Legacy Banking Systems" [2024-11] [paper]
"Are Large Language Models Memorizing Bug Benchmarks?" [2024-11] [paper]
"An Empirical Study of Vulnerability Detection using Federated Learning" [2024-11] [paper]
"Fault Localization from the Semantic Code Search Perspective" [2024-11] [paper]
"Deep Android Malware Detection", 2017-03, CODASPY 2017, [paper]
"A Multimodal Deep Learning Method for Android Malware Detection Using Various Features", 2018-08, IEEE Trans. inf. Forensics Secur. 2019, [paper]
"Portable, Data-Driven Malware Detection using Language Processing and Machine Learning Techniques on Behavioral Analysis Reports", 2018-12, Digit. Investig. 2019, [paper]
"I-MAD: Interpretable Malware Detector Using Galaxy Transformer", 2019-09, Comput. Secur. 2021, [paper]
"Droidetec: Android Malware Detection and Malicious Code Localization through Deep Learning", 2020-02, [paper]
"Malicious Code Detection: Run Trace Output Analysis by LSTM", 2021-01, IEEE Access 2021, [paper]
"Intelligent malware detection based on graph convolutional network", 2021-08, J. Supercomput. 2021, [paper]
"Malbert: A novel pre-training method for malware detection", 2021-09, Comput. Secur. 2021, [paper]
"Single-Shot Black-Box Adversarial Attacks Against Malware Detectors: A Causal Language Model Approach", 2021-12, ISI 2021, [paper]
"M2VMapper: Malware-to-Vulnerability mapping for Android using text processing", 2021-12, Expert Syst. 응용 2022, [paper]
"Malware Detection and Prevention using Artificial Intelligence Techniques", 2021-12, IEEE BigData 2021, [paper]
"An Ensemble of Pre-trained Transformer Models For Imbalanced Multiclass Malware Classification", 2021-12, Comput. Secur. 2022, [paper]
"EfficientNet convolutional neural networks-based Android malware detection", 2022-01, Comput. Secur. 2022, [paper]
"Static Malware Detection Using Stacked BiLSTM and GPT-2", 2022-05, IEEE Access 2022, [paper]
"APT Malicious Sample Organization Traceability Based on Text Transformer Model", 2022-07, PRML 2022, [paper]
"Self-Supervised Vision Transformers for Malware Detection", 2022-08, IEEE Access 2022, [paper]
"A Survey of Recent Advances in Deep Learning Models for Detecting Malware in Desktop and Mobile Platforms", 2022-09, ACM Computing Surveys, [paper]
"Malicious Source Code Detection Using Transformer", 2022-09, [paper]
"Flexible Android Malware Detection Model based on Generative Adversarial Networks with Code Tensor", 2022-10, CyberC 2022, [paper]
"MalBERTv2: Code Aware BERT-Based Model for Malware Identification" [2023-03] [Big Data Cogn. 컴퓨터. 2023] [paper]
"GPThreats-3: Is Automatic Malware Generation a Threat?" [2023-05] [SPW 2023] [paper]
"GitHub Copilot: A Threat to High School Security? Exploring GitHub Copilot's Proficiency in Generating Malware from Simple User Prompts" [2023-08] [ETNCC 2023] [paper]
"An Attacker's Dream? Exploring the Capabilities of ChatGPT for Developing Malware" [2023-08] [CSET 2023] [paper]
"Malicious code detection in android: the role of sequence characteristics and disassembling methods" [2023-12] [Int. J. Inf. 비서. 2023] [paper]
"Prompt Engineering-assisted Malware Dynamic Analysis Using GPT-4" [2023-12] [paper]
"Shifting the Lens: Detecting Malware in npm Ecosystem with Large Language Models" [2024-03] [paper]
"AppPoet: Large Language Model based Android malware detection via multi-view prompt engineering" [2024-04] [paper]
"Tactics, Techniques, and Procedures (TTPs) in Interpreted Malware: A Zero-Shot Generation with Large Language Models" [2024-07] [paper]
"DetectBERT: Towards Full App-Level Representation Learning to Detect Android Malware" [2024-08] [paper]
"PackageIntel: Leveraging Large Language Models for Automated Intelligence Extraction in Package Ecosystems" [2024-09] [paper]
"Learning Performance-Improving Code Edits" [2023-06] [ICLR 2024 Spotlight] [paper]
"Large Language Models for Compiler Optimization" [2023-09] [paper]
"Refining Decompiled C Code with Large Language Models" [2023-10] [paper]
"Priority Sampling of Large Language Models for Compilers" [2024-02] [paper]
"Should AI Optimize Your Code? A Comparative Study of Current Large Language Models Versus Classical Optimizing Compilers" [2024-06] [paper]
"Iterative or Innovative? A Problem-Oriented Perspective for Code Optimization" [2024-06] [paper]
"Meta Large Language Model Compiler: Foundation Models of Compiler Optimization" [2024-06] [paper]
"ViC: Virtual Compiler Is All You Need For Assembly Code Search" [2024-08] [paper]
"Search-Based LLMs for Code Optimization" [2024-08] [paper]
"E-code: Mastering Efficient Code Generation through Pretrained Models and Expert Encoder Group" [2024-08] [paper]
"Large Language Models for Energy-Efficient Code: Emerging Results and Future Directions" [2024-10] [paper]
"Using recurrent neural networks for decompilation" [2018-03] [SANER 2018] [paper]
"Evolving Exact Decompilation" [2018] [paper]
"Towards Neural Decompilation" [2019-05] [paper]
"Coda: An End-to-End Neural Program Decompiler" [2019-06] [NeurIPS 2019] [paper]
"N-Bref : A High-fidelity Decompiler Exploiting Programming Structures" [2020-09] [paper]
"Neutron: an attention-based neural decompiler" [2021-03] [Cybersecurity 2021] [paper]
"Beyond the C: Retargetable Decompilation using Neural Machine Translation" [2022-12] [paper]
"Boosting Neural Networks to Decompile Optimized Binaries" [2023-01] [ACSAC 2022] [paper]
"SLaDe: A Portable Small Language Model Decompiler for Optimized Assembly" [2023-05] [paper]
"Nova+: Generative Language Models for Binaries" [2023-11] [paper]
"CodeArt: Better Code Models by Attention Regularization When Symbols Are Lacking" [2024-11] [paper]
"LLM4Decompile: Decompiling Binary Code with Large Language Models" [2024-03] [paper]
"WaDec: Decompile WebAssembly Using Large Language Model" [2024-06] [paper]
"MAD: Move AI Decompiler to Improve Transparency and Auditability on Non-Open-Source Blockchain Smart Contract" [2024-10] [paper]
"Source Code Foundation Models are Transferable Binary Analysis Knowledge Bases" [2024-11] [paper]
"Automated Commit Message Generation with Large Language Models: An Empirical Study and Beyond" [2024-04] [paper]
"Towards Realistic Evaluation of Commit Message Generation by Matching Online and Offline Settings" [2024-10] [paper]
"Using Pre-Trained Models to Boost Code Review Automation" [2022-01] [ICSE 2022] [paper]
"AUGER: Automatically Generating Review Comments with Pre-training Models" [2022-08] [ESEC/FSE 2022] [paper]
"Automatic Code Review by Learning the Structure Information of Code Graph" [2023-02] [Sensors] [paper]
"LLaMA-Reviewer: Advancing Code Review Automation with Large Language Models through Parameter-Efficient Fine-Tuning" [2023-08] [ISSRE 2023] [paper]
"AI-powered Code Review with LLMs: Early Results" [2024-04] [paper]
"AI-Assisted Assessment of Coding Practices in Modern Code Review" [2024-05] [paper]
"A GPT-based Code Review System for Programming Language Learning" [2024-07] [paper]
"LLM Critics Help Catch LLM Bugs" [2024-06] [paper]
"Exploring the Capabilities of LLMs for Code Change Related Tasks" [2024-07] [paper]
"Evaluating Language Models for Generating and Judging Programming Feedback" [2024-07] [paper]
"Can LLMs Replace Manual Annotation of Software Engineering Artifacts?" [2024-08] [paper]
"Leveraging Reviewer Experience in Code Review Comment Generation" [2024-09] [paper]
"CRScore: Grounding Automated Evaluation of Code Review Comments in Code Claims and Smells" [2024-09] [paper]
"Enhancing Code Annotation Reliability: Generative AI's Role in Comment Quality Assessment Models" [2024-10] [paper]
"Knowledge-Guided Prompt Learning for Request Quality Assurance in Public Code Review" [2024-10] [paper]
"Impact of LLM-based Review Comment Generation in Practice: A Mixed Open-/Closed-source User Study" [2024-11] [paper]
"Prompting and Fine-tuning Large Language Models for Automated Code Review Comment Generation" [2024-11] [paper]
"Deep Learning-based Code Reviews: A Paradigm Shift or a Double-Edged Sword?" [2024-11] [paper]
"Redefining Crowdsourced Test Report Prioritization: An Innovative Approach with Large Language Model" [2024-11] [paper]
"LogStamp: Automatic Online Log Parsing Based on Sequence Labelling" [2022-08] [paper]
"Log Parsing with Prompt-based Few-shot Learning" [2023-02] [ICSE 2023] [paper]
"Log Parsing: How Far Can ChatGPT Go?" [2023-06] [ASE 2023] [paper]
"LogPrompt: Prompt Engineering Towards Zero-Shot and Interpretable Log Analysis" [2023-08] [paper]
"LogGPT: Exploring ChatGPT for Log-Based Anomaly Detection" [2023-09] [paper]
"An Assessment of ChatGPT on Log Data" [2023-09] [paper]
"LILAC: Log Parsing using LLMs with Adaptive Parsing Cache" [2023-10] [paper]
"LLMParser: An Exploratory Study on Using Large Language Models for Log Parsing" [2024-04] [paper]
"On the Influence of Data Resampling for Deep Learning-Based Log Anomaly Detection: Insights and Recommendations" [2024-05] [paper]
"Log Parsing with Self-Generated In-Context Learning and Self-Correction" [2024-06] [paper]
"Stronger, Faster, and Cheaper Log Parsing with LLMs" [2024-06] [paper]
"ULog: Unsupervised Log Parsing with Large Language Models through Log Contrastive Units" [2024-06] [paper]
"Anomaly Detection on Unstable Logs with GPT Models" [2024-06] [paper]
"LogParser-LLM: Advancing Efficient Log Parsing with Large Language Models" [2024-08] [KDD 2024] [paper]
"LUK: Empowering Log Understanding with Expert Knowledge from Large Language Models" [2024-09] [paper]
"A Comparative Study on Large Language Models for Log Parsing" [2024-09] [paper]
"What Information Contributes to Log-based Anomaly Detection? Insights from a Configurable Transformer-Based Approach" [2024-10] [paper]
"LogLM: From Task-based to Instruction-based Automated Log Analysis" [2024-10] [paper]
"Configuration Validation with Large Language Models" [2023-10] [paper]
"CloudEval-YAML: A Practical Benchmark for Cloud Configuration Generation" [2023-11] [paper]
"Can LLMs Configure Software Tools" [2023-12] [paper]
"LuaTaint: A Static Analysis System for Web Configuration Interface Vulnerability of Internet of Things Devices" [2024-02] [IOT] [paper]
"LLM-Based Misconfiguration Detection for AWS Serverless Computing" [2024-11] [paper]
"LogLLM: Log-based Anomaly Detection Using Large Language Models" [2024-11] [paper]
"Towards using Few-Shot Prompt Learning for Automating Model Completion" [2022-12] [paper]
"Model Generation from Requirements with LLMs: an Exploratory Study" [2024-04] [paper]
"How LLMs Aid in UML Modeling: An Exploratory Study with Novice Analysts" [2024-04] [paper]
"Leveraging Large Language Models for Software Model Completion: Results from Industrial and Public Datasets" [2024-06] [paper]
"Studying and Benchmarking Large Language Models For Log Level Suggestion" [2024-10] [paper]
"A Model Is Not Built By A Single Prompt: LLM-Based Domain Modeling With Question Decomposition" [2024-10] [paper]
"On the Utility of Domain Modeling Assistance with Large Language Models" [2024-10] [paper]
"On the use of Large Language Models in Model-Driven Engineering" [2024-10] [paper]
"LLM as a code generator in Agile Model Driven Development" [2024-10] [paper]
"A Transformer-based Approach for Abstractive Summarization of Requirements from Obligations in Software Engineering Contracts" [2023-09] [RE 2023] [paper]
"Advancing Requirements Engineering through Generative AI: Assessing the Role of LLMs" [2023-10] [paper]
"Requirements Engineering using Generative AI: Prompts and Prompting Patterns" [2023-11] [paper]
"Prioritizing Software Requirements Using Large Language Models" [2024-04] [paper]
"Lessons from the Use of Natural Language Inference (NLI) in Requirements Engineering Tasks" [2024-04] [paper]
"Enhancing Legal Compliance and Regulation Analysis with Large Language Models" [2024-04] [paper]
"MARE: Multi-Agents Collaboration Framework for Requirements Engineering" [2024-05] [paper]
"Natural Language Processing for Requirements Traceability" [2024-05] [paper]
"Multilingual Crowd-Based Requirements Engineering Using Large Language Models" [2024-08] [paper]
"From Specifications to Prompts: On the Future of Generative LLMs in Requirements Engineering" [2024-08] [paper]
"Leveraging LLMs for the Quality Assurance of Software Requirements" [2024-08] [paper]
"Generative AI for Requirements Engineering: A Systematic Literature Review" [2024-09] [paper]
"A Fine-grained Sentiment Analysis of App Reviews using Large Language Models: An Evaluation Study" [2024-09] [paper]
"Leveraging Large Language Models for Predicting Cost and Duration in Software Engineering Projects" [2024-09] [paper]
"Privacy Policy Analysis through Prompt Engineering for LLMs" [2024-09] [paper]
"Exploring Requirements Elicitation from App Store User Reviews Using Large Language Models" [2024-09] [paper]
"LLM-Cure: LLM-based Competitor User Review Analysis for Feature Enhancement" [2024-09] [paper]
"Automatic Instantiation of Assurance Cases from Patterns Using Large Language Models" [2024-10] [paper]
"Whose fault is it anyway? SILC: Safe Integration of LLM-Generated Code" [2024-10] [paper]
"Assured Automatic Programming via Large Language Models" [2024-10] [paper]
"Does GenAI Make Usability Testing Obsolete?" [2024-11] [paper]
"Exploring LLMs for Verifying Technical System Specifications Against Requirements" [2024-11] [paper]
"Towards the LLM-Based Generation of Formal Specifications from Natural-Language Contracts: Early Experiments with Symboleo" [2024-11] [paper]
"You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion" [2021-08] [USENIX Security Symposium 2021] [paper]
"Is GitHub's Copilot as Bad as Humans at Introducing Vulnerabilities in Code?" [2022-04] [Empir. Softw. Eng.] [paper]
"Lost at C: A User Study on the Security Implications of Large Language Model Code Assistants" [2022-08] [USENIX Security Symposium 2023] [paper]
"Do Users Write More Insecure Code with AI Assistants?" [2022-1] [CCS 2023] [paper]
"Large Language Models for Code: Security Hardening and Adversarial Testing" [2023-02] [CCS 2023] [paper]
"Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models" [2023-12] [paper]
"CodeAttack: Revealing Safety Generalization Challenges of Large Language Models via Code Completion" [2024-03] [ACL 2024 Findings] [paper]
"Just another copy and paste? Comparing the security vulnerabilities of ChatGPT generated code and StackOverflow answers" [2024-03] [paper]
"DeVAIC: A Tool for Security Assessment of AI-generated Code" [2024-04] [paper]
"CyberSecEval 2: A Wide-Ranging Cybersecurity Evaluation Suite for Large Language Models" [2024-04] [paper]
"LLMs in Web-Development: Evaluating LLM-Generated PHP code unveiling vulnerabilities and limitations" [2024-04] [paper]
"Do Neutral Prompts Produce Insecure Code? FormAI-v2 Dataset: Labelling Vulnerabilities in Code Generated by Large Language Models" [2024-04] [paper]
"Codexity: Secure AI-assisted Code Generation" [2024-05] [paper]
"Measuring Impacts of Poisoning on Model Parameters and Embeddings for Large Language Models of Code" [2024-05] [paper]
"An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection" [2024-06] [paper]
"Is Your AI-Generated Code Really Secure? Evaluating Large Language Models on Secure Code Generation with CodeSecEval" [2024-07] [paper]
"Prompting Techniques for Secure Code Generation: A Systematic Investigation" [2024-07] [paper]
"TAPI: Towards Target-Specific and Adversarial Prompt Injection against Code LLMs" [2024-07] [paper]
"MaPPing Your Model: Assessing the Impact of Adversarial Attacks on LLM-based Programming Assistants" [2024-07] [paper]
"Eliminating Backdoors in Neural Code Models via Trigger Inversion" [2024-08] [paper]
""You still have to study" -- On the Security of LLM generated code" [2024-08] [paper]
"How Well Do Large Language Models Serve as End-to-End Secure Code Producers?" [2024-08] [paper]
"While GitHub Copilot Excels at Coding, Does It Ensure Responsible Output?" [2024-08] [paper]
"PromSec: Prompt Optimization for Secure Generation of Functional Source Code with Large Language Models (LLMs)" [2024-09] [paper]
"RMCBench: Benchmarking Large Language Models' Resistance to Malicious Code" [2024-09] [paper]
"Artificial-Intelligence Generated Code Considered Harmful: A Road Map for Secure and High-Quality Code Generation" [2024-09] [paper]
"Demonstration Attack against In-Context Learning for Code Intelligence" [2024-10] [paper]
"Hallucinating AI Hijacking Attack: Large Language Models and Malicious Code Recommenders" [2024-10] [paper]
"SecCodePLT: A Unified Platform for Evaluating the Security of Code GenAI" [2024-10] [paper]
"Security of Language Models for Code: A Systematic Literature Review" [2024-10] [paper]
"RedCode: Risky Code Execution and Generation Benchmark for Code Agents" [2024-11] [paper]
"ProSec: Fortifying Code LLMs with Proactive Security Alignment" [2024-11] [paper]
"An Empirical Evaluation of GitHub Copilot's Code Suggestions" [2022-05] [MSR 2022] [paper]
"Large Language Models and Simple, Stupid Bugs" [2023-03] [MSR 2023] [paper]
"Evaluating the Code Quality of AI-Assisted Code Generation Tools: An Empirical Study on GitHub Copilot, Amazon CodeWhisperer, and ChatGPT" [2023-04] [paper]
"No Need to Lift a Finger Anymore? Assessing the Quality of Code Generation by ChatGPT" [2023-08] [paper]
"The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations?" [2024-02] [ACL 2024 Findings] [paper]
"Bugs in Large Language Models Generated Code: An Empirical Study" [2024-03] [paper]
"ChatGPT Incorrectness Detection in Software Reviews" [2024-03] [paper]
"Validating LLM-Generated Programs with Metamorphic Prompt Testing" [2024-06] [paper]
"Where Do Large Language Models Fail When Generating Code?" [2024-06] [paper]
"GitHub Copilot: the perfect Code compLeeter?" [2024-06] [paper]
"What's Wrong with Your Code Generated by Large Language Models? An Extensive Study" [2024-07] [paper]
"Uncovering Weaknesses in Neural Code Generation" [2024-07] [paper]
"Understanding Defects in Generated Codes by Language Models" [2024-08] [paper]
"CodeSift: An LLM-Based Reference-Less Framework for Automatic Code Validation" [2024-08] [paper]
"Examination of Code generated by Large Language Models" [2024-08] [paper]
"Fixing Code Generation Errors for Large Language Models" [2024-09] [paper]
"Can OpenSource beat ChatGPT? -- A Comparative Study of Large Language Models for Text-to-Code Generation" [2024-09] [paper]
"Insights from Benchmarking Frontier Language Models on Web App Code Generation" [2024-09] [paper]
"Evaluating the Performance of Large Language Models in Competitive Programming: A Multi-Year, Multi-Grade Analysis" [2024-09] [paper]
"A Case Study of Web App Coding with OpenAI Reasoning Models" [2024-09] [paper]
"CodeJudge: Evaluating Code Generation with Large Language Models" [2024-10] [paper]
"An evaluation of LLM code generation capabilities through graded exercises" [2024-10] [paper]
"A Deep Dive Into Large Language Model Code Generation Mistakes: What and Why?" [2024-11] [paper]
"Evaluating ChatGPT-3.5 Efficiency in Solving Coding Problems of Different Complexity Levels: An Empirical Analysis" [2024-11] [paper]
"LLM4DS: Evaluating Large Language Models for Data Science Code Generation" [2024-11] [paper]
"A Preliminary Study of Multilingual Code Language Models for Code Generation Task Using Translated Benchmarks" [2024-11] [paper]
"Exploring and Evaluating Hallucinations in LLM-Powered Code Generation" [2024-04] [paper]
"CodeHalu: Code Hallucinations in LLMs Driven by Execution-based Verification" [2024-04] [paper]
"We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs" [2024-06] [paper]
"Code Hallucination" [2024-07] [paper]
"On Mitigating Code LLM Hallucinations with API Documentation" [2024-07] [paper]
"CodeMirage: Hallucinations in Code Generated by Large Language Models" [2024-08] [paper]
"LLM Hallucinations in Practical Code Generation: Phenomena, Mechanism, and Mitigation" [2024-09] [paper]
"Collu-Bench: A Benchmark for Predicting Language Model Hallucinations in Code" [2024-10] [paper]
"ETF: An Entity Tracing Framework for Hallucination Detection in Code Summaries" [2024-10] [paper]
"On Evaluating the Efficiency of Source Code Generated by LLMs" [2024-04] [paper]
"A Controlled Experiment on the Energy Efficiency of the Source Code Generated by Code Llama" [2024-05] [paper]
"From Effectiveness to Efficiency: Comparative Evaluation of Code Generated by LCGMs for Bilingual Programming Questions" [2024-06] [paper]
"How Efficient is LLM-Generated Code? A Rigorous & High-Standard Benchmark" [2024-06] [paper]
"ECCO: Can We Improve Model-Generated Code Efficiency Without Sacrificing Functional Correctness?" [2024-07] [paper]
"A Performance Study of LLM-Generated Code on Leetcode" [2024-07] [paper]
"Evaluating Language Models for Efficient Code Generation" [2024-08] [paper]
"Effi-Code: Unleashing Code Efficiency in Language Models" [2024-10] [paper]
"Rethinking Code Refinement: Learning to Judge Code Efficiency" [2024-10] [paper]
"Generating Energy-efficient code with LLMs" [2024-11] [paper]
"An exploration of the effect of quantisation on energy consumption and inference time of StarCoder2" [2024-11] [paper]
"Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain" [2023-10] [paper]
"Do Large Code Models Understand Programming Concepts? A Black-box Approach" [2024-02] [ICML 2024] [paper]
"Syntactic Robustness for LLM-based Code Generation" [2024-04] [paper]
"NLPerturbator: Studying the Robustness of Code LLMs to Natural Language Variations" [2024-06] [paper]
"An Empirical Study on Capability of Large Language Models in Understanding Code Semantics" [2024-07] [paper]
"Comparing Robustness Against Adversarial Attacks in Code Generation: LLM-Generated vs. Human-Written" [2024-11] [paper]
"A Critical Study of What Code-LLMs (Do Not) Learn" [2024-06] [ACL 2024 Findings] [paper]
"Looking into Black Box Code Language Models" [2024-07] [paper]
"DeepCodeProbe: Towards Understanding What Models Trained on Code Learn" [2024-07] [paper]
"Towards More Trustworthy and Interpretable LLMs for Code through Syntax-Grounded Explanations" [2024-07] [paper]
"How and Why LLMs Use Deprecated APIs in Code Completion? An Empirical Study" [2024-06] [paper]
"Is ChatGPT a Good Software Librarian? An Exploratory Study on the Use of ChatGPT for Software Library Recommendations" [2024-08] [paper]
"A Systematic Evaluation of Large Code Models in API Suggestion: When, Which, and How" [2024-09] [paper]
"AutoAPIEval: A Framework for Automated Evaluation of LLMs in API-Oriented Code Generation" [2024-09] [paper]
"Does Your Neural Code Completion Model Use My Code? A Membership Inference Approach" [2024-04] [paper]
"CodeCipher: Learning to Obfuscate Source Code Against LLMs" [2024-10] [paper]
"Decoding Secret Memorization in Code LLMs Through Token-Level Characterization" [2024-10] [paper]
"Exploring Multi-Lingual Bias of Large Code Models in Code Generation" [2024-04] [paper]
"Mitigating Gender Bias in Code Large Language Models via Model Editing" [2024-10] [paper]
"Bias Unveiled: Investigating Social Bias in LLM-Generated Code" [2024-11] [paper]
"Zero-Shot Detection of Machine-Generated Codes" [2023-10] [paper]
"CodeIP: A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code" [2024-04] [paper]
"ChatGPT Code Detection: Techniques for Uncovering the Source of Code" [2024-05] [paper]
"Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting" [2024-05] [paper]
"Automatic Detection of LLM-generated Code: A Case Study of Claude 3 Haiku" [2024-09] [paper]
"An Empirical Study on Automatically Detecting AI-Generated Source Code: How Far Are We?" [2024-11] [paper]
"Distinguishing LLM-generated from Human-written Code by Contrastive Learning" [2024-11] [paper]
"Who Wrote this Code? Watermarking for Code Generation" [2023-05] [ACL 2024] [paper]
"Testing the Effect of Code Documentation on Large Language Model Code Understanding" [2024-04] [paper]
"Automated Creation of Source Code Variants of a Cryptographic Hash Function Implementation Using Generative Pre-Trained Transformer Models" [2024-04] [paper]
"Evaluation of the Programming Skills of Large Language Models" [2024-05] [paper]
"Where Are Large Language Models for Code Generation on GitHub?" [2024-06] [paper]
"Beyond Functional Correctness: Investigating Coding Style Inconsistencies in Large Language Models" [2024-06] [paper]
"Benchmarking Language Model Creativity: A Case Study on Code Generation" [2024-07] [paper]
"Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models" [2024-07] [paper]
"Is Functional Correctness Enough to Evaluate Code Language Models? Exploring Diversity of Generated Codes" [2024-08] [paper]
"Strategic Optimization and Challenges of Large Language Models in Object-Oriented Programming" [2024-08] [paper]
"A Survey on Evaluating Large Language Models in Code Generation Tasks" [2024-08] [paper]
"An exploratory analysis of Community-based Question-Answering Platforms and GPT-3-driven Generative AI: Is it the end of online community-based learning?" [2024-09] [paper]
"Code Generation and Algorithmic Problem Solving Using Llama 3.1 405B" [2024-09] [paper]
"Benchmarking ChatGPT, Codeium, and GitHub Copilot: A Comparative Study of AI-Driven Programming and Debugging Assistants" [2024-09] [paper]
"Model Editing for LLMs4Code: How Far are We?" [2024-11] [paper]
"An Empirical Study on LLM-based Agents for Automated Bug Fixing" [2024-11] [paper]
"Precision or Peril: Evaluating Code Quality from Quantized Large Language Models" [2024-11] [paper]
"Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models" [2022-04] [CHI EA 2022] [paper]
"Grounded Copilot: How Programmers Interact with Code-Generating Models" [2022-06] [OOPSLA 2023] [paper]
"Reading Between the Lines: Modeling User Behavior and Costs in AI-Assisted Programming" [2022-10] [paper]
"The Impact of AI on Developer Productivity: Evidence from GitHub Copilot" [2023-02] [paper]
"The Programmer's Assistant: Conversational Interaction with a Large Language Model for Software Development" [2023-02] [IUI 2023] [paper]
""It's Weird That it Knows What I Want": Usability and Interactions with Copilot for Novice Programmers" [2023-04] [ACM TCHI] [paper]
"DevGPT: Studying Developer-ChatGPT Conversations" [2023-08] [paper]
"How Do Analysts Understand and Verify AI-Assisted Data Analyses?" [2023-09] [paper]
"How Novices Use LLM-Based Code Generators to Solve CS1 Coding Tasks in a Self-Paced Learning Environment" [2023-09] [Koli Calling 2023] [paper]
"Conversational Challenges in AI-Powered Data Science: Obstacles, Needs, and Design Opportunities" [2023-10] [paper]
"The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers" [2024-04] [paper]
"Unlocking Adaptive User Experience with Generative AI" [2024-04] [paper]
"BISCUIT: Scaffolding LLM-Generated Code with Ephemeral UIs in Computational Notebooks" [2024-04] [paper]
"How far are AI-powered programming assistants from meeting developers' needs?" [2024-04] [paper]
"Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice" [2024-04] [paper]
"The GPT Surprise: Offering Large Language Model Chat in a Massive Coding Class Reduced Engagement but Increased Adopters Exam Performances" [2024-04] [paper]
"amplified.dev: a living document that begins to sketch a vision for a future where developers are amplified, not automated" [2024-05] [paper]
"Sketch Then Generate: Providing Incremental User Feedback and Guiding LLM Code Generation through Language-Oriented Code Sketches" [2024-05] [paper]
"Using AI Assistants in Software Development: A Qualitative Study on Security Practices and Concerns" [2024-05] [paper]
"Full Line Code Completion: Bringing AI to Desktop" [2024-05] [paper]
"Developers' Perceptions on the Impact of ChatGPT in Software Development: A Survey" [2024-05] [paper]
"A Transformer-Based Approach for Smart Invocation of Automatic Code Completion" [2024-05] [paper]
"A Study on Developer Behaviors for Validating and Repairing LLM-Generated Code Using Eye Tracking and IDE Actions" [2024-05] [paper]
"Analyzing Chat Protocols of Novice Programmers Solving Introductory Programming Tasks with ChatGPT" [2024-05] [paper]
"Benchmarking the Communication Competence of Code Generation for LLMs and LLM Agent" [2024-05] [paper]
"Learning Task Decomposition to Assist Humans in Competitive Programming" [2024-06] [ACL 2024] [paper]
"Impact of AI-tooling on the Engineering Workspace" [2024-06] [paper]
"Using AI-Based Coding Assistants in Practice: State of Affairs, Perceptions, and Ways Forward" [2024-06] [paper]
"Instruct, Not Assist: LLM-based Multi-Turn Planning and Hierarchical Questioning for Socratic Code Debugging" [2024-06] [paper]
"Transforming Software Development: Evaluating the Efficiency and Challenges of GitHub Copilot in Real-World Projects" [2024-06] [paper]
"Let the Code LLM Edit Itself When You Edit the Code" [2024-07] [paper]
"Enhancing Computer Programming Education with LLMs: A Study on Effective Prompt Engineering for Python Code Generation" [2024-07] [paper]
"How Novice Programmers Use and Experience ChatGPT when Solving Programming Exercises in an Introductory Course" [2024-07] [paper]
"Can Developers Prompt? A Controlled Experiment for Code Documentation Generation" [2024-08] [paper]
"The Impact of Generative AI-Powered Code Generation Tools on Software Engineer Hiring: Recruiters' Experiences, Perceptions, and Strategies" [2024-09] [paper]
"Investigating the Role of Cultural Values in Adopting Large Language Models for Software Engineering" [2024-09] [paper]
"The Impact of Large Language Models on Open-source Innovation: Evidence from GitHub Copilot" [2024-09] [paper]
""I Don't Use AI for Everything": Exploring Utility, Attitude, and Responsibility of AI-empowered Tools in Software Development" [2024-09] [paper]
"Harnessing the Potential of Gen-AI Coding Assistants in Public Sector Software Development" [2024-09] [paper]
"Understanding the Human-LLM Dynamic: A Literature Survey of LLM Use in Programming Tasks" [2024-10] [paper]
"Code-Survey: An LLM-Driven Methodology for Analyzing Large-Scale Codebases" [2024-10] [paper]
"The potential of LLM-generated reports in DevSecOps" [2024-10] [paper]
"The Impact of Generative AI on Collaborative Open-Source Software Development: Evidence from GitHub Copilot" [2024-10] [paper]
"Exploring the Design Space of Cognitive Engagement Techniques with AI-Generated Code for Enhanced Learning" [2024-10] [paper]
"One Step at a Time: Combining LLMs and Static Analysis to Generate Next-Step Hints for Programming Tasks" [2024-10] [paper]
"UniAutoML: A Human-Centered Framework for Unified Discriminative and Generative AutoML with Large Language Models" [2024-10] [paper]
"How much does AI impact development speed? An enterprise-based randomized controlled trial" [2024-10] [paper]
"Understanding the Effect of Algorithm Transparency of Model Explanations in Text-to-SQL Semantic Parsing" [2024-10] [paper]
"Dear Diary: A randomized controlled trial of Generative AI coding tools in the workplace" [2024-10] [paper]
"LLMs are Imperfect, Then What? An Empirical Study on LLM Failures in Software Engineering" [2024-11] [paper]
"Human-In-the-Loop Software Development Agents" [2024-11] [paper]
CodeSearchNet : "CodeSearchNet Challenge: Evaluating the State of Semantic Code Search" [2019-09] [paper] [repo] [data]
The Pile : "The Pile: An 800GB Dataset of Diverse Text for Language Modeling" [2020-12], [paper] [data]
CodeParrot , 2022-02, [data]
The Stack : "The Stack: 3 TB of permissively licensed source code" [2022-11] [paper] [data]
ROOTS : "The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset" [2023-03] [NeurIPS 2022 Datasets and Benchmarks Track] [paper] [data]
The Stack v2 : "StarCoder 2 and The Stack v2: The Next Generation" [2024-02] [paper] [data]
CodeXGLUE : "CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation" [2021-02] [NeurIPS Datasets and Benchmarks 2021] [paper] [repo] [data]
CodefuseEval : "CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model" [2023-10] [paper] [repo]
CodeScope : "CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation" [2023-11] [ACL 2024] [paper] [repo]
CodeEditorBench : "CodeEditorBench: Evaluating Code Editing Capability of Large Language Models" [2024-04] [paper] [repo]
Long Code Arena : "Long Code Arena: a Set of Benchmarks for Long-Context Code Models" [2024-06] [paper] [repo]
CodeRAG-Bench : "CodeRAG-Bench: Can Retrieval Augment Code Generation?" [2024-06] [paper] [repo]
LiveBench : "LiveBench: A Challenging, Contamination-Free LLM Benchmark" [2024-06] [paper] [repo]
DebugEval : "Enhancing the Code Debugging Ability of LLMs via Communicative Agent Based Data Refinement" [2024-08] [paper] [repo]
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2018-02 | LREC 2018 | NL2Bash | 9305 | 세게 때리다 | "NL2Bash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System" [paper] [data] |
| 2018-08 | EMNLP 2018 | CONCODE | 104K | 자바 | "Mapping Language to Code in Programmatic Context" [paper] [data] |
| 2019-10 | EMNLP-IJCNLP 2019 | 주스 | 1.5M/3725 * | 파이썬 | "JuICe: A Large Scale Distantly Supervised Dataset for Open Domain Context-based Code Generation" [paper] [data] |
| 2021-05 | NeurIPS 2021 | 앱 | 10000 | 파이썬 | "Measuring Coding Challenge Competence With APPS" [paper] [data] |
| 2021-07 | arxiv | HumanEval | 164 | 파이썬 | "Evaluating Large Language Models Trained on Code" [paper] [data] |
| 2021-08 | arxiv | MBPP/MathQA-Python | 974/23914 | 파이썬 | "Program Synthesis with Large Language Models" [paper] [MBPP] [MathQA-Python] |
| 2021-08 | ACL/IJCNLP 2021 | PlotCoder | 40797 | 파이썬 | "PlotCoder: Hierarchical Decoding for Synthesizing Visualization Code in Programmatic Context" [paper] [data] |
| 2022-01 | arxiv | DSP | 1119 | 파이썬 | "Training and Evaluating a Jupyter Notebook Data Science Assistant" [paper] [data] |
| 2022-02 | 과학 | CodeContests | 13610 | C++, Python, Java | "Competition-Level Code Generation with AlphaCode" [paper] [data] |
| 2022-03 | EACL 2023 Findings | MCoNaLa | 896 | 파이썬 | "MCoNaLa: A Benchmark for Code Generation from Multiple Natural Languages" [paper] [data] |
| 2022-06 | arxiv | AixBench | 336 | 자바 | "AixBench: A Code Generation Benchmark Dataset" [paper] [data] |
| 2022-08 | IEEE 트랜스. 소프트웨어 엔지니어링 | 다수의 | "MultiPL-E: A Scalable and Extensible Approach to Benchmarking Neural Code Generation", [paper] [data] | ||
| 2022-10 | ICLR 2023 | MBXP | 12.4K | Python, Java, JS, TypeScript, Go, C#, PHP, Ruby, Kotlin, C++, Perl, Scala, Swift | "Multi-lingual Evaluation of Code Generation Models" [paper] [data] |
| 2022-10 | ICLR 2023 | Multilingual HumanEval | 1.9k | Python, Java, JS, TypeScript, Go, C#, PHP, Ruby, Kotlin, Perl, Scala, Swift | "Multi-lingual Evaluation of Code Generation Models" [paper] [data] |
| 2022-10 | ICLR 2023 | MathQA-X | 5.6k | Python, Java, JS | "Multi-lingual Evaluation of Code Generation Models" [paper] [data] |
| 2022-11 | arxiv | ExeDS | 534 | 파이썬 | "Execution-based Evaluation for Data Science Code Generation Models" [paper] [data] |
| 2022-11 | arxiv | DS-1000 | 1000 | 파이썬 | "DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation" [paper] [data] |
| 2022-12 | arxiv | ODEX | 945 | 파이썬 | "Execution-Based Evaluation for Open-Domain Code Generation" [paper] [data] |
| 2023-02 | arxiv | CoderEval | 460 | Python, Java | "CoderEval: A Benchmark of Pragmatic Code Generation with Generative Pre-trained Models" [paper] [data] |
| 2023-03 | ACL 2024 | xCodeEval | 5.5M | C, C#, C++, Go, Java, JS, Kotlin, PHP, Python, Ruby, Rust | "XCodeEval: An Execution-based Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval" [paper] [data] |
| 2023-03 | arxiv | HumanEval-X | 820 | Python, C++, Java, JS, Go | "CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X" [paper] [data] |
| 2023-05 | arxiv | HumanEval+ | 164 | 파이썬 | "Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation" [paper] [data] |
| 2023-06 | ACL 2024 Findings | StudentEval | 1749 | 파이썬 | "StudentEval: A Benchmark of Student-Written Prompts for Large Language Models of Code" [paper] [data] |
| 2023-08 | ICLR 2024 Spotlight | HumanEvalPack | 984 | Python, JS, Go, Java, C++, Rust | "OctoPack: Instruction Tuning Code Large Language Models" [paper] [data] |
| 2023-06 | NeurIPS 2023 | DotPrompts | 10538 | 자바 | "Guiding Language Models of Code with Global Context using Monitors" [paper] [data] |
| 2023-09 | arxiv | CodeApex | 476 | C ++ | "CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models" [paper] [data] |
| 2023-09 | arxiv | VerilogEval | 8645/156 | Verilog | "VerilogEval: Evaluating Large Language Models for Verilog Code Generation" [paper] [data] |
| 2023-11 | arxiv | ML-Bench | 10040 | 세게 때리다 | "ML-Bench: Large Language Models Leverage Open-source Libraries for Machine Learning Tasks" [paper] [data] |
| 2023-12 | arxiv | TACO | 26,433 | 파이썬 | "TACO: Topics in Algorithmic COde generation dataset" [paper] [data] |
| 2024-01 | HPDC | ParEval | 420 | C++, CUDA, HIP | "Can Large Language Models Write Parallel Code?" [paper] [data] |
| 2024-02 | ACL 2024 Findings | OOP | 431 | 파이썬 | "OOP: Object-Oriented Programming Evaluation Benchmark for Large Language Models" [paper] [data] |
| 2024-02 | LREC-COLING 2024 | HumanEval-XL | 22080 | 23NL, 12PL | "HumanEval-XL: A Multilingual Code Generation Benchmark for Cross-lingual Natural Language Generalization" [paper] [data] |
| 2024-04 | arxiv | USACO | 307 | 파이썬 | "Can Language Models Solve Olympiad Programming?" [paper] [data] |
| 2024-04 | LREC-COLING 2024 | PECC | 2396 | 파이썬 | "PECC: Problem Extraction and Coding Challenges" [paper] [data] |
| 2024-04 | arxiv | CodeGuard+ | 23 | Python, C | "Constrained Decoding for Secure Code Generation" [paper] [data] |
| 2024-05 | ACL 2024 Findings | NaturalCodeBench | 402 | Python, Java | "NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Prompts" [paper] [data] |
| 2024-05 | arxiv | MHPP | 140 | 파이썬 | "MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation" [paper] [repo] |
| 2024-06 | arxiv | VHDL-Eval | 202 | VHDL | "VHDL-Eval: A Framework for Evaluating Large Language Models in VHDL Code Generation" [paper] |
| 2024-06 | arxiv | AICoderEval | 492 | 파이썬 | "AICoderEval: Improving AI Domain Code Generation of Large Language Models" [paper] [data] |
| 2024-06 | arxiv | VersiCode | 98,692 | 파이썬 | "VersiCode: Towards Version-controllable Code Generation" [paper] [data] |
| 2024-06 | IEEE AITest 2024 | ScenEval | 12,864 | 자바 | "ScenEval: A Benchmark for Scenario-Based Evaluation of Code Generation" [paper] |
| 2024-06 | arxiv | BigCodeBench | 1,140 | 파이썬 | "BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions" [paper] [data] |
| 2024-07 | arxiv | CodeUpdateArena | 670 | 파이썬 | "CodeUpdateArena: Benchmarking Knowledge Editing on API Updates" [paper] [data] |
| 2024-07 | arxiv | LBPP | 161 | 파이썬 | "On Leakage of Code Generation Evaluation Datasets" [paper] [data] |
| 2024-07 | arxiv | NoviCode | 150 | 파이썬 | "NoviCode: Generating Programs from Natural Language Utterances by Novices" [paper] [data] |
| 2024-07 | arxiv | Case2Code | 1.3m | 파이썬 | "Case2Code: Learning Inductive Reasoning with Synthetic Data" [paper] [data] |
| 2024-07 | arxiv | Scicode | 338 | 파이썬 | "SciCode: A Research Coding Benchmark Curated by Scientists" [paper] [data] |
| 2024-07 | arxiv | auto-regression | 460 | 파이썬 | "Generating Unseen Code Tests In Infinitum" [paper] |
| 2024-07 | arxiv | WebApp1K | 1000 | 자바 스크립트 | "WebApp1K: A Practical Code-Generation Benchmark for Web App Development" [paper] [data] |
| 2024-08 | ACL 2024 Findings | CodeInsight | 3409 | 파이썬 | "CodeInsight: A Curated Dataset of Practical Coding Solutions from Stack Overflow" [paper] [data] |
| 2024-08 | arxiv | DomainEval | 2454 | 파이썬 | "DOMAINEVAL: An Auto-Constructed Benchmark for Multi-Domain Code Generation" [paper] [data] |
| 2024-09 | arxiv | ComplexCodeEval | 7184/3897 | Python/Java | "ComplexCodeEval: A Benchmark for Evaluating Large Code Models on More Complex Code" [paper] [data] |
| 2024-09 | ASE 2024 | CoCoNote | 58221 | Python Notebook | "Contextualized Data-Wrangling Code Generation in Computational Notebooks" [paper] [data] |
| 2024-10 | arxiv | 이름이 없습니다 | 77 | 파이썬 | "Evaluation of Code LLMs on Geospatial Code Generation" [paper] [data] |
| 2024-10 | arxiv | mHumanEval | 836,400 | 25PL, 204NL | "mHumanEval -- A Multilingual Benchmark to Evaluate Large Language Models for Code Generation" [paper] [data] |
| 2024-10 | arxiv | FeatEng | 103 | 파이썬 | "Can Models Help Us Create Better Models? Evaluating LLMs as Data Scientists" [paper] [data] |
| 2024-11 | arxiv | GitChameleon | 116 | 파이썬 | "GitChameleon: Unmasking the Version-Switching Capabilities of Code Generation Models" [paper] [data] |
* Automatically mined/human-annotated
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2024-04 | arxiv | MMCode | 3548 | 파이썬 | "MMCode: Evaluating Multi-Modal Code Large Language Models with Visually Rich Programming Problems" [paper] [data] |
| 2024-05 | arxiv | Plot2Code | 132 | 파이썬 | "Plot2Code: A Comprehensive Benchmark for Evaluating Multi-modal Large Language Models in Code Generation from Scientific Plots" [paper] [data] |
| 2024-06 | arxiv | ChartMimic | 1000 | 파이썬 | "ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation" [paper] [data] |
| 2024-10 | arxiv | HumanEval-V | 108 | 파이썬 | "HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks" [paper] [data] |
| 2024-10 | arxiv | TurtleBench | 260 | 파이썬 | "TurtleBench: A Visual Programming Benchmark in Turtle Geometry" [paper] [data] |
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2021-09 | EMNLP 2021 Findings | CodeQA | 120K/70K | Java/Python | "CodeQA: A Question Answering Dataset for Source Code Comprehension" [paper] [data] |
| 2022-10 | NAACL 2022 | CS1QA | 9237 | 파이썬 | "CS1QA: A Dataset for Assisting Code-based Question Answering in an Introductory Programming Course" [paper] [data] |
| 2023-09 | arxiv | CodeApex | 250 | C ++ | "CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models" [paper] [data] |
| 2024-01 | ICML 2024 | CRUXEval | 800 | 파이썬 | "CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution" [paper] [data] |
| 2024-05 | arxiv | PythonIO | 2650 | 파이썬 | "Multiple-Choice Questions are Efficient and Robust LLM Evaluators" [paper] [data] |
| 2024-05 | arxiv | StaCCQA | 270K | 파이썬 | "Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering" [paper] [data] |
| 2024-06 | arxiv | RepoQA | 500 | Python, C++, Java, Rust, TypeScript | "RepoQA: Evaluating Long Context Code Understanding" [paper] [data] |
| 2024-08 | arxiv | CruxEval-X | 12.6K | 19 | "CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution" [paper] [data] |
| 2024-09 | arxiv | SpecEval | 204 | 자바 | "SpecEval: Evaluating Code Comprehension in Large Language Models via Program Specifications" [paper] [data] |
| 2024-10 | arxiv | CodeMMLU | 19912 | 13 | "CodeMMLU: A Multi-Task Benchmark for Assessing Code Understanding Capabilities of CodeLLMs" [paper] [data] |
| 2024-11 | arxiv | 이름이 없습니다 | 80232 | 파이썬 | "Leveraging Large Language Models in Code Question Answering: Baselines and Issues" [paper] [data] |
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2017-08 | arxiv | WikiSQL | 80654 | "Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning" [paper] [data] | |
| 2018-06 | CL 2018 | 조언 | 4570 | "Improving Text-to-SQL Evaluation Methodology" [paper] [data] | |
| 2018-09 | EMNLP 2018 | 거미 | 10181 | "Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task" [paper] [data] | |
| 2019-06 | ACL 2019 | SParC | 12726 | "SParC: Cross-Domain Semantic Parsing in Context" [paper] [data] | |
| 2019-07 | WWW 2020 | MIMICSQL | 10000 | "Text-to-SQL Generation for Question Answering on Electronic Medical Records" [paper] [data] | |
| 2019-09 | EMNLP-IJCNLP 2019 | CoSQL | 15598 | "CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases" [paper] [data] | |
| 2020-05 | LREC 2020 | Criteria-to-SQL | 2003 | "Dataset and Enhanced Model for Eligibility Criteria-to-SQL Semantic Parsing" [paper] [data] | |
| 2020-10 | EMNLP 2020 Findings | 돌풍 | 11276 | "On the Potential of Lexico-logical Alignments for Semantic Parsing to SQL Queries" [paper] [data] | |
| 2020-10 | NAACL-HLT 2021 | Spider-Realistic | 508 | "Structure-Grounded Pretraining for Text-to-SQL" [paper] [data] | |
| 2021-06 | ACL/IJCNLP 2021 | Spider-Syn | 8034 | "Towards Robustness of Text-to-SQL Models against Synonym Substitution" [paper] [data] | |
| 2021-06 | NLP4Prog 2021 | SEDE | 12023 | "Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data" [paper] [data] | |
| 2021-06 | ACL/IJCNLP 2021 | KaggleDBQA | 400 | "KaggleDBQA: Realistic Evaluation of Text-to-SQL Parsers" [paper] [data] | |
| 2021-09 | EMNLP | Spider-DK | 535 | "Exploring Underexplored Limitations of Cross-Domain Text-to-SQL Generalization" [paper] [data] | |
| 2022-05 | NAACL 2022 Findings | Spider-SS/CG | 8034/45599 | "Measuring and Improving Compositional Generalization in Text-to-SQL via Component Alignment" [paper] [data] | |
| 2023-05 | arxiv | 새 | 12751 | "Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs" [paper] [data] | |
| 2023-06 | ACL 2023 | XSemPLR | 24.4K | "XSemPLR: Cross-Lingual Semantic Parsing in Multiple Natural Languages and Meaning Representations" [paper] [data] | |
| 2024-05 | ACL 2024 Findings | EHR-SeqSQL | 31669 | "EHR-SeqSQL : A Sequential Text-to-SQL Dataset For Interactively Exploring Electronic Health Records" [paper] | |
| 2024-06 | NAACL 2024 | BookSQL | 100k | "BookSQL: A Large Scale Text-to-SQL Dataset for Accounting Domain" [paper] [data] | |
| 2024-08 | ACL 2024 Findings | MultiSQL | 9257 | "MultiSQL: A Schema-Integrated Context-Dependent Text2SQL Dataset with Diverse SQL Operations" [paper] [data] | |
| 2024-09 | arxiv | 비버 | 93 | "BEAVER: An Enterprise Benchmark for Text-to-SQL" [paper] | |
| 2024-10 | arxiv | PRACTIQ | 2812 | "PRACTIQ: A Practical Conversational Text-to-SQL dataset with Ambiguous and Unanswerable Queries" [paper] | |
| 2024-10 | arxiv | 두번 | 239 | "BIS: NL2SQL Service Evaluation Benchmark for Business Intelligence Scenarios" [paper] [data] | |
| 2024-11 | arxiv | Spider 2.0 | 632 | "Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows" [paper] [data] |
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2020-06 | NeurIPS 2020 | Transcoder GeeksforGeeks | 1.4K | C++, Java, Python | "Unsupervised Translation of Programming Languages" [paper] [data] |
| 2021-02 | NeurIPS Datasets and Benchmarks 2021 | CodeTrans | 11.8K | Java, C# | "CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation" [paper] [data] |
| 2021-08 | ACL 2023 Findings | 화신 | 9515 | Java, Python | "AVATAR: A Parallel Corpus for Java-Python Program Translation" [paper] [data] |
| 2022-06 | AAAI 2022 | 비용 | 132k | C++, Java, Python, C#, JS, PHP, C | "Multilingual Code Snippets Training for Program Translation" [paper] [data] |
| 2022-06 | arxiv | XLCoST | 567K | C++, Java, Python, C#, JS, PHP, C | "XLCoST: A Benchmark Dataset for Cross-lingual Code Intelligence" [paper] [data] |
| 2023-03 | arxiv | xCodeEval | 5.6M | C, C#, C++, Go, Java, JS, Kotlin, PHP, Python, Ruby, Rust | "xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval" [paper] [data] |
| 2023-03 | arxiv | HumanEval-X | 1640 | Python, C++, Java, JS, Go | "CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X" [paper] [data] |
| 2023-08 | arxiv | G-TransEval | 4000 | C++, Java, C#, JS, Python | "On the Evaluation of Neural Code Translation: Taxonomy and Benchmark" [paper] [data] |
| 2023-10 | arxiv | CodeTransOcean | 270.5K | 45 | "CodeTransOcean: A Comprehensive Multilingual Benchmark for Code Translation" [paper] [data] |
| 2024-11 | arxiv | Classeval-T | 94 | Python, Java, C++ | "Escalating LLM-based Code Translation Benchmarking into the Class-level Era" [paper] |
| 2024-11 | arxiv | RustRepoTrans | 375 | C++, Java, Python, Rust | "Repository-level Code Translation Benchmark Targeting Rust" [paper] [data] |
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2014-07 | ISSTA 2014 | Defects4J | 357 | 자바 | "Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs" [paper] [data] |
| 2015-12 | IEEE 트랜스. 소프트웨어 엔지니어링 | ManyBugs/IntroClass | 185/998 | 기음 | "The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs" [paper] [data] |
| 2016-11 | FSE 2016 | BugAID | 105k | JS | "Discovering Bug Patterns in JavaScript" [paper] [data] |
| 2017-02 | AAAI 2017 | DeepFix | 6971 | 기음 | "DeepFix: Fixing Common C Language Errors by Deep Learning" [paper] [data] |
| 2017-05 | ICSE-C 2017 | Codeflaws | 3902 | 기음 | "DeepFix: Fixing Common C Language Errors by Deep Learning" [paper] [data] |
| 2017-10 | SPLASH 2017 | QuixBugs | 80 | Java, Python | "QuixBugs: a multi-lingual program repair benchmark set based on the quixey challenge" [paper] [data] |
| 2018-05 | MSR 2018 | Bugs.jar | 1158 | 자바 | "Bugs.jar: a large-scale, diverse dataset of real-world Java bugs" [paper] [data] |
| 2018-12 | ACM Trans. Softw. 잉그 Methodol. | BFP | 124K | 자바 | "An Empirical Study on Learning Bug-Fixing Patches in the Wild via Neural Machine Translation" [paper] [data] |
| 2019-01 | SANER 2019 | 곰 | 251 | 자바 | "Bears: An Extensible Java Bug Benchmark for Automatic Program Repair Studies" [paper] [data] |
| 2019-01 | ICSE 2019 | 이름이 없습니다 | 21.8K * | 자바 | "On Learning Meaningful Code Changes via Neural Machine Translation" [paper] [data] |
| 2019-04 | ICST 2019 | BugsJS | 453 | JS | "BugsJS: a Benchmark of JavaScript Bugs" [paper] [data] |
| 2019-05 | ICSE 2019 | BugSwarm | 1827/1264 | Java/Python | "BugSwarm: mining and continuously growing a dataset of reproducible failures and fixes" [paper] [data] |
| 2019-05 | ICSE 2019 | CPatMiner | 17K * | 자바 | "Graph-based mining of in-the-wild, fine-grained, semantic code change patterns" [paper] [data] |
| 2019-05 | MSR 2020 | ManySStuBs4J | 154K | 자바 | "How Often Do Single-Statement Bugs Occur? The ManySStuBs4J Dataset" [paper] [data] |
| 2019-11 | ASE 2019 | Refactory | 1783 | 파이썬 | "Re-factoring based program repair applied to programming assignments" [paper] [data] |
| 2020-07 | ISSTA 2020 | 코코넛 | 24m | Java, Python, C, JS | "CoCoNuT: combining context-aware neural translation models using ensemble for program repair" [paper] [data] |
| 2020-10 | inf. Softw. 테크놀로. | Review4Repair | 58021 | 자바 | "Review4Repair: Code Review Aided Automatic Program Repairing" [paper] [data] |
| 2020-11 | ESEC/FSE 2020 | BugsInPy | 493 | 파이썬 | "BugsInPy: A Database of Existing Bugs in Python Programs to Enable Controlled Testing and Debugging Studies" [paper] [data] |
| 2021-07 | ICML 2021 | TFix | 105k | JS | "TFix: Learning to Fix Coding Errors with a Text-to-Text Transformer" [paper] [data] |
| 2021-08 | arxiv | Megadiff | 663K * | 자바 | "Megadiff: A Dataset of 600k Java Source Code Changes Categorized by Diff Size" [paper] [data] |
| 2022-01 | SSB/TSSB | MSR 2022 | 9M/3M | 파이썬 | "TSSB-3M: Mining single statement bugs at massive scale" [paper] [data] |
| 2022-10 | MSR 2022 | FixJS | 324K | JS | "FixJS: a dataset of bug-fixing JavaScript commits" [paper] [data] |
| 2022-11 | ESEC/FSE 2022 | TypeBugs | 93 | 파이썬 | "PyTER: Effective Program Repair for Python Type Errors" [paper] [data] |
| 2023-03 | arxiv | xCodeEval | 4.7M | C, C#, C++, Go, Java, JS, Kotlin, PHP, Python, Ruby, Rust | "xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval" [paper] [data] |
| 2023-04 | arxiv | RunBugRun | 450K | C, C++, Java, Python, JS, Ruby, Go, PHP | "RunBugRun -- An Executable Dataset for Automated Program Repair" [paper] [data] |
| 2023-08 | arxiv | HumanEvalPack | 984 | Python, JS, Go, Java, C++, Rust | "OctoPack: Instruction Tuning Code Large Language Models" [paper] [data] |
| 2024-01 | arxiv | DebugBench | 4253 | C++, Java, Python | "DebugBench: Evaluating Debugging Capability of Large Language Models" [paper] [data] |
| 2024-11 | arxiv | MdEval | 3513 | 18 | "MdEval: Massively Multilingual Code Debugging" [paper] |
* These are code-change datasest, and only a subset therein concerns bug fixing.
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2016-08 | ACL 2016 | CODE-NN | 66K/32K | C#/SQL | "Summarizing Source Code using a Neural Attention Model" [paper] [data] |
| 2017-07 | IJCNLP 2017 | 이름이 없습니다 | 150K | 파이썬 | "A parallel corpus of Python functions and documentation strings for automated code documentation and code generation" [paper] [data] |
| 2018-05 | ICPC 2018 | DeepCom | 588K | 자바 | "Deep code comment generation" [paper] [data] |
| 2018-07 | IJCAI 2018 | TL-CodeSum | 411k | 자바 | "Summarizing Source Code with Transferred API Knowledge" [paper] [data] |
| 2018-11 | ASE 2018 | 이름이 없습니다 | 109K | 파이썬 | "Improving Automatic Source Code Summarization via Deep Reinforcement Learning" [paper] [data] |
| 2019-09 | arxiv | CodeSearchNet | 2.3m | Go, JS, Python, PHP, Java, Ruby | "CodeSearchNet Challenge: Evaluating the State of Semantic Code Search" [paper] [data] |
| 2023-08 | arxiv | HumanEvalPack | 984 | Python, JS, Go, Java, C++, Rust | "OctoPack: Instruction Tuning Code Large Language Models" [paper] [data] |
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2018-01 | NDSS 2018 | CGD | 62k | C, C++ | "VulDeePecker: A Deep Learning-Based System for Vulnerability Detection" [paper] [data] |
| 2018-04 | IEEE 트랜스. Ind. Informatics | 이름이 없습니다 | 32988 | C, C++ | "Cross-Project Transfer Representation Learning for Vulnerable Function Discovery" [paper] [data] |
| 2018-07 | ICMLA 2018 | Draper VDISC | 12.8M | C, C++ | "Automated Vulnerability Detection in Source Code Using Deep Representation Learning" [paper] [data] |
| 2018-07 | IEEE TDSC | SySeVR | 15591 | C, C++ | "SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities" [paper] [data] |
| 2019-02 | MSR 2019 | 이름이 없습니다 | 624 | 자바 | "A Manually-Curated Dataset of Fixes to Vulnerabilities of Open-Source Software" [paper] [data] |
| 2019-09 | NeurIPS 2019 | Devign | 49K | 기음 | "Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks" [paper] [data] |
| 2019-11 | IEEE TDSC | 이름이 없습니다 | 170K | C, C++ | "Software Vulnerability Discovery via Learning Multi-Domain Knowledge Bases" [paper] [data] |
| 2019-12 | ICLR 2020 | 엄청난 | 2.8m | 파이썬 | "Global Relational Models of Source Code" [paper] [data] |
| 2020-01 | IEEE TDSC | MVD | 182k | C, C++ | "μVulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection" [paper] [data] |
| 2020-02 | ICICS 2019 | 이름이 없습니다 | 1471 | 기음 | "Deep Learning-Based Vulnerable Function Detection: A Benchmark" [paper] [data] |
| 2020-09 | IEEE 트랜스. Software Eng. | 드러내다 | 18K | 기음 | "Deep Learning based Vulnerability Detection: Are We There Yet?" [paper] [data] |
| 2020-09 | MSR 2020 | Big-Vul | 265K | C, C++ | "AC/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries" [paper] [data] |
| 2021-02 | ICSE (SEIP) 2021 | D2A | 1.3m | C, C++ | "D2A: A Dataset Built for AI-Based Vulnerability Detection Methods Using Differential Analysis" [paper] [data] |
| 2021-05 | NeurIPS 2021 | PyPIBugs | 2374 | 파이썬 | "Self-Supervised Bug Detection and Repair" [paper] [data] |
| 2021-07 | In PROMISE 2021 | CVEfixes | 5495 | 27 | "CVEfixes: Automated Collection of Vulnerabilities and Their Fixes from Open-Source Software" [paper] [data] |
| 2021-08 | ESEC/FSE 2021 | CrossVul | 27476 | 40+ | "CrossVul: a cross-language vulnerability dataset with commit data" [paper] [data] |
| 2023-04 | RAID 2023 | DiverseVul | 349K | C, C++ | "DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection" [paper] [data] |
| 2023-06 | arxiv | VulnPatchPairs | 26K | 기음 | "Limits of Machine Learning for Automatic Vulnerability Detection" [paper] [data] |
| 2023-11 | arxiv | VulBench | 455 | 기음 | "How Far Have We Gone in Vulnerability Detection Using Large Language Models" [paper] [data] |
| 2024-03 | arxiv | PrimeVul | 236K | C/C ++ | "Vulnerability Detection with Code Language Models: How Far Are We?" [종이] |
| 2024-06 | arxiv | VulDetectBench | 1000 | C/C ++ | "VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models" [paper] [data] |
| 2024-08 | arxiv | CodeJudge-Eval | 1860 | 파이썬 | "CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?" [paper] [data] |
| 2024-11 | arxiv | CleanVul | 11632 | Java, Python, JS, C#, C/C++ | "CleanVul: Automatic Function-Level Vulnerability Detection in Code Commits Using LLM Heuristics" [paper] [data] |
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2018-03 | WWW 2018 | StaQC | 148K/120K | Python/SQL | "StaQC: A Systematically Mined Question-Code Dataset from Stack Overflow" [paper] [data] |
| 2018-05 | ICSE 2018 | DeepCS | 16.2M | 자바 | "Deep Code Search" [paper] [data] |
| 2018-05 | MSR 2018 | CoNaLa | 600K/2.9K | 파이썬 | "Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow" [paper] [data] |
| 2019-08 | arxiv | 이름이 없습니다 | 287 | 자바 | "Neural Code Search Evaluation Dataset" [paper] [data] |
| 2019-09 | arxiv | CodeSearchNet | 2.3M/99 | Go, PHP, JS, Python, Java, Ruby | "CodeSearchNet Challenge: Evaluating the State of Semantic Code Search" [paper] [data] |
| 2020-02 | SANER 2020 | CosBench | 52 | 자바 | "Are the Code Snippets What We Are Searching for? A Benchmark and an Empirical Study on Code Search with Natural-Language Queries" [paper] [data] |
| 2020-08 | arxiv | SO-DS | 2.2k | 파이썬 | "Neural Code Search Revisited: Enhancing Code Snippet Retrieval through Natural Language Intent" [paper] [data] |
| 2020-10 | ACM Trans. Knowl. Discov. 데이터 | FB-Java | 249K | 자바 | "Deep Graph Matching and Searching for Semantic Code Retrieval" [paper] [data] |
| 2021-02 | NeurIPS Datasets and Benchmarks 2021 | AdvTest/WebQueryTest | 280K/1K | 파이썬 | "CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation" [paper] [[data]] |
| 2021-05 | ACL/IJCNLP 2021 | CoSQA | 21K | 파이썬 | "CoSQA: 20,000+ Web Queries for Code Search and Question Answering" [paper] [data] |
| 2024-03 | arxiv | ProCQA | 5.2m | C, C++, Java, Python, Ruby, Lisp, JS, C#, Go, Rust, PHP | "ProCQA: A Large-scale Community-based Programming Question Answering Dataset for Code Search" [paper] [data] |
| 2024-06 | arxiv | CoSQA+ | 109K | 파이썬 | "CoSQA+: Enhancing Code Search Dataset with Matching Code" [paper] [data] |
| 2024-07 | arxiv | CoIR | ~2M | 14 | "CoIR: A Comprehensive Benchmark for Code Information Retrieval Models" [paper] [data] |
| 2024-08 | arxiv | SeqCoBench | 14.5k | 파이썬 | "What can Large Language Models Capture about Code Functional Equivalence?" [종이] |
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2019-12 | ESEC/FSE 2020 | TypeWriter OSS | 208K | 파이썬 | "TypeWriter: Neural Type Prediction with Search-based Validation" [paper] [data] |
| 2020-04 | PLDI 2020 | Typilus | 252K | 파이썬 | "Typilus: Neural Type Hints" [paper] [data] |
| 2020-04 | ICLR 2020 | LambdaNet | 300 * | TypeScript | "LambdaNet: Probabilistic Type Inference using Graph Neural Networks" [paper] [data] |
| 2021-04 | MSR 2021 | ManyTypes4Py | 869K | 파이썬 | "ManyTypes4Py: A Benchmark Python Dataset for Machine Learning-based Type Inference" [paper] [data] |
| 2022-10 | MSR 2022 | ManyTypes4TypeScript | 9.1M | TypeScript | "ManyTypes4TypeScript: a comprehensive TypeScript dataset for sequence-based type inference" [paper] [data] |
| 2023-02 | ECOOP 2023 | TypeWeaver | 513 * | TypeScript | "Do Machine Learning Models Produce TypeScript Types That Type Check?" [paper] [data] |
| 2023-03 | ICLR 2023 | BetterTypes4Py/InferTypes4Py | 608K/4.6K | 파이썬 | "TypeT5: Seq2seq Type Inference using Static Analysis" [paper] [data] |
| 2023-05 | arxiv | OpenTau | 744 * | TypeScript | "Type Prediction With Program Decomposition and Fill-in-the-Type Training" [paper] [data] |
* These are project counts.
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2017-03 | ICPC 2017 | 이름이 없습니다 | 509K | 자바 | "Towards Automatic Generation of Short Summaries of Commits" [paper] [data] |
| 2017-04 | ACL 2017 | CommitGen | 153K | Python, JS, C++, Java | "A Neural Architecture for Generating Natural Language Descriptions from Source Code Changes" [paper] [data] |
| 2017-08 | ASE 2017 | CommitGen | 32K/75K * | 자바 | "Automatically Generating Commit Messages from Diffs using Neural Machine Translation" [paper] [data] |
| 2018-09 | ASE 2018 | NNGen | 27K | 자바 | "Neural-machine-translation-based commit message generation: how far are we?" [paper] [data] |
| 2019-05 | MSR 2019 | PtrGNCMsg | 64.9K | 자바 | "Generating commit messages from diffs using pointer-generator network" [paper] [[data(https://zenodo.org/records/2593787)]] |
| 2019-08 | IJCAI 2019 | CoDiSum | 90.7k | 자바 | "Commit message generation for source code changes" [paper] [data] |
| 2019-12 | IEEE 트랜스. Software Eng. | 원자 | 160K | 자바 | "ATOM: Commit Message Generation Based on Abstract Syntax Tree and Hybrid Ranking" [paper] [data] |
| 2021-05 | arxiv | CommitBERT | 346K | Python, PHP, Go, Java, JS, Ruby | "CommitBERT: Commit Message Generation Using Pre-Trained Programming Language Model" [paper] [data] |
| 2021-07 | ICSME 2021 | MCMD | 2.25m | Java, C#, C++, Python, JS | "On the Evaluation of Commit Message Generation Models: An Experimental Study" [paper] [data] |
| 2021-07 | ACM Trans. Softw. 잉그 Methodol. | CoRec | 107k | 자바 | "Context-aware Retrieval-based Deep Commit Message Generation" [paper] [data] |
| 2023-07 | ASE 2023 | ExGroFi | 19263 | 자바 | "Delving into Commit-Issue Correlation to Enhance Commit Message Generation Models" [paper] [data] |
| 2023-08 | ASE 2023 | CommitChronicle | 10.7M | 20 | "From Commit Message Generation to History-Aware Commit Message Completion" [paper] [data] |
* with/without verb-direct object filter
| 날짜 | 장소 | 기준 | 크기 | 언어 | 원천 |
|---|---|---|---|---|---|
| 2023-03 | arxiv | RepoEval | 1600/1600/373 * | 파이썬 | "RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation" [paper] [data] |
| 2023-06 | ICLR 2024 | RepoBench | 890K/9M/43K | Python, Java | "RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems" [paper] [data] |
| 2023-06 | NeurIPS 2023 | PragmaticCode | 880 ** | 자바 | "Guiding Language Models of Code with Global Context using Monitors" [paper] [data] |
| 2023-06 | arxiv | Stack-Repo | 816K | 자바 | "RepoFusion: Training Code Models to Understand Your Repository" [paper] [data] |
| 2023-09 | ISMB 2024 | BioCoder | 2269/460/460 | Python, Java | "BioCoder: A Benchmark for Bioinformatics Code Generation with Large Language Models" [paper] [data] |
| 2023-09 | arxiv | CodePlan | 645/21 | C#/Python | "CodePlan: Repository-level Coding using LLMs and Planning" [paper] [data] |
| 2023-10 | arxiv | SWE-Bench | 2294 | 파이썬 | "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" [paper] [data] |
| 2023-10 | arxiv | CrossCodeEval | 9928 | Python, Java, TypeScript, C# | "CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion" [paper] [data] |
| 2024-03 | arxiv | EvoCodeBench | 275 | 파이썬 | "EvoCodeBench: An Evolving Code Generation Benchmark Aligned with Real-World Code Repositories" [paper] [data] |
| 2024-05 | ACL 2024 Findings | DevEval | 1874 | 파이썬 | "DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories" [paper] [data] |
| 2024-06 | arxiv | JavaBench | 389 | 자바 | "Can AI Beat Undergraduates in Entry-level Java Assignments? Benchmarking Large Language Models on JavaBench" [paper] [data] |
| 2024-06 | arxiv | HumanEvo | 200/200 | Python/Java | "Towards more realistic evaluation of LLM-based code generation: an experimental study and beyond" [paper] [data] |
| 2024-06 | arxiv | RepoExec | 355 | 파이썬 | "REPOEXEC: Evaluate Code Generation with a Repository-Level Executable Benchmark" [paper] |
| 2024-06 | arxiv | RES-Q | 100 | Python, JavaScript | "RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale" [paper] [data] |
| 2024-08 | arxiv | SWE-bench-java | 91 | 자바 | "SWE-bench-java: A GitHub Issue Resolving Benchmark for Java" [paper] [data] |
| 2024-10 | arxiv | Codev-Bench | 296 | 파이썬 | "Codev-Bench: How Do LLMs Understand Developer-Centric Code Completion?" [paper] [data] |
| 2024-10 | arxiv | SWE-bench M | 617 | 자바 스크립트 | "SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?" [paper] [data] |
| 2024-10 | arxiv | SWE-Bench+ | 548 | 파이썬 | "SWE-Bench+: Enhanced Coding Benchmark for LLMs" [paper] [data] |
| 2024-10 | arxiv | DA-Code | 500 | Python, Bash, SQL | "DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models" [paper] [data] |
| 2024-10 | arxiv | RepoCod | 980 | 파이썬 | "Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'" [paper] |
| 2024-10 | arxiv | M2rc-Eval | 5993 repos | 18 | "M2rc-Eval: Massively Multilingual Repository-level Code Completion Evaluation" [paper] [data] |
*Line Completion/API Invocation Completion/Function Completion
** File count
30 papers as a primer on LLM.
| 날짜 | 예어 | 종이 | tl; dr |
|---|---|---|---|
| 2014-09 | 주목 | Neural Machine Translation by Jointly Learning to Align and Translate | The original attention, proposed for encoder-decoder RNN |
| 2015-08 | BPE | Neural Machine Translation of Rare Words with Subword Units | Byte-pair encoding: split rare words into subword units |
| 2017-06 | 변신 로봇 | Attention Is All You Need | Replace LSTM with self-attention for long-range dependency and parallel training |
| 2017-10 | Mixed Precision Training | Mixed Precision Training | Store model weights in fp16 to save memory |
| 2018-04 | 아교 | GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding | A language understanding benchmark |
| 2018-06 | gpt | Improving Language Understanding by Generative Pre-Training | Pretraining-finetuning paradigm applied to Transformer decoder |
| 2018-10 | 버트 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | Masked Language Modeling (MLM) applied to Transformer encoder for pretraining |
| 2019-02 | GPT-2 | Language Models are Unsupervised Multitask Learners | GPT made larger (1.5B). They found language models implicitly learn about downstream tasks (such as translation) during pretraining. |
| 2019-05 | SuperGLUE | SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems | Another language understanding benchmark |
| 2019-07 | 로베르타 | RoBERTa: A Robustly Optimized BERT Pretraining Approach | An optimized BERT |
| 2019-09 | Megatron-LM | Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism | Model parallelism |
| 2019-10 | 영 | ZeRO: Memory Optimizations Toward Training Trillion Parameter Models | Memory-efficient distributed optimization |
| 2019-10 | T5 | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | Transformer encoder-decoder pretrained with an MLM-like denoising objective |
| 2020-05 | GPT-3 | Language Models are Few-Shot Learners | By training an even larger version of GPT-2 (175B), they discovered a new learning paradigm: In-Context Learning (ICL) |
| 2020-09 | MMLU | Measuring Massive Multitask Language Understanding | A world-knowledge and complex reasoning benchmark |
| 2020-12 | 말뚝 | The Pile: An 800GB Dataset of Diverse Text for Language Modeling | A diverse pretraining dataset |
| 2021-06 | 로라 | LORA : 대형 언어 모델의 낮은 순위 적응 | Memory-efficient finetuning |
| 2021-09 | 플랜 | Finetuned Language Models Are Zero-Shot Learners | Instruction-finetuning |
| 2021-10 | T0 | Multitask Prompted Training Enables Zero-Shot Task Generalization | Also instruction finetuning, but applied to the much smaller T5 |
| 2021-12 | 부지런한 사람 | Scaling Language Models: Methods, Analysis & Insights from Training Gopher | A 280B LLM with comprehensive experiments |
| 2022-01 | 간이 침대 | Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | Chain-of-Though reasoning |
| 2022-03 | instructgpt | Training language models to follow instructions with human feedback | GPT-3 instruction finetuned with RLHF (reinforcement learning from human feedback) |
| 2022-03 | 친칠라 | Training Compute-Optimal Large Language Models | A smaller (70B) version of Gopher that's pretrained on more data |
| 2022-04 | 손바닥 안에 감추다 | PaLM: Scaling Language Modeling with Pathways | The largest dense model ever (540B) |
| 2022-05 | 0-shot CoT | Large Language Models are Zero-Shot Reasoners | Tell LLMs to think step by step, and they can actually do it |
| 2022-06 | BIG Bench | Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models | Another world-knowledge and complex reasoning benchmark |
| 2022-06 | Emergent Ability | Emergent Abilities of Large Language Models | A review on emergent abilities |
| 2022-10 | 플랜 | Scaling Instruction-Finetuned Language Models | Consolidate all the existing instruction tuning datasets, and you get SOTA |
| 2022-11 | 꽃 | BLOOM: A 176B-Parameter Open-Access Multilingual Language Model | The largest open-source LLM, trained on 46 languages, with detailed discussion about training and evaluation |
| 2022-12 | Self-Instruct | Self-Instruct: Aligning Language Models with Self-Generated Instructions | Instruction tuning using LLM-generated data |
This list aims to provide the essential background for understanding current LLM technologies, and thus excludes more recent models such as LLaMA, GPT-4 or PaLM 2. For comprehensive reviews on these more general topics, we refer to other sources such as this paper or these repositories: Awesome-LLM, Awesome AIGC Tutorials. And for LLM applications in other specific domains: Awesome Domain LLM, Awesome Tool Learning, Awesome-LLM-MT, Awesome Education LLM.
If you find this repo or our survey helpful, please consider citing us:
@article{zhang2024unifying,
title={Unifying the Perspectives of {NLP} and Software Engineering: A Survey on Language Models for Code},
author={Ziyin Zhang and Chaoyu Chen and Bingchang Liu and Cong Liao and Zi Gong and Hang Yu and Jianguo Li and Rui Wang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=hkNnGqZnpa},
note={}
}
We are on the lookout for top talents to join our vibrant team! If you're eager to develop your career in an environment filled with energy, innovation, and a culture of excellence, we welcome you to explore our career opportunities for both campus and experienced hires. Join us and be a part of creating the next milestone in the industry.
Campus Recruitment : https://hrrecommend.antgroup.com/guide.html?code=8uoP5mlus5DqQYbE_EnqcE2FD5JZH21MwvMUIb9mb6X3osXPuBraG54SyM8GLn_7
Experienced Hires : https://talent.antgroup.com/off-campus-position?positionId=1933830
我们正在寻找行业中的佼佼者加入我们的团队!如果您希望在一个充满活力、创新和卓越文化的环境中发展您的职业生涯,欢迎您查看我们的社招&校招机会,加入我们,一起创造下一个行业里程碑。
校招:https://hrrecommend.antgroup.com/guide.html?code=8uoP5mlus5DqQYbE_EnqcE2FD5JZH21MwvMUIb9mb6X3osXPuBraG54SyM8GLn_7
社招:https://talent.antgroup.com/off-campus-position?positionId=1933830
永久企业微信交流群:



