Apple AI 연구팀은 텍스트, 이미지 등 다양한 데이터 유형을 통합할 수 있는 차세대 다중 모드 대형 언어 모델 제품군 MM1.5를 출시했으며 시각적 질문 답변, 이미지 생성 및 다중 언어 생성 등의 작업에서 강력한 성능을 입증했습니다. 모달 데이터 해석 능력. MM1.5는 텍스트가 많은 이미지와 세밀한 시각적 작업을 처리하는 데 있어 이전 다중 모드 모델의 어려움을 극복했습니다. 혁신적인 데이터 중심 접근 방식을 통해 고해상도 OCR 데이터와 합성 이미지 설명을 사용하여 모델 성능을 크게 향상시킵니다. . 이해력. Downcodes의 편집자는 MM1.5의 혁신과 여러 벤치마크 테스트에서 뛰어난 성능에 대한 심층적인 이해를 제공합니다.
최근 Apple의 AI 연구팀은 차세대 다중 모드 MLLM(대형 언어 모델) 제품군인 MM1.5를 출시했습니다. 이 일련의 모델은 텍스트 및 이미지와 같은 여러 데이터 유형을 결합하여 복잡한 작업을 이해하는 AI의 새로운 능력을 보여줍니다. 시각적 질문 답변, 이미지 생성, 다중 모드 데이터 해석과 같은 작업은 모두 이러한 모델의 도움으로 더 잘 해결될 수 있습니다.
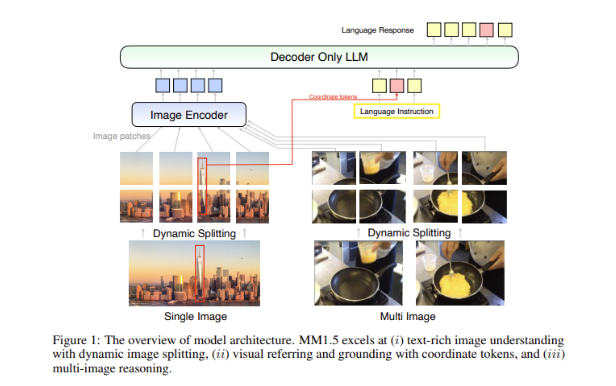
다중 모드 모델의 큰 과제는 다양한 데이터 유형 간의 효과적인 상호 작용을 달성하는 방법입니다. 과거 모델은 텍스트가 많은 이미지나 세밀한 비전 작업으로 인해 어려움을 겪는 경우가 많았습니다. 이에 Apple 연구팀은 모델의 이해력을 강화하기 위해 고해상도 OCR 데이터와 합성 이미지 설명을 활용하는 혁신적인 데이터 중심 방식을 MM1.5 모델에 도입했습니다.
이 방법을 사용하면 MM1.5가 시각적 이해 및 위치 지정 작업에서 이전 모델을 능가할 수 있을 뿐만 아니라 비디오 이해 및 위치 지정에 각각 사용되는 두 가지 특수 버전의 모델인 MM1.5-Video 및 MM1.5-UI를 출시할 수 있습니다. . 모바일 인터페이스 분석.
MM1.5 모델의 훈련은 세 가지 주요 단계로 나뉩니다.
첫 번째 단계는 20억 쌍의 이미지 및 텍스트 데이터, 6억 개의 인터리브된 이미지-텍스트 문서 및 2조 개의 텍스트 전용 토큰을 사용하는 대규모 사전 학습입니다.
두 번째 단계는 4,500만 개의 고품질 OCR 데이터와 700만 개의 합성 설명에 대한 지속적인 사전 학습을 통해 텍스트가 풍부한 이미지 작업의 성능을 더욱 향상시키는 것입니다.
마지막으로 감독된 미세 조정 단계에서는 신중하게 선택된 단일 이미지, 다중 이미지 및 텍스트 전용 데이터를 사용하여 모델을 최적화하여 상세한 시각적 참조 및 다중 이미지 추론을 더 잘 수행합니다.
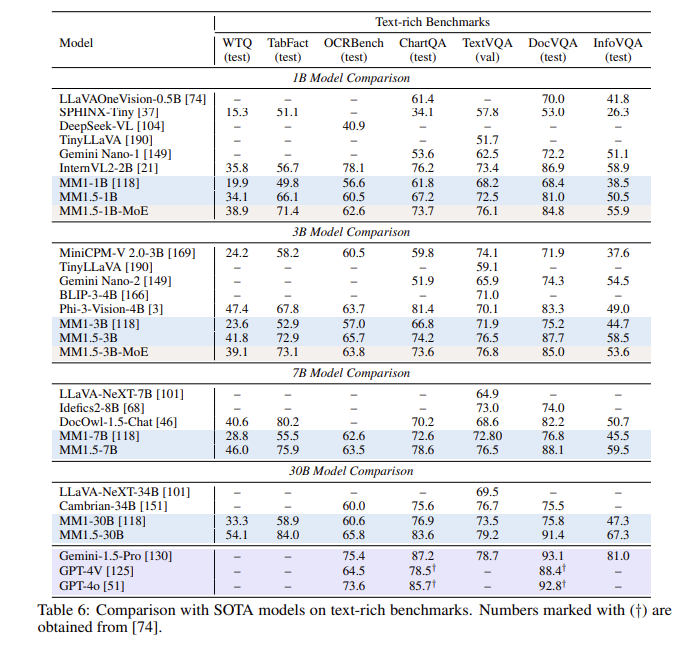
일련의 평가 후 MM1.5 모델은 여러 벤치마크 테스트에서 특히 텍스트가 풍부한 이미지 이해를 처리할 때 이전 모델보다 1.4포인트 향상된 성능을 보였습니다. 또한 비디오 이해를 위해 특별히 설계된 MM1.5-Video도 강력한 다중 모드 기능을 통해 관련 작업에서 선도적인 수준에 도달했습니다.
MM1.5 모델 제품군은 다중 모드 대형 언어 모델에 대한 새로운 벤치마크를 설정할 뿐만 아니라 일반 이미지 텍스트 이해부터 비디오 및 사용자 인터페이스 분석에 이르기까지 다양한 애플리케이션에서 탁월한 성능으로 잠재력을 보여줍니다.
가장 밝은 부분:
**모델 변형**: 10억에서 300억까지의 매개변수를 가진 밀도 모델과 MoE 모델을 포함하여 확장성과 유연한 배포를 보장합니다.
? **훈련 데이터**: 20억 개의 이미지-텍스트 쌍, 6억 개의 인터리브된 이미지-텍스트 문서 및 2조 개의 텍스트 전용 토큰을 활용합니다.
**성능 개선**: 텍스트가 풍부한 이미지 이해에 초점을 맞춘 벤치마크 테스트에서 이전 모델에 비해 1.4점 개선이 이루어졌습니다.
전체적으로 Apple의 MM1.5 모델 제품군은 다중 모드 대형 언어 모델 분야에서 상당한 진전을 이루었으며 혁신적인 방법과 뛰어난 성능은 미래 AI 개발을 위한 새로운 방향을 제시합니다. 우리는 MM1.5가 더 많은 애플리케이션 시나리오에서 잠재력을 보여줄 수 있기를 기대합니다.