JARVIS ChatGPT
1.0.0
다양한 합성 목소리가 장착 된 음성 기반의 대화 형 보조원 (Ironman의 Jarvis의 목소리 포함)
 MidJourney AI의 이미지
MidJourney AI의 이미지
갑옷을 개선하기 위해 하이퍼 지능 시스템 팁을 요청하는 꿈을 꾸었습니까? 이제 당신은 할 수 있습니다! 글쎄, 아마도 갑옷 부분이 아닐 수도 있습니다 ...이 프로젝트는 Openai Whisper, Openai Chatgpt 및 IBM Watson을 이용합니다.
프로젝트 동기 부여 :
여러 번 아이디어가 최악의 순간에 와서 더 잘 탐색 할 시간이 있기 전에 사라집니다. 이 프로젝트의 목적은 준 진실에 팁과 의견을 제시 할 수있는 시스템을 개발하는 것입니다. Ultimate Assistant는 집이나 휴대 전화 내부의 승인 된 마이크에서 액세스 할 수 있으며, 배경에서 지속적으로 실행해야하며, 소환 할 때는 PC 또는 서버와의 인터페이스뿐만 아니라 나중에 액세스 할 수있는 파일을 저장/읽기/쓰기 할 수 있어야하며, 소환 할 때는 의미있는 답변 (나쁜 음성 포함)을 생성 할 수 있어야합니다. 연구를 실행하고 인터넷에서 자료를 수집 할 수 있어야합니다 (HTML 페이지에서 콘텐츠 추출, YouTube 동영상을 전사하고 과학 논문을 찾는 등) 및 정보에 입각 한 결정을 내릴 수있는 요약을 제공 할 수 있어야합니다. 또한 일부 외부 가제트 (IoT)와 인터페이스 할 수 있지만 추가입니다.
데모:
Finnaly는 연구 모드의 첫 번째 초안을 공유 할 수 있습니다. 이 양식은 종종 연구 논문을 다루는 사람들에게 생각되었습니다.
추신 :이 모드는 매우 안정적이지 않으며 작업해야합니다.
PPS :이 프로젝트는 2024 년까지 논문을 작업하기 위해 한동안 중단 될 것입니다. 그러나 이미 개선 될 수있는 많은 것들이 너무 많아서 돌아올 것입니다!
부인 성명:
이 프로젝트는 OpenAI 신용을 소비하여 바람직하지 않은 청구를 초래할 수 있습니다.
나는 원치 않는 혐의에 대해 책임을지지 않습니다.
OpenAI 계정에서 신용 소비에 대한 제한을 설정하는 것을 고려하십시오.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 );당신은 당신을 위해 대부분의 일을 할 새로운
setup.bat에 의존 할 수 있습니다.
실행 해야하는 기본 스크립트 : openai_api_chatbot.py Demos 폴더 내부에서 최신 버전의 OpenAI API를 사용하려면 프로젝트에 사용 된 패키지에 대한 지침을 찾을 수 있습니다. 오류가 있으면이 파일을 먼저 확인하여 문제를 대상으로 할 수 있습니다. 주로 어시스턴트 폴더에 저장 voice.py . get_audio.py 마이크 상호 작용 tools.py 처리하기위한 모든 기능을 저장합니다. Agents.py
나머지 스크립트는 음성 생성을 보충하며 편집해서는 안됩니다.
Windows/Linux에서 실행중인 경우 setup.bat 실행할 수 있습니다. 스크립트는 수동 설치의 모든 단계를 순서대로 수행합니다. 절차가 실패 해야하는 경우를 참조하십시오.
자동 설치는 Vicuna 설치 (Vicuna 설치 가이드)도 실행됩니다.
pip install -r venv_requirements.txt ; 시간이 좀 걸릴 수 있습니다. 특정 패키지에서 충돌이 발생하면 ==<version> 없이 수동으로 설치하십시오.whisper_edits 폴더에서 찾은 파일을 환경의 whisper 폴더에 복사하여 붙여 넣습니다 (. venv lib site-packages whisper ) 이 편집은 Whisper 모델에 속성 만 추가하여 차원에 더 쉽게 액세스 할 수 있습니다.demos/tts_demo.py 실행할 수 있음); cd Vicuna
call vicuna.ps1
env.txt 파일에 모든 키를 붙여 넣고 .env 로 이름을 바꿉니다 (예, txt 확장자 제거).torch.cuda.is_available() 및 torch.cuda.get_device_name(0) 실행하여 Graphic Engine 및 Cuda 버전을 Pytorch와 호환되는지 확인하십시오. .tests.py 실행합니다. 이 파일은 오류가 발생할 수있는 기본 작업을 수행하려고 시도합니다.VirtualAssistant.__init__() ; 
whisper_model = whisper.load_model("large") 의 __main__() 의 더 큰 것으로 업그레이드하십시오. 그러나 GPU 메모리도 마찬가지로 크기를 바랍니다. openai_api_chatbot.py ) :실행할 때 많은 정보가 표시됩니다. 나는 실행의 가독성을 향상시키기 위해 끊임없이 노력하고 있습니다. 전체 프로젝트는 거대한 베타이며 아래 화면에서 약간의 변형을 용서합니다. 어쨌든, 이것은 당신이 'run'을 때릴 때 일반적으로 일어나는 일입니다.
Jarvis 말해야합니다. 이 시점에서 대화가 시작되며 원하는 언어로 말할 수 있습니다 (2 단계를 따르는 경우). 대화가 끝나면 1) 1) 중지 단어 2) 한 단어 ( 'OK'와 같은 단어) 3) 3) 30 초 이상 질문을 중단 할 때 
chat_history 를 확장하고 API와 함께 요청을 보내며 ChatGpt로부터 전체 답변을받는 즉시 기록을 업데이트합니다 (이는 최대 5-10 초가 걸릴 수 있으며 서둘러 서둘러 짧은 답변을 명시 적으로 요구하는 것을 고려하십시오).say() 함수는 Jarvis/누군가의 목소리와 대화하기 위해 음성 복제를 수행합니다. 논쟁이 영어로되어 있지 않으면 IBM Watson은 멋진 텍스트 연설 모델 중 하나에서 응답을 보낼 것입니다. 모든 것이 실패하면 기능은 빠르고 시원한 대안이 아닌 pyttsx3에 의존합니다.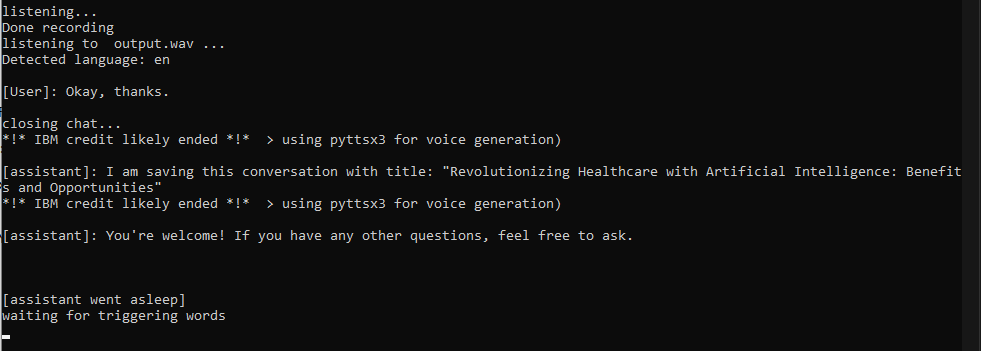
나는 프롬프트를 만들고 대화를 마무리했다
이상적이지는 않지만 지금은 작동합니다
VirtualAssistant 클래스 생성 현재 작업 :
수행원:
더 많은 통찰력은 프로젝트의 UpdateHistory.MD를 확인하십시오.
재미있게 보내세요!
카테고리 : 설치, 일반, 런타임
문제는 Whisper와 관련이 있습니다. pip install whisper-openai 사용하여 수동으로 다시 설치해야합니다
pip install --upgrade openai 로 사용하십시오. 요구 사항은 모든 커밋을 업데이트하지 않습니다. 이로 인해 오류가 발생할 수 있지만 누락 된 모듈을 신속하게 설치할 수 있으며 동시에 새로운 패키지를 시도 할 때 환경이 충돌로부터 깨끗하게 유지됩니다 (그리고 많은 시도를 시도합니다).
그것은 당신이 선택한 모델이 Cuda 장치 메모리에 너무 큰 것을 의미합니다. 불행히도 더 작은 모델을로드하는 것 외에는 할 수있는 일이 많지 않습니다. 작은 모델이 당신을 만족시키지 못하면, 당신은 '명확한'말을하거나 더 긴 프롬프트를 만들어 모델이 당신이 말하는 것을보다 정확하게 예측하도록 할 수 있습니다. 이것은 불편하게 들리지만 제 경우에는 영어권을 크게 향상 시켰습니다 :)
이것은 여전히 존재하는 버그이며, 어느 시점에서 전체 대화를 기억하기에 충분한 기억을 가질 것이기 때문에 조수와의 대화가 오래 걸릴 것으로 기대하지 않습니다. 수정이 개발 중이며 일부 개념을 반복 할 수 있어도 '슬라이딩 윈도우'접근 방식을 채택하는 것으로 구성 될 수 있습니다.
지금 (2023 년 4 월) 나는 이것에 대해 거의 논스톱으로 일하고 있습니다. 나는 논문을 작업하기 때문에 여름에 휴식을 취할 것입니다.
궁금한 점이 있으면 문제를 제기하여 저에게 연락 할 수 있으며 가능한 빨리 도움을 줄 수 있습니다.
Gianmarco Guarnier


