최근 AI LLM(대형 언어 모델) 애플리케이션의 인기로 인해 하드웨어 분야에서 치열한 경쟁이 벌어지고 있습니다. AMD는 최신 Strix Point APU 시리즈를 출시했으며, Ryzen AI 프로세서는 Intel의 Lunar Lake 시리즈를 훨씬 능가하는 성능으로 LLM 작업을 처리하는 데 상당한 이점을 보여줍니다. Downcodes의 편집자는 Strix Point APU 시리즈의 성능과 그 뒤에 숨은 기술 혁신에 대한 심층적인 이해를 제공할 것입니다.
최근 AMD는 AI LLM(대형 언어 모델) 애플리케이션에서 시리즈의 뛰어난 성능을 강조하는 최신 Strix Point APU 시리즈를 출시하여 Intel의 Lunar Lake 시리즈 프로세서를 훨씬 능가했습니다. AI 워크로드에 대한 수요가 계속 증가함에 따라 하드웨어 경쟁도 점점 더 치열해지고 있습니다. 시장에 대응하여 AMD는 더 높은 성능과 더 낮은 대기 시간을 목표로 모바일 플랫폼용으로 설계된 AI 프로세서를 출시했습니다.
AMD는 ix Point 시리즈의 Ryzen AI300 프로세서가 AI LLM 작업을 처리할 때 초당 처리되는 토큰 수를 크게 늘릴 수 있다고 밝혔습니다. Intel의 Core Ultra258V와 비교하여 Ryzen AI9375의 성능은 27% 향상되었습니다. Core Ultra7V는 L Lake 시리즈에서 가장 빠른 모델은 아니지만 코어 및 스레드 수는 고급 Lunar Lake 프로세서에 가까워 이 분야에서 AMD 제품의 경쟁력을 보여줍니다.
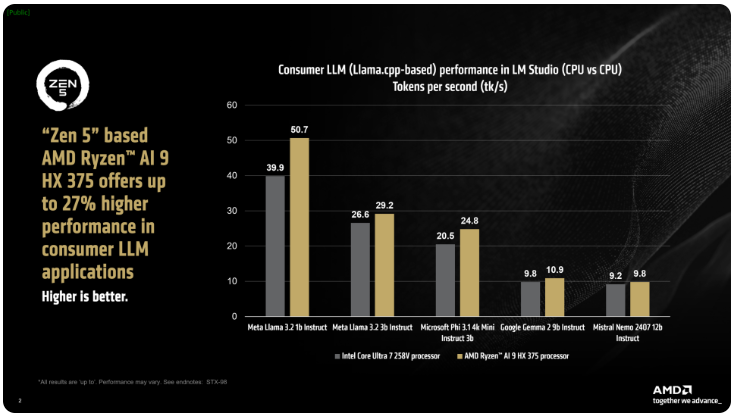
AMD의 LM Studio 도구는 llama.cpp 프레임워크를 기반으로 하는 소비자 지향 애플리케이션으로, 대규모 언어 모델의 사용을 단순화하도록 설계되었습니다. 프레임워크는 x86 CPU의 성능을 최적화합니다. LLM을 실행하는 데 GPU가 필요하지는 않지만 GPU를 사용하면 처리 속도가 더욱 빨라질 수 있습니다. 테스트에 따르면 Ryzen AI9HX375는 Meta Llama3.21b Instruct 모델에서 35배 더 낮은 대기 시간을 달성하여 초당 50.7 토큰을 처리할 수 있습니다. 이에 비해 Core Ultra7258V는 39.9 토큰에 불과합니다.
뿐만 아니라 Strix Point APU에는 RDNA3.5 아키텍처 기반의 강력한 Radeon 통합 그래픽 카드도 장착되어 있어 ulkan API를 통해 작업을 iGPU로 오프로드하여 LLM의 성능을 더욱 향상시킬 수 있습니다. Ryzen AI300 프로세서는 VGM(가변 그래픽 메모리) 기술을 사용하여 메모리 할당을 최적화하고 에너지 효율성을 향상시키며 궁극적으로 최대 60%의 성능 향상을 달성할 수 있습니다.
비교 테스트에서 AMD는 Intel AI Playground 플랫폼에서 동일한 설정을 사용했으며 Ryzen AI9HX375가 Microsoft Phi3.1의 Core Ultra7258V보다 87% 빠르고 Mistral7b Instruct0.3 모델에서 13% 더 빠른 것으로 나타났습니다. 그래도 Lunar Lake 시리즈의 주력 제품인 Core Ultra9288V와 비교하면 결과가 더 흥미롭습니다. 현재 AMD는 LM Studio를 통해 대규모 언어 모델의 사용을 더욱 대중화하는 데 주력하고 있으며, 기술에 익숙하지 않은 사용자가 더 쉽게 시작할 수 있도록 하는 것을 목표로 하고 있습니다.
AMD Strix Point APU 시리즈의 출시는 AI 프로세서 분야의 경쟁이 더욱 심화되고 미래의 AI 애플리케이션이 더욱 강력한 하드웨어 지원을 받게 될 것임을 나타냅니다. 성능과 에너지 효율성이 향상되어 사용자에게 더욱 부드럽고 강력한 AI 경험을 선사할 것입니다. Downcodes의 편집자는 이 분야의 최신 개발에 계속해서 관심을 기울이고 독자들에게 더욱 흥미로운 보고서를 제공할 것입니다.