다운코드 편집자 보고서: 최근 몇 년 동안 오디오 기반 이미지 애니메이션 기술이 빠르게 발전했지만 기존 모델은 효율성과 지속 시간 측면에서 여전히 병목 현상을 겪고 있습니다. 이 문제를 해결하기 위해 연구원들은 독창적인 2단계 설계를 통해 오디오 기반 이미지 애니메이션의 품질과 효율성을 크게 향상시키는 JoyVASA라는 새로운 기술을 개발했습니다. JoyVASA는 긴 애니메이션 영상을 제작할 수 있을 뿐만 아니라 동물 얼굴 애니메이션을 지원하고 다국어 호환성도 뛰어나 애니메이션 제작 분야에 새로운 가능성을 열어줍니다.
최근 연구자들은 오디오 기반 이미지 애니메이션 효과를 향상시키는 것을 목표로 하는 JoyVASA라는 새로운 기술을 제안했습니다. 딥 러닝 및 확산 모델의 지속적인 개발로 오디오 기반 인물 애니메이션은 비디오 품질과 입술 동기화 정확도가 크게 향상되었습니다. 그러나 기존 모델의 복잡성으로 인해 훈련 및 추론의 효율성이 높아지는 동시에 비디오의 지속 시간과 프레임 간 연속성이 제한됩니다.
JoyVASA는 2단계 디자인을 채택합니다. 첫 번째 단계에서는 동적 얼굴 표정과 정적 3차원 얼굴 표현을 분리하는 분리된 얼굴 표현 프레임워크를 도입합니다.
이러한 분리를 통해 시스템은 정적 3D 얼굴 모델을 동적 동작 시퀀스와 결합하여 더 긴 애니메이션 비디오를 생성할 수 있습니다. 두 번째 단계에서 연구팀은 오디오 신호에서 직접 액션 시퀀스를 생성할 수 있는 확산 변환기(캐릭터 정체성과 무관한 프로세스)를 훈련했습니다. 마지막으로 1단계 학습을 기반으로 한 생성기는 3D 얼굴 표현과 생성된 동작 시퀀스를 입력으로 사용하여 고품질 애니메이션 효과를 렌더링합니다.
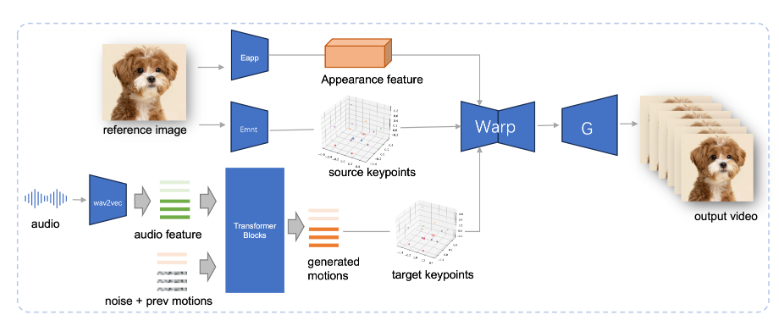
특히 JoyVASA는 인간 초상화 애니메이션에만 국한되지 않고 동물 얼굴도 원활하게 애니메이션화할 수 있습니다. 이 모델은 비공개 중국어 데이터와 공개 영어 데이터를 결합한 혼합 데이터 세트로 학습되었으며 우수한 다국어 지원 기능을 보여줍니다. 실험 결과는 이 방법의 효율성을 입증합니다. 향후 연구에서는 실시간 성능을 향상하고 표현 제어를 개선하여 이미지 애니메이션에서 이 프레임워크의 적용을 더욱 확장하는 데 중점을 둘 것입니다.
JoyVASA의 등장은 오디오 기반 애니메이션 기술의 중요한 혁신을 의미하며 애니메이션 분야의 새로운 가능성을 촉진합니다.
프로젝트 입구: https://jdh-algo.github.io/JoyVASA/
JoyVASA 기술의 혁신은 애니메이션 제작을 위한 보다 편리하고 효율적인 솔루션을 제공하는 효율적인 2단계 설계와 강력한 다국어 지원 기능에 있습니다. 앞으로도 JoyVASA는 기술이 더욱 발전하여 더 많은 분야에서 널리 활용되어 더욱 실감나고 흥미로운 애니메이션 작품을 선보일 것으로 기대됩니다. 더 많은 기술적 혁신과 애니메이션 산업 발전의 새로운 장을 이끌기를 기대합니다!