GPTCache
v0.1.44
LLM API 비용을 10 배나 10 배, 속도를 100x로 슬래시하십시오.
? GPTCACHE는? ️? langchain과 완전히 통합되었습니다! 자세한 사용 지침은 다음과 같습니다.
? GPTCACHE Server Docker Image가 릴리스되었으므로 모든 언어가 GPTCache를 사용할 수 있습니다!
? 이 프로젝트는 신속한 개발을 진행하고 있으며, 따라서 API는 언제든지 변경 될 수 있습니다. 최신 정보는 최신 문서 및 릴리스 노트를 참조하십시오.
참고 : 대형 모델의 수가 폭발적으로 증가하고 API 모양이 지속적으로 발전하고 있기 때문에 더 이상 새로운 API 또는 모델에 대한 지원을 추가하지 않습니다. GPTCACHE에서 Get and Set API를 사용하는 것을 권장합니다. 여기에 데모 코드가 있습니다 : https://github.com/zilliztech/gptcache/blob/main/examples/adapter/api.py
pip install gptcache
Chatgpt 및 다양한 대형 언어 모델 (LLM)은 놀라운 다목적 성을 자랑하여 광범위한 응용 프로그램의 개발을 가능하게합니다. 그러나 응용 프로그램이 인기를 얻고 트래픽 수준이 높아짐에 따라 LLM API 통화와 관련된 비용이 상당해질 수 있습니다. 또한 LLM 서비스는 특히 상당한 수의 요청을 처리 할 때 느린 응답 시간을 나타낼 수 있습니다.
이 도전을 해결하기 위해 LLM 응답을 저장하기위한 시맨틱 캐시를 구축하는 데 전념하는 프로젝트 인 GPTCACHE를 만들었습니다.
메모 :
python --version 확인하십시오.python -m pip install --upgrade pip . # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py install이 예는 정확하고 유사한 일치하는 캐싱과 일치하는 방법을 이해하는 데 도움이됩니다. Colab에서 예제를 실행할 수도 있습니다. 그리고 더 많은 예제는 부트 캠프를 참조 할 수 있습니다
예제를 실행하기 전에 echo $OPENAI_API_KEY 실행하여 OpenAI_API_KEY 환경 변수가 설정되어 있는지 확인하십시오 .
아직 설정되지 않은 경우 Unix/Linux/MacOS 시스템에서 export OPENAI_API_KEY=YOUR_API_KEY 사용하거나 Windows 시스템에서 set OPENAI_API_KEY=YOUR_API_KEY 설정할 수 있습니다.
이 방법은 일시적으로 만 효과적이므로 영구적 인 효과를 원한다면 환경 변수 구성 파일을 수정해야합니다. 예를 들어, Mac에서는
/etc/profile에있는 파일을 수정할 수 있습니다.
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )chatgpt에 똑같은 두 가지 질문을 묻는 경우, 두 번째 질문에 대한 답변은 Chatgpt를 다시 요청하지 않고 캐시에서 얻을 것입니다.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )몇 가지 유사한 질문에 대한 응답으로 Chatgpt로부터 답을 얻은 후, 후속 질문에 대한 답변은 ChatGpt를 다시 요청하지 않고도 캐시에서 검색 할 수 있습니다.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )API 서비스 또는 모델을 요청하는 동안 언제든지 온도 매개 변수를 전달할 수 있습니다.
temperature범위는 [0, 2]이고 기본값은 0.0입니다.온도가 높을수록 캐시 검색을 건너 뛰고 대형 모델을 직접 요청할 가능성이 높아집니다. 온도가 2 인 경우 캐시를 건너 뛰고 요청을 대형 모델로 직접 보냅니다. 온도가 0 인 경우 큰 모델 서비스를 요청하기 전에 캐시를 검색합니다.
Default
post_process_messages_func은temperature_softmax입니다. 이 경우temperature출력에 어떤 영향을 미치는지 알아 보려면 API 참조를 참조하십시오.
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])GPTCache를 독점적으로 사용하려면 다음 줄의 코드 만 필요하며 기존 코드를 수정할 필요가 없습니다.
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()더 많은 문서 :
GPTCache는 다음과 같은 주요 이점을 제공합니다.
온라인 서비스는 종종 데이터 지역을 나타냅니다. 캐시 시스템은 일반적으로 액세스하는 데이터를 저장 하여이 동작을 활용하여 데이터 검색 시간을 줄이고 응답 시간을 개선하며 백엔드 서버의 부담을 완화시킵니다. 기존 캐시 시스템은 일반적으로 새 쿼리와 캐시 된 쿼리 간의 정확한 일치를 사용하여 데이터를 가져 오기 전에 요청 된 컨텐츠를 캐시에서 사용할 수 있는지 확인합니다.
그러나 LLM 캐시에 정확한 일치 접근 방식을 사용하는 것은 LLM 쿼리의 복잡성과 변동성으로 인해 덜 효과적이므로 캐시 적중률이 낮습니다. 이 문제를 해결하기 위해 GPTCACHE는 시맨틱 캐싱과 같은 대체 전략을 채택합니다. 시맨틱 캐싱은 유사하거나 관련 쿼리를 식별하고 저장하여 캐시 적중 확률을 높이고 전체 캐싱 효율을 향상시킵니다.
GPTCACHE는 임베딩 알고리즘을 사용하여 쿼리를 임베딩으로 변환하고 이러한 임베딩에서 유사성 검색을 위해 벡터 저장소를 사용합니다. 이 프로세스를 통해 GPTCache는 모듈 섹션에 표시된 것처럼 캐시 스토리지에서 유사하거나 관련 쿼리를 식별하고 검색 할 수 있습니다.
모듈 식 디자인을 특징으로하는 GPTCache는 사용자가 자신의 시맨틱 캐시를 쉽게 사용자 정의 할 수 있습니다. 이 시스템은 각 모듈에 대한 다양한 구현을 제공하며 사용자는 특정 요구에 맞게 자체 구현을 개발할 수도 있습니다.
시맨틱 캐시에서는 캐시 히트 중에 오 탐지와 캐시 미스 중에 잘못된 부정을 만날 수 있습니다. GPTCACHE는 성능을 측정하기위한 세 가지 메트릭을 제공하며 개발자가 캐싱 시스템을 최적화하는 데 도움이됩니다.
사용자가 시맨틱 캐시의 성능을 평가하는 것으로 시작할 수있는 샘플 벤치 마크가 포함되어 있습니다.
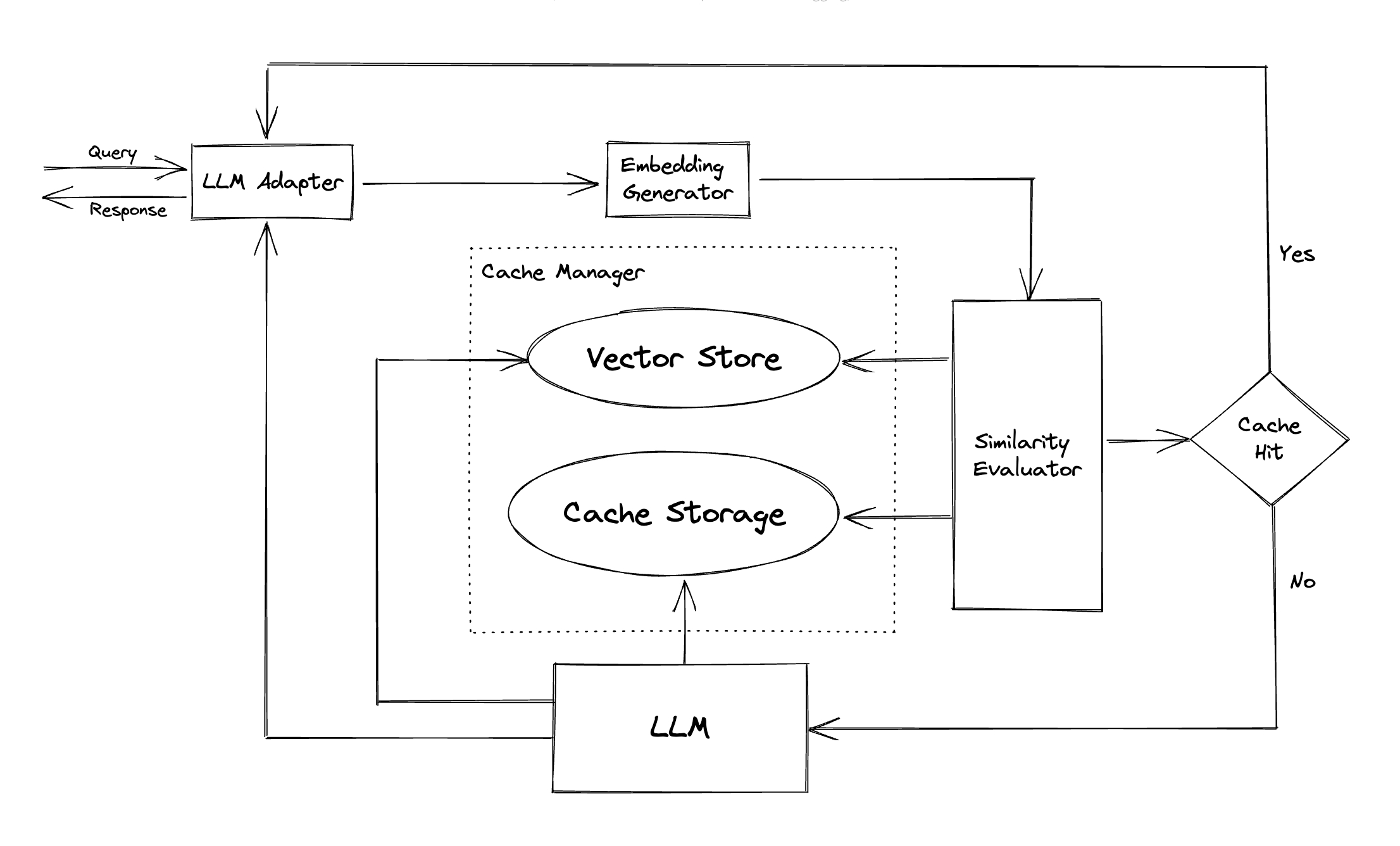
LLM 어댑터 : LLM 어댑터는 API 및 요청 프로토콜을 통합하여 다른 LLM 모델을 통합하도록 설계되었습니다. GPTCACHE는이 목적을위한 표준화 된 인터페이스를 제공하며 ChatGpt 통합을위한 현재 지원을 제공합니다.
멀티 모달 어댑터 (실험) : 멀티 모달 어댑터는 API 및 요청 프로토콜을 통합하여 다른 대형 멀티 모달 모델을 통합하도록 설계되었습니다. GPTCACHE는이 목적을위한 표준화 된 인터페이스를 제공하며 이미지 생성, 오디오 전사의 통합을 지원합니다.
삽입 생성기 :이 모듈은 유사성 검색 요청에서 내장을 추출하도록 만들어졌습니다. GPTCACHE는 다중 임베딩 API를 지원하는 일반적인 인터페이스를 제공하며 선택할 수있는 다양한 솔루션을 제공합니다.
캐시 스토리지 : 캐시 스토리지는 ChatGpt와 같은 LLM의 응답이 저장되는 곳입니다. 캐시 된 응답은 유사성 평가를 돕기 위해 검색되며 의미 론적 일치가 있으면 요청자에게 반환됩니다. 현재 GPTCache는 SQLITE를 지원 하고이 모듈의 확장에 대한 보편적으로 액세스 가능한 인터페이스를 제공합니다.
벡터 스토어 : 벡터 스토어 모듈은 입력 요청의 추출 된 임베딩에서 가장 유사한 요청을 찾는 데 도움이됩니다. 결과는 유사성을 평가하는 데 도움이 될 수 있습니다. GPTCache는 Milvus, Zilliz Cloud 및 Faiss를 포함한 다양한 벡터 매장을 지원하는 사용자 친화적 인 인터페이스를 제공합니다. 앞으로 더 많은 옵션을 사용할 수 있습니다.
캐시 관리자 : 캐시 관리자는 캐시 스토리지 및 벡터 스토어 의 작동을 제어 할 책임이 있습니다.
cachetools 사용하여 메모리에서 또는 Redis를 키 값 저장소로 사용하여 분산 방식으로 관리 할 수 있습니다.현재 GPTCACHE는 라인 수만 기반으로 퇴거에 대한 결정을 내립니다. 이 접근법은 부정확 한 리소스 평가를 초래할 수 있으며 메모리 외 (OOM) 오류가 발생할 수 있습니다. 우리는보다 정교한 전략을 적극적으로 조사하고 개발하고 있습니다.
메모리 인 캐싱을 사용하여 GPTCACHE 배포를 가로로 확장하려면 가능하지 않습니다. 캐시 된 정보는 단일 포드로 제한되기 때문에.
분산 된 캐싱을 사용하면 모든 복제본에서 일관된 캐시 정보를 일관되게 캐시합니다. Redis와 같은 분산 캐시 스토어를 사용할 수 있습니다.
유사성 평가자 :이 모듈은 캐시 스토리지 및 벡터 스토어 에서 데이터를 수집하고 다양한 전략을 사용하여 입력 요청과 벡터 스토어 의 요청 간의 유사성을 결정합니다. 이러한 유사성을 기반으로 요청이 캐시와 일치하는지 여부를 결정합니다. GPTCACHE는 다양한 전략을 통합하기위한 표준화 된 인터페이스와 사용할 구현 모음을 제공합니다. 다음 유사성 정의는 현재 지원되거나 향후 지원됩니다.
참고 : 다른 모듈의 모든 조합이 서로 호환되는 것은 아닙니다. 예를 들어, 임베딩 추출기를 비활성화하면 벡터 스토어가 의도 한대로 작동하지 않을 수 있습니다. 우리는 현재 GPTCACHE 에 대한 Combinity Sanity Check를 구현하기 위해 노력하고 있습니다.
곧 올 것입니다! 계속 지켜봐!
우리는 새로운 기능, 향상된 인프라 또는 개선 된 문서를 통해 기부 할 수 있습니다.
기부 방법에 대한 포괄적 인 지침은 기여 안내서를 참조하십시오.


